τα στοιχεία επικοινωνίας μου
Ταχυδρομείο[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina







Υψηλή καινοτομία | CEEMDAN-VMD-GRU-Προσοχή διπλή αποσύνθεση + περιφραγμένη επαναλαμβανόμενη μονάδα + μηχανισμός προσοχής πολυμεταβλητή πρόβλεψη χρονοσειρών
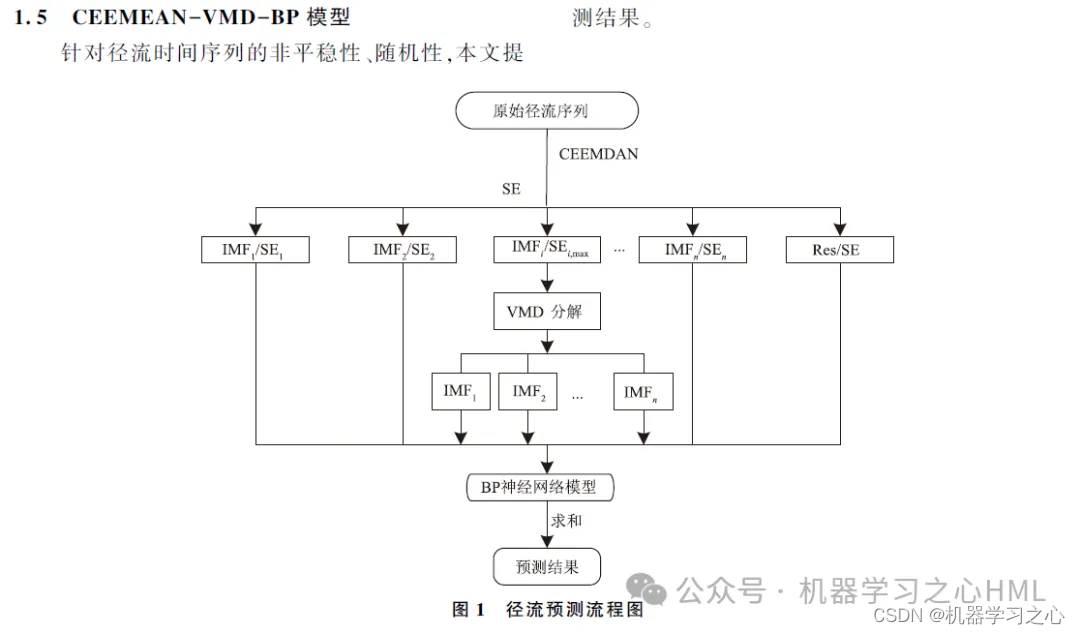
Αυτή η εργασία προτείνει μια δευτερεύουσα μέθοδο αποσύνθεσης που βασίζεται στο CEEMDAN, η οποία αναδομεί την ακολουθία που αποσυντίθεται από το CEEMDAN μέσω της εντροπίας του δείγματος.
1.Το Matlab εφαρμόζει CEEMDAN-VMD-GRU-Προσοχή διπλή αποσύνθεση + μονάδα κλειστού βρόχου + πολλαπλούς μηχανισμούς προσοχήςπρόβλεψη χρονοσειρών(Πλήρης πηγαίος κώδικας και δεδομένα)
2. Το CEEMDAN αποσυντίθεται, υπολογίζει την εντροπία του δείγματος, εκτελεί ομαδοποίηση kmeans με βάση την εντροπία του δείγματος, καλεί το VMD για να αποσυνθέσει το στοιχείο υψηλής συχνότητας δύο φορές και χρησιμοποιεί το στοιχείο υψηλής συχνότητας και το μπροστινό στοιχείο που αποσυντίθεται από το VMD ως κυκλική μονάδα με πύλη συνέλιξηςΜοντέλο μηχανισμού προσοχήςΟι έξοδοι στόχου προβλέπονται χωριστά και στη συνέχεια προστίθενται.
3. Πολυμεταβλητή μεμονωμένη έξοδος, εξετάστε την επιρροή των ιστορικών χαρακτηριστικών! Οι δείκτες αξιολόγησης περιλαμβάνουν R2, MAE, RMSE, MAPE κ.λπ.
4. Ο αλγόριθμος είναι νέος. Το μοντέλο CEEMDAN-VMD-GRU-Attention επεξεργάζεται δεδομένα με μεγαλύτερη ακρίβεια και μπορεί να παρακολουθεί τις τάσεις και τις αλλαγές δεδομένων. Το μοντέλο VMD χειρίζεται μη γραμμικά, μη στάσιμα και σύνθετα δεδομένα και αποδίδει καλύτερα από τη σειρά EMD, επομένως, τα ανακατασκευασμένα δεδομένα αποσυντίθενται μέσω του μοντέλου VMD για να βελτιωθεί η ακρίβεια του μοντέλου.
5. Μπορεί να χρησιμοποιηθεί αντικαθιστώντας απευθείας τα δεδομένα του Excel. Οι σχολιασμοί είναι σαφείς και κατάλληλοι για αρχάριους.
6. Χαρακτηριστικά κώδικα: παραμετρικός προγραμματισμός, οι παράμετροι μπορούν εύκολα να αλλάξουν, οι ιδέες προγραμματισμού κώδικα είναι σαφείς και τα σχόλια είναι λεπτομερή.



%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
%% 数据归一化
[P_train, ps_input] = mapminmax(P_train, 0, 1);
P_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
%% 数据平铺
P_train = double(reshape(P_train, f_, 1, 1, M));
P_test = double(reshape(P_test , f_, 1, 1, N));
t_train = t_train';
t_test = t_test' ;
%% 数据格式转换
for i = 1 : M
p_train{i, 1} = P_train(:, :, 1, i);
end
for i = 1 : N
p_test{i, 1} = P_test( :, :, 1, i);
end
%% 参数设置
options = trainingOptions('adam', ... % Adam 梯度下降算法
'MaxEpochs', 100, ... % 最大训练次数
'InitialLearnRate', 0.01, ... % 初始学习率为0.01
'LearnRateSchedule', 'piecewise', ... % 学习率下降
'LearnRateDropFactor', 0.1, ... % 学习率下降因子 0.1
'LearnRateDropPeriod', 70, ... % 经过训练后 学习率为 0.01*0.1
'Shuffle', 'every-epoch', ... % 每次训练打乱数据集
'Verbose', 1);
figure
subplot(2,1,1)
plot(T_train,'k--','LineWidth',1.5);
hold on
plot(T_sim_a','r-','LineWidth',1.5)
legend('真实值','预测值')
title('CEEMDAN-VMD-CNN-GRU-Attention训练集预测效果对比')
xlabel('样本点')
ylabel('数值')
subplot(2,1,2)
bar(T_sim_a'-T_train)
title('CEEMDAN-VMD-GRU-Attention训练误差图')
xlabel('样本点')
ylabel('数值')
disp('…………测试集误差指标…………')
[mae2,rmse2,mape2,error2]=calc_error(T_test,T_sim_b');
fprintf('n')
figure
subplot(2,1,1)
plot(T_test,'k--','LineWidth',1.5);
hold on
plot(T_sim_b','b-','LineWidth',1.5)
legend('真实值','预测值')
title('CEEMDAN-VMD-GRU-Attention测试集预测效果对比')
xlabel('样本点')
ylabel('数值')
subplot(2,1,2)
bar(T_sim_b'-T_test)
title('CEEMDAN-VMD-GRU-Attention测试误差图')
xlabel('样本点')
ylabel('数值')
[1] https://hmlhml.blog.csdn.net/article/details/135536086?spm=1001.2014.3001.5502
[2] https://hmlhml.blog.csdn.net/article/details/137166860?spm=1001.2014.3001.5502
[3] https://hmlhml.blog.csdn.net/article/details/132372151

Έχει αφοσιωθεί στην έρευνα της τεχνολογίας για περισσότερα από 30 χρόνια και είναι ικανός σε διάφορες γλώσσες όπως java, linux, javascript, php, css κ.λπ. Έχει κάνει πολλές συνεισφορές στον τομέα του ανοιχτού κώδικα σταθμός τεκμηρίωσης προγραμματιστή για να μοιραστείτε ορισμένα ζητήματα στην ανάπτυξη τεχνολογίας για μελλοντική αναφορά

Ταχυδρομείο[email protected]