
내 연락처 정보
우편메소피아@프로톤메일.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
최근 대규모 모델 애플리케이션에서 그래프 데이터베이스나 지식 그래프를 사용하는 것이 점점 더 대중화되고 있습니다. 그래프는 다양하고 상호 연관된 정보를 표현하고 저장하는 데 자연스러운 이점을 가지며, 다양한 데이터 유형 간의 복잡한 관계와 속성을 쉽게 캡처할 수 있으므로 대규모 모델에 대한 컨텍스트 또는 데이터 지원을 더 잘 제공할 수 있습니다. 이번 글에서는 대규모 모델 애플리케이션에서 그래프 데이터베이스나 지식 그래프를 사용하는 방법을 살펴보겠습니다.
이 글은 단순한 소개와 경험일 뿐입니다.그래프 데이터베이스나 neo4j를 모르더라도 상관없습니다. 이 글의 단계를 따르세요. . 이 기사는 RAG의 지식 그래프 적용 방법을 이해하는 데 도움이 될 수 있습니다. 경험이 있으면 나중에 필요할 때 그래프 데이터베이스를 사용하는 방법을 배울 수 있습니다.
지식 그래프는 개체(사람, 장소, 조직 등)와 개체 간의 관계(사람 관계, 지리적 위치 관계 등)를 그래프 형태로 저장하고 표현하는 구조화된 의미론적 지식 베이스이다. 지식 그래프는 검색 엔진의 의미론적 이해를 강화하여 더 풍부한 정보와 더 정확한 검색 결과를 제공하는 데 자주 사용됩니다.
지식 그래프의 주요 기능은 다음과 같습니다.
1. 실체 : 현실 세계의 사물이나 개념을 나타내는 지식 그래프의 기본 단위입니다.
2. 관계: '속함', '~에 위치함', '작성자' 등과 같은 개체 간의 관계입니다.
3. 속성: 개인의 나이, 해당 위치의 경도, 위도 등 해당 개체가 보유하고 있는 설명 정보입니다.
4. 그래프 구조: 지식 그래프는 노드(엔티티)와 에지(관계)를 포함하여 데이터를 그래프 형태로 구성합니다.
5. *의미론적 네트워크: 지식 그래프는 노드와 에지가 의미론적 의미를 갖는 의미망으로 볼 수 있다.
6. 추론: 지식 그래프는 추론, 즉 알려진 개체와 관계를 통해 새로운 정보를 도출하는 데 사용될 수 있습니다.
지식 그래프는 검색 엔진 최적화(SEO), 추천 시스템, 자연어 처리(NLP), 데이터 마이닝 및 기타 분야에서 널리 사용됩니다. 예를 들어 Google의 Knowledge Graph, Wikidata, DBpedia 등은 모두 잘 알려진 지식 그래프의 예입니다.
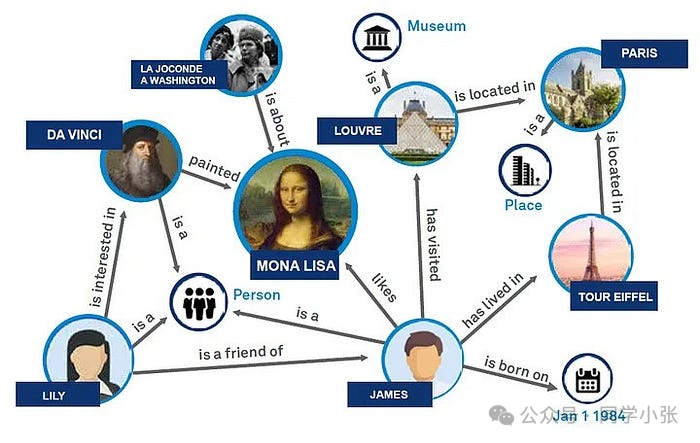
데이터 구성의 한 형태로서 지식 그래프의 중요성은 복잡한 데이터 관계를 효율적이고 직관적으로 표현하고 관리할 수 있는 방법을 제공하는 것입니다. 그래프 구조의 노드와 엣지를 통해 데이터를 구조화된 형태로 표시하고, 데이터의 의미적 표현 능력을 향상시키며, 개체 간의 관계를 명확하고 명확하게 만들어 줍니다. 지식 그래프는 특히 자연어 처리 분야에서 정보 검색의 정확성을 크게 향상시켜 기계가 복잡한 사용자 쿼리를 더 잘 이해하고 응답할 수 있게 해줍니다. 지식 그래프는 추천 시스템, 지능형 질문 답변 등과 같은 지능형 애플리케이션에서 핵심 역할을 합니다.
지루한 소개를 마치고, RAG+ 지식 그래프의 사례를 살펴보고 직접 구현해 보겠습니다.
다음 사례는 LangChain의 공식 문서에서 발췌한 것입니다: https://python.langchain.com/v0.1/docs/integrations/graphs/neo4j_cypher/#refresh-graph-schema-information
(1) 먼저 그래프 데이터베이스를 설치해야 합니다. 여기서는 neo4j를 사용합니다.
파이썬 설치 명령:
pip install neo4j
(2) 공식 계정을 등록하고 로그인한 후 데이터베이스 인스턴스를 생성합니다. (학습용으로 사용하시려면 무료를 선택하시면 됩니다.)
온라인 데이터베이스 인스턴스를 생성한 후 페이지는 다음과 같습니다.
이제 코드에서 이 데이터베이스를 사용할 수 있습니다.
(1) 데이터베이스 인스턴스를 생성한 후 데이터의 링크, 사용자 이름 및 비밀번호를 가져와야 합니다. 이전 규칙은 이를 환경 변수에 넣은 다음 Python을 통해 환경 변수를 로드하는 것입니다.
neo4j_url = os.getenv('NEO4J_URI')
neo4j_username = os.getenv('NEO4J_USERNAME')
neo4j_password = os.getenv('NEO4J_PASSWORD')
(2) 데이터베이스 연결
LangChain은 neo4j 인터페이스를 캡슐화하므로 이를 사용하려면 Neo4jGraph 클래스만 가져오면 됩니다.
from langchain_community.graphs import Neo4jGraph
graph = Neo4jGraph(url=neo4j_url, username=neo4j_username, password=neo4j_password)
(3) 데이터 쿼리 및 채우기
쿼리 인터페이스를 사용하여 결과를 쿼리하고 반환할 수 있습니다. 쿼리 문의 언어는 Cypher 쿼리 언어입니다.
result = graph.query(
"""
MERGE (m:Movie {name:"Top Gun", runtime: 120})
WITH m
UNWIND ["Tom Cruise", "Val Kilmer", "Anthony Edwards", "Meg Ryan"] AS actor
MERGE (a:Actor {name:actor})
MERGE (a)-[:ACTED_IN]->(m)
"""
)
print(result)
# 输出:[]
위 코드의 출력은 다음과 같습니다. []。
(4) 그래프의 아키텍처 정보를 새로 고칩니다.
graph.refresh_schema()
print(graph.schema)

그 결과, 스키마에는 노드 유형, 속성, 유형 간 관계 등의 정보가 포함되며 그래프의 아키텍처가 됩니다.
또한 neo4j 웹페이지에 로그인하여 그래프 데이터베이스에 저장된 데이터를 볼 수도 있습니다.
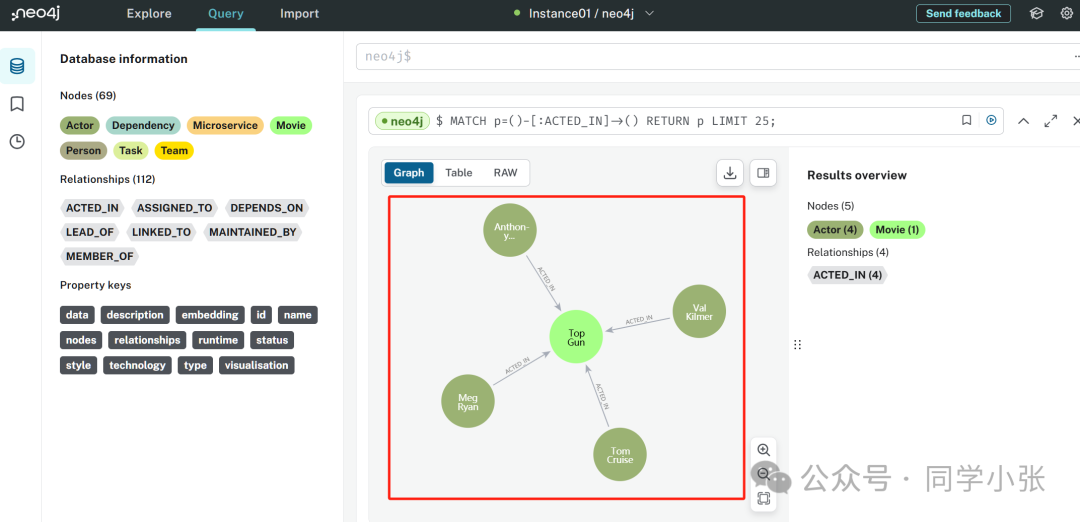
(5) 이제 그래프 데이터베이스에 데이터가 있으므로 쿼리할 수 있습니다.
GraphCypherQAChain 클래스는 LangChain에 캡슐화되어 있으며 그래프 데이터베이스를 사용하여 쉽게 쿼리할 수 있습니다. 다음 코드:
chain = GraphCypherQAChain.from_llm(
ChatOpenAI(temperature=0), graph=graph, verbose=True
)
result = chain.invoke({"query": "Who played in Top Gun?"})
print(result)
실행 과정 및 결과:

먼저 자연어(누가 탑건에서 플레이했나요?)를 대형 모델을 통해 그래프 쿼리문으로 변환한 후 neo4j를 통해 쿼리문을 실행하고 결과를 반환한 후 마지막으로 대형 모델을 통해 자연어로 변환한다. 모델을 만들어 사용자에게 출력합니다.
위 코드에서는 LangChain에서 제공하는 그래프 데이터베이스 쿼리 및 질문 및 답변 체인인 LangChain의 GraphCypherQAChain 클래스를 사용합니다.다음과 같이 설정할 수 있는 많은 매개변수가 있습니다.exclude_types 무시할 노드 유형 또는 관계를 설정하려면 다음을 수행하십시오.
chain = GraphCypherQAChain.from_llm(
graph=graph,
cypher_llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo"),
qa_llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo-16k"),
verbose=True,
exclude_types=["Movie"],
)
출력은 다음과 유사합니다.
Node properties are the following:
Actor {name: STRING}
Relationship properties are the following:
The relationships are the following:
사용 가능한 유사한 매개변수가 많이 있습니다. 공식 문서를 참조하세요: https://python.langchain.com/v0.1/docs/integrations/graphs/neo4j_cypher/#use-separate-llms-for-cypher-and- 답변 생성
다음은 GraphCypherQAChain의 실행 소스 코드이다. 실행 과정을 간략히 살펴보자.
(1)cypher_generation_chain: 자연어를 그래프 쿼리문으로 변환합니다.
(2)extract_cypher: 쿼리문을 꺼냅니다. 이는 대형 모델이 일부 추가 설명 정보를 반환할 수 있으므로 제거해야 하기 때문입니다.
(3)cypher_query_corrector: 쿼리문을 수정합니다.
(4)graph.query: 쿼리문 실행, 그래프 데이터베이스 쿼리, 콘텐츠 획득
(5)self.qa_chain: 원래의 질문과 질의 내용을 바탕으로 다시 대형 모델을 이용하여 답변을 정리하고 자연어로 사용자에게 출력합니다.
def _call( self,
inputs: Dict[str, Any],
run_manager: Optional[CallbackManagerForChainRun] = None,) -> Dict[str, Any]:
"""Generate Cypher statement, use it to look up in db and answer question."""
......
generated_cypher = self.cypher_generation_chain.run(
{"question": question, "schema": self.graph_schema}, callbacks=callbacks
)
# Extract Cypher code if it is wrapped in backticks
generated_cypher = extract_cypher(generated_cypher)
# Correct Cypher query if enabled
if self.cypher_query_corrector:
generated_cypher = self.cypher_query_corrector(generated_cypher)
......
# Retrieve and limit the number of results
# Generated Cypher be null if query corrector identifies invalid schema
if generated_cypher:
context = self.graph.query(generated_cypher)[: self.top_k]
else:
context = []
if self.return_direct:
final_result = context
else:
......
result = self.qa_chain(
{"question": question, "context": context},
callbacks=callbacks,
)
final_result = result[self.qa_chain.output_key]
chain_result: Dict[str, Any] = {self.output_key: final_result}
......
return chain_result
열정적인 인터넷 베테랑으로서 저는 귀중한 AI 지식을 모든 사람과 공유하기로 결정했습니다. 당신이 얼마나 배울 수 있는지는 당신의 공부 인내와 능력에 달려 있습니다. AI 대형모델 입문학습 마인드맵, 고품질 AI 대형모델 학습서 및 매뉴얼, 동영상 튜토리얼, 실기학습, 기타 녹화영상 등 중요한 AI 대형모델 자료를 무료로 공유해왔습니다.
대형 모델 AI 학습 자료의 전체 버전이 CSDN에 업로드되었습니다. 필요한 경우 친구가 WeChat에서 아래 CSDN 공식 인증 QR 코드를 스캔하여 무료로 받을 수 있습니다.保证100%免费】

대형 AI 모델 시대의 학습 여정: 기초부터 최첨단까지 인공지능 핵심 기술을 마스터하세요!

640개의 보고서로 구성된 이 컬렉션은 이론적 연구, 기술 구현, 대규모 AI 모델의 산업 적용과 같은 다양한 측면을 다루고 있습니다. 귀하가 과학 연구자, 엔지니어 또는 대규모 AI 모델에 관심이 있는 열성팬이든 관계없이 이 보고서 모음은 귀중한 정보와 영감을 제공할 것입니다.

인공지능 기술의 급속한 발전과 함께 AI 대형모델은 오늘날 과학기술 분야에서 뜨거운 화제가 되고 있다. GPT-3, BERT, XLNet 등과 같은 대규모 사전 훈련 모델은 강력한 언어 이해 및 생성 기능을 통해 인공 지능에 대한 이해를 변화시키고 있습니다. 다음 PDF 책은 매우 훌륭한 학습 자료입니다.


일반인으로서 대형모델 시대로 진입하기 위해서는 자신의 능력과 인지수준을 지속적으로 향상시키기 위한 지속적인 학습과 실천이 필요하며, 동시에 인공지능의 건전한 발전에 기여하기 위한 책임감과 윤리의식도 필요합니다. .

그는 30년 넘게 기술 연구에 전념해 왔으며, java, linux, javascript, php, css 등 다양한 언어에 능숙하며, 오픈소스 분야에 많은 공헌을 해왔습니다. 나중에 참조할 수 있도록 기술 개발의 일부 문제를 공유하는 개발자 문서 스테이션입니다.

우편메소피아@프로톤메일.com