プライベートな連絡先の最初の情報
送料メール:
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina







高い革新性 | セームダン-VMD-GRU-アテンション二重分解 + ゲート付きリカレントユニット + アテンションメカニズム多変量時系列予測
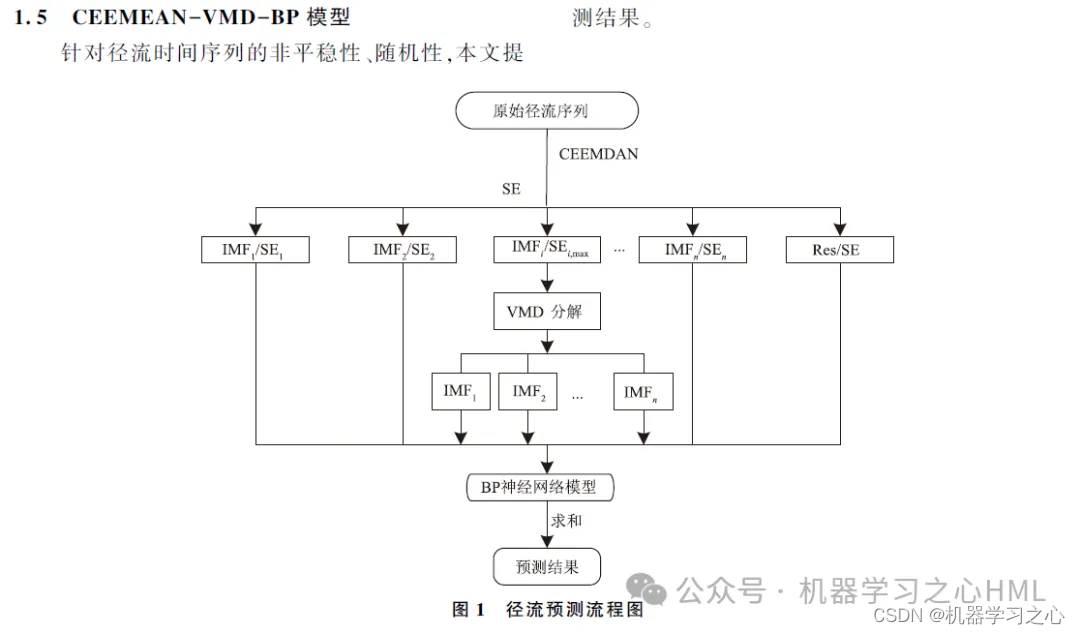
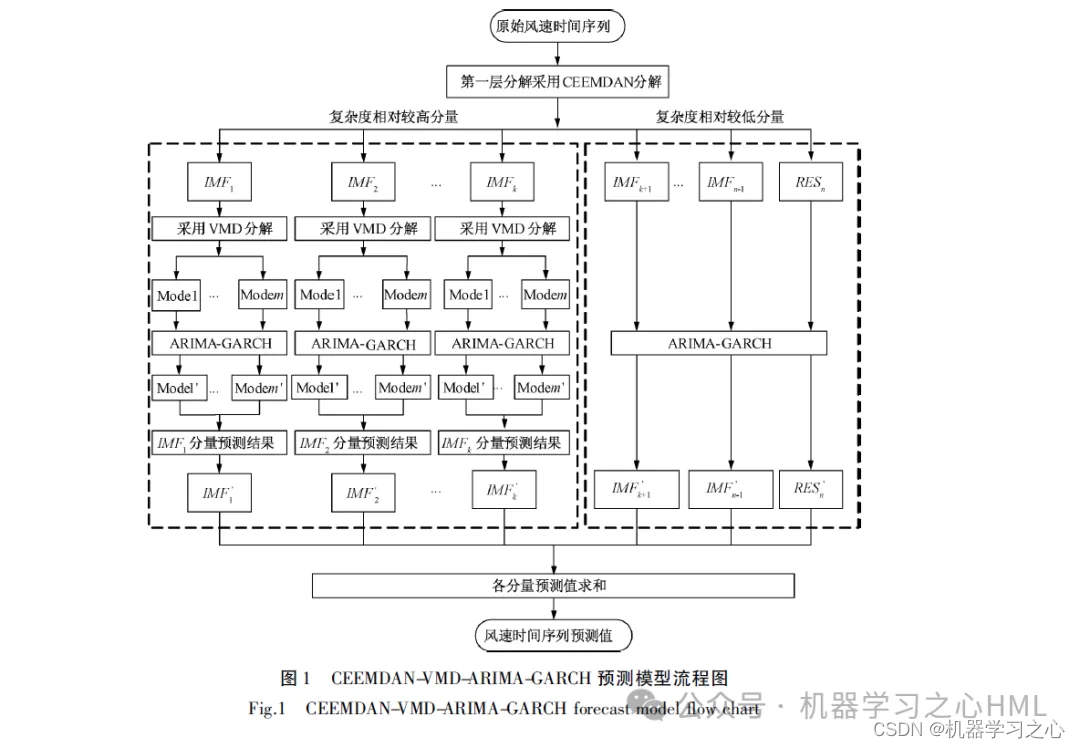
本稿では、CEEMDANで分解された系列をVMDで分解した後、GRU-Attendantモデルで各成分を予測し、最終的に予測結果を統合するCEEMDANに基づく二次分解手法を提案する。
1.Matlab は CEEMDAN-VMD-GRU-Attention デュアル分解 + ゲート ループ ユニット + 複数のアテンション メカニズムを実装します。時系列予測(完全なソースコードとデータ)
2. CEEMDAN は分解し、サンプル エントロピーを計算し、サンプル エントロピーに基づいて kmeans クラスタリングを実行し、VMD を呼び出して高周波成分を 2 回分解し、VMD によって分解された高周波成分とフロント成分を畳み込みゲート巡回ユニットとして使用します。注意メカニズムモデルターゲット出力は個別に予測されてから加算されます。
3. 多変数単一出力、履歴特性の影響を考慮!評価指標にはR2、MAE、RMSE、MAPEなどが含まれます。
4. アルゴリズムが斬新です。 CEEMDAN-VMD-GRU-Attendee モデルは、より高い精度でデータを処理し、データの傾向と変化を追跡できます。 VMD モデルは非線形、非定常、複雑なデータを処理し、EMD シリーズよりも優れたパフォーマンスを発揮します。そのため、再構築されたデータは VMD モデルを通じて分解され、モデルの精度が向上します。
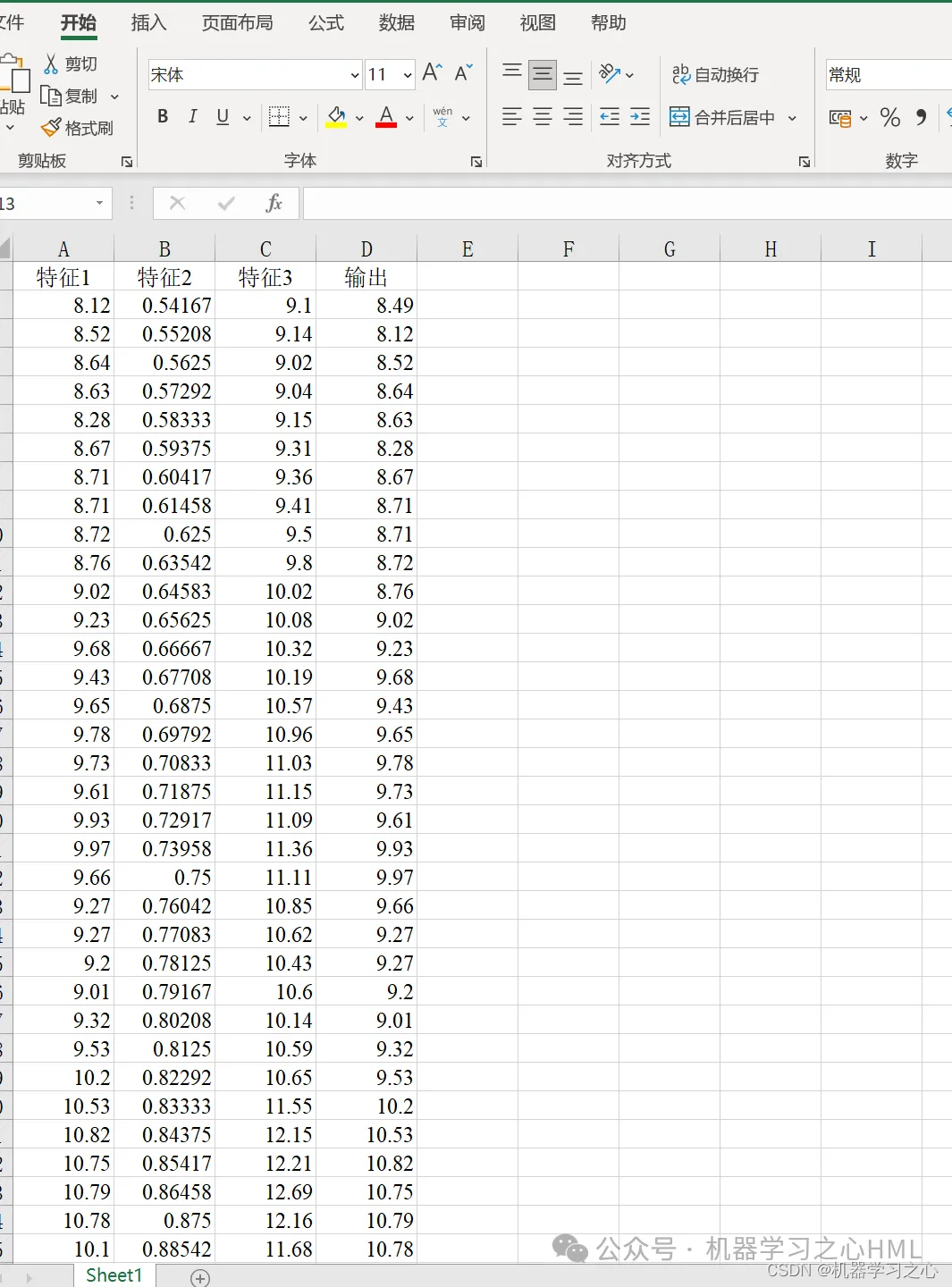
5. Excel データを直接置き換えて使用できます。注釈はわかりやすく、ワンクリックでメインファイルを直接実行してグラフを出力できます。
6. コードの特徴: パラメトリック プログラミング、パラメーターは簡単に変更でき、コード プログラミングのアイデアは明確で、コメントは詳細です。



%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
%% 数据归一化
[P_train, ps_input] = mapminmax(P_train, 0, 1);
P_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
%% 数据平铺
P_train = double(reshape(P_train, f_, 1, 1, M));
P_test = double(reshape(P_test , f_, 1, 1, N));
t_train = t_train';
t_test = t_test' ;
%% 数据格式转换
for i = 1 : M
p_train{i, 1} = P_train(:, :, 1, i);
end
for i = 1 : N
p_test{i, 1} = P_test( :, :, 1, i);
end
%% 参数设置
options = trainingOptions('adam', ... % Adam 梯度下降算法
'MaxEpochs', 100, ... % 最大训练次数
'InitialLearnRate', 0.01, ... % 初始学习率为0.01
'LearnRateSchedule', 'piecewise', ... % 学习率下降
'LearnRateDropFactor', 0.1, ... % 学习率下降因子 0.1
'LearnRateDropPeriod', 70, ... % 经过训练后 学习率为 0.01*0.1
'Shuffle', 'every-epoch', ... % 每次训练打乱数据集
'Verbose', 1);
figure
subplot(2,1,1)
plot(T_train,'k--','LineWidth',1.5);
hold on
plot(T_sim_a','r-','LineWidth',1.5)
legend('真实值','预测值')
title('CEEMDAN-VMD-CNN-GRU-Attention训练集预测效果对比')
xlabel('样本点')
ylabel('数值')
subplot(2,1,2)
bar(T_sim_a'-T_train)
title('CEEMDAN-VMD-GRU-Attention训练误差图')
xlabel('样本点')
ylabel('数值')
disp('…………测试集误差指标…………')
[mae2,rmse2,mape2,error2]=calc_error(T_test,T_sim_b');
fprintf('n')
figure
subplot(2,1,1)
plot(T_test,'k--','LineWidth',1.5);
hold on
plot(T_sim_b','b-','LineWidth',1.5)
legend('真实值','预测值')
title('CEEMDAN-VMD-GRU-Attention测试集预测效果对比')
xlabel('样本点')
ylabel('数值')
subplot(2,1,2)
bar(T_sim_b'-T_test)
title('CEEMDAN-VMD-GRU-Attention测试误差图')
xlabel('样本点')
ylabel('数值')
[1] https://hmlhml.blog.csdn.net/article/details/135536086?spm=1001.2014.3001.5502
[2] https://hmlhml.blog.csdn.net/article/details/137166860?spm=1001.2014.3001.5502
[3] https://hmlhml.blog.csdn.net/article/details/132372151

彼は 30 年以上テクノロジーの研究に専念しており、java、linux、javascript、php、css などのさまざまな言語に堪能であり、オープンソース分野で多くの貢献を行っています。将来の参考のために技術開発におけるいくつかの問題を共有する開発者ドキュメント ステーション。

送料メール: