2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina







Korkea innovaatio | CEEMDAN-VMD-GRU - Huomio kaksoishajottelu + portitettu toistuva yksikkö + huomiomekanismi monimuuttuja aikasarjan ennuste
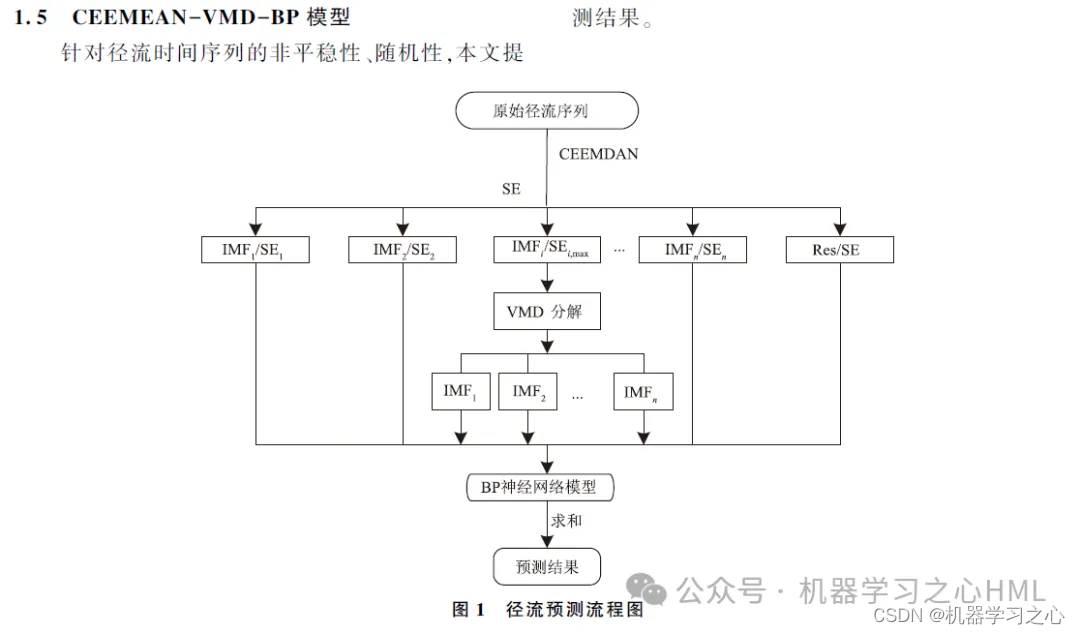
Tässä artikkelissa ehdotetaan CEEMDAN:iin perustuvaa toissijaista hajoamismenetelmää, joka rekonstruoi CEEMDANin hajottaman sekvenssin näyteentropian avulla. Kun kompleksisekvenssi on hajotettu VMD:llä, jokainen komponentti ennustetaan GRU-Attention-mallilla ja ennustustulokset integroidaan lopulta.
1.Matlab toteuttaa CEEMDAN-VMD-GRU-Attention-kaksoishajotus + portitettu silmukkayksikkö + useita huomiomekanismejaaikasarjan ennustaminen(Täydellinen lähdekoodi ja tiedot)
2. CEEMDAN hajottaa, laskee näyteentropian, suorittaa kmeans-klusteroinnin näytteen entropian perusteella, kutsuu VMD:tä hajottamaan suurtaajuisen komponentin kahdesti ja käyttää VMD:n hajottamaa suurtaajuista komponenttia ja etukomponenttia konvoluutioavainnettavana syklisenä yksikkönäHuomiomekanismin malliTavoitetulokset ennustetaan erikseen ja lisätään sitten.
3. Monimuuttuja yksittäinen lähtö, harkitse historiallisten ominaisuuksien vaikutusta! Arviointiindikaattoreita ovat R2, MAE, RMSE, MAPE jne.
4. Algoritmi on uusi. CEEMDAN-VMD-GRU-Attention-malli käsittelee tietoja suuremmalla tarkkuudella ja voi seurata tietojen trendejä ja muutoksia. VMD-malli käsittelee epälineaarista, ei-stationaarista ja monimutkaista dataa ja toimii paremmin kuin EMD-sarja. Siksi rekonstruoitu data hajotetaan VMD-mallin avulla mallin tarkkuuden parantamiseksi.
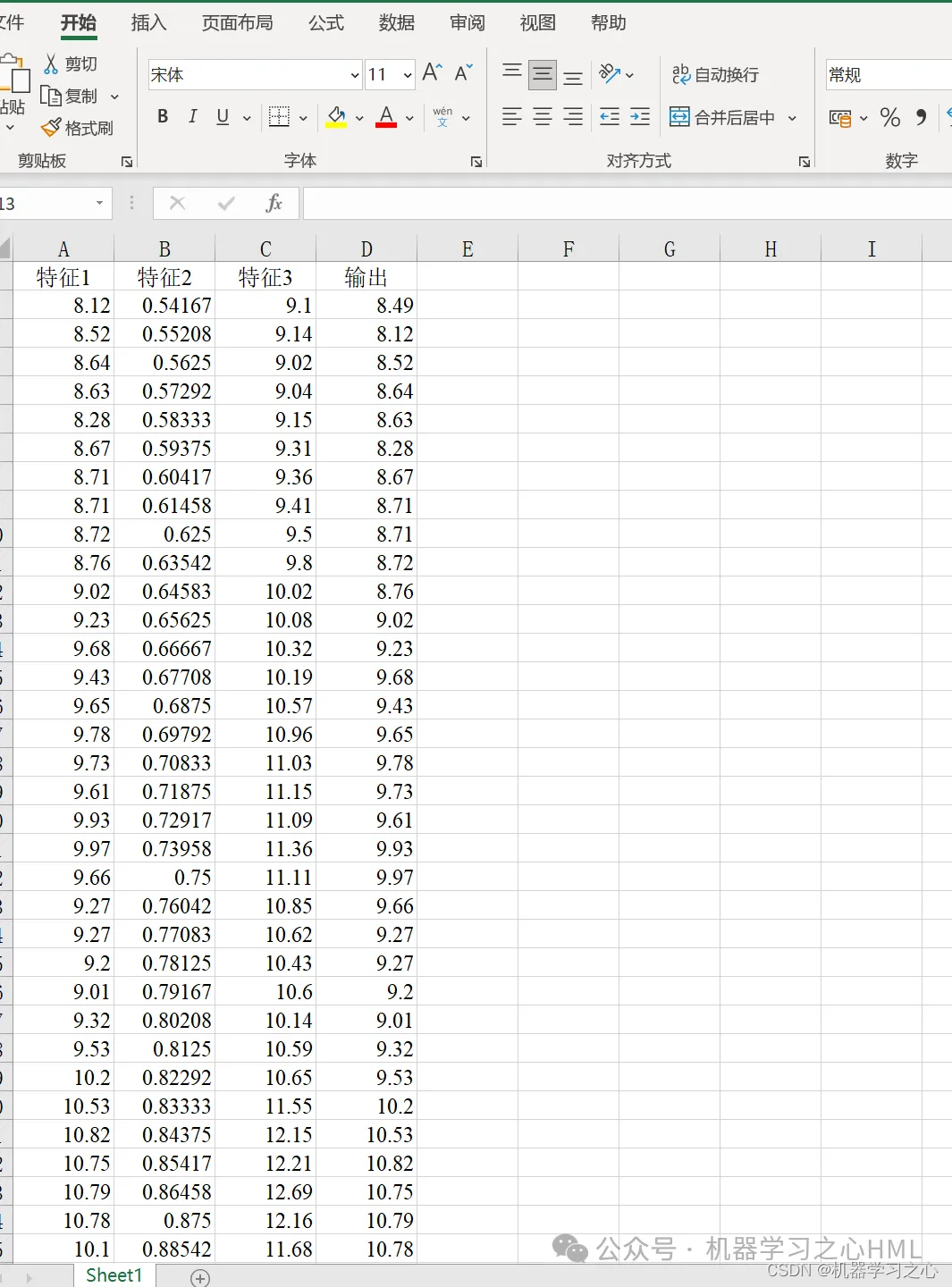
5. Sitä voidaan käyttää korvaamalla suoraan Excel-tiedot. Merkinnät ovat selkeitä ja sopivat aloittelijoille. Voit suorittaa päätiedoston suoraan yhdellä napsautuksella.
6. Koodin ominaisuudet: parametrinen ohjelmointi, parametreja voidaan muuttaa helposti, koodiohjelmointiideat ovat selkeät ja kommentit yksityiskohtaisia.



%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
%% 数据归一化
[P_train, ps_input] = mapminmax(P_train, 0, 1);
P_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
%% 数据平铺
P_train = double(reshape(P_train, f_, 1, 1, M));
P_test = double(reshape(P_test , f_, 1, 1, N));
t_train = t_train';
t_test = t_test' ;
%% 数据格式转换
for i = 1 : M
p_train{i, 1} = P_train(:, :, 1, i);
end
for i = 1 : N
p_test{i, 1} = P_test( :, :, 1, i);
end
%% 参数设置
options = trainingOptions('adam', ... % Adam 梯度下降算法
'MaxEpochs', 100, ... % 最大训练次数
'InitialLearnRate', 0.01, ... % 初始学习率为0.01
'LearnRateSchedule', 'piecewise', ... % 学习率下降
'LearnRateDropFactor', 0.1, ... % 学习率下降因子 0.1
'LearnRateDropPeriod', 70, ... % 经过训练后 学习率为 0.01*0.1
'Shuffle', 'every-epoch', ... % 每次训练打乱数据集
'Verbose', 1);
figure
subplot(2,1,1)
plot(T_train,'k--','LineWidth',1.5);
hold on
plot(T_sim_a','r-','LineWidth',1.5)
legend('真实值','预测值')
title('CEEMDAN-VMD-CNN-GRU-Attention训练集预测效果对比')
xlabel('样本点')
ylabel('数值')
subplot(2,1,2)
bar(T_sim_a'-T_train)
title('CEEMDAN-VMD-GRU-Attention训练误差图')
xlabel('样本点')
ylabel('数值')
disp('…………测试集误差指标…………')
[mae2,rmse2,mape2,error2]=calc_error(T_test,T_sim_b');
fprintf('n')
figure
subplot(2,1,1)
plot(T_test,'k--','LineWidth',1.5);
hold on
plot(T_sim_b','b-','LineWidth',1.5)
legend('真实值','预测值')
title('CEEMDAN-VMD-GRU-Attention测试集预测效果对比')
xlabel('样本点')
ylabel('数值')
subplot(2,1,2)
bar(T_sim_b'-T_test)
title('CEEMDAN-VMD-GRU-Attention测试误差图')
xlabel('样本点')
ylabel('数值')
[1] https://hmlhml.blog.csdn.net/article/details/135536086?spm=1001.2014.3001.5502
[2] https://hmlhml.blog.csdn.net/article/details/137166860?spm=1001.2014.3001.5502
[3] https://hmlhml.blog.csdn.net/article/details/132372151

Hän on omistautunut teknologian tutkimukselle yli 30 vuoden ajan ja hallitsee useita kieliä, kuten java, linux, javascript, php, css jne. Hän on tehnyt paljon työtä avoimen lähdekoodin tässä Kehittäjän dokumentaatioasema jakaaksesi teknologian kehityksen ongelman tulevaa käyttöä varten
