2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
L'utilisation de bases de données de graphes ou de graphes de connaissances dans les applications de grands modèles est devenue de plus en plus populaire ces derniers temps. Les graphiques présentent des avantages naturels pour représenter et stocker des informations diverses et interdépendantes, et peuvent facilement capturer des relations et des attributs complexes entre différents types de données, fournissant ainsi un meilleur contexte ou une prise en charge des données pour les grands modèles. Dans cet article, voyons comment utiliser des bases de données de graphiques ou des graphiques de connaissances dans des applications de grands modèles.
Cet article n’est qu’une simple introduction et expérience.Peu importe si vous ne connaissez pas la base de données graphique ou neo4j, suivez simplement les étapes décrites dans cet article. . Cet article peut vous aider à comprendre la méthode d'application du graphe de connaissances dans RAG. Une fois que vous aurez l'expérience, vous pourrez apprendre à utiliser la base de données graphique plus tard si vous en avez besoin.
Un graphe de connaissances est une base de connaissances sémantique structurée qui stocke et représente des entités (telles que des personnes, des lieux, des organisations, etc.) et des relations entre entités (telles que des relations entre personnes, des relations de localisation géographique, etc.) sous forme de graphiques. Les graphes de connaissances sont souvent utilisés pour améliorer la compréhension sémantique des moteurs de recherche, en fournissant des informations plus riches et des résultats de recherche plus précis.
Les principales fonctionnalités du graphe de connaissances comprennent :
1. Entité : L'unité de base du graphe de connaissances, représentant un objet ou un concept dans le monde réel.
2. Relation: La relation entre les entités, telles que "appartient à", "se trouve dans", "créateur", etc.
3. Attribut: Informations descriptives possédées par l'entité, telles que l'âge de la personne, la longitude et la latitude du lieu, etc.
4. Structure du graphique: Le graphe de connaissances organise les données sous la forme d'un graphe, comprenant des nœuds (entités) et des arêtes (relations).
5. *Réseau sémantique: Un graphe de connaissances peut être considéré comme un réseau sémantique dans lequel les nœuds et les arêtes ont des significations sémantiques.
6. Inférence: Les graphiques de connaissances peuvent être utilisés pour le raisonnement, c'est-à-dire pour dériver de nouvelles informations à travers des entités et des relations connues.
Les graphes de connaissances sont largement utilisés dans l'optimisation des moteurs de recherche (SEO), les systèmes de recommandation, le traitement du langage naturel (NLP), l'exploration de données et d'autres domaines. Par exemple, le Knowledge Graph de Google, Wikidata, DBpedia, etc. sont tous des exemples bien connus de graphes de connaissances.
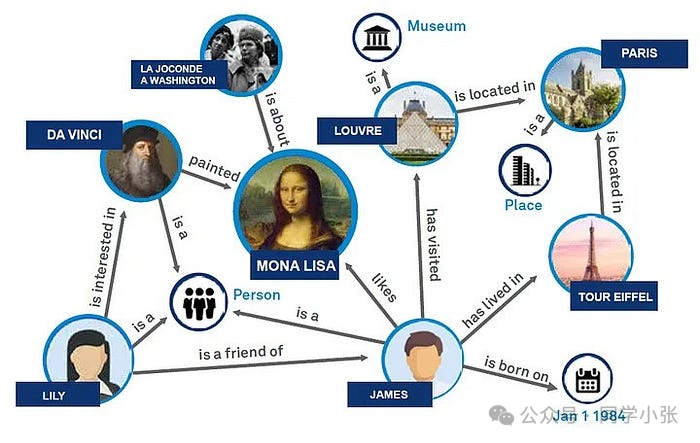
En tant que forme d'organisation des données, l'importance du graphe de connaissances est de fournir un moyen efficace et intuitif de représenter et de gérer des relations de données complexes. Il affiche les données sous une forme structurée à travers les nœuds et les bords de la structure graphique, améliore la capacité d'expression sémantique des données et rend la relation entre les entités claire et nette. Les graphes de connaissances améliorent considérablement la précision de la recherche d'informations, en particulier dans le domaine du traitement du langage naturel, permettant aux machines de mieux comprendre et de mieux répondre aux requêtes complexes des utilisateurs. Les graphes de connaissances jouent un rôle essentiel dans les applications intelligentes, telles que les systèmes de recommandation, les réponses intelligentes aux questions, etc.
Après l'introduction ennuyeuse, jetons un coup d'œil au cas du graphe de connaissances RAG+ et implémentons-le nous-mêmes.
Le cas suivant est issu de la documentation officielle de LangChain : https://python.langchain.com/v0.1/docs/integrations/graphs/neo4j_cypher/#refresh-graph-schema-information
(1) Vous devez d’abord installer une base de données graphique, ici nous utilisons neo4j.
Commande d'installation Python :
pip install neo4j
(2) Enregistrez un compte officiel, connectez-vous et créez une instance de base de données. (Si vous souhaitez l'utiliser pour apprendre, choisissez simplement celui gratuit.)
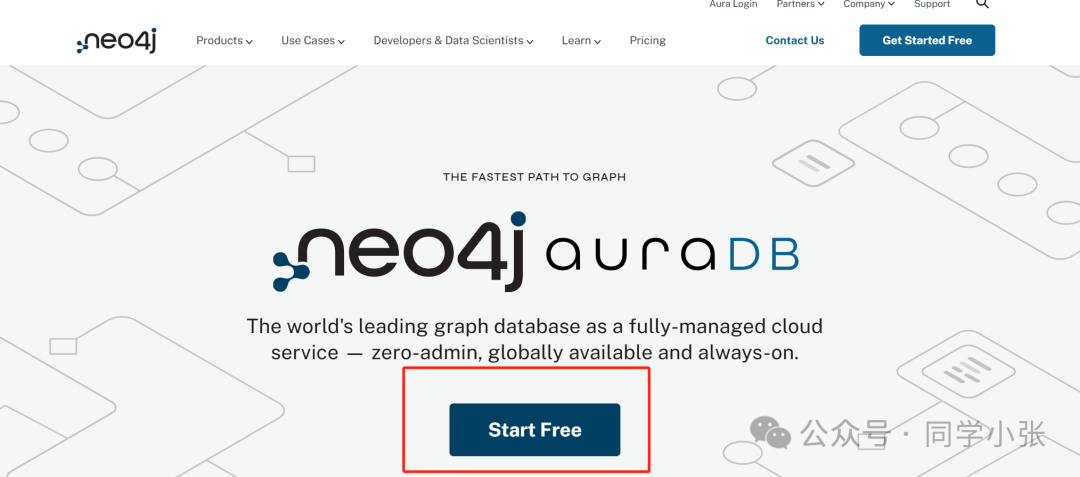
Après avoir créé une instance de base de données en ligne, la page est la suivante :
Vous pouvez maintenant utiliser cette base de données dans votre code.
(1) Après avoir créé l'instance de base de données, vous devez obtenir le lien, le nom d'utilisateur et le mot de passe des données. L'ancienne règle consiste à les mettre dans la variable d'environnement, puis à charger la variable d'environnement via Python :
neo4j_url = os.getenv('NEO4J_URI')
neo4j_username = os.getenv('NEO4J_USERNAME')
neo4j_password = os.getenv('NEO4J_PASSWORD')
(2) Base de données de liens
LangChain encapsule l'interface neo4j et il suffit d'importer la classe Neo4jGraph pour l'utiliser.
from langchain_community.graphs import Neo4jGraph
graph = Neo4jGraph(url=neo4j_url, username=neo4j_username, password=neo4j_password)
(3) Interroger et remplir les données
Vous pouvez utiliser l'interface de requête pour interroger et renvoyer des résultats. Le langage de l'instruction de requête est le langage de requête Cypher.
result = graph.query(
"""
MERGE (m:Movie {name:"Top Gun", runtime: 120})
WITH m
UNWIND ["Tom Cruise", "Val Kilmer", "Anthony Edwards", "Meg Ryan"] AS actor
MERGE (a:Actor {name:actor})
MERGE (a)-[:ACTED_IN]->(m)
"""
)
print(result)
# 输出:[]
La sortie du code ci-dessus est []。
(4) Actualiser les informations architecturales du graphique
graph.refresh_schema()
print(graph.schema)

À partir des résultats, le schéma contient des informations telles que les types de nœuds, les attributs et les relations entre les types, et constitue l'architecture du graphique.
Nous pouvons également nous connecter à la page Web neo4j pour visualiser les données stockées dans la base de données graphique :
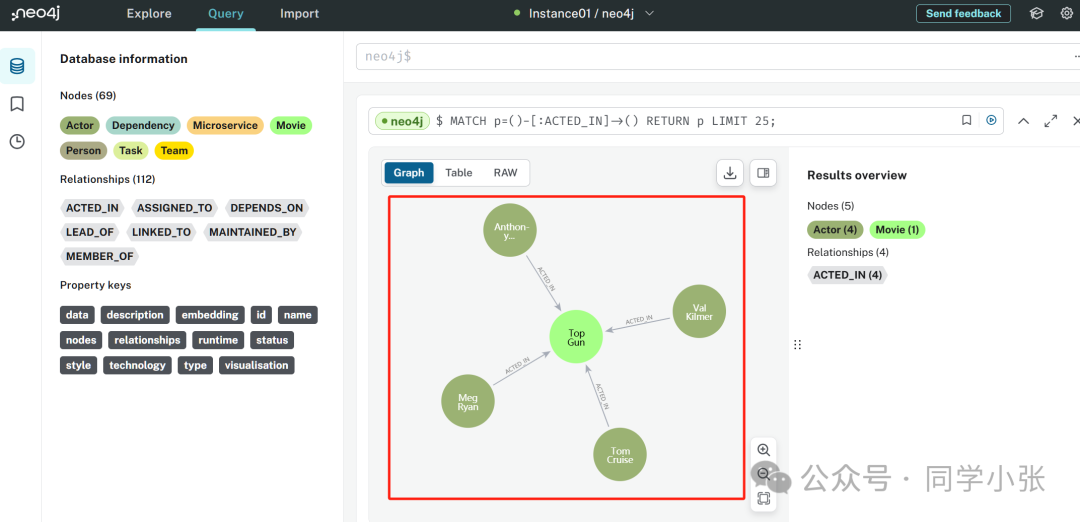
(5) Maintenant qu'il y a des données dans la base de données graphique, nous pouvons les interroger.
La classe GraphCypherQAChain est encapsulée dans LangChain, qui peut être facilement interrogée à l'aide de la base de données graphique. Le code suivant :
chain = GraphCypherQAChain.from_llm(
ChatOpenAI(temperature=0), graph=graph, verbose=True
)
result = chain.invoke({"query": "Who played in Top Gun?"})
print(result)
Processus d’exécution et résultats :

Tout d'abord, le langage naturel (Qui a joué dans Top Gun ?) est converti en une instruction de requête graphique via un grand modèle, puis l'instruction de requête est exécutée via neo4j, les résultats sont renvoyés et enfin, elle est convertie en langage naturel via le grand modèle. modèle et sortie à l’utilisateur.
Dans le code ci-dessus, nous utilisons la classe GraphCypherQAChain de LangChain, qui est la requête de base de données graphique et la chaîne de questions et réponses fournies par LangChain.Il comporte de nombreux paramètres pouvant être définis, tels que l'utilisationexclude_types Pour définir les types de nœuds ou les relations à ignorer :
chain = GraphCypherQAChain.from_llm(
graph=graph,
cypher_llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo"),
qa_llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo-16k"),
verbose=True,
exclude_types=["Movie"],
)
Le résultat est similaire à ce qui suit :
Node properties are the following:
Actor {name: STRING}
Relationship properties are the following:
The relationships are the following:
Il existe de nombreux paramètres similaires disponibles, vous pouvez vous référer à la documentation officielle : https://python.langchain.com/v0.1/docs/integrations/graphs/neo4j_cypher/#use-separate-llms-for-cypher-and- génération de réponses
Voici le code source d'exécution de GraphCypherQAChain. Jetons un bref aperçu de son processus d'exécution.
(1)cypher_generation_chain: Conversion du langage naturel en instructions de requête graphique.
(2)extract_cypher : supprimez l'instruction de requête. En effet, les modèles volumineux peuvent renvoyer des informations de description supplémentaires et doivent être supprimés.
(3)cypher_query_corrector : corrigez l'instruction de requête.
(4)graph.query: Exécuter des instructions de requête, interroger la base de données graphique et obtenir du contenu
(5)self.qa_chain: Sur la base du contenu de la question et de la requête d'origine, le grand modèle est à nouveau utilisé pour organiser les réponses et les envoyer à l'utilisateur en langage naturel.
def _call( self,
inputs: Dict[str, Any],
run_manager: Optional[CallbackManagerForChainRun] = None,) -> Dict[str, Any]:
"""Generate Cypher statement, use it to look up in db and answer question."""
......
generated_cypher = self.cypher_generation_chain.run(
{"question": question, "schema": self.graph_schema}, callbacks=callbacks
)
# Extract Cypher code if it is wrapped in backticks
generated_cypher = extract_cypher(generated_cypher)
# Correct Cypher query if enabled
if self.cypher_query_corrector:
generated_cypher = self.cypher_query_corrector(generated_cypher)
......
# Retrieve and limit the number of results
# Generated Cypher be null if query corrector identifies invalid schema
if generated_cypher:
context = self.graph.query(generated_cypher)[: self.top_k]
else:
context = []
if self.return_direct:
final_result = context
else:
......
result = self.qa_chain(
{"question": question, "context": context},
callbacks=callbacks,
)
final_result = result[self.qa_chain.output_key]
chain_result: Dict[str, Any] = {self.output_key: final_result}
......
return chain_result
En tant que vétéran enthousiaste d'Internet, j'ai décidé de partager mes précieuses connaissances en IA avec tout le monde. Quant à ce que vous pouvez apprendre, cela dépend de votre persévérance et de vos capacités à étudier. J'ai partagé gratuitement du matériel important sur les grands modèles d'IA, notamment des cartes mentales d'introduction à l'apprentissage des grands modèles d'IA, des livres et manuels d'apprentissage de grands modèles d'IA de haute qualité, des didacticiels vidéo, des apprentissages pratiques et d'autres vidéos enregistrées gratuitement.
Cette version complète du matériel d'apprentissage de l'IA à grand modèle a été téléchargée sur CSDN. Si vous en avez besoin, vos amis peuvent scanner le code QR de certification officielle CSDN ci-dessous sur WeChat pour l'obtenir gratuitement [.保证100%免费】

Le parcours d'apprentissage à l'ère des grands modèles d'IA : des bases à l'avant-garde, maîtrisez les compétences clés de l'intelligence artificielle !

Cette collection de 640 rapports couvre de nombreux aspects tels que la recherche théorique, la mise en œuvre technique et l'application industrielle de grands modèles d'IA. Que vous soyez un chercheur scientifique, un ingénieur ou un passionné intéressé par les grands modèles d'IA, cette collection de rapports vous fournira des informations et une inspiration précieuses.

Avec le développement rapide de la technologie de l’intelligence artificielle, les grands modèles d’IA sont devenus un sujet brûlant dans le domaine scientifique et technologique actuel. Ces modèles pré-entraînés à grande échelle, tels que GPT-3, BERT, XLNet, etc., changent notre compréhension de l'intelligence artificielle grâce à leurs puissantes capacités de compréhension du langage et de génération. Les livres PDF suivants sont de très bonnes ressources d’apprentissage.


En tant que personne ordinaire, entrer dans l’ère des grands modèles nécessite un apprentissage et une pratique continus pour améliorer continuellement ses compétences et son niveau cognitif. En même temps, il faut avoir un sens des responsabilités et une conscience éthique pour contribuer au développement sain de l’intelligence artificielle. .

Il se consacre à la recherche technologique depuis plus de trente ans, maîtrise divers langages tels que java, linux, javascript, php, css, etc., et a apporté de nombreuses contributions dans le domaine de l'open source. une station de documentation pour les développeurs pour partager certains problèmes de développement technologique pour référence future.

