
minhas informações de contato
Correspondência[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
O uso de bancos de dados gráficos ou gráficos de conhecimento em aplicações de grandes modelos tornou-se cada vez mais popular recentemente. Os gráficos têm vantagens naturais na representação e armazenamento de informações diversas e inter-relacionadas e podem capturar facilmente relacionamentos e atributos complexos entre diferentes tipos de dados, fornecendo assim melhor contexto ou suporte de dados para grandes modelos. Neste artigo, vamos dar uma olhada em como usar bancos de dados gráficos ou gráficos de conhecimento em aplicativos de modelos grandes.
Este artigo é apenas uma simples introdução e experiência.Não importa se você não conhece banco de dados gráfico ou neo4j, basta seguir os passos deste artigo . Este artigo pode ajudá-lo a entender o método de aplicação do gráfico de conhecimento no RAG. Depois de adquirir a experiência, você poderá aprender como usar o banco de dados gráfico posteriormente, se necessário.
O gráfico de conhecimento é uma base de conhecimento semântica estruturada que armazena e representa entidades (como pessoas, lugares, organizações, etc.) e relacionamentos entre entidades (como relacionamentos pessoais, relacionamentos de localização geográfica, etc.) na forma de gráficos. Os gráficos de conhecimento são frequentemente usados para aprimorar a compreensão semântica dos mecanismos de pesquisa, fornecendo informações mais ricas e resultados de pesquisa mais precisos.
Os principais recursos do gráfico de conhecimento incluem:
1. Entidade : A unidade básica no gráfico de conhecimento, representando um objeto ou conceito no mundo real.
2. Relacionamento: A relação entre entidades, como “pertence a”, “está localizado em”, “criador”, etc.
3. Atributo: Informações descritivas possuídas pela entidade, como a idade da pessoa, a longitude e latitude do local, etc.
4. Estrutura do gráfico: O gráfico de conhecimento organiza os dados na forma de um gráfico, incluindo nós (entidades) e arestas (relacionamentos).
5. *Rede Semântica: Um gráfico de conhecimento pode ser visto como uma rede semântica na qual nós e arestas têm significados semânticos.
6. Inferência: Os gráficos de conhecimento podem ser usados para raciocínio, ou seja, derivar novas informações por meio de entidades e relacionamentos conhecidos.
Os gráficos de conhecimento são amplamente utilizados em otimização de mecanismos de pesquisa (SEO), sistemas de recomendação, processamento de linguagem natural (PNL), mineração de dados e outros campos. Por exemplo, Knowledge Graph do Google, Wikidata, DBpedia, etc. são exemplos bem conhecidos de gráficos de conhecimento.
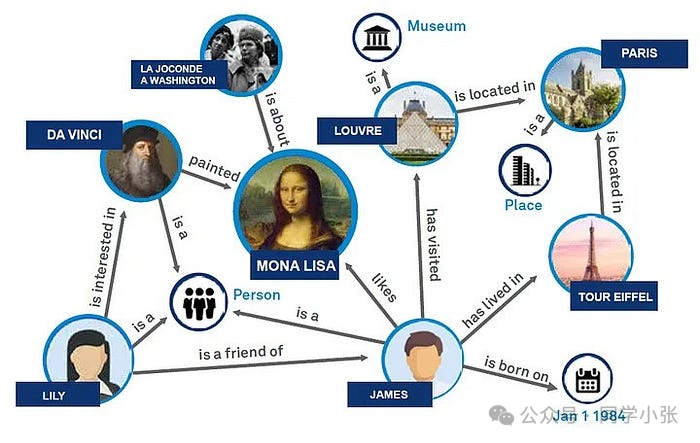
Como forma de organização de dados, a importância do gráfico de conhecimento é fornecer uma maneira eficiente e intuitiva de representar e gerenciar relacionamentos de dados complexos. Ele exibe os dados de forma estruturada por meio dos nós e bordas da estrutura do gráfico, aprimora a capacidade de expressão semântica dos dados e torna o relacionamento entre as entidades claro e claro. Os gráficos de conhecimento melhoram significativamente a precisão da recuperação de informações, especialmente na área de processamento de linguagem natural, permitindo que as máquinas compreendam e respondam melhor às consultas complexas dos usuários. Os gráficos de conhecimento desempenham um papel fundamental em aplicações inteligentes, como sistemas de recomendação, respostas inteligentes a perguntas, etc.
Após a enfadonha introdução, vamos dar uma olhada no caso do gráfico de conhecimento RAG+ e implementá-lo nós mesmos.
O seguinte caso é da documentação oficial do LangChain: https://python.langchain.com/v0.1/docs/integrations/graphs/neo4j_cypher/#refresh-graph-schema-information
(1) Primeiro você precisa instalar um banco de dados gráfico, aqui usamos neo4j.
comando de instalação do python:
pip install neo4j
(2) Registre uma conta oficial, faça login e crie uma instância de banco de dados. (Se você quiser usá-lo para aprender, basta escolher o gratuito.)
Depois de criar uma instância de banco de dados online, a página é a seguinte:
Agora você pode usar esse banco de dados em seu código.
(1) Após criar a instância do banco de dados, você deve obter o link, nome de usuário e senha dos dados. A regra antiga é colocá-los na variável de ambiente e, em seguida, carregar a variável de ambiente através do Python:
neo4j_url = os.getenv('NEO4J_URI')
neo4j_username = os.getenv('NEO4J_USERNAME')
neo4j_password = os.getenv('NEO4J_PASSWORD')
(2) Banco de dados de links
LangChain encapsula a interface neo4j e só precisamos importar a classe Neo4jGraph para usá-la.
from langchain_community.graphs import Neo4jGraph
graph = Neo4jGraph(url=neo4j_url, username=neo4j_username, password=neo4j_password)
(3) Consultar e preencher dados
Você pode usar a interface de consulta para consultar e retornar resultados. A linguagem da instrução de consulta é a linguagem de consulta Cypher.
result = graph.query(
"""
MERGE (m:Movie {name:"Top Gun", runtime: 120})
WITH m
UNWIND ["Tom Cruise", "Val Kilmer", "Anthony Edwards", "Meg Ryan"] AS actor
MERGE (a:Actor {name:actor})
MERGE (a)-[:ACTED_IN]->(m)
"""
)
print(result)
# 输出:[]
A saída do código acima é []。
(4) Atualize as informações arquitetônicas do gráfico
graph.refresh_schema()
print(graph.schema)

A partir dos resultados, o esquema contém informações como tipos de nós, atributos e relacionamentos entre tipos e é a arquitetura do gráfico.
Também podemos fazer login na página da web do neo4j para visualizar os dados armazenados no banco de dados gráfico:
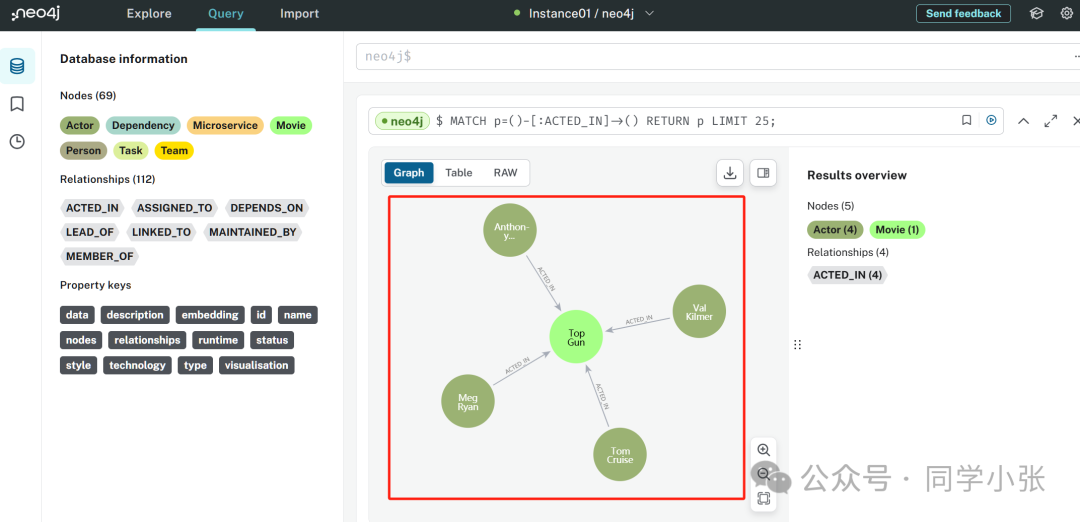
(5) Agora que existem dados no banco de dados gráfico, podemos consultá-los.
A classe GraphCypherQAChain é encapsulada em LangChain, que pode ser facilmente consultada usando o banco de dados gráfico. O seguinte código:
chain = GraphCypherQAChain.from_llm(
ChatOpenAI(temperature=0), graph=graph, verbose=True
)
result = chain.invoke({"query": "Who played in Top Gun?"})
print(result)
Processo de execução e resultados:

Primeiro, a linguagem natural (Quem jogou Top Gun?) É convertida em uma instrução de consulta gráfica por meio de um modelo grande, depois a instrução de consulta é executada por meio do neo4j, os resultados são retornados e, finalmente, é convertida em linguagem natural por meio do grande modelo e saída para o usuário.
No código acima, usamos a classe GraphCypherQAChain do LangChain, que é a consulta do banco de dados gráfico e a cadeia de perguntas e respostas fornecida pelo LangChain.Possui muitos parâmetros que podem ser definidos, como usarexclude_types Para definir quais tipos de nós ou relacionamentos serão ignorados:
chain = GraphCypherQAChain.from_llm(
graph=graph,
cypher_llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo"),
qa_llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo-16k"),
verbose=True,
exclude_types=["Movie"],
)
A saída é semelhante à seguinte:
Node properties are the following:
Actor {name: STRING}
Relationship properties are the following:
The relationships are the following:
Existem muitos parâmetros semelhantes disponíveis, você pode consultar a documentação oficial: https://python.langchain.com/v0.1/docs/integrations/graphs/neo4j_cypher/#use-separate-llms-for-cypher-and- geração de resposta
A seguir está o código-fonte de execução do GraphCypherQAChain. Vamos dar uma breve olhada em seu processo de execução.
(1)cypher_generation_chain: Conversão de linguagem natural em instruções de consulta gráfica.
(2)extract_cypher: retire a instrução de consulta. Isso ocorre porque modelos grandes podem retornar algumas informações de descrição adicionais e precisam ser removidos.
(3)cypher_query_corrector: corrija a instrução da consulta.
(4)graph.query: Execute instruções de consulta, consulte banco de dados gráfico e obtenha conteúdo
(5)self.qa_chain: com base no conteúdo da pergunta e consulta originais, o modelo grande é novamente usado para organizar as respostas e a saída para o usuário em linguagem natural.
def _call( self,
inputs: Dict[str, Any],
run_manager: Optional[CallbackManagerForChainRun] = None,) -> Dict[str, Any]:
"""Generate Cypher statement, use it to look up in db and answer question."""
......
generated_cypher = self.cypher_generation_chain.run(
{"question": question, "schema": self.graph_schema}, callbacks=callbacks
)
# Extract Cypher code if it is wrapped in backticks
generated_cypher = extract_cypher(generated_cypher)
# Correct Cypher query if enabled
if self.cypher_query_corrector:
generated_cypher = self.cypher_query_corrector(generated_cypher)
......
# Retrieve and limit the number of results
# Generated Cypher be null if query corrector identifies invalid schema
if generated_cypher:
context = self.graph.query(generated_cypher)[: self.top_k]
else:
context = []
if self.return_direct:
final_result = context
else:
......
result = self.qa_chain(
{"question": question, "context": context},
callbacks=callbacks,
)
final_result = result[self.qa_chain.output_key]
chain_result: Dict[str, Any] = {self.output_key: final_result}
......
return chain_result
Como um entusiasta veterano da Internet, decidi compartilhar meu valioso conhecimento sobre IA com todos. Quanto ao quanto você pode aprender, depende da sua perseverança e habilidade no estudo. Eu compartilhei materiais importantes de modelos grandes de IA, incluindo mapas mentais introdutórios de aprendizagem de modelos grandes de IA, livros e manuais de aprendizagem de modelos grandes de IA de alta qualidade, tutoriais em vídeo, aprendizado prático e outros vídeos gravados gratuitamente.
Esta versão completa de materiais de aprendizagem de IA de modelo grande foi carregada no CSDN. Se você precisar, os amigos podem escanear o código QR de certificação oficial da CSDN abaixo no WeChat para obtê-lo gratuitamente [.保证100%免费】

A jornada de aprendizagem na era dos grandes modelos de IA: do básico ao de ponta, domine as habilidades básicas da inteligência artificial!

Esta coleção de 640 relatórios cobre muitos aspectos, como pesquisa teórica, implementação técnica e aplicação industrial de grandes modelos de IA. Quer você seja um pesquisador científico, um engenheiro ou um entusiasta interessado em grandes modelos de IA, esta coleção de relatórios fornecerá informações e inspiração valiosas.

Com o rápido desenvolvimento da tecnologia de inteligência artificial, os grandes modelos de IA tornaram-se um tema quente no campo científico e tecnológico atual. Esses modelos pré-treinados em grande escala, como GPT-3, BERT, XLNet, etc., estão mudando nossa compreensão da inteligência artificial com seus poderosos recursos de compreensão e geração de linguagem. Os seguintes livros em PDF são recursos de aprendizagem muito bons.


Como pessoa comum, entrar na era dos grandes modelos exige aprendizado e prática contínuos para melhorar continuamente as habilidades e o nível cognitivo. Ao mesmo tempo, é preciso ter senso de responsabilidade e consciência ética para contribuir para o desenvolvimento saudável da inteligência artificial. .

Ele se dedica à pesquisa de tecnologia há mais de 30 anos e é proficiente em diversas linguagens como java, linux, javascript, php, css, etc. estação de documentação do desenvolvedor para compartilhar alguns problemas no desenvolvimento de tecnologia para referência futura.

Correspondência[email protected]