2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Graafitietokantojen tai tietograafien käyttö suurissa mallisovelluksissa on tullut viime aikoina yhä suositummaksi. Kaavioilla on luonnollisia etuja erilaisten ja toisiinsa liittyvien tietojen esittämisessä ja tallentamisessa, ja ne voivat helposti kaapata monimutkaisia suhteita ja attribuutteja eri tietotyyppien välillä, mikä tarjoaa paremman kontekstin tai datatuen suurille malleille. Tässä artikkelissa tarkastellaan kaaviotietokantojen tai tietokaavioiden käyttöä suurissa mallisovelluksissa.
Tämä artikkeli on vain yksinkertainen johdanto ja kokemus.Sillä ei ole väliä, jos et tunne kaaviotietokantaa tai neo4j:tä, noudata vain tämän artikkelin ohjeita . Tämä artikkeli voi auttaa sinua ymmärtämään tietograafin soveltamismenetelmän RAG:ssa Kun sinulla on kokemusta, voit oppia käyttämään kaaviotietokantaa tarvittaessa.
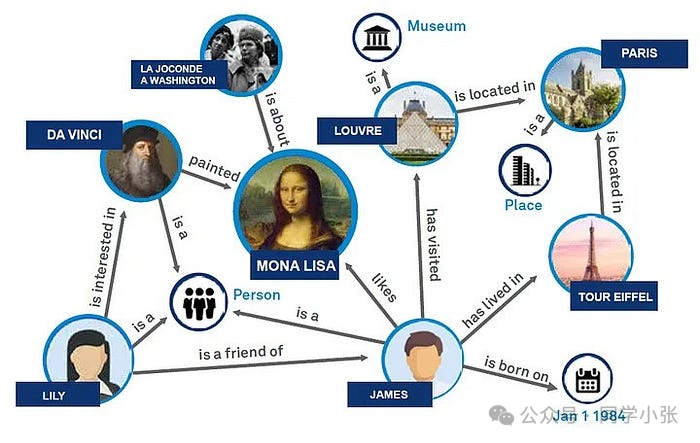
Tietograafi on jäsennelty semanttinen tietokanta, joka tallentaa ja edustaa entiteettejä (kuten ihmisiä, paikkoja, organisaatioita jne.) ja entiteettien välisiä suhteita (kuten henkilösuhteita, maantieteellisiä sijaintisuhteita jne.) graafien muodossa. Tietokaavioita käytetään usein parantamaan hakukoneiden semanttista ymmärrystä tarjoamalla monipuolisempaa tietoa ja tarkempia hakutuloksia.
Tietograafin tärkeimmät ominaisuudet ovat:
1. Entiteetti : Tietograafin perusyksikkö, joka edustaa objektia tai käsitettä todellisessa maailmassa.
2. Suhde: entiteettien välinen suhde, kuten "kuuluu", "sijaitsee", "luoja" jne.
3. Attribuutti: Yhteisön hallussa olevat kuvaavat tiedot, kuten henkilön ikä, sijainnin pituus- ja leveysaste jne.
4. Graafinen rakenne: Tietograafi järjestää tiedot graafin muotoon, mukaan lukien solmut (entiteetit) ja reunat (relaatiot).
5. *Semanttinen verkko: Tietograafia voidaan pitää semanttisena verkkona, jossa solmuilla ja reunoilla on semanttinen merkitys.
6. Päätelmä: Tietograafia voidaan käyttää päättelyyn, eli uuden tiedon johtamiseen tunnettujen entiteettien ja suhteiden kautta.
Tietokaavioita käytetään laajasti hakukoneoptimoinnissa (SEO), suositusjärjestelmissä, luonnollisen kielen käsittelyssä (NLP), tiedon louhinnassa ja muilla aloilla. Esimerkiksi Googlen Knowledge Graph, Wikidata, DBpedia jne. ovat kaikki hyvin tunnettuja esimerkkejä tietokaavioista.
Tiedon organisointimuotona tietograafin merkitys on tarjota tehokas ja intuitiivinen tapa esittää ja hallita monimutkaisia tietosuhteita. Se näyttää tiedot jäsennellyssä muodossa graafirakenteen solmujen ja reunojen kautta, parantaa datan semanttista ilmaisukykyä ja tekee entiteettien välisestä suhteesta selkeän ja selkeän. Tietokaaviot parantavat merkittävästi tiedonhaun tarkkuutta, erityisesti luonnollisen kielen käsittelyn alalla, jolloin koneet voivat paremmin ymmärtää monimutkaisia käyttäjien kyselyitä ja vastata niihin. Tietokaavioilla on keskeinen rooli älykkäissä sovelluksissa, kuten suositusjärjestelmissä, älykkäissä kysymyksiin vastaamisessa jne.
Tylsän johdannon jälkeen katsotaanpa RAG+-tietograafin tapausta ja toteutetaan se itse.
Seuraava tapaus on LangChainin virallisesta dokumentaatiosta: https://python.langchain.com/v0.1/docs/integrations/graphs/neo4j_cypher/#refresh-graph-schema-information
(1) Ensin sinun on asennettava graafitietokanta, tässä käytämme neo4j:tä.
python-asennuskomento:
pip install neo4j
(2) Rekisteröi virallinen tili, kirjaudu sisään ja luo tietokantaesiintymä. (Jos haluat käyttää sitä oppimiseen, valitse ilmainen.)
Kun olet luonut online-tietokannan ilmentymän, sivu on seuraava:
Voit nyt käyttää tätä tietokantaa koodissasi.
(1) Kun olet luonut tietokannan ilmentymän, sinun pitäisi saada linkki, käyttäjätunnus ja salasana. Vanha sääntö on laittaa se ympäristömuuttujaan ja ladata sitten ympäristömuuttuja Pythonin kautta:
neo4j_url = os.getenv('NEO4J_URI')
neo4j_username = os.getenv('NEO4J_USERNAME')
neo4j_password = os.getenv('NEO4J_PASSWORD')
(2) Linkkitietokanta
LangChain kapseloi neo4j-rajapinnan, ja meidän tarvitsee vain tuoda Neo4jGraph-luokka käyttääksemme sitä.
from langchain_community.graphs import Neo4jGraph
graph = Neo4jGraph(url=neo4j_url, username=neo4j_username, password=neo4j_password)
(3) Kysely ja täytä tiedot
Voit käyttää kyselyliittymää kyselyihin ja tulosten palauttamiseen. Kyselylauseen kieli on Cypher-kyselykieli.
result = graph.query(
"""
MERGE (m:Movie {name:"Top Gun", runtime: 120})
WITH m
UNWIND ["Tom Cruise", "Val Kilmer", "Anthony Edwards", "Meg Ryan"] AS actor
MERGE (a:Actor {name:actor})
MERGE (a)-[:ACTED_IN]->(m)
"""
)
print(result)
# 输出:[]
Yllä olevan koodin tulos on []。
(4) Päivitä kaavion arkkitehtoniset tiedot
graph.refresh_schema()
print(graph.schema)

Tuloksista skeema sisältää tietoja, kuten solmutyypit, attribuutit ja tyyppien väliset suhteet, ja se on graafin arkkitehtuuri.
Voimme myös kirjautua sisään neo4j-verkkosivulle nähdäksesi graafitietokantaan tallennetut tiedot:
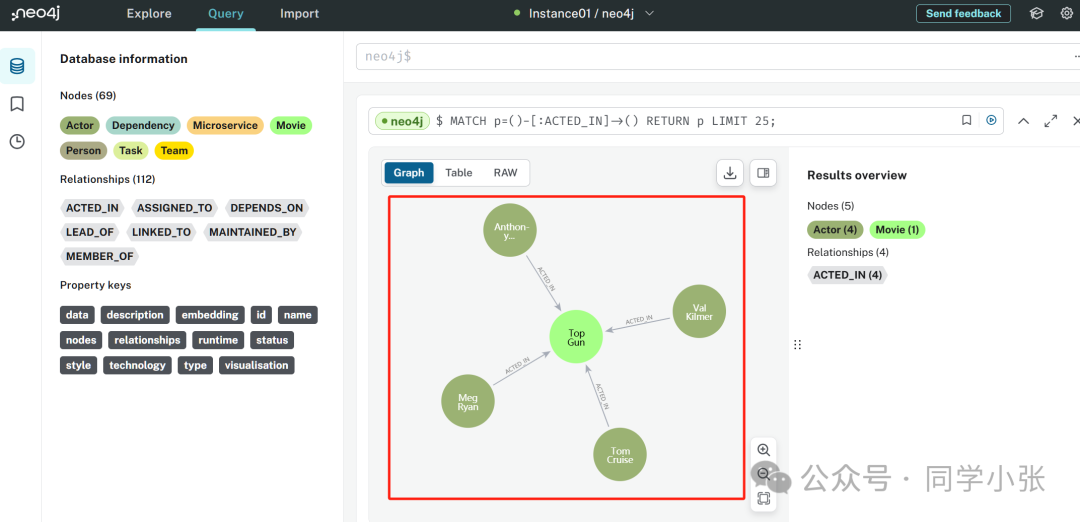
(5) Kun data on graafitietokannassa, voimme kysyä sitä seuraavaksi.
GraphCypherQAChain-luokka on kapseloitu LangChainiin, josta on helppo tehdä kyselyitä graafitietokannan avulla. Seuraava koodi:
chain = GraphCypherQAChain.from_llm(
ChatOpenAI(temperature=0), graph=graph, verbose=True
)
result = chain.invoke({"query": "Who played in Top Gun?"})
print(result)
Toteutusprosessi ja tulokset:

Ensin luonnollinen kieli (Kuka soitti Top Gunissa?) muunnetaan graafin kyselylauseeksi suuren mallin avulla, sitten kyselylause suoritetaan neo4j:n kautta, tulokset palautetaan ja lopuksi se muunnetaan luonnolliseksi kieleksi suuren mallin kautta. mallia ja tulosta käyttäjälle.
Yllä olevassa koodissa käytämme LangChainin GraphCypherQAChain-luokkaa, joka on LangChainin tarjoama graafitietokantakysely ja kysymys- ja vastausketju.Siinä on monia parametreja, jotka voidaan asettaa, kuten käyttöexclude_types Voit määrittää, mitkä solmutyypit tai -suhteet ohitetaan:
chain = GraphCypherQAChain.from_llm(
graph=graph,
cypher_llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo"),
qa_llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo-16k"),
verbose=True,
exclude_types=["Movie"],
)
Tulos on seuraavanlainen:
Node properties are the following:
Actor {name: STRING}
Relationship properties are the following:
The relationships are the following:
Saatavilla on monia samanlaisia parametreja, voit katsoa virallista dokumentaatiota: https://python.langchain.com/v0.1/docs/integrations/graphs/neo4j_cypher/#use-separate-llms-for-cypher-and- vastaus-sukupolvi
Seuraavassa on GraphCypherQAChainin suorituslähdekoodi. Katsotaanpa lyhyesti sen suoritusprosessia.
(1)cypher_generation_chain: Luonnollisen kielen muuntaminen graafisiksi kyselylauseiksi.
(2)extract_cypher: Poista kyselylause. Tämä johtuu siitä, että suuret mallit voivat palauttaa lisäkuvaustietoja ja ne on poistettava.
(3)cypher_query_corrector: Korjaa kyselylause.
(4)graph.query: Suorita kyselykäskyt, tee kyselykuvaajatietokanta ja hanki sisältöä
(5)self.qa_chain: Alkuperäisen kysymyksen ja kyselyn sisällön perusteella isoa mallia käytetään jälleen järjestämään vastaukset ja tulosteet käyttäjälle luonnollisella kielellä.
def _call( self,
inputs: Dict[str, Any],
run_manager: Optional[CallbackManagerForChainRun] = None,) -> Dict[str, Any]:
"""Generate Cypher statement, use it to look up in db and answer question."""
......
generated_cypher = self.cypher_generation_chain.run(
{"question": question, "schema": self.graph_schema}, callbacks=callbacks
)
# Extract Cypher code if it is wrapped in backticks
generated_cypher = extract_cypher(generated_cypher)
# Correct Cypher query if enabled
if self.cypher_query_corrector:
generated_cypher = self.cypher_query_corrector(generated_cypher)
......
# Retrieve and limit the number of results
# Generated Cypher be null if query corrector identifies invalid schema
if generated_cypher:
context = self.graph.query(generated_cypher)[: self.top_k]
else:
context = []
if self.return_direct:
final_result = context
else:
......
result = self.qa_chain(
{"question": question, "context": context},
callbacks=callbacks,
)
final_result = result[self.qa_chain.output_key]
chain_result: Dict[str, Any] = {self.output_key: final_result}
......
return chain_result
Innostuneena Internet-veteraanina päätin jakaa arvokkaan tekoälytietoni kaikkien kanssa. Mitä tulee siihen, kuinka paljon voit oppia, se riippuu oppimisen sinnikkyydestäsi ja kyvystäsi. Olen jakanut tärkeitä tekoälyn suuria mallimateriaaleja, kuten tekoälyn suuren mallin esittelyoppimisen ajatuskarttoja, korkealaatuisia tekoälyn suurten mallien oppimiskirjoja ja -oppaita, opetusvideoita, käytännön oppimista ja muita tallennettuja videoita ilmaiseksi.
Tämä laajan mallin tekoälyn oppimateriaalien täydellinen versio on ladattu CSDN:ään, jos tarvitset sitä, ystäväsi voivat skannata alla olevan virallisen CSDN-sertifioinnin QR-koodin WeChatissa saadakseen sen ilmaiseksi [.保证100%免费】

Oppimismatka suurten tekoälymallien aikakaudella: perusasioista huippuluokkaan, hallitse tekoälyn ydintaidot!

Tämä 640 raportin kokoelma kattaa monia näkökohtia, kuten teoreettisen tutkimuksen, teknisen toteutuksen ja suurten tekoälymallien teollisuuden soveltamisen. Olitpa tieteellinen tutkija, insinööri tai suurista tekoälymalleista kiinnostunut innokas, tämä raporttikokoelma tarjoaa sinulle arvokasta tietoa ja inspiraatiota.

Tekoälyteknologian nopean kehityksen myötä suurista tekoälymalleista on tullut kuuma aihe nykypäivän tieteen ja teknologian alalla. Nämä suuren mittakaavan esikoulutetut mallit, kuten GPT-3, BERT, XLNet jne., muuttavat käsitystämme tekoälystä voimakkailla kielen ymmärtämisellä ja generointiominaisuuksilla. Seuraavat PDF-kirjat ovat erittäin hyviä oppimisresursseja.


Tavallisena ihmisenä suurten mallien aikakauteen astuminen vaatii jatkuvaa oppimista ja harjoittelua oman taitojen ja kognitiivisen tason jatkuvaksi parantamiseksi. Samalla tarvitaan vastuuntuntoa ja eettistä tietoisuutta edistääkseen tekoälyn tervettä kehitystä. .

Hän on omistautunut teknologian tutkimukselle yli 30 vuoden ajan ja hallitsee useita kieliä, kuten java, linux, javascript, php, css jne. Hän on tehnyt paljon työtä avoimen lähdekoodin tässä Kehittäjän dokumentaatioasema, jossa voit ja teknologian kehittämisen ongelman myöhempää käyttöä varten

