
Mi informacion de contacto
Correo[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
El uso de bases de datos de gráficos o gráficos de conocimiento en aplicaciones de modelos grandes se ha vuelto cada vez más popular recientemente. Los gráficos tienen ventajas naturales a la hora de representar y almacenar información diversa e interrelacionada, y pueden capturar fácilmente relaciones y atributos complejos entre diferentes tipos de datos, proporcionando así un mejor contexto o soporte de datos para modelos grandes. En este artículo, veamos cómo utilizar bases de datos de gráficos o gráficos de conocimiento en aplicaciones de modelos grandes.
Este artículo es solo una simple introducción y experiencia.No importa si no conoces la base de datos de gráficos o neo4j, solo sigue los pasos de este artículo. . Este artículo puede ayudarlo a comprender el método de aplicación del gráfico de conocimiento en RAG. Una vez que tenga la experiencia, podrá aprender a usar la base de datos de gráficos más adelante si es necesario.
El gráfico de conocimiento es una base de conocimiento semántica estructurada que almacena y representa entidades (como personas, lugares, organizaciones, etc.) y relaciones entre entidades (como relaciones entre personas, relaciones de ubicación geográfica, etc.) en forma de gráficos. Los gráficos de conocimiento se utilizan a menudo para mejorar la comprensión semántica de los motores de búsqueda, proporcionando información más rica y resultados de búsqueda más precisos.
Las características principales del gráfico de conocimiento incluyen:
1. Entidad : La unidad básica en el gráfico de conocimiento, que representa un objeto o concepto en el mundo real.
2. Relación: La relación entre entidades, como "pertenece a", "está ubicado en", "creador", etc.
3. Atributo: Información descriptiva que posee la entidad, como la edad de la persona, la longitud y latitud del lugar, etc.
4. Estructura del gráfico: El gráfico de conocimiento organiza datos en forma de gráfico, incluidos nodos (entidades) y aristas (relaciones).
5. *Red Semántica: Un gráfico de conocimiento puede verse como una red semántica en la que los nodos y los bordes tienen significados semánticos.
6. Inferencia: Los gráficos de conocimiento se pueden utilizar para razonar, es decir, derivar nueva información a través de entidades y relaciones conocidas.
Los gráficos de conocimiento se utilizan ampliamente en la optimización de motores de búsqueda (SEO), sistemas de recomendación, procesamiento del lenguaje natural (NLP), minería de datos y otros campos. Por ejemplo, Knowledge Graph de Google, Wikidata, DBpedia, etc. son ejemplos bien conocidos de gráficos de conocimiento.
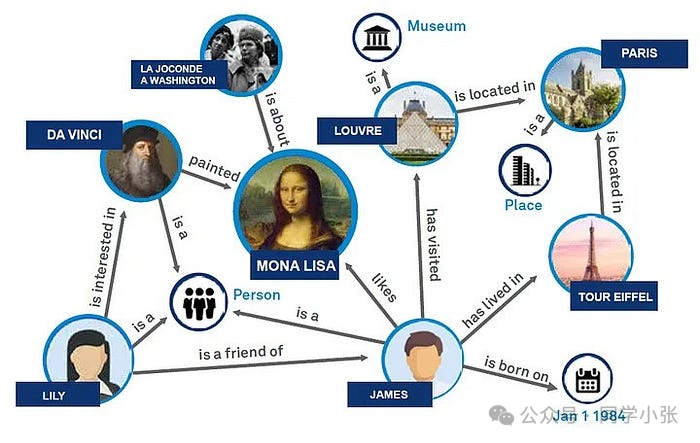
Como forma de organización de datos, la importancia del gráfico de conocimiento es proporcionar una forma eficiente e intuitiva de representar y gestionar relaciones de datos complejas. Muestra datos en forma estructurada a través de los nodos y bordes de la estructura del gráfico, mejora la capacidad de expresión semántica de los datos y hace que la relación entre entidades sea clara y clara. Los gráficos de conocimiento mejoran significativamente la precisión de la recuperación de información, especialmente en el campo del procesamiento del lenguaje natural, permitiendo que las máquinas comprendan y respondan mejor a consultas complejas de los usuarios. Los gráficos de conocimiento desempeñan un papel fundamental en las aplicaciones inteligentes, como los sistemas de recomendación, la respuesta inteligente a preguntas, etc.
Después de la aburrida introducción, echemos un vistazo al caso del gráfico de conocimiento RAG+ e implementémoslo nosotros mismos.
El siguiente caso es de la documentación oficial de LangChain: https://python.langchain.com/v0.1/docs/integrations/graphs/neo4j_cypher/#refresh-graph-schema-information
(1) Primero necesita instalar una base de datos gráfica, aquí usamos neo4j.
comando de instalación de Python:
pip install neo4j
(2) Registre una cuenta oficial, inicie sesión y cree una instancia de base de datos. (Si quieres usarlo para aprender, simplemente elige el gratuito).
Después de crear una instancia de base de datos en línea, la página es la siguiente:
Ahora puede utilizar esta base de datos en su código.
(1) Después de crear la instancia de la base de datos, debe obtener el enlace, el nombre de usuario y la contraseña de los datos. La regla anterior es colocarlos en la variable de entorno y luego cargar la variable de entorno a través de Python:
neo4j_url = os.getenv('NEO4J_URI')
neo4j_username = os.getenv('NEO4J_USERNAME')
neo4j_password = os.getenv('NEO4J_PASSWORD')
(2) Base de datos de enlaces
LangChain encapsula la interfaz neo4j y solo necesitamos importar la clase Neo4jGraph para usarla.
from langchain_community.graphs import Neo4jGraph
graph = Neo4jGraph(url=neo4j_url, username=neo4j_username, password=neo4j_password)
(3) Consultar y completar datos
Puede utilizar la interfaz de consulta para consultar y devolver resultados. El idioma de la declaración de consulta es el lenguaje de consulta Cypher.
result = graph.query(
"""
MERGE (m:Movie {name:"Top Gun", runtime: 120})
WITH m
UNWIND ["Tom Cruise", "Val Kilmer", "Anthony Edwards", "Meg Ryan"] AS actor
MERGE (a:Actor {name:actor})
MERGE (a)-[:ACTED_IN]->(m)
"""
)
print(result)
# 输出:[]
La salida del código anterior es []。
(4) Actualizar la información arquitectónica del gráfico.
graph.refresh_schema()
print(graph.schema)

A partir de los resultados, el esquema contiene información como tipos de nodos, atributos y relaciones entre tipos, y es la arquitectura del gráfico.
También podemos iniciar sesión en la página web de neo4j para ver los datos almacenados en la base de datos de gráficos:
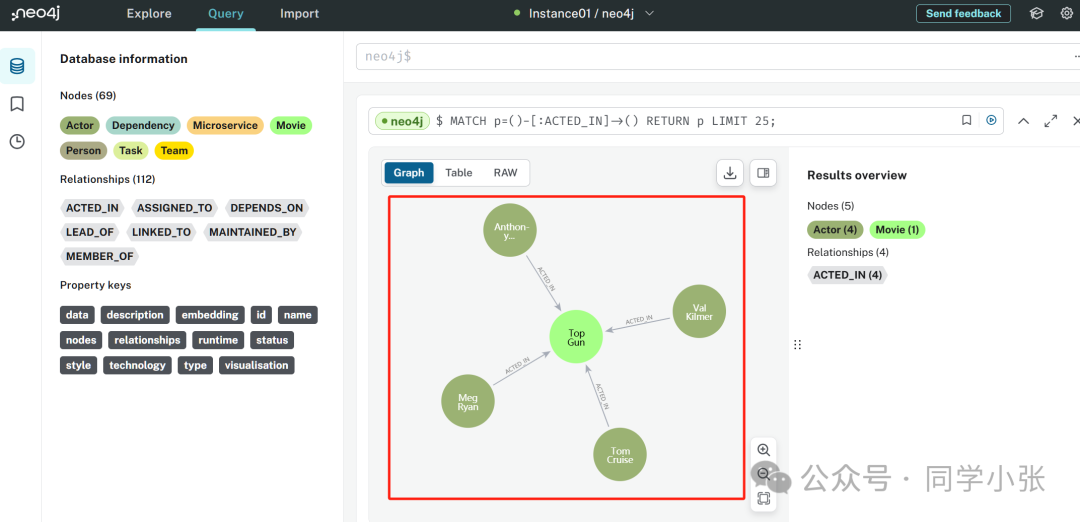
(5) Ahora que hay datos en la base de datos del gráfico, podemos consultarlos.
La clase GraphCypherQAChain está encapsulada en LangChain, que se puede consultar fácilmente utilizando la base de datos de gráficos. El siguiente código:
chain = GraphCypherQAChain.from_llm(
ChatOpenAI(temperature=0), graph=graph, verbose=True
)
result = chain.invoke({"query": "Who played in Top Gun?"})
print(result)
Proceso de ejecución y resultados:

Primero, el lenguaje natural (¿Quién jugó en Top Gun?) se convierte en una declaración de consulta gráfica a través de un modelo grande, luego la declaración de consulta se ejecuta a través de neo4j, se devuelven los resultados y finalmente se convierte a lenguaje natural a través del modelo grande. modelo y salida al usuario.
En el código anterior, utilizamos la clase GraphCypherQAChain de LangChain, que es la consulta de la base de datos de gráficos y la cadena de preguntas y respuestas proporcionada por LangChain.Tiene muchos parámetros que se pueden configurar, como el usoexclude_types Para establecer qué tipos de nodos o relaciones se ignoran:
chain = GraphCypherQAChain.from_llm(
graph=graph,
cypher_llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo"),
qa_llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo-16k"),
verbose=True,
exclude_types=["Movie"],
)
El resultado es similar al siguiente:
Node properties are the following:
Actor {name: STRING}
Relationship properties are the following:
The relationships are the following:
Hay muchos parámetros similares disponibles, puede consultar la documentación oficial: https://python.langchain.com/v0.1/docs/integrations/graphs/neo4j_cypher/#use-separate-llms-for-cypher-and- generación de respuestas
El siguiente es el código fuente de ejecución de GraphCypherQAChain. Echemos un vistazo breve a su proceso de ejecución.
(1)cypher_generation_chain: Conversión de lenguaje natural a declaraciones de consulta gráficas.
(2)extract_cypher: Elimine la declaración de consulta. Esto se debe a que los modelos grandes pueden devolver información de descripción adicional y es necesario eliminarla.
(3)cypher_query_corrector: Corrija la declaración de la consulta.
(4)graph.query: Ejecute declaraciones de consulta, consulte la base de datos de gráficos y obtenga contenido
(5)self.qa_chain: Según el contenido de la pregunta y consulta originales, el modelo grande se utiliza nuevamente para organizar las respuestas y enviarlas al usuario en lenguaje natural.
def _call( self,
inputs: Dict[str, Any],
run_manager: Optional[CallbackManagerForChainRun] = None,) -> Dict[str, Any]:
"""Generate Cypher statement, use it to look up in db and answer question."""
......
generated_cypher = self.cypher_generation_chain.run(
{"question": question, "schema": self.graph_schema}, callbacks=callbacks
)
# Extract Cypher code if it is wrapped in backticks
generated_cypher = extract_cypher(generated_cypher)
# Correct Cypher query if enabled
if self.cypher_query_corrector:
generated_cypher = self.cypher_query_corrector(generated_cypher)
......
# Retrieve and limit the number of results
# Generated Cypher be null if query corrector identifies invalid schema
if generated_cypher:
context = self.graph.query(generated_cypher)[: self.top_k]
else:
context = []
if self.return_direct:
final_result = context
else:
......
result = self.qa_chain(
{"question": question, "context": context},
callbacks=callbacks,
)
final_result = result[self.qa_chain.output_key]
chain_result: Dict[str, Any] = {self.output_key: final_result}
......
return chain_result
Como entusiasta veterano de Internet, decidí compartir mi valioso conocimiento sobre IA con todos. En cuanto a cuánto puedes aprender, depende de tu perseverancia y capacidad de estudio. He compartido importantes materiales de modelos grandes de IA, incluidos mapas mentales de aprendizaje introductorio de modelos grandes de IA, libros y manuales de aprendizaje de modelos grandes de IA de alta calidad, tutoriales en video, aprendizaje práctico y otros videos grabados de forma gratuita.
Esta versión completa de los materiales de aprendizaje de IA de modelo grande se ha subido a CSDN. Si la necesita, sus amigos pueden escanear el código QR de certificación oficial de CSDN a continuación en WeChat para obtenerlo de forma gratuita.保证100%免费】

El viaje de aprendizaje en la era de los grandes modelos de IA: desde lo básico hasta lo más vanguardista, ¡domine las habilidades básicas de la inteligencia artificial!

Esta colección de 640 informes cubre muchos aspectos, como la investigación teórica, la implementación técnica y la aplicación industrial de grandes modelos de IA. Si es un investigador científico, un ingeniero o un entusiasta interesado en los grandes modelos de IA, esta colección de informes le proporcionará información valiosa e inspiración.

Con el rápido desarrollo de la tecnología de inteligencia artificial, los grandes modelos de IA se han convertido en un tema candente en el campo científico y tecnológico actual. Estos modelos preentrenados a gran escala, como GPT-3, BERT, XLNet, etc., están cambiando nuestra comprensión de la inteligencia artificial con sus poderosas capacidades de generación y comprensión del lenguaje. Los siguientes libros en PDF son muy buenos recursos de aprendizaje.


Como persona común, ingresar a la era de los grandes modelos requiere aprendizaje y práctica continuos para mejorar continuamente las habilidades y el nivel cognitivo. Al mismo tiempo, es necesario tener un sentido de responsabilidad y conciencia ética para contribuir al desarrollo saludable de la inteligencia artificial. .

Se ha dedicado a la investigación de tecnología durante más de 30 años y domina varios lenguajes como java, linux, javascript, php, css, etc. Ha realizado muchas contribuciones en el campo del código abierto. Estación de documentación para desarrolladores para compartir algunos problemas en el desarrollo de tecnología para referencia futura.

Correo[email protected]