2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
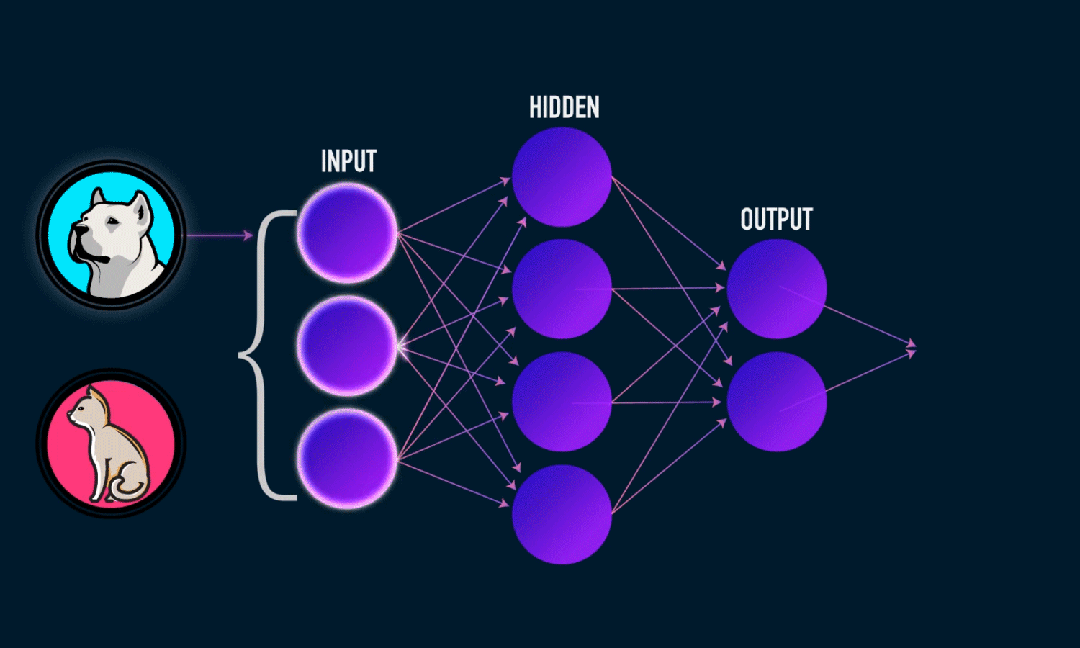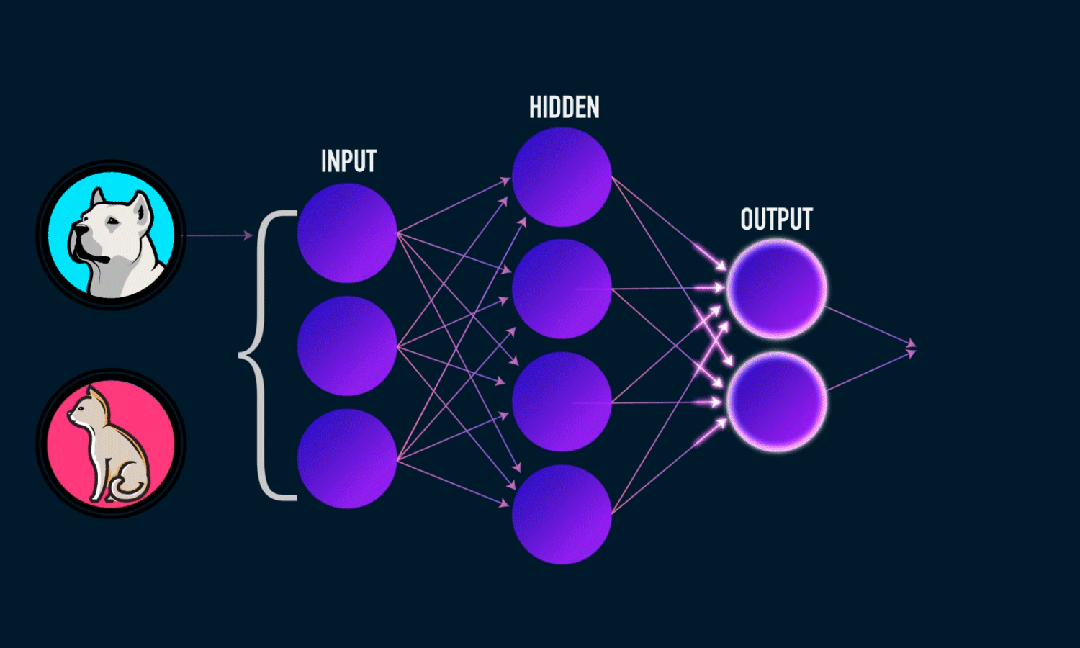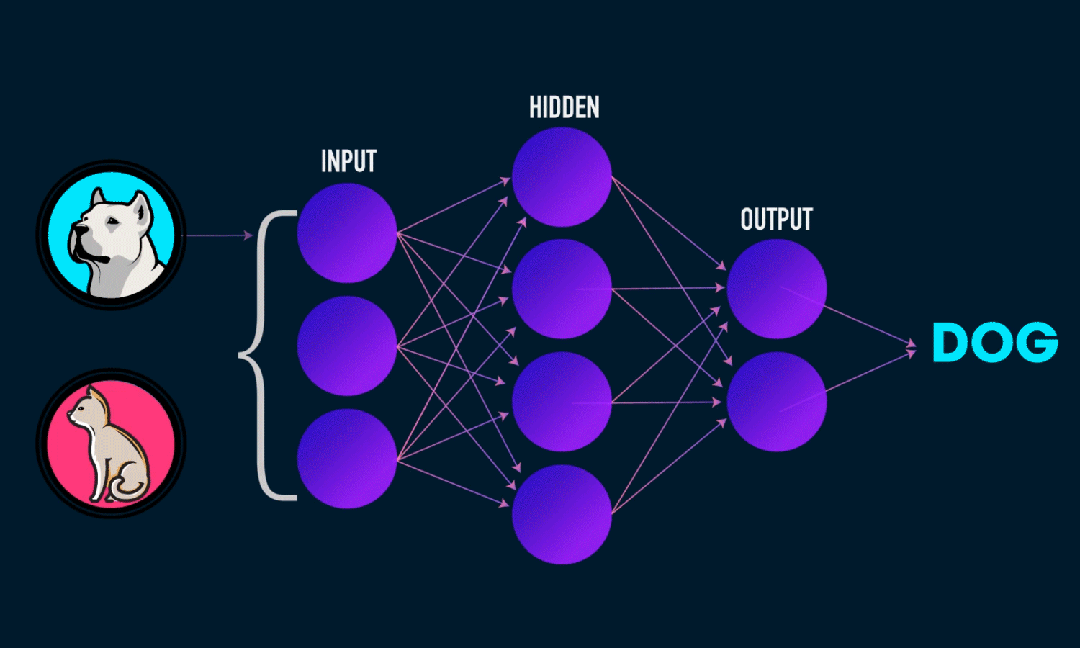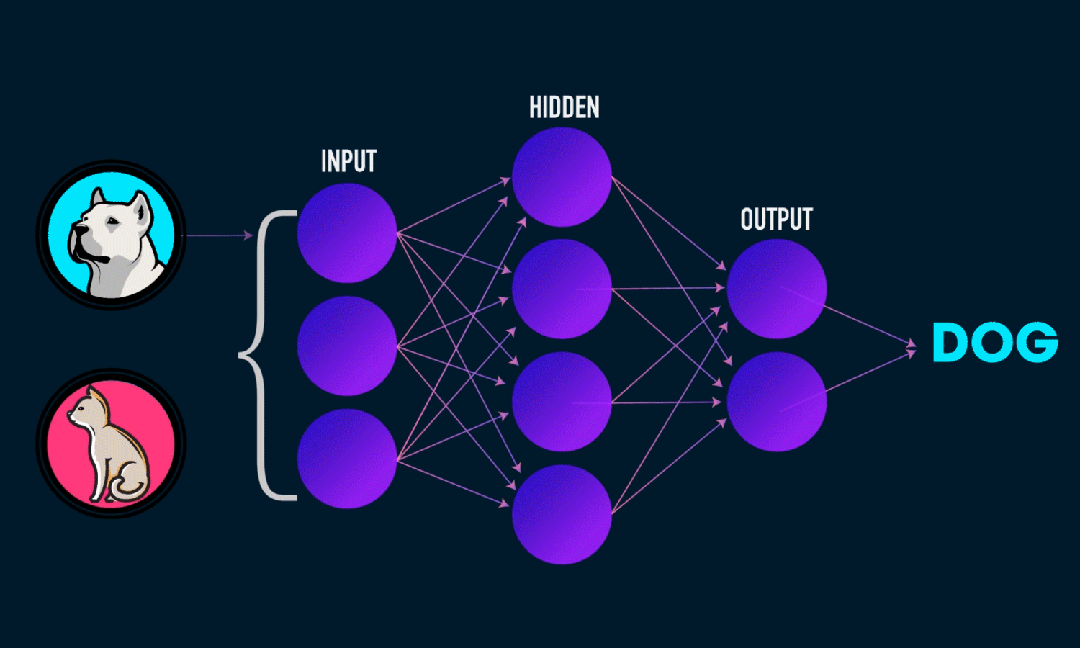
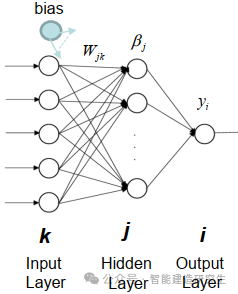
Extreme Learning Machine (ELM) ist ein einfacher Lernalgorithmus für einschichtige Feedforward-Neuronale Netzwerke (SLFN). Theoretisch bieten extrem lernende maschinelle Algorithmen (ELM) tendenziell eine gute Leistung (gehören zu maschinellen Lernalgorithmen) mit extrem hohen Lerngeschwindigkeiten und wurden von Huang et al. vorgeschlagen. Das Hauptmerkmal von ELM ist, dass seine Lerngeschwindigkeit im Vergleich zu herkömmlichen Gradientenabstiegsmethoden (wie dem neuronalen BP-Netzwerk) sehr hoch ist. Das Grundprinzip besteht darin, die Gewichte und Verzerrungen der verborgenen Schicht zufällig auszuwählen und dann die Ausgabegewichte zu lernen, indem der Fehler der Ausgabeschicht minimiert wird.
img
Initialisieren Sie die Gewichtungen und Bias, die in die verborgene Ebene eingegeben werden, nach dem Zufallsprinzip:
Die Gewichte und Verzerrungen der verborgenen Schichten werden zufällig generiert und bleiben während des Trainings konstant.
Berechnen Sie die Ausgabematrix der verborgenen Schicht (d. h. die Ausgabe der Aktivierungsfunktion).:
Berechnen Sie die Ausgabe der verborgenen Ebene mithilfe einer Aktivierungsfunktion (z. B. Sigmoid, ReLU usw.).
Ausgangsgewicht berechnen:
Die Gewichte von der verborgenen Schicht zur Ausgabeschicht werden nach der Methode der kleinsten Quadrate berechnet.
Die mathematische Formel von ELM lautet wie folgt:
Gegeben sei ein Trainingsdatensatz, wobei:
Die Berechnungsformel der Ausgabematrix der verborgenen Schicht lautet:
Dabei ist die Eingabematrix, die in die verborgene Schicht eingegebene Gewichtsmatrix, der Bias-Vektor und die Aktivierungsfunktion.
Die Berechnungsformel des Ausgabegewichts lautet:
Dabei ist die verallgemeinerte Umkehrung der Ausgabematrix der verborgenen Schicht die Ausgabematrix.
Verarbeitung großer Datensätze: ELM bietet eine gute Leistung bei der Verarbeitung großer Datensätze, da seine Trainingsgeschwindigkeit sehr hoch ist und sich für Szenarien eignet, die ein schnelles Training von Modellen erfordern, wie z. B. die Klassifizierung großer Bilder, die Verarbeitung natürlicher Sprache und andere Aufgaben.
Branchenprognose : ELM verfügt über ein breites Anwendungsspektrum im Bereich der industriellen Vorhersage, beispielsweise zur Qualitätskontrolle und zur Vorhersage von Geräteausfällen in industriellen Produktionsprozessen. Es kann schnell Vorhersagemodelle trainieren und schnell auf Echtzeitdaten reagieren.
Der Finanzsektor : ELM kann für die Analyse und Vorhersage von Finanzdaten verwendet werden, z. B. Aktienkursvorhersage, Risikomanagement, Kreditbewertung usw. Da Finanzdaten in der Regel hochdimensional sind, ist die schnelle Trainingsgeschwindigkeit von ELM für die Verarbeitung dieser Daten von Vorteil.
medizinische Diagnose : Im medizinischen Bereich kann ELM für Aufgaben wie Krankheitsvorhersage und medizinische Bildanalyse eingesetzt werden. Es kann Modelle schnell trainieren und Patientendaten klassifizieren oder regressieren, was Ärzten hilft, schnellere und genauere Diagnosen zu stellen.
Intelligentes Steuerungssystem : ELM kann in intelligenten Steuerungssystemen wie Smart Homes, intelligenten Transportsystemen usw. eingesetzt werden. Durch das Erlernen der Eigenschaften und Muster der Umgebung kann ELM dem System helfen, intelligente Entscheidungen zu treffen und die Systemeffizienz und -leistung zu verbessern.
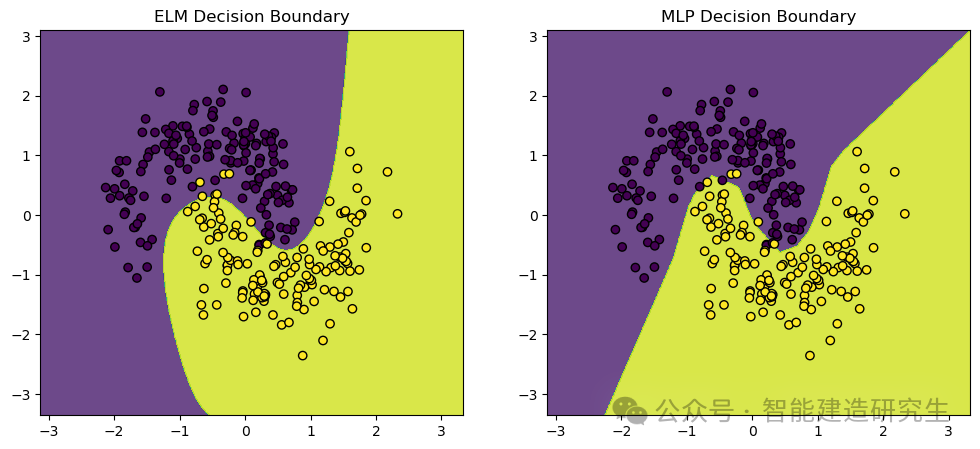
Wir gebrauchenmake_moons Datensatz, ein Spielzeugdatensatz, der häufig für maschinelles Lernen und Deep-Learning-Klassifizierungsaufgaben verwendet wird. Es generiert Punkte, die in zwei sich schneidenden Halbmondformen verteilt sind und sich ideal zur Demonstration der Leistungs- und Entscheidungsgrenzen von Klassifizierungsalgorithmen eignen.
- import numpy as np
- import matplotlib.pyplot as plt
- from sklearn.datasets import make_moons
- from sklearn.model_selection import train_test_split
- from sklearn.neural_network import MLPClassifier
- from sklearn.preprocessing import StandardScaler
- from sklearn.metrics import accuracy_score
-
- # 定义极限学习机(ELM)类
- class ELM:
- def __init__(self, n_hidden_units):
- # 初始化隐藏层神经元数量
- self.n_hidden_units = n_hidden_units
-
- def _sigmoid(self, x):
- # 定义Sigmoid激活函数
- return 1 / (1 + np.exp(-x))
-
- def fit(self, X, y):
- # 随机初始化输入权重
- self.input_weights = np.random.randn(X.shape[1], self.n_hidden_units)
- # 随机初始化偏置
- self.biases = np.random.randn(self.n_hidden_units)
- # 计算隐藏层输出矩阵H
- H = self._sigmoid(np.dot(X, self.input_weights) + self.biases)
- # 计算输出权重
- self.output_weights = np.dot(np.linalg.pinv(H), y)
-
- def predict(self, X):
- # 计算隐藏层输出矩阵H
- H = self._sigmoid(np.dot(X, self.input_weights) + self.biases)
- # 返回预测结果
- return np.dot(H, self.output_weights)
-
- # 创建数据集并进行预处理
- X, y = make_moons(n_samples=1000, noise=0.2, random_state=42)
- # 将标签转换为二维数组(ELM需要二维数组作为标签)
- y = y.reshape(-1, 1)
-
- # 标准化数据
- scaler = StandardScaler()
- X_scaled = scaler.fit_transform(X)
-
- # 拆分训练集和测试集
- X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42)
-
- # 训练和比较ELM与MLP
-
- # 训练ELM
- elm = ELM(n_hidden_units=10)
- elm.fit(X_train, y_train)
- y_pred_elm = elm.predict(X_test)
- # 将预测结果转换为类别标签
- y_pred_elm_class = (y_pred_elm > 0.5).astype(int)
- # 计算ELM的准确率
- accuracy_elm = accuracy_score(y_test, y_pred_elm_class)
-
- # 训练MLP
- mlp = MLPClassifier(hidden_layer_sizes=(10,), max_iter=1000, random_state=42)
- mlp.fit(X_train, y_train.ravel())
- # 预测测试集结果
- y_pred_mlp = mlp.predict(X_test)
- # 计算MLP的准确率
- accuracy_mlp = accuracy_score(y_test, y_pred_mlp)
-
- # 打印ELM和MLP的准确率
- print(f"ELM Accuracy: {accuracy_elm}")
- print(f"MLP Accuracy: {accuracy_mlp}")
-
- # 可视化结果
- def plot_decision_boundary(model, X, y, ax, title):
- # 设置绘图范围
- x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
- y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
- # 创建网格
- xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01),
- np.arange(y_min, y_max, 0.01))
- # 预测网格中的所有点
- Z = model(np.c_[xx.ravel(), yy.ravel()])
- Z = (Z > 0.5).astype(int)
- Z = Z.reshape(xx.shape)
- # 画出决策边界
- ax.contourf(xx, yy, Z, alpha=0.8)
- # 画出数据点
- ax.scatter(X[:, 0], X[:, 1], c=y.ravel(), edgecolors='k', marker='o')
- ax.set_title(title)
-
- # 创建图形
- fig, axs = plt.subplots(1, 2, figsize=(12, 5))
-
- # 画出ELM的决策边界
- plot_decision_boundary(lambda x: elm.predict(x), X_test, y_test, axs[0], "ELM Decision Boundary")
- # 画出MLP的决策边界
- plot_decision_boundary(lambda x: mlp.predict(x), X_test, y_test, axs[1], "MLP Decision Boundary")
-
- # 显示图形
- plt.show()
-
- # 输出:
- '''
- ELM Accuracy: 0.9666666666666667
- MLP Accuracy: 0.9766666666666667
- '''
Visuelle Ausgabe:
Der obige Inhalt ist aus dem Internet zusammengefasst. Wenn er hilfreich ist, leiten Sie ihn bitte weiter.

Er widmet sich seit mehr als 30 Jahren der Technologieforschung und beherrscht verschiedene Sprachen wie Java, Linux, Javascript, PHP, CSS usw. Er hat viele Beiträge im Open-Source-Bereich geleistet, Entwicklerdokumentationsstation, um einige Themen in der Technologieentwicklung als zukünftige Referenz zu teilen

