Mi informacion de contacto
Correo[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina







Alta innovación | CEEMDA-VMD-GRU-Atención descomposición dual + unidad recurrente cerrada + mecanismo de atención predicción de series temporales multivariadas
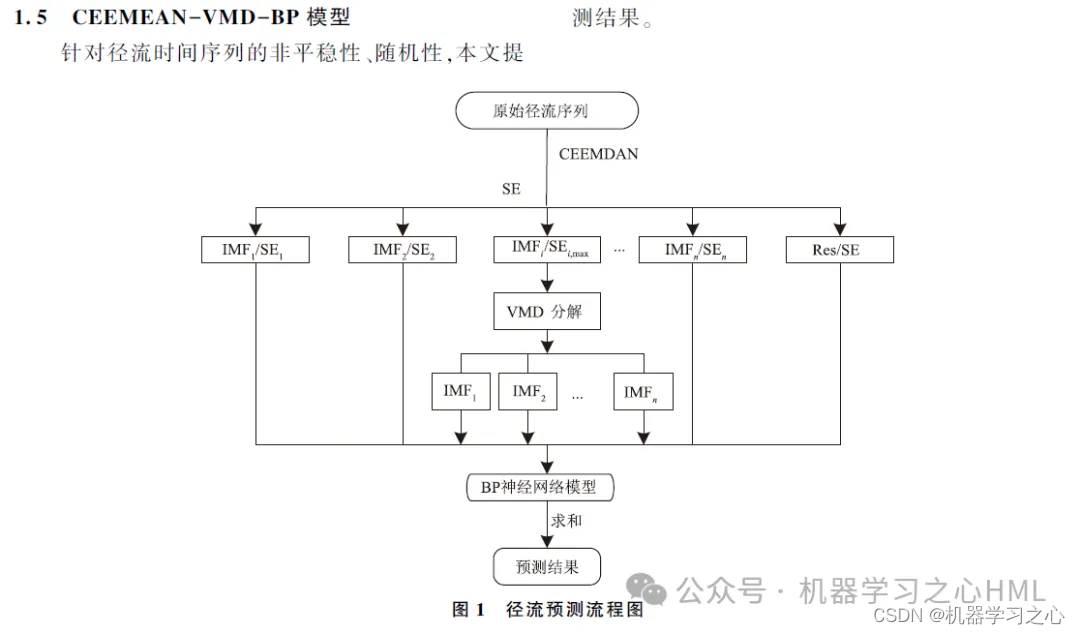
Este artículo propone un método de descomposición secundaria basado en CEEMDAN, que reconstruye la secuencia descompuesta por CEEMDAN mediante entropía de muestra. Después de que VMD descompone la secuencia compleja, el modelo GRU-Atención predice cada componente y finalmente integra los resultados de la predicción.
1.Matlab implementa CEEMDAN-VMD-GRU-Atención de descomposición dual + unidad de bucle cerrado + múltiples mecanismos de atenciónpronóstico de series de tiempo(Código fuente completo y datos)
2. CEEMDAN descompone, calcula la entropía de la muestra, realiza agrupaciones de kmeans en función de la entropía de la muestra, llama a VMD para descomponer el componente de alta frecuencia dos veces y utiliza el componente de alta frecuencia y el componente frontal descompuesto por VMD como una unidad cíclica controlada por convoluciónModelo de mecanismo de atención.Los resultados objetivo se predicen por separado y luego se suman.
3. Salida única multivariable, ¡considere la influencia de las características históricas! Los indicadores de evaluación incluyen R2, MAE, RMSE, MAPE, etc.
4. El algoritmo es novedoso. El modelo CEEMDAN-VMD-GRU-Attention procesa datos con mayor precisión y puede rastrear tendencias y cambios en los datos. El modelo VMD maneja datos no lineales, no estacionarios y complejos y funciona mejor que la serie EMD. Por lo tanto, los datos reconstruidos se descomponen mediante el modelo VMD para mejorar la precisión del modelo.
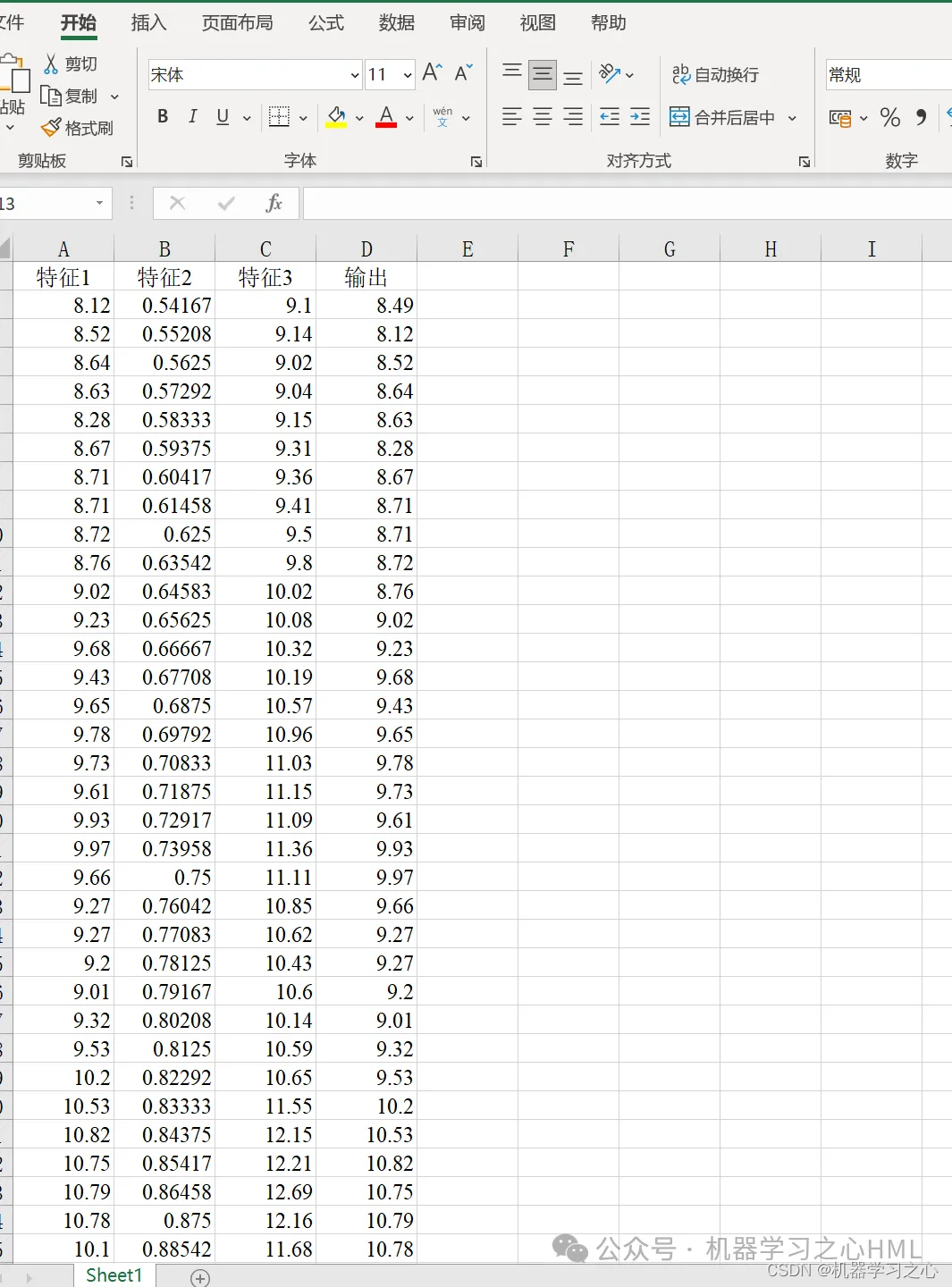
5. Se puede utilizar reemplazando directamente los datos de Excel. Las anotaciones son claras y adecuadas para principiantes. Puede ejecutar directamente el archivo principal para generar el gráfico con un solo clic.
6. Características del código: programación paramétrica, los parámetros se pueden cambiar fácilmente, las ideas de programación del código son claras y los comentarios son detallados.



%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
%% 数据归一化
[P_train, ps_input] = mapminmax(P_train, 0, 1);
P_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
%% 数据平铺
P_train = double(reshape(P_train, f_, 1, 1, M));
P_test = double(reshape(P_test , f_, 1, 1, N));
t_train = t_train';
t_test = t_test' ;
%% 数据格式转换
for i = 1 : M
p_train{i, 1} = P_train(:, :, 1, i);
end
for i = 1 : N
p_test{i, 1} = P_test( :, :, 1, i);
end
%% 参数设置
options = trainingOptions('adam', ... % Adam 梯度下降算法
'MaxEpochs', 100, ... % 最大训练次数
'InitialLearnRate', 0.01, ... % 初始学习率为0.01
'LearnRateSchedule', 'piecewise', ... % 学习率下降
'LearnRateDropFactor', 0.1, ... % 学习率下降因子 0.1
'LearnRateDropPeriod', 70, ... % 经过训练后 学习率为 0.01*0.1
'Shuffle', 'every-epoch', ... % 每次训练打乱数据集
'Verbose', 1);
figure
subplot(2,1,1)
plot(T_train,'k--','LineWidth',1.5);
hold on
plot(T_sim_a','r-','LineWidth',1.5)
legend('真实值','预测值')
title('CEEMDAN-VMD-CNN-GRU-Attention训练集预测效果对比')
xlabel('样本点')
ylabel('数值')
subplot(2,1,2)
bar(T_sim_a'-T_train)
title('CEEMDAN-VMD-GRU-Attention训练误差图')
xlabel('样本点')
ylabel('数值')
disp('…………测试集误差指标…………')
[mae2,rmse2,mape2,error2]=calc_error(T_test,T_sim_b');
fprintf('n')
figure
subplot(2,1,1)
plot(T_test,'k--','LineWidth',1.5);
hold on
plot(T_sim_b','b-','LineWidth',1.5)
legend('真实值','预测值')
title('CEEMDAN-VMD-GRU-Attention测试集预测效果对比')
xlabel('样本点')
ylabel('数值')
subplot(2,1,2)
bar(T_sim_b'-T_test)
title('CEEMDAN-VMD-GRU-Attention测试误差图')
xlabel('样本点')
ylabel('数值')
[1] https://hmlhml.blog.csdn.net/article/details/135536086?spm=1001.2014.3001.5502
[2] https://hmlhml.blog.csdn.net/article/details/137166860?spm=1001.2014.3001.5502
[3] https://hmlhml.blog.csdn.net/article/details/132372151

Se ha dedicado a la investigación de tecnología durante más de 30 años y domina varios lenguajes como java, linux, javascript, php, css, etc. Ha realizado muchas contribuciones en el campo del código abierto. Estación de documentación para desarrolladores para compartir algunos problemas en el desarrollo de tecnología para referencia futura.

Correo[email protected]