2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina







उच्च नवीनता | सीएमदान-VMD-GRU-ध्यान द्वय अपघटन + गेटेड पुनरावर्ती इकाई + ध्यान तंत्र बहुचर समय श्रृंखला भविष्यवाणी
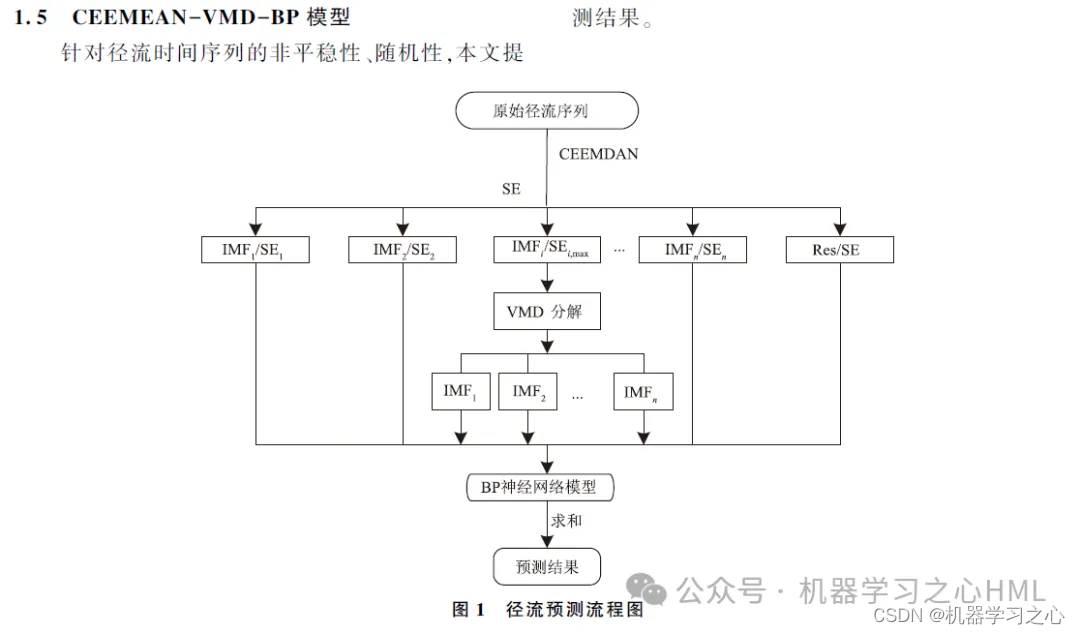
अस्मिन् पत्रे CEEMDAN इत्यस्य आधारेण गौणविघटनपद्धतिः प्रस्ताविता अस्ति, या नमूना एन्ट्रोपीद्वारा CEEMDAN द्वारा विघटितस्य अनुक्रमस्य पुनर्निर्माणं करोति VMD द्वारा जटिलक्रमस्य विघटनस्य अनन्तरं प्रत्येकस्य घटकस्य पूर्वानुमानं GRU-Attention मॉडलेन क्रियते, अन्ते च भविष्यवाणीपरिणामाः एकीकृताः भवन्ति
1.Matlab CEEMDAN-VMD-GRU-Attention द्वय अपघटन + गेटेड लूप यूनिट + बहु ध्यान तंत्र कार्यान्वित करतासमयश्रृङ्खला पूर्वानुमान(सम्पूर्णः स्रोतसङ्केतः दत्तांशः च)
2. CEEMDAN विघटयति, नमूना एन्ट्रोपी गणयति, नमूना एन्ट्रोपी इत्यस्य आधारेण kmeans क्लस्टरिंग् करोति, उच्च-आवृत्ति-घटकस्य द्विवारं विघटनार्थं VMD इति आह्वयति, तथा च उच्च-आवृत्ति-घटकस्य तथा VMD द्वारा विघटितस्य अग्रघटकस्य च उपयोगं कन्वोल्यूशन गेटेड् चक्रीय-एककरूपेण करोतिध्यान तन्त्र प्रतिरूपलक्ष्यनिर्गमाः पृथक् पृथक् पूर्वानुमानिताः भवन्ति ततः योजिताः भवन्ति ।
3. बहु-चर एकल उत्पादन, ऐतिहासिक विशेषताओं के प्रभाव पर विचार करें! मूल्याङ्कनसूचकेषु R2, MAE, RMSE, MAPE इत्यादयः सन्ति ।
4. अल्गोरिदम् नवीनम् अस्ति। CEEMDAN-VMD-GRU-Attention मॉडल् अधिकसटीकतया आँकडानां संसाधनं करोति तथा च आँकडाप्रवृत्तिं परिवर्तनं च निरीक्षितुं शक्नोति । वीएमडी-प्रतिरूपं अरैखिक, अस्थिर-जटिल-दत्तांशं सम्पादयति तथा च ईएमडी-श्रृङ्खलायाः अपेक्षया उत्तमं प्रदर्शनं करोति अतः पुनर्निर्मित-आँकडानां विघटनं वीएमडी-प्रतिरूपस्य माध्यमेन भवति, येन मॉडलस्य सटीकतायां सुधारः भवति
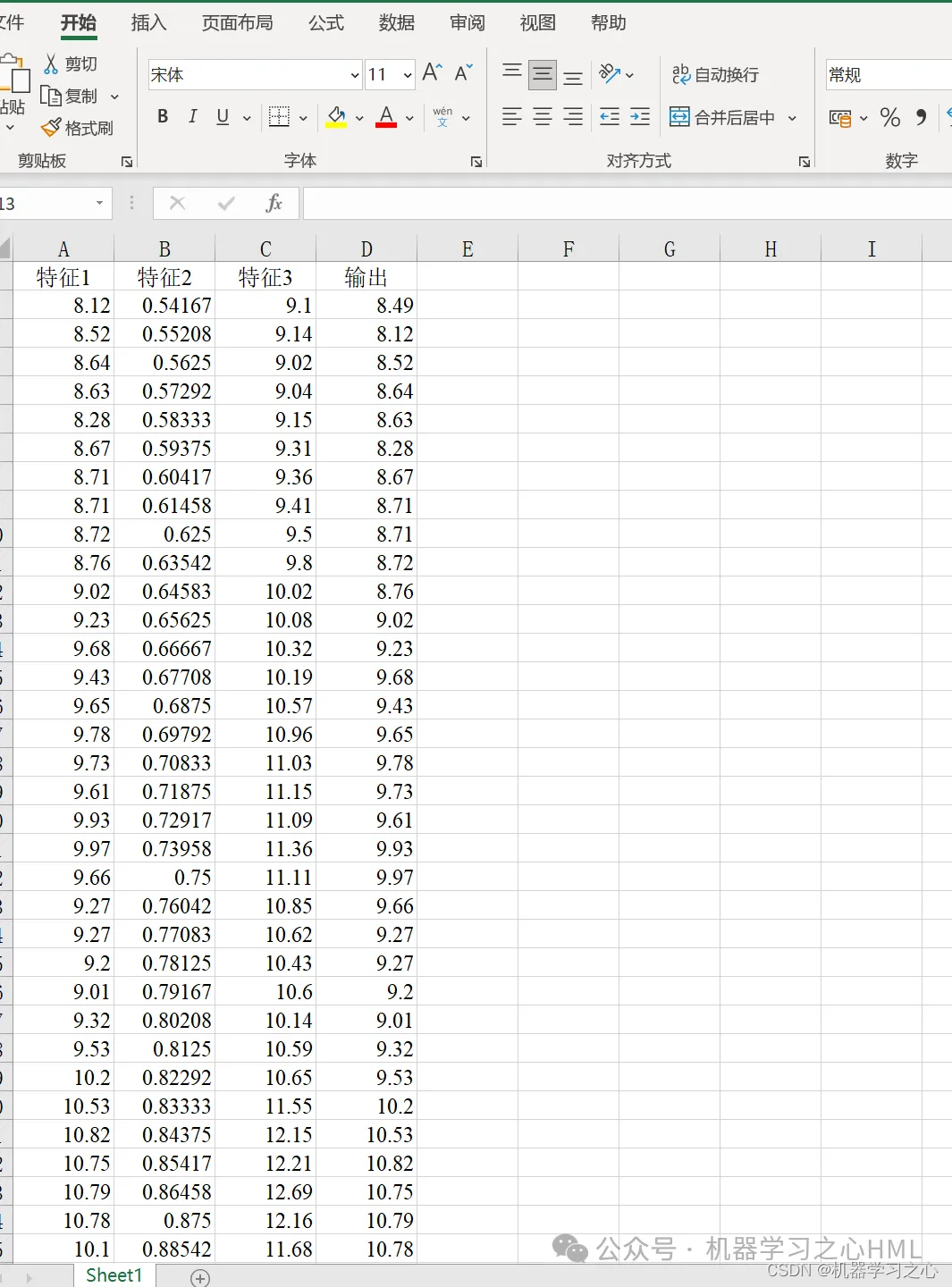
5. Excel data इत्यस्य स्थाने प्रत्यक्षतया उपयोगः कर्तुं शक्यते ।
6. कोडविशेषताः : पैरामीटरिकप्रोग्रामिंग्, पैरामीटर्स् सहजतया परिवर्तयितुं शक्यन्ते, कोडप्रोग्रामिंगविचाराः स्पष्टाः सन्ति, टिप्पण्याः च विस्तृताः सन्ति।



%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
%% 数据归一化
[P_train, ps_input] = mapminmax(P_train, 0, 1);
P_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
%% 数据平铺
P_train = double(reshape(P_train, f_, 1, 1, M));
P_test = double(reshape(P_test , f_, 1, 1, N));
t_train = t_train';
t_test = t_test' ;
%% 数据格式转换
for i = 1 : M
p_train{i, 1} = P_train(:, :, 1, i);
end
for i = 1 : N
p_test{i, 1} = P_test( :, :, 1, i);
end
%% 参数设置
options = trainingOptions('adam', ... % Adam 梯度下降算法
'MaxEpochs', 100, ... % 最大训练次数
'InitialLearnRate', 0.01, ... % 初始学习率为0.01
'LearnRateSchedule', 'piecewise', ... % 学习率下降
'LearnRateDropFactor', 0.1, ... % 学习率下降因子 0.1
'LearnRateDropPeriod', 70, ... % 经过训练后 学习率为 0.01*0.1
'Shuffle', 'every-epoch', ... % 每次训练打乱数据集
'Verbose', 1);
figure
subplot(2,1,1)
plot(T_train,'k--','LineWidth',1.5);
hold on
plot(T_sim_a','r-','LineWidth',1.5)
legend('真实值','预测值')
title('CEEMDAN-VMD-CNN-GRU-Attention训练集预测效果对比')
xlabel('样本点')
ylabel('数值')
subplot(2,1,2)
bar(T_sim_a'-T_train)
title('CEEMDAN-VMD-GRU-Attention训练误差图')
xlabel('样本点')
ylabel('数值')
disp('…………测试集误差指标…………')
[mae2,rmse2,mape2,error2]=calc_error(T_test,T_sim_b');
fprintf('n')
figure
subplot(2,1,1)
plot(T_test,'k--','LineWidth',1.5);
hold on
plot(T_sim_b','b-','LineWidth',1.5)
legend('真实值','预测值')
title('CEEMDAN-VMD-GRU-Attention测试集预测效果对比')
xlabel('样本点')
ylabel('数值')
subplot(2,1,2)
bar(T_sim_b'-T_test)
title('CEEMDAN-VMD-GRU-Attention测试误差图')
xlabel('样本点')
ylabel('数值')
[1] https://hmlhml.blog.csdn.net/लेख/विवरण/135536086?spm=1001.2014.3001.5502
[2] https://hmlhml.blog.csdn.net/लेख/विवरण/137166860?spm=1001.2014.3001.5502
[3] https://hmlhml.blog.csdn.net/लेख/विवरण/132372151

सः ३० वर्षाणाम् अधिकं कालात् प्रौद्योगिक्याः शोधकार्यं कर्तुं समर्पितः अस्ति, तथा च जावा, लिनक्स, जावास्क्रिप्ट्, php, css इत्यादिषु विविधभाषासु प्रवीणः अस्ति, मुक्तस्रोतक्षेत्रे सः बहु योगदानं कृतवान् अस्ति विकासक दस्तावेजीकरणस्थानकं भविष्ये सन्दर्भार्थं प्रौद्योगिकीविकासे केचन विषयाः साझां कर्तुं सर्वे तत् पश्यन्तु
