
minhas informações de contato
Correspondência[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
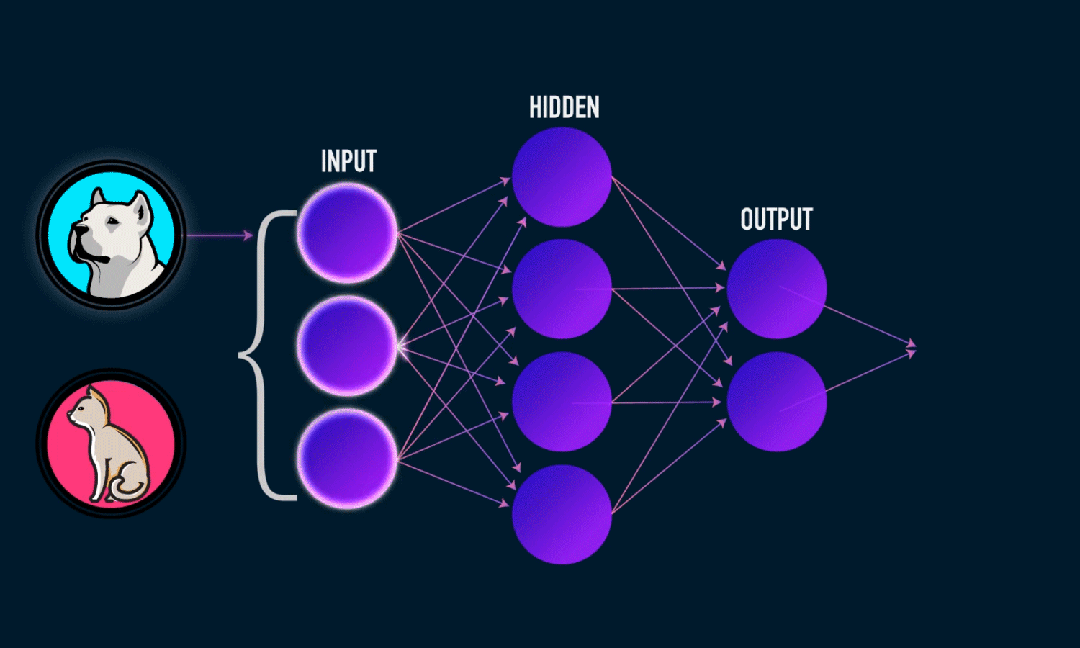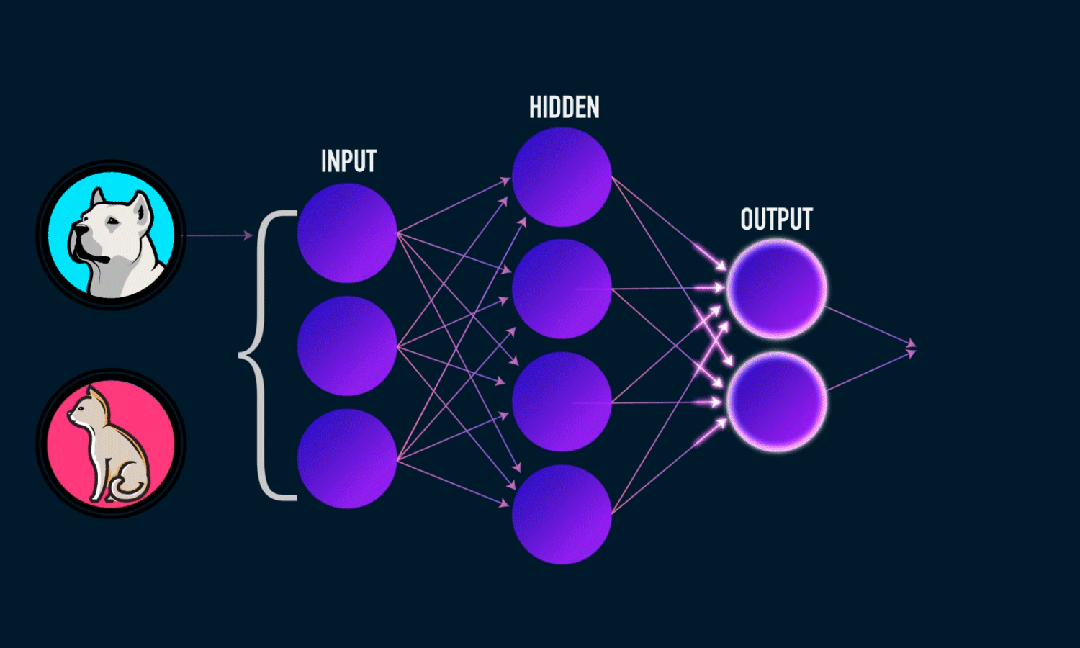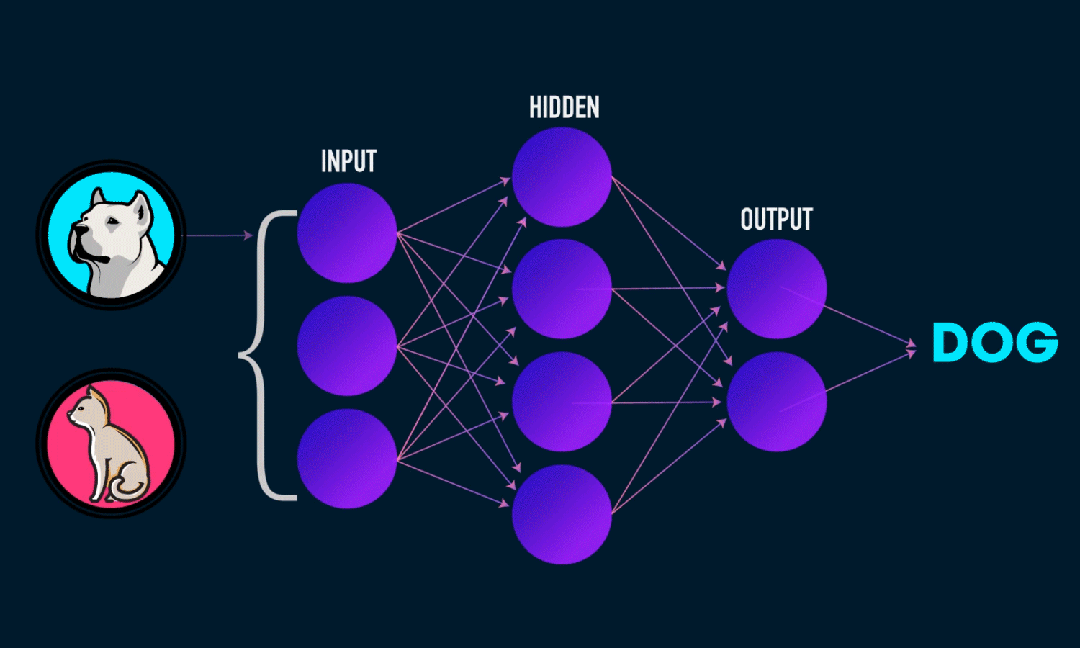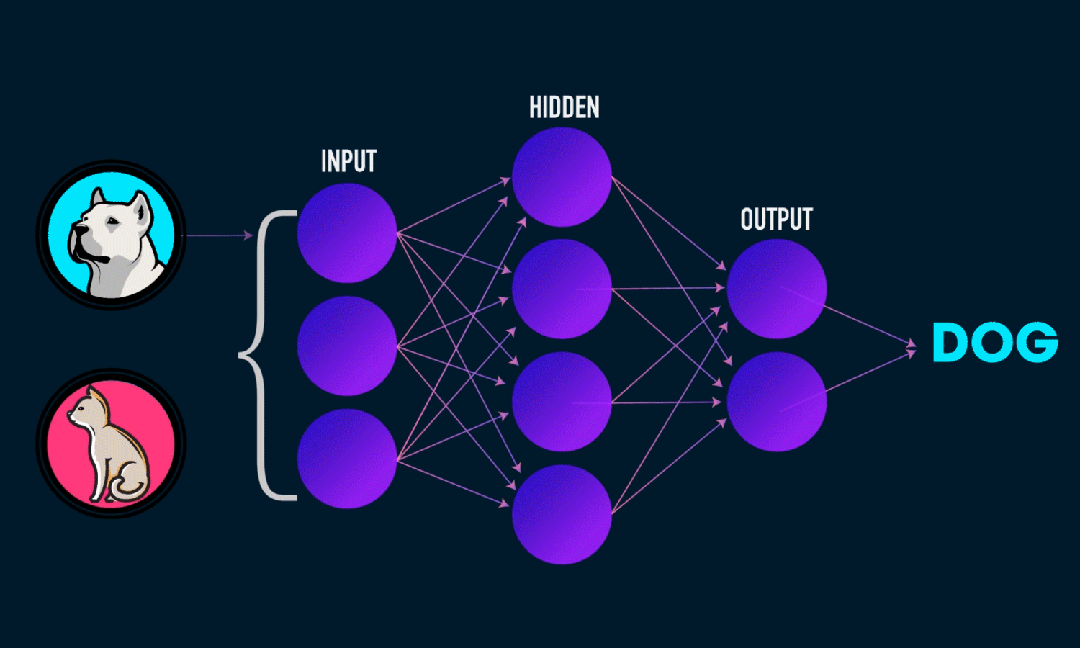
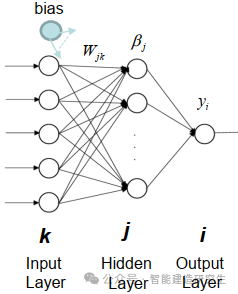
Extreme Learning Machine (ELM) é um algoritmo simples de aprendizagem de rede neural feedforward (SLFN) de camada única. Em teoria, algoritmos de máquina de aprendizado extremo (ELM) tendem a fornecer bom desempenho (pertencentes a algoritmos de aprendizado de máquina) com velocidades de aprendizado extremamente rápidas e foram propostos por Huang et al. A principal característica do ELM é que sua velocidade de aprendizado é muito rápida. Em comparação com os métodos tradicionais de descida de gradiente (como a rede neural BP), o ELM não requer um processo iterativo. O princípio básico é selecionar aleatoriamente os pesos e tendências da camada oculta e, em seguida, aprender os pesos de saída minimizando o erro da camada de saída.
imagem
Inicialize aleatoriamente a entrada de pesos e tendências para a camada oculta:
Os pesos e desvios das camadas ocultas são gerados aleatoriamente e permanecem constantes durante o treinamento.
Calcule a matriz de saída da camada oculta (ou seja, a saída da função de ativação):
Calcule a saída da camada oculta usando uma função de ativação (como sigmóide, ReLU, etc.).
Calcular o peso de saída:
Os pesos da camada oculta para a camada de saída são calculados pelo método dos mínimos quadrados.
A fórmula matemática do ELM é a seguinte:
Dado um conjunto de dados de treinamento, onde,
A fórmula de cálculo da matriz de saída da camada oculta é:
onde é a matriz de entrada, é a entrada da matriz de pesos para a camada oculta, é o vetor de polarização e é a função de ativação.
A fórmula de cálculo do peso de saída é:
onde é o inverso generalizado da matriz de saída da camada oculta e é a matriz de saída.
Processamento de conjunto de dados em grande escala: O ELM tem um bom desempenho no processamento de conjuntos de dados em grande escala porque sua velocidade de treinamento é muito rápida e é adequada para cenários que exigem treinamento rápido de modelos, como classificação de imagens em grande escala, processamento de linguagem natural e outras tarefas.
Previsão da Indústria : O ELM possui uma ampla gama de aplicações na área de previsão industrial, como controle de qualidade e previsão de falhas de equipamentos em processos de produção industrial. Ele pode treinar rapidamente modelos preditivos e responder rapidamente a dados em tempo real.
O setor financeiro : ELM pode ser usado para análise e previsão de dados financeiros, como previsão de preços de ações, gerenciamento de risco, pontuação de crédito, etc. Como os dados financeiros são geralmente de alta dimensão, a rápida velocidade de treinamento do ELM é vantajosa para o processamento desses dados.
diagnóstico médico : Na área médica, o ELM pode ser usado para tarefas como previsão de doenças e análise de imagens médicas. Ele pode treinar modelos rapidamente e classificar ou regredir dados de pacientes, ajudando os médicos a fazer diagnósticos mais rápidos e precisos.
Sistema de controle inteligente : O ELM pode ser usado em sistemas de controle inteligentes, como casas inteligentes, sistemas de transporte inteligentes, etc. Ao aprender as características e padrões do ambiente, o ELM pode ajudar o sistema a tomar decisões inteligentes e melhorar a eficiência e o desempenho do sistema.
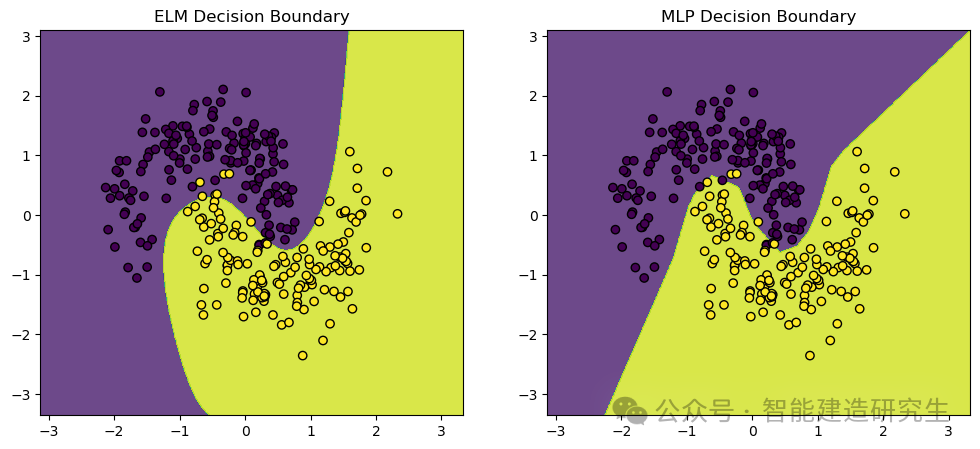
Nós usamosmake_moons Conjunto de dados, um conjunto de dados de brinquedo comumente usado para tarefas de classificação de aprendizado de máquina e aprendizado profundo. Ele gera pontos distribuídos em duas formas de meia-lua que se cruzam, ideais para demonstrar o desempenho e os limites de decisão de algoritmos de classificação.
- import numpy as np
- import matplotlib.pyplot as plt
- from sklearn.datasets import make_moons
- from sklearn.model_selection import train_test_split
- from sklearn.neural_network import MLPClassifier
- from sklearn.preprocessing import StandardScaler
- from sklearn.metrics import accuracy_score
-
- # 定义极限学习机(ELM)类
- class ELM:
- def __init__(self, n_hidden_units):
- # 初始化隐藏层神经元数量
- self.n_hidden_units = n_hidden_units
-
- def _sigmoid(self, x):
- # 定义Sigmoid激活函数
- return 1 / (1 + np.exp(-x))
-
- def fit(self, X, y):
- # 随机初始化输入权重
- self.input_weights = np.random.randn(X.shape[1], self.n_hidden_units)
- # 随机初始化偏置
- self.biases = np.random.randn(self.n_hidden_units)
- # 计算隐藏层输出矩阵H
- H = self._sigmoid(np.dot(X, self.input_weights) + self.biases)
- # 计算输出权重
- self.output_weights = np.dot(np.linalg.pinv(H), y)
-
- def predict(self, X):
- # 计算隐藏层输出矩阵H
- H = self._sigmoid(np.dot(X, self.input_weights) + self.biases)
- # 返回预测结果
- return np.dot(H, self.output_weights)
-
- # 创建数据集并进行预处理
- X, y = make_moons(n_samples=1000, noise=0.2, random_state=42)
- # 将标签转换为二维数组(ELM需要二维数组作为标签)
- y = y.reshape(-1, 1)
-
- # 标准化数据
- scaler = StandardScaler()
- X_scaled = scaler.fit_transform(X)
-
- # 拆分训练集和测试集
- X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42)
-
- # 训练和比较ELM与MLP
-
- # 训练ELM
- elm = ELM(n_hidden_units=10)
- elm.fit(X_train, y_train)
- y_pred_elm = elm.predict(X_test)
- # 将预测结果转换为类别标签
- y_pred_elm_class = (y_pred_elm > 0.5).astype(int)
- # 计算ELM的准确率
- accuracy_elm = accuracy_score(y_test, y_pred_elm_class)
-
- # 训练MLP
- mlp = MLPClassifier(hidden_layer_sizes=(10,), max_iter=1000, random_state=42)
- mlp.fit(X_train, y_train.ravel())
- # 预测测试集结果
- y_pred_mlp = mlp.predict(X_test)
- # 计算MLP的准确率
- accuracy_mlp = accuracy_score(y_test, y_pred_mlp)
-
- # 打印ELM和MLP的准确率
- print(f"ELM Accuracy: {accuracy_elm}")
- print(f"MLP Accuracy: {accuracy_mlp}")
-
- # 可视化结果
- def plot_decision_boundary(model, X, y, ax, title):
- # 设置绘图范围
- x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
- y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
- # 创建网格
- xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01),
- np.arange(y_min, y_max, 0.01))
- # 预测网格中的所有点
- Z = model(np.c_[xx.ravel(), yy.ravel()])
- Z = (Z > 0.5).astype(int)
- Z = Z.reshape(xx.shape)
- # 画出决策边界
- ax.contourf(xx, yy, Z, alpha=0.8)
- # 画出数据点
- ax.scatter(X[:, 0], X[:, 1], c=y.ravel(), edgecolors='k', marker='o')
- ax.set_title(title)
-
- # 创建图形
- fig, axs = plt.subplots(1, 2, figsize=(12, 5))
-
- # 画出ELM的决策边界
- plot_decision_boundary(lambda x: elm.predict(x), X_test, y_test, axs[0], "ELM Decision Boundary")
- # 画出MLP的决策边界
- plot_decision_boundary(lambda x: mlp.predict(x), X_test, y_test, axs[1], "MLP Decision Boundary")
-
- # 显示图形
- plt.show()
-
- # 输出:
- '''
- ELM Accuracy: 0.9666666666666667
- MLP Accuracy: 0.9766666666666667
- '''
Saída visual:
O conteúdo acima foi resumido da Internet. Se for útil, encaminhe-o na próxima vez!

Ele se dedica à pesquisa de tecnologia há mais de 30 anos e é proficiente em diversas linguagens como java, linux, javascript, php, css, etc. estação de documentação do desenvolvedor para compartilhar alguns problemas no desenvolvimento de tecnologia para referência futura.

Correspondência[email protected]