내 연락처 정보
우편메소피아@프로톤메일.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina







높은 혁신 | 심단-VMD-GRU-Attention 이중 분해 + 게이트 순환 단위 + 주의 메커니즘 다변량 시계열 예측
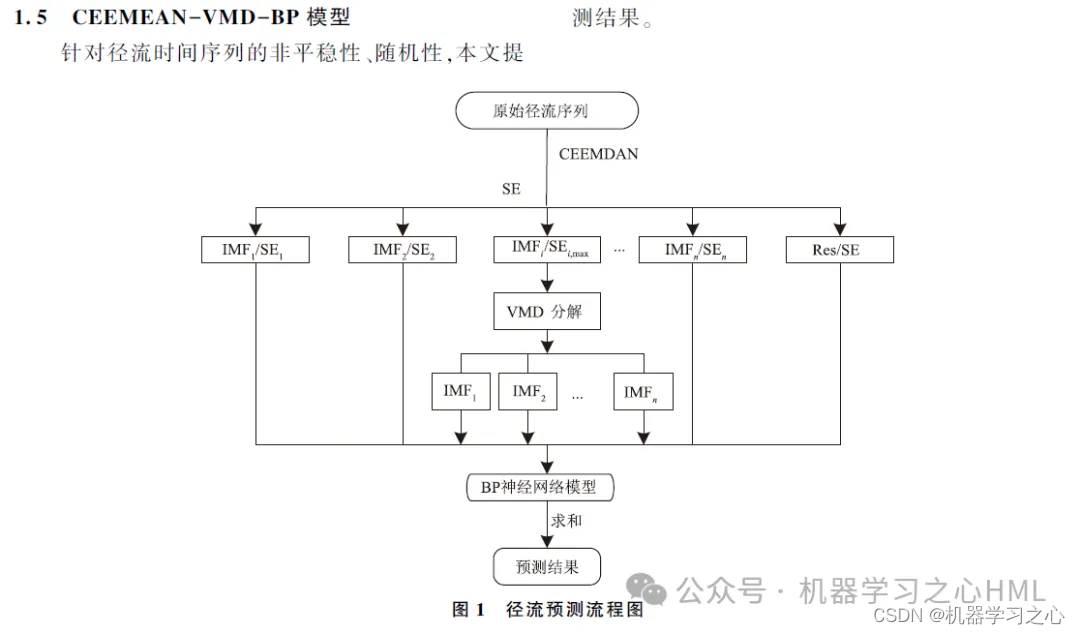
본 논문에서는 CEEMDAN에 의해 분해된 시퀀스를 VMD에 의해 분해한 후 GRU-Attention 모델을 통해 각 구성요소를 예측하고 최종적으로 예측 결과를 통합하는 CEEMDAN 기반의 2차 분해 방법을 제안한다.
1. Matlab은 CEEMDAN-VMD-GRU-Attention 이중 분해 + 게이트 루프 장치 + 다중 주의 메커니즘을 구현합니다.시계열 예측(완전한 소스 코드 및 데이터)
2. CEEMDAN은 분해하여 샘플 엔트로피를 계산하고, 샘플 엔트로피를 기반으로 kmeans 클러스터링을 수행하고, VMD를 호출하여 고주파 성분을 두 번 분해하고, VMD에서 분해된 고주파 성분과 앞부분 성분을 컨볼루션 게이트 순환 단위로 사용합니다.주의 메커니즘 모델목표 출력은 별도로 예측된 다음 추가됩니다.
3. 다변수 단일 출력, 역사적 특성의 영향을 고려하십시오! 평가 지표에는 R2, MAE, RMSE, MAPE 등이 포함됩니다.
4. 알고리즘이 참신합니다. CEEMDAN-VMD-GRU-Attention 모델은 더 높은 정확도로 데이터를 처리하고 데이터 추세와 변경 사항을 추적할 수 있습니다. VMD 모델은 비선형, 비정상 및 복잡한 데이터를 처리하며 EMD 시리즈보다 성능이 우수합니다. 따라서 재구성된 데이터를 VMD 모델을 통해 분해하여 모델의 정확도를 향상시킵니다.
5. 엑셀 데이터를 직접 교체하여 사용할 수 있으며, 주석이 명확하고 초보자에게도 적합합니다. 한 번의 클릭으로 메인 파일을 직접 실행하여 그래프를 출력할 수 있습니다.
6. 코드 기능: 파라메트릭 프로그래밍, 매개변수를 쉽게 변경할 수 있고 코드 프로그래밍 아이디어가 명확하며 설명이 상세합니다.



%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
%% 数据归一化
[P_train, ps_input] = mapminmax(P_train, 0, 1);
P_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
%% 数据平铺
P_train = double(reshape(P_train, f_, 1, 1, M));
P_test = double(reshape(P_test , f_, 1, 1, N));
t_train = t_train';
t_test = t_test' ;
%% 数据格式转换
for i = 1 : M
p_train{i, 1} = P_train(:, :, 1, i);
end
for i = 1 : N
p_test{i, 1} = P_test( :, :, 1, i);
end
%% 参数设置
options = trainingOptions('adam', ... % Adam 梯度下降算法
'MaxEpochs', 100, ... % 最大训练次数
'InitialLearnRate', 0.01, ... % 初始学习率为0.01
'LearnRateSchedule', 'piecewise', ... % 学习率下降
'LearnRateDropFactor', 0.1, ... % 学习率下降因子 0.1
'LearnRateDropPeriod', 70, ... % 经过训练后 学习率为 0.01*0.1
'Shuffle', 'every-epoch', ... % 每次训练打乱数据集
'Verbose', 1);
figure
subplot(2,1,1)
plot(T_train,'k--','LineWidth',1.5);
hold on
plot(T_sim_a','r-','LineWidth',1.5)
legend('真实值','预测值')
title('CEEMDAN-VMD-CNN-GRU-Attention训练集预测效果对比')
xlabel('样本点')
ylabel('数值')
subplot(2,1,2)
bar(T_sim_a'-T_train)
title('CEEMDAN-VMD-GRU-Attention训练误差图')
xlabel('样本点')
ylabel('数值')
disp('…………测试集误差指标…………')
[mae2,rmse2,mape2,error2]=calc_error(T_test,T_sim_b');
fprintf('n')
figure
subplot(2,1,1)
plot(T_test,'k--','LineWidth',1.5);
hold on
plot(T_sim_b','b-','LineWidth',1.5)
legend('真实值','预测值')
title('CEEMDAN-VMD-GRU-Attention测试集预测效果对比')
xlabel('样本点')
ylabel('数值')
subplot(2,1,2)
bar(T_sim_b'-T_test)
title('CEEMDAN-VMD-GRU-Attention测试误差图')
xlabel('样本点')
ylabel('数值')
[1] https://hmlhml.blog.csdn.net/article/details/135536086?spm=1001.2014.3001.5502
[2] https://hmlhml.blog.csdn.net/article/details/137166860?spm=1001.2014.3001.5502
[3] https://hmlhml.blog.csdn.net/article/details/132372151

그는 30년 이상 기술 연구에 전념해 왔으며, java, linux, javascript, php, css 등 다양한 언어에 능숙하며, 오픈 소스 분야에 많은 공헌을 했습니다. 나중에 참조할 수 있도록 기술 개발의 일부 문제를 공유하는 개발자 문서 스테이션입니다.

우편메소피아@프로톤메일.com