
informasi kontak saya
Surat[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Penggunaan database grafik atau grafik pengetahuan dalam aplikasi model besar menjadi semakin populer akhir-akhir ini. Grafik memiliki keunggulan alami dalam mewakili dan menyimpan informasi yang beragam dan saling terkait, dan dapat dengan mudah menangkap hubungan dan atribut yang kompleks antara tipe data yang berbeda, sehingga memberikan dukungan konteks atau data yang lebih baik untuk model besar. Pada artikel ini, mari kita lihat cara menggunakan database grafik atau grafik pengetahuan dalam aplikasi model besar.
Artikel ini hanyalah pengenalan dan pengalaman sederhana.Tidak masalah jika Anda tidak mengetahui database grafik atau neo4j, cukup ikuti langkah-langkah dalam artikel ini . Artikel ini dapat membantu Anda memahami metode penerapan grafik pengetahuan di RAG. Setelah Anda memiliki pengalaman, Anda dapat mempelajari cara menggunakan database grafik nanti jika perlu.
Grafik pengetahuan adalah basis pengetahuan semantik terstruktur yang menyimpan dan mewakili entitas (seperti orang, tempat, organisasi, dll.) dan hubungan antar entitas (seperti hubungan orang, hubungan lokasi geografis, dll.) dalam bentuk grafik. Grafik pengetahuan sering kali digunakan untuk meningkatkan pemahaman semantik mesin pencari, memberikan informasi yang lebih kaya dan hasil pencarian yang lebih akurat.
Fitur utama grafik pengetahuan meliputi:
1. Entitas : Unit dasar dalam grafik pengetahuan, yang mewakili suatu objek atau konsep di dunia nyata.
2. Hubungan: Hubungan antar entitas, seperti "milik", "terletak di", "pencipta", dll.
3. Atribut: Informasi deskriptif yang dimiliki oleh entitas, seperti usia seseorang, garis bujur dan lintang lokasi, dll.
4. Struktur Grafik: Grafik pengetahuan mengatur data dalam bentuk grafik, termasuk node (entitas) dan edge (hubungan).
5. *Jaringan Semantik: Grafik pengetahuan dapat dilihat sebagai jaringan semantik di mana node dan tepinya memiliki makna semantik.
6. Inferensi: Grafik pengetahuan dapat digunakan untuk penalaran, yaitu memperoleh informasi baru melalui entitas dan hubungan yang diketahui.
Grafik pengetahuan banyak digunakan dalam optimasi mesin pencari (SEO), sistem rekomendasi, pemrosesan bahasa alami (NLP), penambangan data dan bidang lainnya. Misalnya, Grafik Pengetahuan Google, Wikidata, DBpedia, dll. adalah contoh grafik pengetahuan yang terkenal.
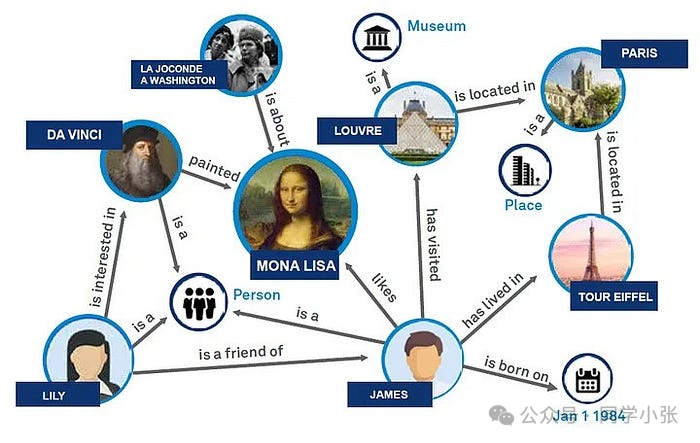
Sebagai bentuk organisasi data, pentingnya grafik pengetahuan adalah menyediakan cara yang efisien dan intuitif untuk merepresentasikan dan mengelola hubungan data yang kompleks. Ini menampilkan data dalam bentuk terstruktur melalui node dan tepi struktur grafik, meningkatkan kemampuan ekspresi semantik data, dan membuat hubungan antar entitas menjadi jelas dan jelas. Grafik pengetahuan secara signifikan meningkatkan keakuratan pengambilan informasi, terutama di bidang pemrosesan bahasa alami, memungkinkan mesin untuk lebih memahami dan merespons pertanyaan pengguna yang kompleks. Grafik pengetahuan memainkan peran inti dalam aplikasi cerdas, seperti sistem rekomendasi, menjawab pertanyaan cerdas, dll.
Setelah pengenalan yang membosankan, mari kita lihat kasus grafik pengetahuan RAG+ dan implementasinya sendiri.
Kasus berikut ini berasal dari dokumentasi resmi LangChain: https://python.langchain.com/v0.1/docs/integrations/graphs/neo4j_cypher/#refresh-graph-schema-information
(1) Pertama Anda perlu menginstal database grafik, di sini kami menggunakan neo4j.
perintah instalasi python:
pip install neo4j
(2) Daftarkan akun resmi, masuk, dan buat instance database. (Jika ingin digunakan untuk belajar, pilih saja yang gratis.)
Setelah membuat instance database online, halamannya adalah sebagai berikut:
Anda sekarang dapat menggunakan database ini dalam kode Anda.
(1) Setelah membuat instance database, Anda harus mendapatkan link, nama pengguna dan kata sandi dari data tersebut. Aturan lama adalah memasukkannya ke dalam variabel lingkungan, dan kemudian memuat variabel lingkungan melalui Python:
neo4j_url = os.getenv('NEO4J_URI')
neo4j_username = os.getenv('NEO4J_USERNAME')
neo4j_password = os.getenv('NEO4J_PASSWORD')
(2) Tautan basis data
LangChain merangkum antarmuka neo4j, dan kita hanya perlu mengimpor kelas Neo4jGraph untuk menggunakannya.
from langchain_community.graphs import Neo4jGraph
graph = Neo4jGraph(url=neo4j_url, username=neo4j_username, password=neo4j_password)
(3) Kueri dan isi data
Anda dapat menggunakan antarmuka kueri untuk menanyakan dan mengembalikan hasil. Bahasa pernyataan kueri adalah bahasa kueri Cypher.
result = graph.query(
"""
MERGE (m:Movie {name:"Top Gun", runtime: 120})
WITH m
UNWIND ["Tom Cruise", "Val Kilmer", "Anthony Edwards", "Meg Ryan"] AS actor
MERGE (a:Actor {name:actor})
MERGE (a)-[:ACTED_IN]->(m)
"""
)
print(result)
# 输出:[]
Output dari kode di atas adalah []。
(4) Segarkan informasi arsitektur grafik
graph.refresh_schema()
print(graph.schema)

Dari hasilnya, skema berisi informasi seperti tipe node, atribut, dan hubungan antar tipe, serta merupakan arsitektur grafik.
Kita juga dapat masuk ke halaman web neo4j untuk melihat data yang disimpan dalam database grafik:
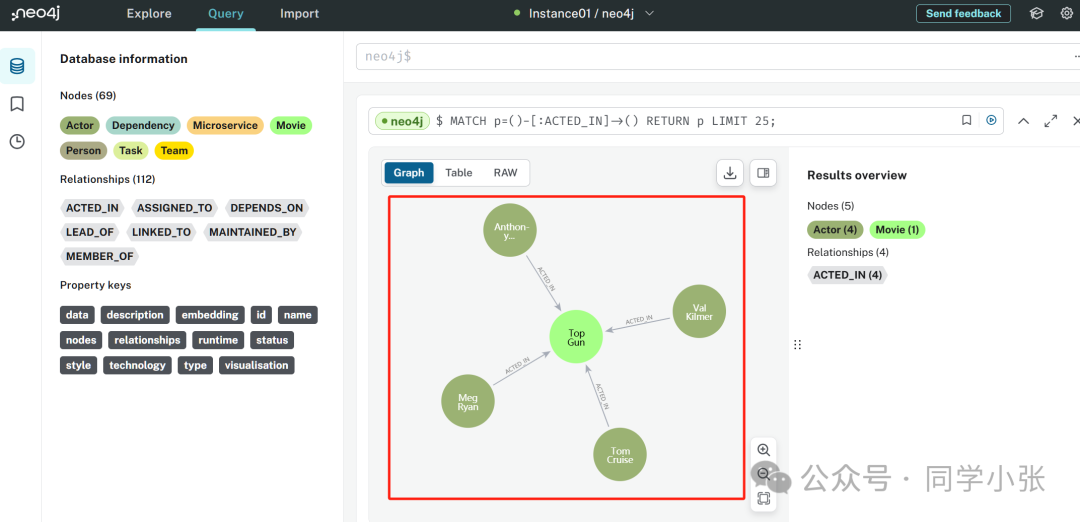
(5) Dengan data dalam database grafik, selanjutnya kita dapat menanyakannya.
Kelas GraphCypherQAChain dienkapsulasi dalam LangChain, yang dapat dengan mudah ditanyakan menggunakan database grafik. Kode berikut:
chain = GraphCypherQAChain.from_llm(
ChatOpenAI(temperature=0), graph=graph, verbose=True
)
result = chain.invoke({"query": "Who played in Top Gun?"})
print(result)
Proses dan hasil eksekusi:

Pertama, bahasa alami (Siapa yang bermain di Top Gun?) diubah menjadi pernyataan kueri grafik melalui model besar, kemudian pernyataan kueri dijalankan melalui neo4j, hasilnya dikembalikan, dan terakhir diubah menjadi bahasa alami melalui model besar model dan output ke pengguna.
Dalam kode di atas, kami menggunakan kelas GraphCypherQAChain LangChain, yang merupakan kueri database grafik serta rantai tanya jawab yang disediakan oleh LangChain.Ini memiliki banyak parameter yang dapat diatur, seperti penggunaanexclude_types Untuk mengatur tipe atau hubungan simpul mana yang diabaikan:
chain = GraphCypherQAChain.from_llm(
graph=graph,
cypher_llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo"),
qa_llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo-16k"),
verbose=True,
exclude_types=["Movie"],
)
Outputnya mirip dengan berikut ini:
Node properties are the following:
Actor {name: STRING}
Relationship properties are the following:
The relationships are the following:
Ada banyak parameter serupa yang tersedia, Anda dapat merujuk ke dokumentasi resmi: https://python.langchain.com/v0.1/docs/integrations/graphs/neo4j_cypher/#use-separate-llms-for-cypher-and- generasi jawaban
Berikut ini adalah kode sumber eksekusi GraphCypherQAChain. Mari kita lihat sekilas proses eksekusinya.
(1)cypher_generation_chain: Konversi bahasa alami ke pernyataan kueri grafik.
(2)extract_cypher: Keluarkan pernyataan kueri. Ini karena model besar mungkin mengembalikan beberapa informasi deskripsi tambahan dan perlu dihapus.
(3)cypher_query_corrector: Memperbaiki pernyataan kueri.
(4)graph.query: Jalankan pernyataan kueri, database grafik kueri, dan dapatkan konten
(5)self.qa_chain: Berdasarkan konten pertanyaan dan kueri awal, model besar digunakan lagi untuk mengatur jawaban dan keluaran kepada pengguna dalam bahasa alami.
def _call( self,
inputs: Dict[str, Any],
run_manager: Optional[CallbackManagerForChainRun] = None,) -> Dict[str, Any]:
"""Generate Cypher statement, use it to look up in db and answer question."""
......
generated_cypher = self.cypher_generation_chain.run(
{"question": question, "schema": self.graph_schema}, callbacks=callbacks
)
# Extract Cypher code if it is wrapped in backticks
generated_cypher = extract_cypher(generated_cypher)
# Correct Cypher query if enabled
if self.cypher_query_corrector:
generated_cypher = self.cypher_query_corrector(generated_cypher)
......
# Retrieve and limit the number of results
# Generated Cypher be null if query corrector identifies invalid schema
if generated_cypher:
context = self.graph.query(generated_cypher)[: self.top_k]
else:
context = []
if self.return_direct:
final_result = context
else:
......
result = self.qa_chain(
{"question": question, "context": context},
callbacks=callbacks,
)
final_result = result[self.qa_chain.output_key]
chain_result: Dict[str, Any] = {self.output_key: final_result}
......
return chain_result
Sebagai seorang veteran Internet yang antusias, saya memutuskan untuk berbagi pengetahuan AI saya yang berharga dengan semua orang. Adapun seberapa banyak Anda dapat belajar, itu tergantung pada ketekunan dan kemampuan belajar Anda. Saya telah membagikan materi penting model besar AI termasuk peta pikiran pembelajaran pengantar model besar AI, buku dan manual pembelajaran model besar AI berkualitas tinggi, tutorial video, pembelajaran praktis, dan rekaman video lainnya secara gratis.
Materi pembelajaran AI model besar versi lengkap ini telah diunggah ke CSDN, jika Anda membutuhkannya, teman-teman dapat memindai kode QR sertifikasi resmi CSDN di bawah ini di WeChat untuk mendapatkannya secara gratis [保证100%免费】

Perjalanan pembelajaran di era model AI besar: dari dasar hingga mutakhir, kuasai keterampilan inti kecerdasan buatan!

Kumpulan 640 laporan ini mencakup banyak aspek seperti penelitian teoretis, implementasi teknis, dan penerapan model AI besar dalam industri. Baik Anda seorang peneliti ilmiah, insinyur, atau penggemar yang tertarik dengan model AI besar, kumpulan laporan ini akan memberi Anda informasi dan inspirasi berharga.

Dengan pesatnya perkembangan teknologi kecerdasan buatan, model besar AI telah menjadi topik hangat di bidang ilmu pengetahuan dan teknologi saat ini. Model terlatih berskala besar ini, seperti GPT-3, BERT, XLNet, dll., mengubah pemahaman kita tentang kecerdasan buatan dengan pemahaman bahasa dan kemampuan generasi yang kuat. Buku-buku PDF berikut adalah sumber belajar yang sangat bagus.


Sebagai manusia biasa, memasuki era model besar memerlukan pembelajaran dan latihan terus menerus untuk terus meningkatkan keterampilan dan tingkat kognitif seseorang, pada saat yang sama, seseorang perlu memiliki rasa tanggung jawab dan kesadaran etis untuk berkontribusi pada perkembangan kecerdasan buatan yang sehat .

Ia telah mengabdikan dirinya untuk meneliti teknologi selama lebih dari tiga puluh tahun, dan mahir dalam berbagai bahasa seperti java, linux, javascript, php, css, dll, dan telah memberikan banyak kontribusi di bidang open source yang telah ia dirikan stasiun dokumentasi pengembang untuk berbagi beberapa masalah dalam pengembangan teknologi untuk referensi di masa mendatang

Surat[email protected]