
내 연락처 정보
우편메소피아@프로톤메일.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
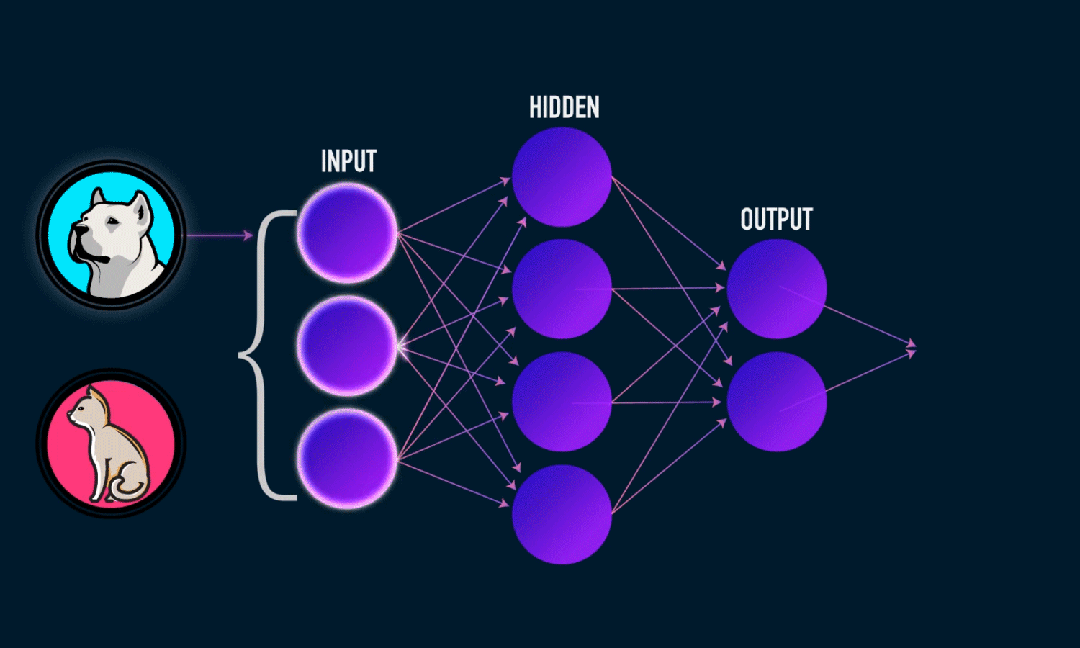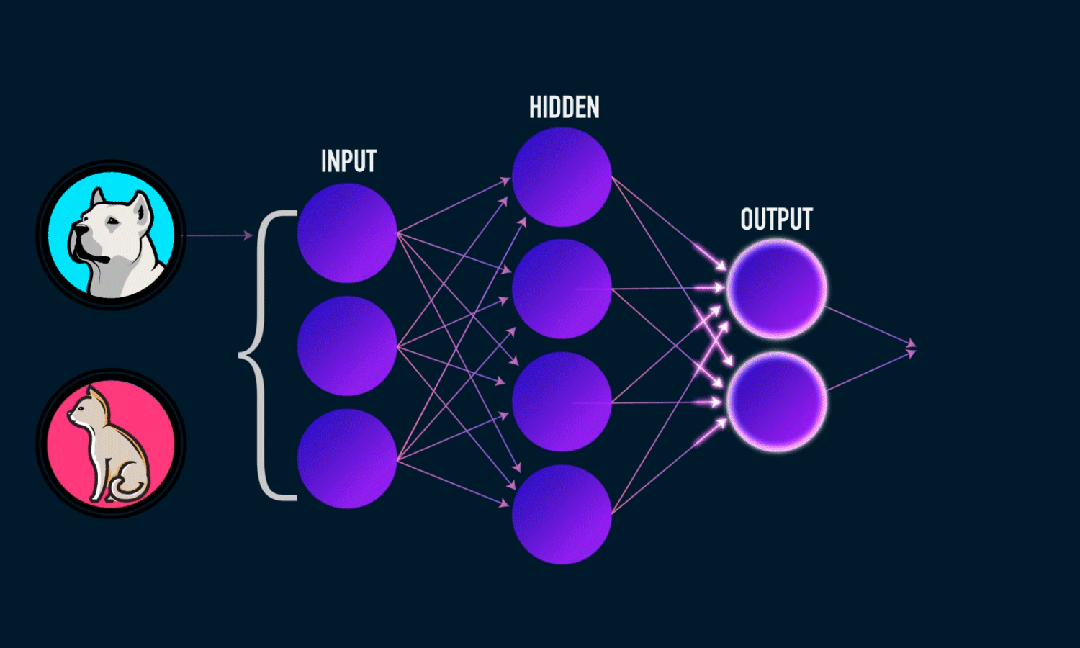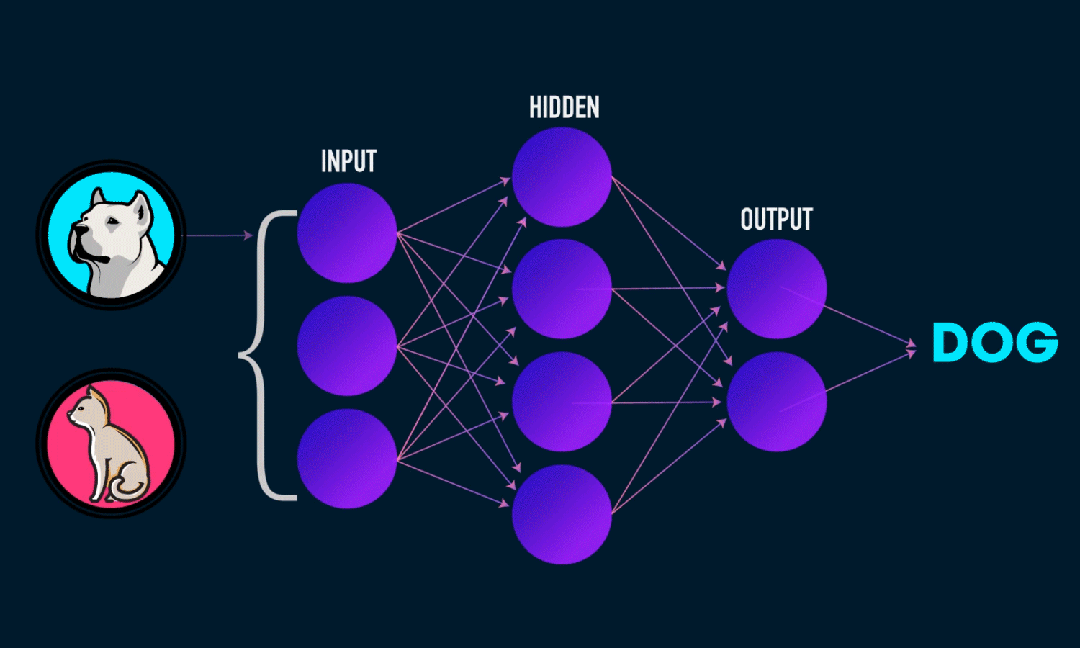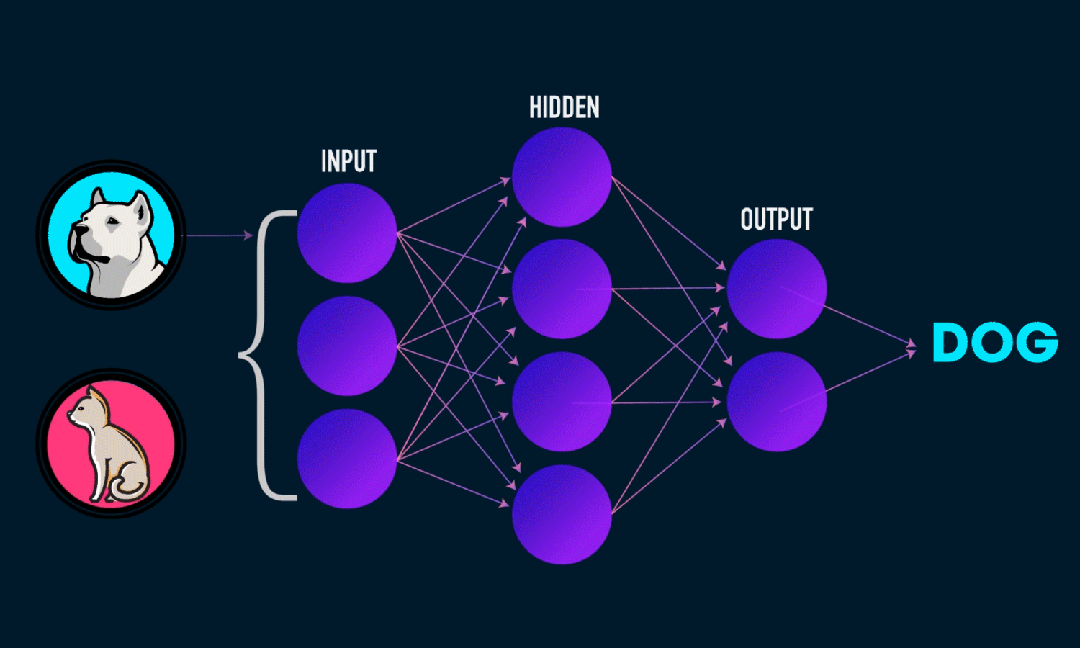
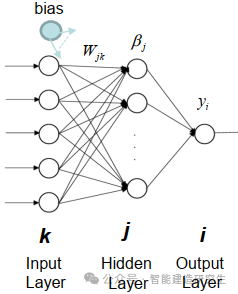
ELM(Extreme Learning Machine)은 간단한 단일 계층 피드포워드 신경망(SLFN) 학습 알고리즘입니다. 이론적으로 ELM(Extreme Learning Machine Algorithms)은 매우 빠른 학습 속도로 우수한 성능(기계 학습 알고리즘에 속함)을 제공하는 경향이 있으며 Huang et al. ELM의 주요 특징은 학습 속도가 매우 빠르다는 것입니다. 전통적인 경사하강법(예: BP 신경망)에 비해 ELM은 반복 프로세스가 필요하지 않습니다. 기본 원리는 은닉층의 가중치와 편향을 무작위로 선택한 후, 출력층의 오차를 최소화하여 출력 가중치를 학습하는 것입니다.
이미지
은닉층에 입력된 가중치와 편향을 무작위로 초기화합니다.:
숨겨진 레이어의 가중치와 편향은 무작위로 생성되며 훈련 중에 일정하게 유지됩니다.
은닉층의 출력 행렬(즉, 활성화 함수의 출력)을 계산합니다.:
활성화 함수(예: Sigmoid, ReLU 등)를 사용하여 숨겨진 레이어의 출력을 계산합니다.
출력 중량 계산:
은닉층부터 출력층까지의 가중치는 최소자승법으로 계산된다.
ELM의 수학 공식은 다음과 같습니다.
훈련 데이터 세트가 주어졌을 때, 여기서,
은닉층의 출력 행렬의 계산 공식은 다음과 같습니다.
여기서 는 입력 행렬, 는 은닉층에 입력되는 가중치 행렬, 는 바이어스 벡터, 는 활성화 함수입니다.
출력 중량의 계산 공식은 다음과 같습니다.
그 중 은 은닉층 출력 행렬의 일반화된 역행렬이며 출력 행렬이다.
대규모 데이터 세트 처리: ELM은 학습 속도가 매우 빠르고, 대규모 이미지 분류, 자연어 처리, 기타 작업 등 모델의 빠른 학습이 필요한 시나리오에 적합하기 때문에 대규모 데이터 세트를 처리할 때 성능이 좋습니다.
산업 예측 : ELM은 산업 생산 공정의 품질 관리, 장비 고장 예측 등 산업 예측 분야에서 광범위한 응용 분야를 보유하고 있습니다. 예측 모델을 신속하게 훈련하고 실시간 데이터에 신속하게 대응할 수 있습니다.
금융 부문 : ELM은 주가 예측, 리스크 관리, 신용평점 등 금융 데이터 분석 및 예측에 활용될 수 있습니다. 금융 데이터는 일반적으로 고차원적이므로 ELM의 빠른 학습 속도는 이러한 데이터를 처리하는 데 유리합니다.
의료 진단 : 의료 분야에서는 질병 예측, 의료 영상 분석 등의 업무에 ELM을 활용할 수 있습니다. 신속하게 모델을 훈련하고 환자 데이터를 분류 또는 회귀 분석하여 의사가 더 빠르고 정확한 진단을 내릴 수 있도록 돕습니다.
지능형 제어 시스템 : ELM은 스마트 홈, 지능형 교통 시스템 등 지능형 제어 시스템에 활용될 수 있습니다. ELM은 환경의 특성과 패턴을 학습함으로써 시스템이 지능적인 결정을 내리는 데 도움을 주고 시스템 효율성과 성능을 향상시킬 수 있습니다.
우리는 사용make_moons 데이터 세트(Dataset)는 기계 학습 및 딥 러닝 분류 작업에 일반적으로 사용되는 장난감 데이터 세트입니다. 두 개의 교차하는 반달 모양으로 분포된 점을 생성하며 분류 알고리즘의 성능 및 결정 경계를 보여주는 데 이상적입니다.
- import numpy as np
- import matplotlib.pyplot as plt
- from sklearn.datasets import make_moons
- from sklearn.model_selection import train_test_split
- from sklearn.neural_network import MLPClassifier
- from sklearn.preprocessing import StandardScaler
- from sklearn.metrics import accuracy_score
-
- # 定义极限学习机(ELM)类
- class ELM:
- def __init__(self, n_hidden_units):
- # 初始化隐藏层神经元数量
- self.n_hidden_units = n_hidden_units
-
- def _sigmoid(self, x):
- # 定义Sigmoid激活函数
- return 1 / (1 + np.exp(-x))
-
- def fit(self, X, y):
- # 随机初始化输入权重
- self.input_weights = np.random.randn(X.shape[1], self.n_hidden_units)
- # 随机初始化偏置
- self.biases = np.random.randn(self.n_hidden_units)
- # 计算隐藏层输出矩阵H
- H = self._sigmoid(np.dot(X, self.input_weights) + self.biases)
- # 计算输出权重
- self.output_weights = np.dot(np.linalg.pinv(H), y)
-
- def predict(self, X):
- # 计算隐藏层输出矩阵H
- H = self._sigmoid(np.dot(X, self.input_weights) + self.biases)
- # 返回预测结果
- return np.dot(H, self.output_weights)
-
- # 创建数据集并进行预处理
- X, y = make_moons(n_samples=1000, noise=0.2, random_state=42)
- # 将标签转换为二维数组(ELM需要二维数组作为标签)
- y = y.reshape(-1, 1)
-
- # 标准化数据
- scaler = StandardScaler()
- X_scaled = scaler.fit_transform(X)
-
- # 拆分训练集和测试集
- X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42)
-
- # 训练和比较ELM与MLP
-
- # 训练ELM
- elm = ELM(n_hidden_units=10)
- elm.fit(X_train, y_train)
- y_pred_elm = elm.predict(X_test)
- # 将预测结果转换为类别标签
- y_pred_elm_class = (y_pred_elm > 0.5).astype(int)
- # 计算ELM的准确率
- accuracy_elm = accuracy_score(y_test, y_pred_elm_class)
-
- # 训练MLP
- mlp = MLPClassifier(hidden_layer_sizes=(10,), max_iter=1000, random_state=42)
- mlp.fit(X_train, y_train.ravel())
- # 预测测试集结果
- y_pred_mlp = mlp.predict(X_test)
- # 计算MLP的准确率
- accuracy_mlp = accuracy_score(y_test, y_pred_mlp)
-
- # 打印ELM和MLP的准确率
- print(f"ELM Accuracy: {accuracy_elm}")
- print(f"MLP Accuracy: {accuracy_mlp}")
-
- # 可视化结果
- def plot_decision_boundary(model, X, y, ax, title):
- # 设置绘图范围
- x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
- y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
- # 创建网格
- xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01),
- np.arange(y_min, y_max, 0.01))
- # 预测网格中的所有点
- Z = model(np.c_[xx.ravel(), yy.ravel()])
- Z = (Z > 0.5).astype(int)
- Z = Z.reshape(xx.shape)
- # 画出决策边界
- ax.contourf(xx, yy, Z, alpha=0.8)
- # 画出数据点
- ax.scatter(X[:, 0], X[:, 1], c=y.ravel(), edgecolors='k', marker='o')
- ax.set_title(title)
-
- # 创建图形
- fig, axs = plt.subplots(1, 2, figsize=(12, 5))
-
- # 画出ELM的决策边界
- plot_decision_boundary(lambda x: elm.predict(x), X_test, y_test, axs[0], "ELM Decision Boundary")
- # 画出MLP的决策边界
- plot_decision_boundary(lambda x: mlp.predict(x), X_test, y_test, axs[1], "MLP Decision Boundary")
-
- # 显示图形
- plt.show()
-
- # 输出:
- '''
- ELM Accuracy: 0.9666666666666667
- MLP Accuracy: 0.9766666666666667
- '''
시각적 출력:
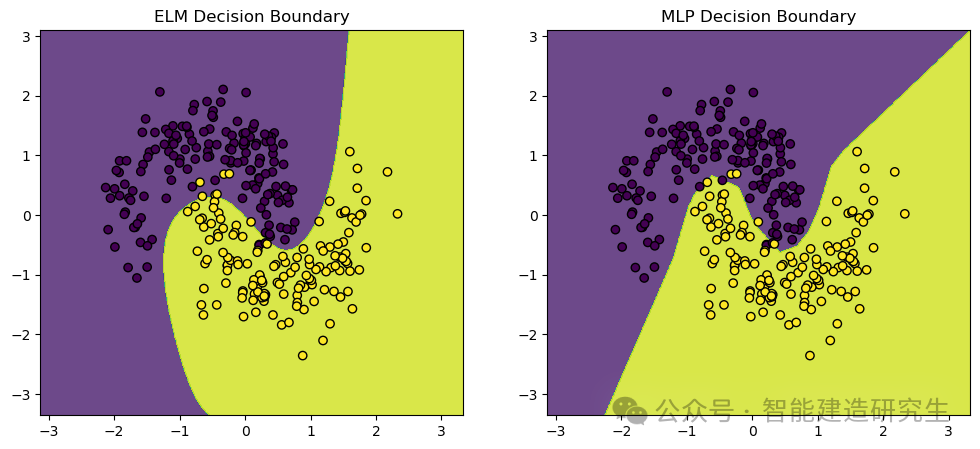
위 내용은 인터넷에서 요약한 내용입니다. 도움이 되셨다면 다음에 또 만나요!

그는 30년 이상 기술 연구에 전념해 왔으며, java, linux, javascript, php, css 등 다양한 언어에 능숙하며, 오픈 소스 분야에 많은 공헌을 했습니다. 나중에 참조할 수 있도록 기술 개발의 일부 문제를 공유하는 개발자 문서 스테이션입니다.

우편메소피아@프로톤메일.com