informasi kontak saya
Surat[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina







Inovasi tinggi | CEMDAN-VMD-GRU-Dekomposisi ganda perhatian + unit berulang yang terjaga keamanannya + mekanisme perhatian prediksi deret waktu multivariat
Makalah ini mengusulkan metode dekomposisi sekunder berdasarkan CEEMDAN, yang merekonstruksi barisan yang didekomposisi oleh CEEMDAN melalui entropi sampel. Setelah barisan kompleks didekomposisi oleh VMD, setiap komponen diprediksi oleh model GRU-Attention, dan hasil prediksi akhirnya diintegrasikan.
1.Matlab mengimplementasikan dekomposisi ganda CEEMDAN-VMD-GRU-Attention + unit loop berpagar + beberapa mekanisme perhatianperamalan deret waktu(Kode sumber dan data lengkap)
2. CEEMDAN menguraikan, menghitung entropi sampel, melakukan pengelompokan kmeans berdasarkan entropi sampel, memanggil VMD untuk menguraikan komponen frekuensi tinggi dua kali, dan menggunakan komponen frekuensi tinggi dan komponen depan yang didekomposisi oleh VMD sebagai unit siklik berpintu konvolusiModel mekanisme perhatianOutput target diprediksi secara terpisah dan kemudian ditambahkan.
3. Keluaran tunggal multi-variabel, pertimbangkan pengaruh karakteristik sejarah! Indikator evaluasi meliputi R2, MAE, RMSE, MAPE, dll.
4. Algoritmanya baru. Model CEEMDAN-VMD-GRU-Attention memproses data dengan akurasi lebih tinggi dan dapat melacak tren dan perubahan data. Model VMD menangani data nonlinier, non-stasioner, dan kompleks serta berkinerja lebih baik daripada seri EMD. Oleh karena itu, data yang direkonstruksi didekomposisi melalui model VMD untuk meningkatkan akurasi model.
5. Dapat digunakan dengan langsung mengganti data Excel. Anotasinya jelas dan cocok untuk pemula. Anda dapat langsung menjalankan file utama untuk menampilkan grafik dengan satu klik.
6. Fitur kode: pemrograman parametrik, parameter dapat dengan mudah diubah, ide pemrograman kode jelas, dan komentar dirinci.

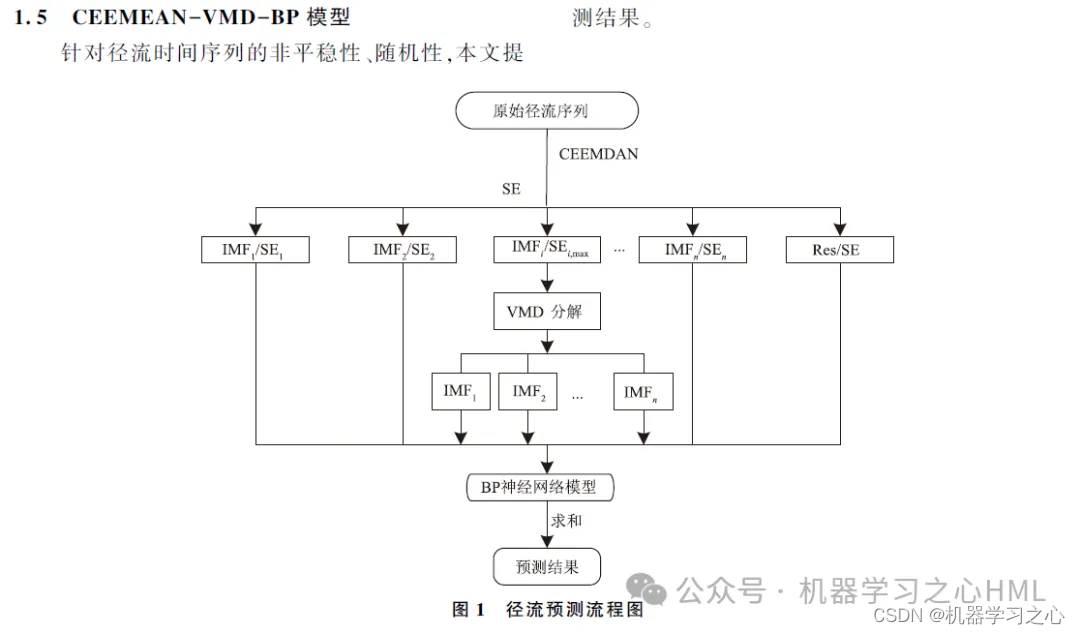


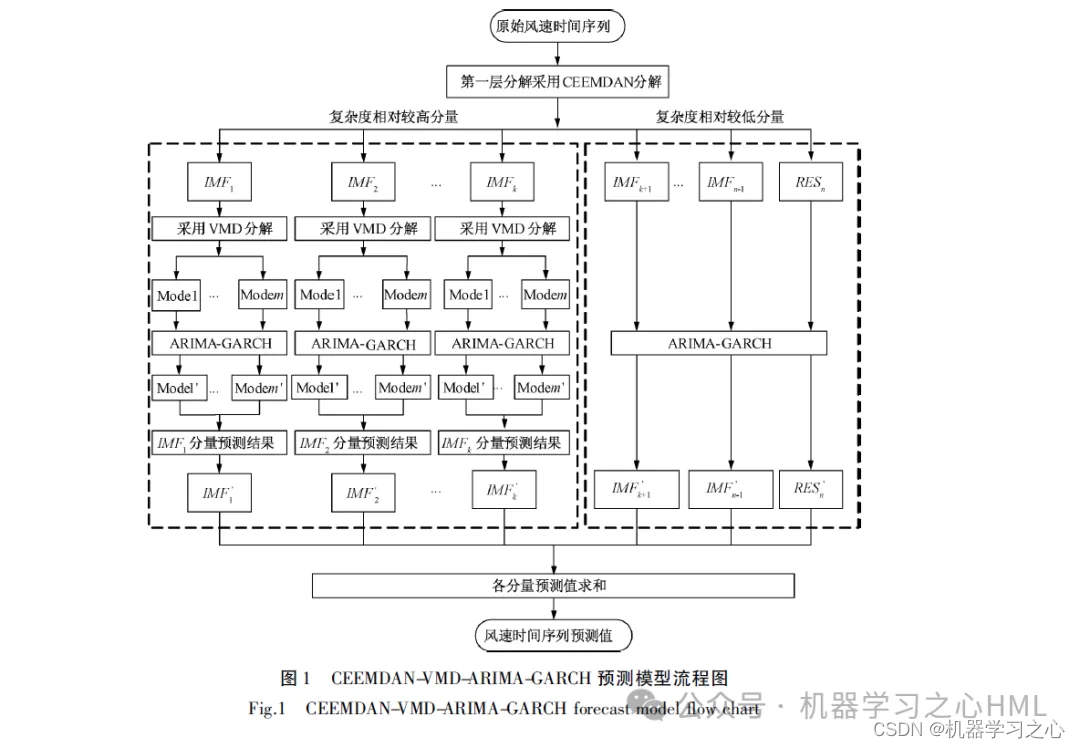
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
%% 数据归一化
[P_train, ps_input] = mapminmax(P_train, 0, 1);
P_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
%% 数据平铺
P_train = double(reshape(P_train, f_, 1, 1, M));
P_test = double(reshape(P_test , f_, 1, 1, N));
t_train = t_train';
t_test = t_test' ;
%% 数据格式转换
for i = 1 : M
p_train{i, 1} = P_train(:, :, 1, i);
end
for i = 1 : N
p_test{i, 1} = P_test( :, :, 1, i);
end
%% 参数设置
options = trainingOptions('adam', ... % Adam 梯度下降算法
'MaxEpochs', 100, ... % 最大训练次数
'InitialLearnRate', 0.01, ... % 初始学习率为0.01
'LearnRateSchedule', 'piecewise', ... % 学习率下降
'LearnRateDropFactor', 0.1, ... % 学习率下降因子 0.1
'LearnRateDropPeriod', 70, ... % 经过训练后 学习率为 0.01*0.1
'Shuffle', 'every-epoch', ... % 每次训练打乱数据集
'Verbose', 1);
figure
subplot(2,1,1)
plot(T_train,'k--','LineWidth',1.5);
hold on
plot(T_sim_a','r-','LineWidth',1.5)
legend('真实值','预测值')
title('CEEMDAN-VMD-CNN-GRU-Attention训练集预测效果对比')
xlabel('样本点')
ylabel('数值')
subplot(2,1,2)
bar(T_sim_a'-T_train)
title('CEEMDAN-VMD-GRU-Attention训练误差图')
xlabel('样本点')
ylabel('数值')
disp('…………测试集误差指标…………')
[mae2,rmse2,mape2,error2]=calc_error(T_test,T_sim_b');
fprintf('n')
figure
subplot(2,1,1)
plot(T_test,'k--','LineWidth',1.5);
hold on
plot(T_sim_b','b-','LineWidth',1.5)
legend('真实值','预测值')
title('CEEMDAN-VMD-GRU-Attention测试集预测效果对比')
xlabel('样本点')
ylabel('数值')
subplot(2,1,2)
bar(T_sim_b'-T_test)
title('CEEMDAN-VMD-GRU-Attention测试误差图')
xlabel('样本点')
ylabel('数值')
[1] https://hmlhml.blog.csdn.net/article/details/135536086?spm=1001.2014.3001.5502
[2] https://hmlhml.blog.csdn.net/article/details/137166860?spm=1001.2014.3001.5502
[3] https://hmlhml.blog.csdn.net/article/details/132372151

Ia telah mengabdikan dirinya untuk meneliti teknologi selama lebih dari 30 tahun, dan mahir dalam berbagai bahasa seperti java, linux, javascript, php, css, dll. Ia telah memberikan banyak kontribusi di bidang open source stasiun dokumentasi pengembang untuk berbagi beberapa masalah dalam pengembangan teknologi untuk referensi di masa mendatang. Semua orang memeriksanya

Surat[email protected]