minhas informações de contato
Correspondência[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina







Alta inovação | CEEMDÃO-VMD-GRU-Decomposição dupla de atenção + unidade recorrente fechada + mecanismo de atenção previsão de série temporal multivariada
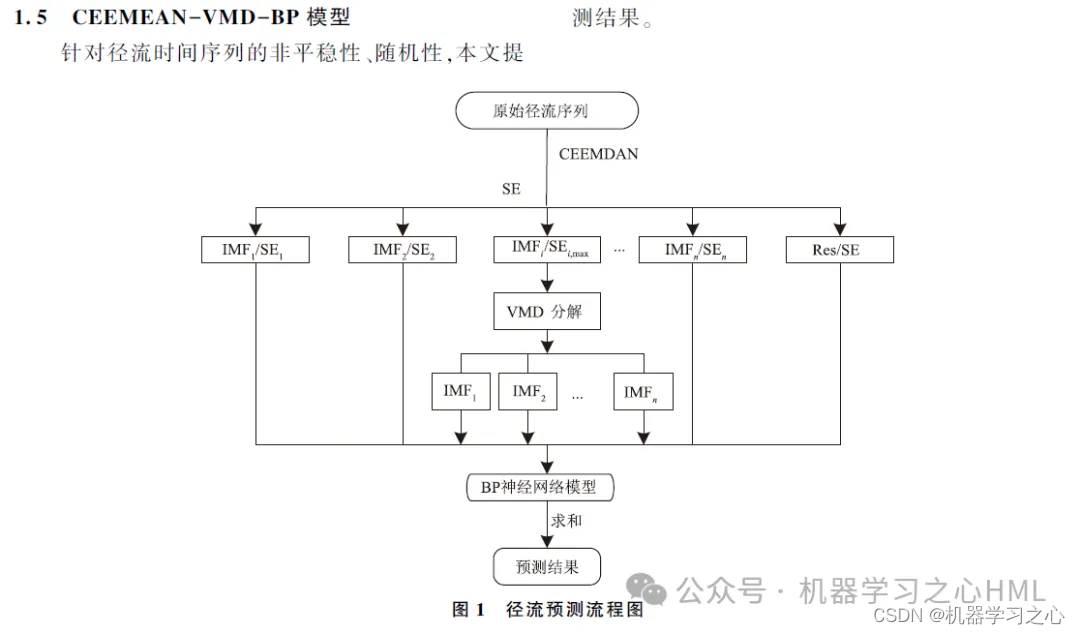
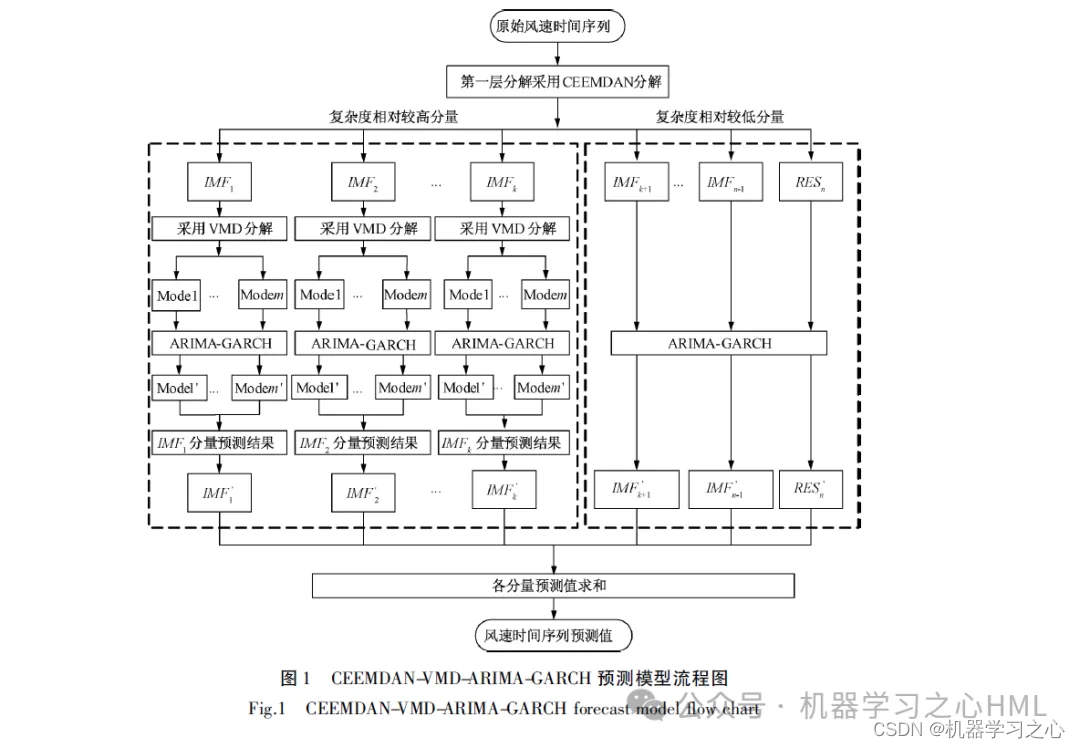
Este artigo propõe um método de decomposição secundária baseado no CEEMDAN, que reconstrói a sequência decomposta pelo CEEMDAN através da entropia da amostra. Após a sequência complexa ser decomposta pelo VMD, cada componente é previsto pelo modelo GRU-Attention e os resultados da predição são finalmente integrados.
1.Matlab implementa decomposição dupla CEEMDAN-VMD-GRU-Atenção + unidade de loop fechado + múltiplos mecanismos de atençãoprevisão de série temporal(Código-fonte completo e dados)
2. CEEMDAN decompõe, calcula a entropia da amostra, realiza agrupamento kmeans com base na entropia da amostra, chama VMD para decompor o componente de alta frequência duas vezes e usa o componente de alta frequência e o componente frontal decomposto pelo VMD como uma unidade cíclica controlada por convoluçãoModelo de mecanismo de atençãoOs resultados alvo são previstos separadamente e depois adicionados.
3. Saída única multivariável, considere a influência das características históricas! Os indicadores de avaliação incluem R2, MAE, RMSE, MAPE, etc.
4. O algoritmo é novo. O modelo CEEMDAN-VMD-GRU-Attention processa dados com maior precisão e pode rastrear tendências e mudanças nos dados. O modelo VMD lida com dados não lineares, não estacionários e complexos e tem melhor desempenho que a série EMD. Portanto, os dados reconstruídos são decompostos por meio do modelo VMD para melhorar a precisão do modelo.
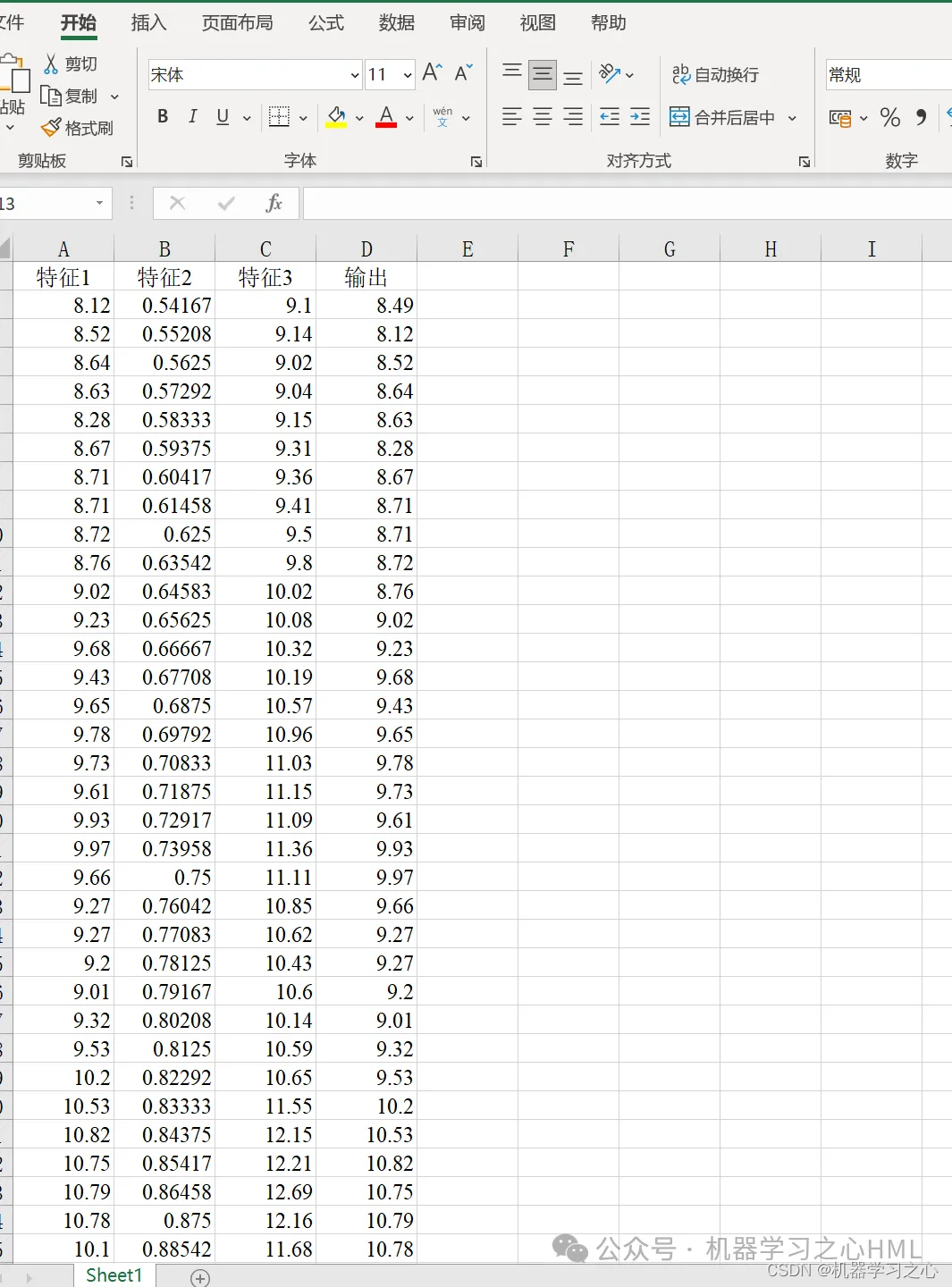
5. Pode ser usado substituindo diretamente os dados do Excel. As anotações são claras e adequadas para iniciantes. Você pode executar diretamente o arquivo principal para gerar o gráfico com um clique.
6. Recursos de código: programação paramétrica, parâmetros podem ser facilmente alterados, ideias de programação de código são claras e comentários são detalhados.



%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
%% 数据归一化
[P_train, ps_input] = mapminmax(P_train, 0, 1);
P_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
%% 数据平铺
P_train = double(reshape(P_train, f_, 1, 1, M));
P_test = double(reshape(P_test , f_, 1, 1, N));
t_train = t_train';
t_test = t_test' ;
%% 数据格式转换
for i = 1 : M
p_train{i, 1} = P_train(:, :, 1, i);
end
for i = 1 : N
p_test{i, 1} = P_test( :, :, 1, i);
end
%% 参数设置
options = trainingOptions('adam', ... % Adam 梯度下降算法
'MaxEpochs', 100, ... % 最大训练次数
'InitialLearnRate', 0.01, ... % 初始学习率为0.01
'LearnRateSchedule', 'piecewise', ... % 学习率下降
'LearnRateDropFactor', 0.1, ... % 学习率下降因子 0.1
'LearnRateDropPeriod', 70, ... % 经过训练后 学习率为 0.01*0.1
'Shuffle', 'every-epoch', ... % 每次训练打乱数据集
'Verbose', 1);
figure
subplot(2,1,1)
plot(T_train,'k--','LineWidth',1.5);
hold on
plot(T_sim_a','r-','LineWidth',1.5)
legend('真实值','预测值')
title('CEEMDAN-VMD-CNN-GRU-Attention训练集预测效果对比')
xlabel('样本点')
ylabel('数值')
subplot(2,1,2)
bar(T_sim_a'-T_train)
title('CEEMDAN-VMD-GRU-Attention训练误差图')
xlabel('样本点')
ylabel('数值')
disp('…………测试集误差指标…………')
[mae2,rmse2,mape2,error2]=calc_error(T_test,T_sim_b');
fprintf('n')
figure
subplot(2,1,1)
plot(T_test,'k--','LineWidth',1.5);
hold on
plot(T_sim_b','b-','LineWidth',1.5)
legend('真实值','预测值')
title('CEEMDAN-VMD-GRU-Attention测试集预测效果对比')
xlabel('样本点')
ylabel('数值')
subplot(2,1,2)
bar(T_sim_b'-T_test)
title('CEEMDAN-VMD-GRU-Attention测试误差图')
xlabel('样本点')
ylabel('数值')
[1] https://hmlhml.blog.csdn.net/article/details/135536086?spm=1001.2014.3001.5502
[2] https://hmlhml.blog.csdn.net/article/details/137166860?spm=1001.2014.3001.5502
[3] https://hmlhml.blog.csdn.net/article/details/132372151

Ele se dedica à pesquisa de tecnologia há mais de 30 anos e é proficiente em diversas linguagens como java, linux, javascript, php, css, etc. estação de documentação do desenvolvedor para compartilhar alguns problemas no desenvolvimento de tecnologia para referência futura.

Correspondência[email protected]