моя контактная информация
Почтамезофия@protonmail.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina







Высокие инновации | КЕМДАН-VMD-GRU-Двойная декомпозиция внимания + вентильный рекуррентный блок + механизм внимания, многомерное предсказание временных рядов
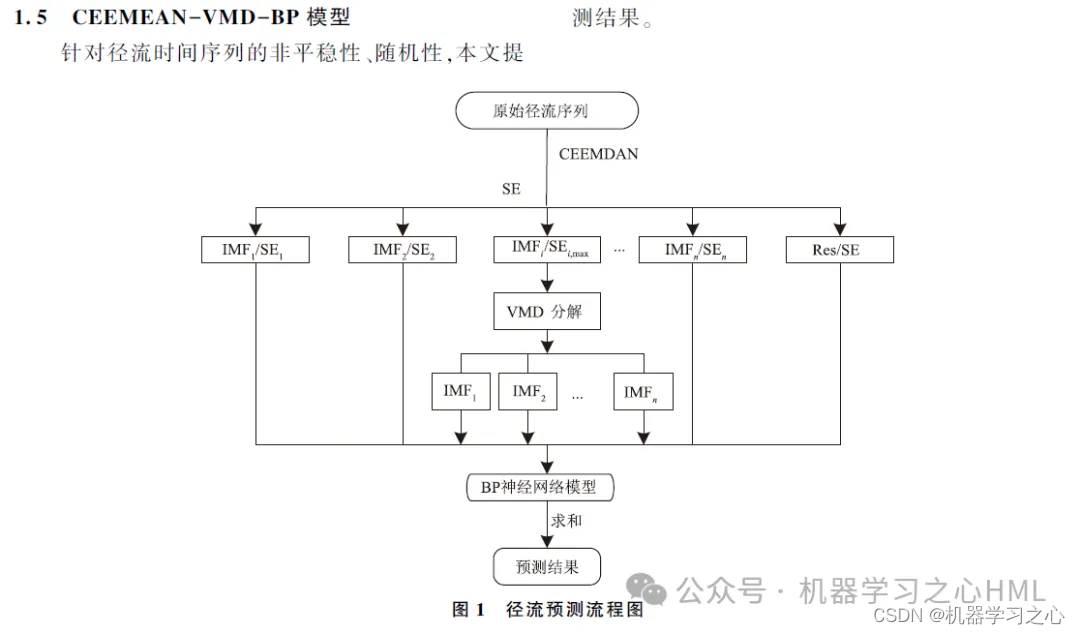
В этой статье предлагается метод вторичной декомпозиции, основанный на CEEMDAN, который восстанавливает последовательность, разложенную CEEMDAN, с помощью энтропии выборки. После того, как сложная последовательность разлагается с помощью VMD, каждый компонент прогнозируется моделью GRU-Attention, и результаты прогнозирования окончательно интегрируются.
1.Matlab реализует двойную декомпозицию CEEMDAN-VMD-GRU-Attention + блок замкнутого цикла + несколько механизмов внимания.прогнозирование временных рядов(Полный исходный код и данные)
2. CEEMDAN разлагает, вычисляет энтропию выборки, выполняет кластеризацию kmeans на основе энтропии выборки, дважды вызывает VMD для разложения высокочастотной составляющей и использует высокочастотную составляющую и переднюю составляющую, разложенную VMD, в качестве циклической единицы со стробированием свертки.Модель механизма вниманияЦелевые результаты прогнозируются отдельно, а затем суммируются.
3. Одиночный выход с несколькими переменными, учитывайте влияние исторических характеристик! Индикаторы оценки включают R2, MAE, RMSE, MAPE и т. д.
4. Алгоритм новый. Модель CEEMDAN-VMD-GRU-Attention обрабатывает данные с более высокой точностью и может отслеживать тенденции и изменения данных. Модель VMD обрабатывает нелинейные, нестационарные и сложные данные и работает лучше, чем серия EMD. Поэтому реконструированные данные разлагаются с помощью модели VMD, чтобы повысить точность модели.
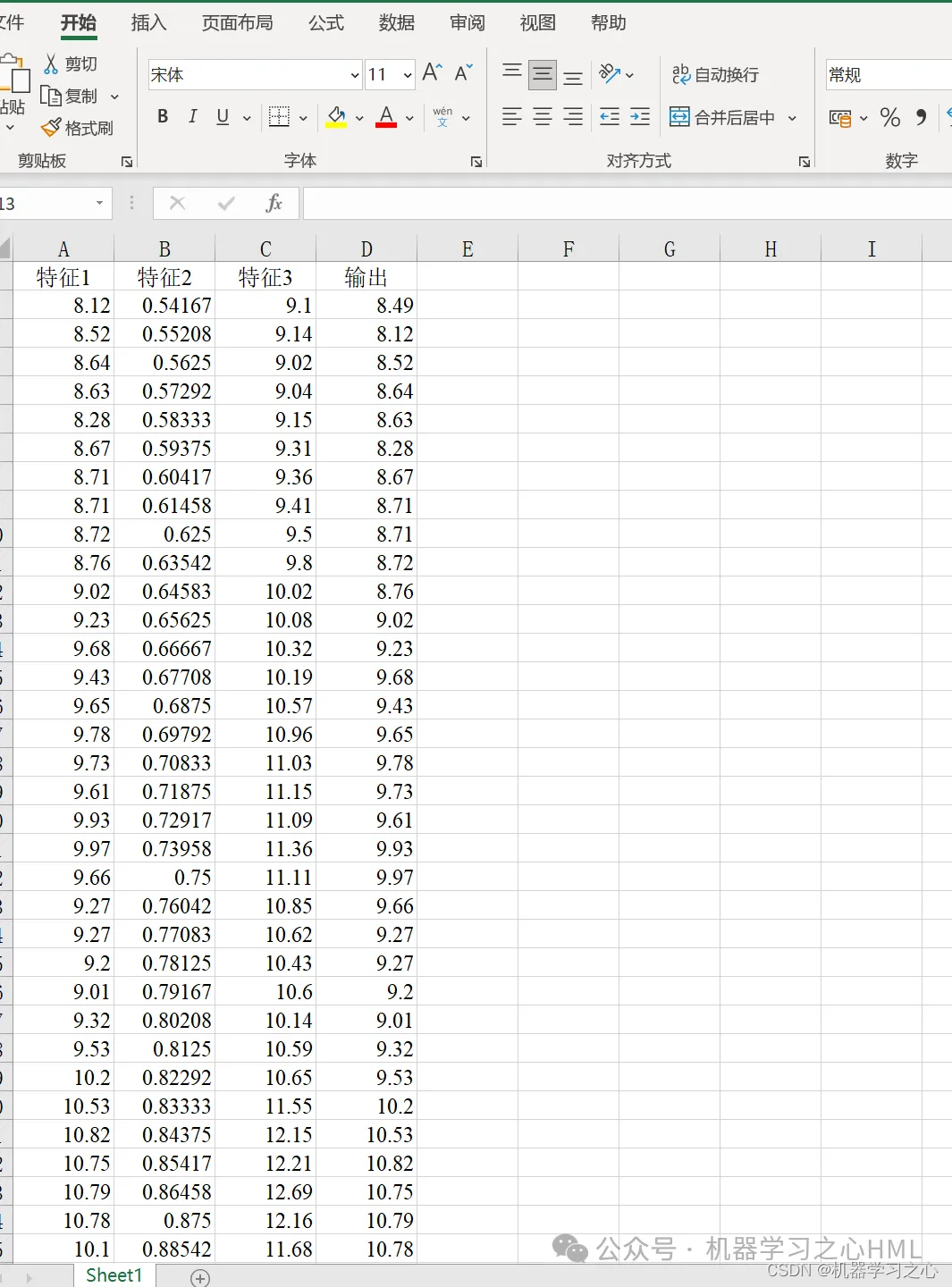
5. Его можно использовать путем прямой замены данных Excel. Аннотации понятны и подходят для новичков. Вы можете напрямую запустить основной файл для вывода графика одним щелчком мыши.
6. Особенности кода: параметрическое программирование, параметры можно легко изменить, идеи программирования кода понятны, комментарии подробны.



%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
%% 数据归一化
[P_train, ps_input] = mapminmax(P_train, 0, 1);
P_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
%% 数据平铺
P_train = double(reshape(P_train, f_, 1, 1, M));
P_test = double(reshape(P_test , f_, 1, 1, N));
t_train = t_train';
t_test = t_test' ;
%% 数据格式转换
for i = 1 : M
p_train{i, 1} = P_train(:, :, 1, i);
end
for i = 1 : N
p_test{i, 1} = P_test( :, :, 1, i);
end
%% 参数设置
options = trainingOptions('adam', ... % Adam 梯度下降算法
'MaxEpochs', 100, ... % 最大训练次数
'InitialLearnRate', 0.01, ... % 初始学习率为0.01
'LearnRateSchedule', 'piecewise', ... % 学习率下降
'LearnRateDropFactor', 0.1, ... % 学习率下降因子 0.1
'LearnRateDropPeriod', 70, ... % 经过训练后 学习率为 0.01*0.1
'Shuffle', 'every-epoch', ... % 每次训练打乱数据集
'Verbose', 1);
figure
subplot(2,1,1)
plot(T_train,'k--','LineWidth',1.5);
hold on
plot(T_sim_a','r-','LineWidth',1.5)
legend('真实值','预测值')
title('CEEMDAN-VMD-CNN-GRU-Attention训练集预测效果对比')
xlabel('样本点')
ylabel('数值')
subplot(2,1,2)
bar(T_sim_a'-T_train)
title('CEEMDAN-VMD-GRU-Attention训练误差图')
xlabel('样本点')
ylabel('数值')
disp('…………测试集误差指标…………')
[mae2,rmse2,mape2,error2]=calc_error(T_test,T_sim_b');
fprintf('n')
figure
subplot(2,1,1)
plot(T_test,'k--','LineWidth',1.5);
hold on
plot(T_sim_b','b-','LineWidth',1.5)
legend('真实值','预测值')
title('CEEMDAN-VMD-GRU-Attention测试集预测效果对比')
xlabel('样本点')
ylabel('数值')
subplot(2,1,2)
bar(T_sim_b'-T_test)
title('CEEMDAN-VMD-GRU-Attention测试误差图')
xlabel('样本点')
ylabel('数值')
[1] https://hmlhml.blog.csdn.net/article/details/135536086?spm=1001.2014.3001.5502
[2] https://hmlhml.blog.csdn.net/article/details/137166860?spm=1001.2014.3001.5502
[3] https://hmlhml.blog.csdn.net/article/details/132372151

Он посвятил себя исследованию технологий более 30 лет и владеет различными языками, такими как Java, Linux, Javascript, php, css и т. д. Он внес большой вклад в область открытого исходного кода. Станция документации для разработчиков, где можно поделиться некоторыми проблемами в разработке технологий для дальнейшего использования. Все ознакомьтесь.

Почтамезофия@protonmail.com