
informasi kontak saya
Surat[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
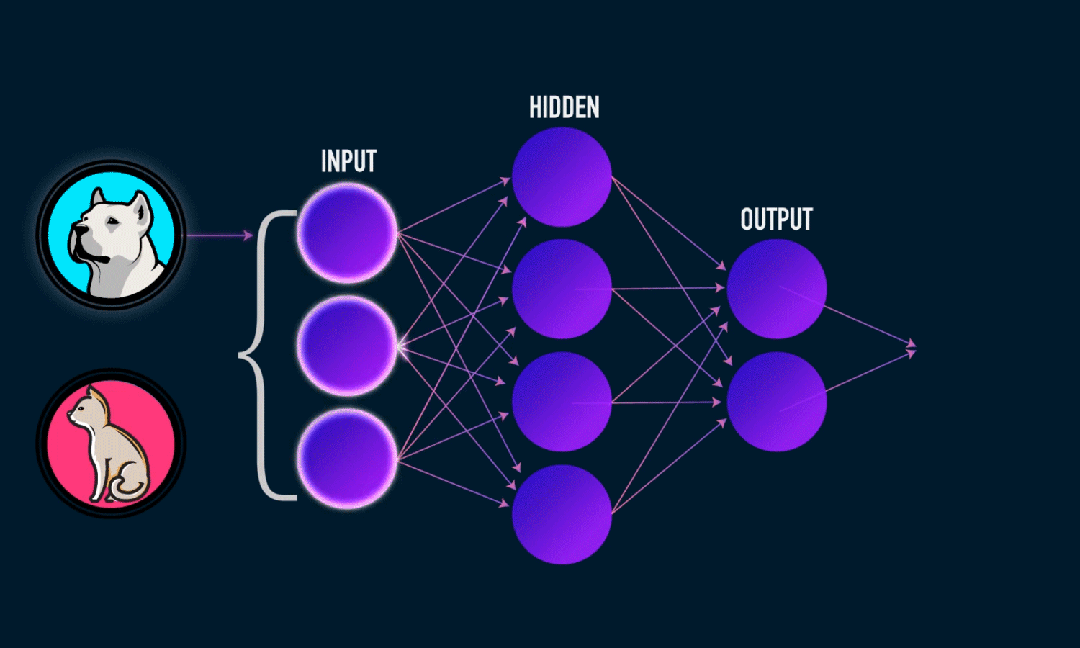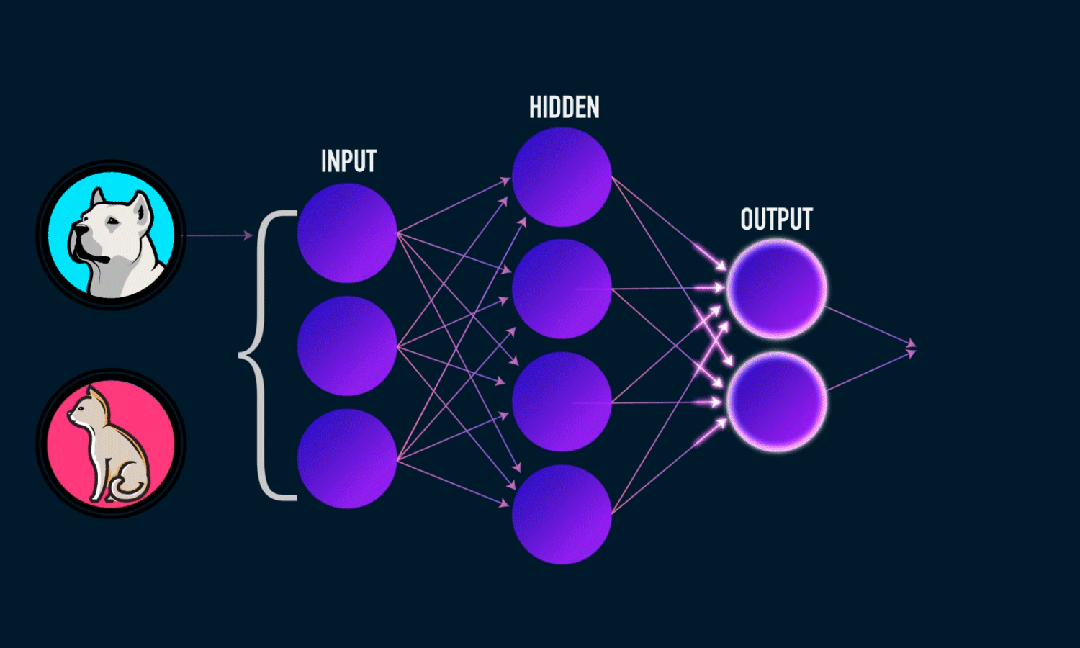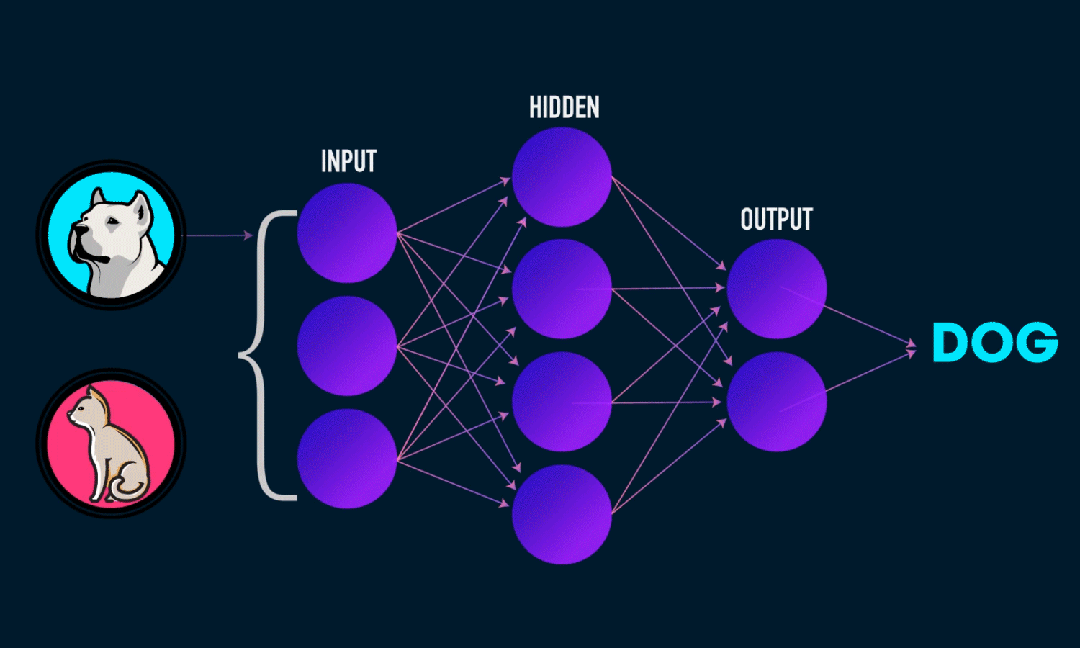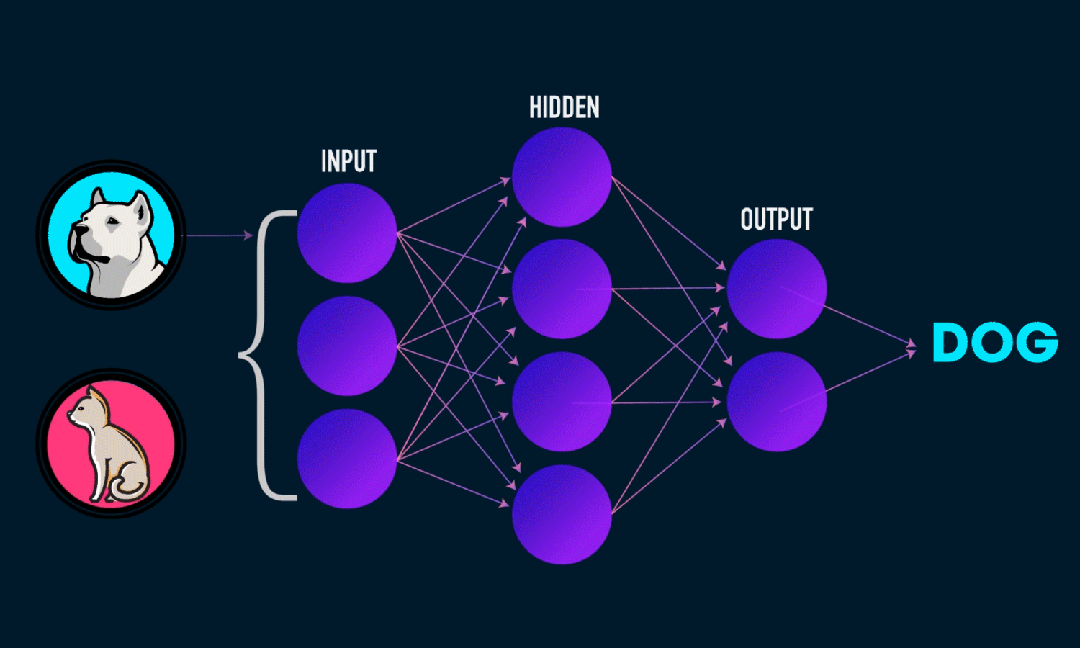
Extreme Learning Machine (ELM) adalah algoritma pembelajaran jaringan saraf umpan maju (SLFN) satu lapis sederhana. Secara teori, algoritma mesin pembelajaran ekstrim (ELM) cenderung memberikan kinerja yang baik (termasuk algoritma pembelajaran mesin) dengan kecepatan pembelajaran yang sangat cepat, dan diusulkan oleh Huang et al. Fitur utama ELM adalah kecepatan pembelajarannya yang sangat cepat. Dibandingkan dengan metode penurunan gradien tradisional (seperti jaringan saraf BP), ELM tidak memerlukan proses berulang. Prinsip dasarnya adalah memilih secara acak bobot dan bias dari lapisan tersembunyi, lalu mempelajari bobot keluaran dengan meminimalkan kesalahan pada lapisan keluaran.
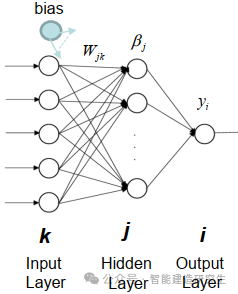
gambar
Inisialisasi input bobot dan bias ke lapisan tersembunyi secara acak:
Bobot dan bias dari lapisan tersembunyi dihasilkan secara acak dan tetap konstan selama pelatihan.
Hitung matriks keluaran dari lapisan tersembunyi (yaitu keluaran dari fungsi aktivasi):
Hitung keluaran lapisan tersembunyi menggunakan fungsi aktivasi (seperti sigmoid, ReLU, dll).
Hitung berat keluaran:
Bobot dari lapisan tersembunyi hingga lapisan keluaran dihitung dengan metode kuadrat terkecil.
Rumus matematika ELM adalah sebagai berikut:
Diberikan kumpulan data pelatihan, di mana,
Rumus perhitungan matriks keluaran lapisan tersembunyi adalah:
dimana adalah matriks masukan, adalah matriks bobot yang dimasukkan ke lapisan tersembunyi, adalah vektor bias, dan merupakan fungsi aktivasi.
Rumus perhitungan bobot keluaran adalah:
dimana adalah kebalikan umum dari matriks keluaran lapisan tersembunyi dan merupakan matriks keluaran.
Pemrosesan kumpulan data skala besar: ELM berkinerja baik saat memproses kumpulan data skala besar karena kecepatan pelatihannya sangat cepat dan cocok untuk skenario yang memerlukan pelatihan model cepat, seperti klasifikasi gambar skala besar, pemrosesan bahasa alami, dan tugas lainnya.
Prakiraan Industri : ELM memiliki berbagai aplikasi dalam bidang prediksi industri, seperti pengendalian kualitas dan prediksi kegagalan peralatan dalam proses produksi industri. Ini dapat dengan cepat melatih model prediktif dan merespons data real-time dengan cepat.
Sektor keuangan : ELM dapat digunakan untuk analisis dan prediksi data keuangan, seperti prediksi harga saham, manajemen risiko, credit scoring, dll. Karena data keuangan biasanya berdimensi tinggi, kecepatan pelatihan ELM yang cepat bermanfaat untuk memproses data ini.
diagnosa medis : Di bidang medis, ELM dapat digunakan untuk tugas-tugas seperti prediksi penyakit dan analisis citra medis. Ini dapat dengan cepat melatih model dan mengklasifikasikan atau mengembalikan data pasien, membantu dokter membuat diagnosis lebih cepat dan akurat.
Sistem kontrol cerdas : ELM dapat digunakan dalam sistem kontrol cerdas, seperti rumah pintar, sistem transportasi cerdas, dll. Dengan mempelajari karakteristik dan pola lingkungan, ELM dapat membantu sistem membuat keputusan cerdas serta meningkatkan efisiensi dan kinerja sistem.
Kita gunakanmake_moons Kumpulan data, kumpulan data mainan yang biasa digunakan untuk pembelajaran mesin dan tugas klasifikasi pembelajaran mendalam. Ini menghasilkan titik-titik yang didistribusikan ke dalam dua bentuk setengah bulan yang berpotongan, ideal untuk menunjukkan kinerja dan batasan keputusan algoritma klasifikasi.
- import numpy as np
- import matplotlib.pyplot as plt
- from sklearn.datasets import make_moons
- from sklearn.model_selection import train_test_split
- from sklearn.neural_network import MLPClassifier
- from sklearn.preprocessing import StandardScaler
- from sklearn.metrics import accuracy_score
-
- # 定义极限学习机(ELM)类
- class ELM:
- def __init__(self, n_hidden_units):
- # 初始化隐藏层神经元数量
- self.n_hidden_units = n_hidden_units
-
- def _sigmoid(self, x):
- # 定义Sigmoid激活函数
- return 1 / (1 + np.exp(-x))
-
- def fit(self, X, y):
- # 随机初始化输入权重
- self.input_weights = np.random.randn(X.shape[1], self.n_hidden_units)
- # 随机初始化偏置
- self.biases = np.random.randn(self.n_hidden_units)
- # 计算隐藏层输出矩阵H
- H = self._sigmoid(np.dot(X, self.input_weights) + self.biases)
- # 计算输出权重
- self.output_weights = np.dot(np.linalg.pinv(H), y)
-
- def predict(self, X):
- # 计算隐藏层输出矩阵H
- H = self._sigmoid(np.dot(X, self.input_weights) + self.biases)
- # 返回预测结果
- return np.dot(H, self.output_weights)
-
- # 创建数据集并进行预处理
- X, y = make_moons(n_samples=1000, noise=0.2, random_state=42)
- # 将标签转换为二维数组(ELM需要二维数组作为标签)
- y = y.reshape(-1, 1)
-
- # 标准化数据
- scaler = StandardScaler()
- X_scaled = scaler.fit_transform(X)
-
- # 拆分训练集和测试集
- X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42)
-
- # 训练和比较ELM与MLP
-
- # 训练ELM
- elm = ELM(n_hidden_units=10)
- elm.fit(X_train, y_train)
- y_pred_elm = elm.predict(X_test)
- # 将预测结果转换为类别标签
- y_pred_elm_class = (y_pred_elm > 0.5).astype(int)
- # 计算ELM的准确率
- accuracy_elm = accuracy_score(y_test, y_pred_elm_class)
-
- # 训练MLP
- mlp = MLPClassifier(hidden_layer_sizes=(10,), max_iter=1000, random_state=42)
- mlp.fit(X_train, y_train.ravel())
- # 预测测试集结果
- y_pred_mlp = mlp.predict(X_test)
- # 计算MLP的准确率
- accuracy_mlp = accuracy_score(y_test, y_pred_mlp)
-
- # 打印ELM和MLP的准确率
- print(f"ELM Accuracy: {accuracy_elm}")
- print(f"MLP Accuracy: {accuracy_mlp}")
-
- # 可视化结果
- def plot_decision_boundary(model, X, y, ax, title):
- # 设置绘图范围
- x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
- y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
- # 创建网格
- xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01),
- np.arange(y_min, y_max, 0.01))
- # 预测网格中的所有点
- Z = model(np.c_[xx.ravel(), yy.ravel()])
- Z = (Z > 0.5).astype(int)
- Z = Z.reshape(xx.shape)
- # 画出决策边界
- ax.contourf(xx, yy, Z, alpha=0.8)
- # 画出数据点
- ax.scatter(X[:, 0], X[:, 1], c=y.ravel(), edgecolors='k', marker='o')
- ax.set_title(title)
-
- # 创建图形
- fig, axs = plt.subplots(1, 2, figsize=(12, 5))
-
- # 画出ELM的决策边界
- plot_decision_boundary(lambda x: elm.predict(x), X_test, y_test, axs[0], "ELM Decision Boundary")
- # 画出MLP的决策边界
- plot_decision_boundary(lambda x: mlp.predict(x), X_test, y_test, axs[1], "MLP Decision Boundary")
-
- # 显示图形
- plt.show()
-
- # 输出:
- '''
- ELM Accuracy: 0.9666666666666667
- MLP Accuracy: 0.9766666666666667
- '''
Keluaran visual:
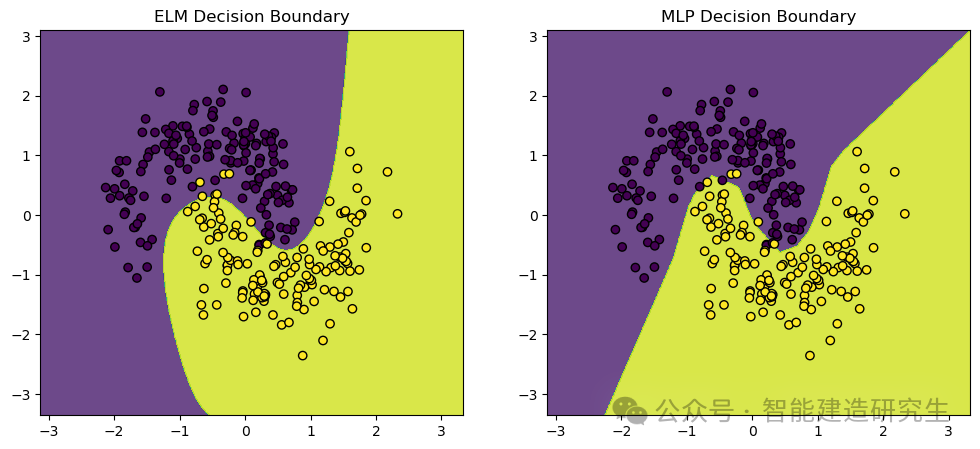
Konten di atas dirangkum dari Internet. Jika bermanfaat, silakan teruskan.

Ia telah mengabdikan dirinya untuk meneliti teknologi selama lebih dari 30 tahun, dan mahir dalam berbagai bahasa seperti java, linux, javascript, php, css, dll. Ia telah memberikan banyak kontribusi di bidang open source stasiun dokumentasi pengembang untuk berbagi beberapa masalah dalam pengembangan teknologi untuk referensi di masa mendatang. Semua orang memeriksanya

Surat[email protected]