
le mie informazioni di contatto
Posta[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
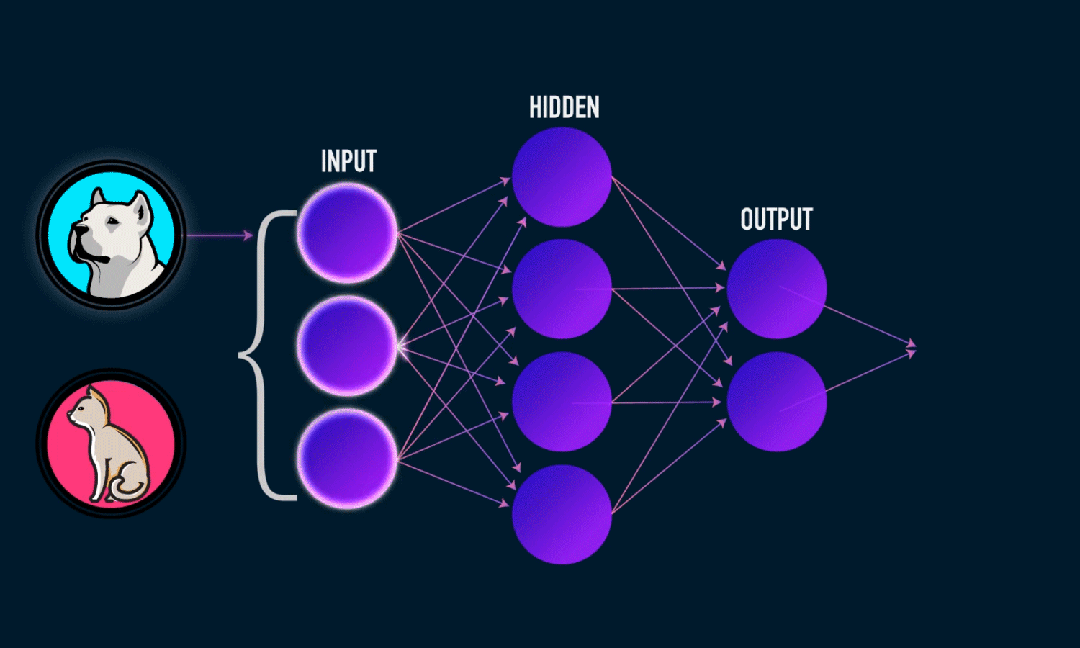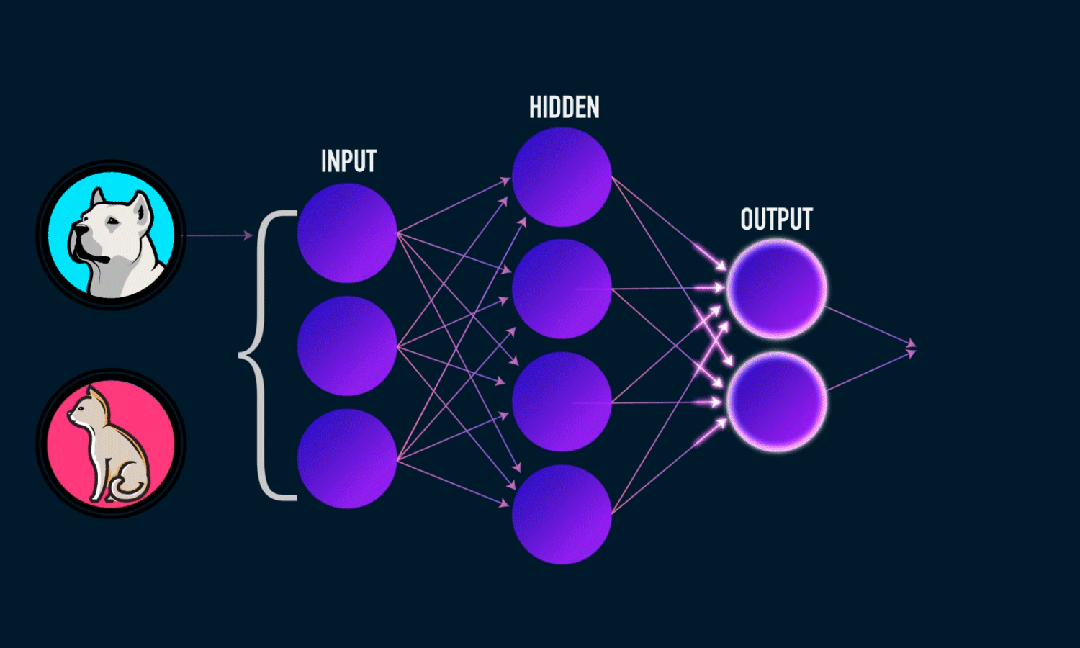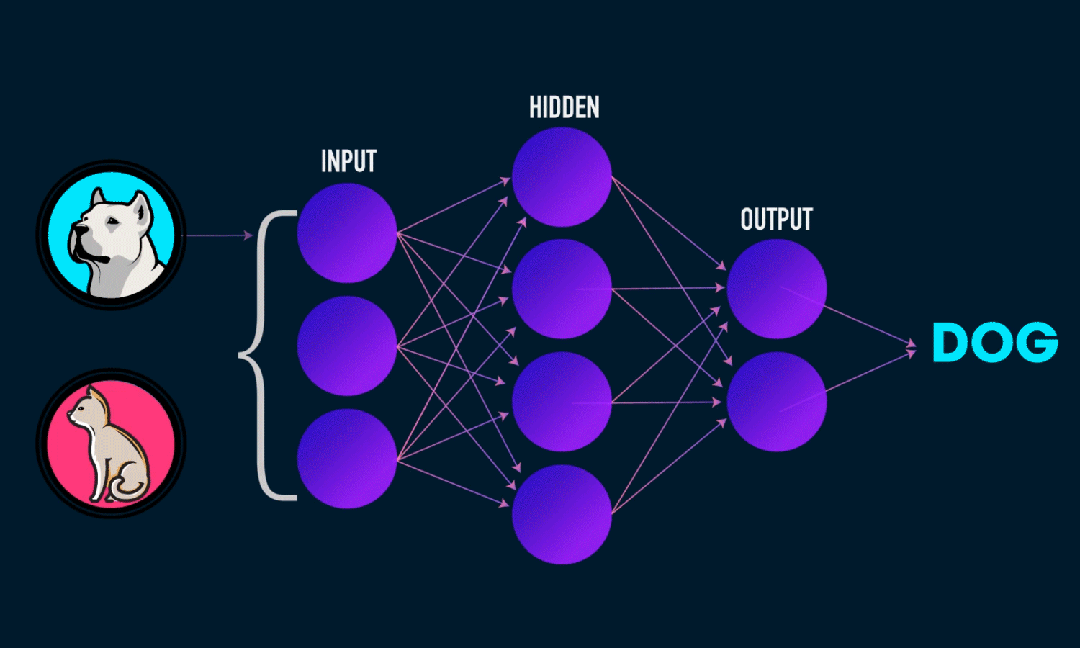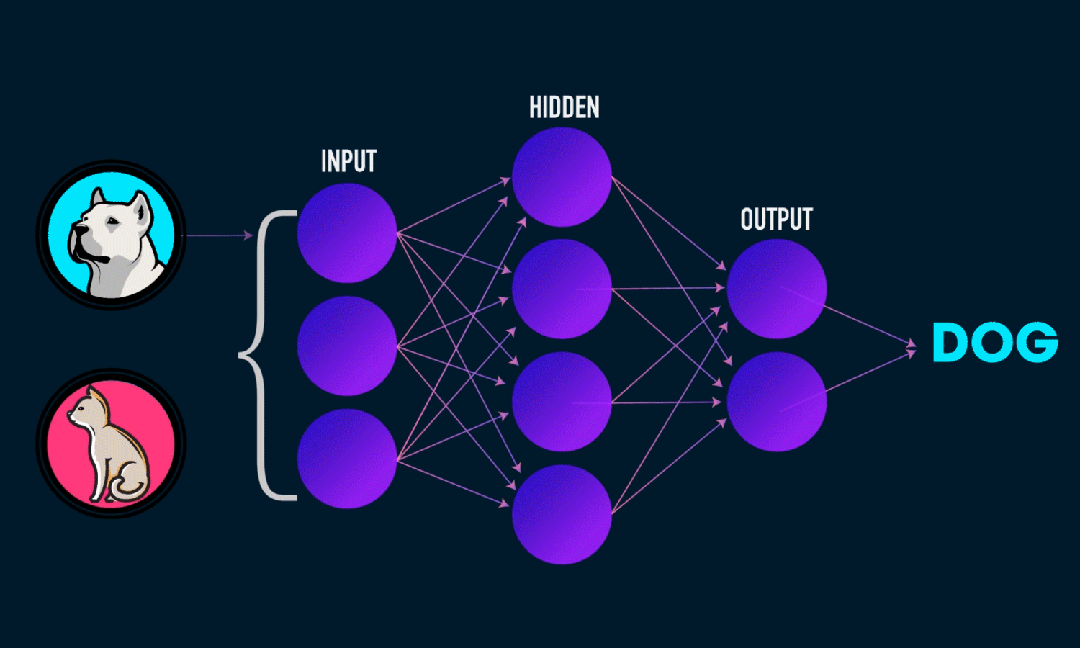
Extreme Learning Machine (ELM) è un semplice algoritmo di apprendimento della rete neurale feedforward (SLFN) a livello singolo. In teoria, gli algoritmi di machine learning estremi (ELM) tendono a fornire buone prestazioni (appartenenti agli algoritmi di machine learning) con velocità di apprendimento estremamente elevate e sono stati proposti da Huang et al. La caratteristica principale di ELM è che la sua velocità di apprendimento è molto rapida rispetto ai tradizionali metodi di discesa del gradiente (come la rete neurale BP), ELM non richiede un processo iterativo. Il principio di base è selezionare in modo casuale i pesi e i bias dello strato nascosto, quindi apprendere i pesi di output minimizzando l'errore dello strato di output.
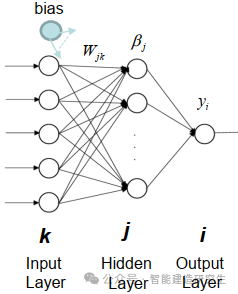
immagine
Inizializza casualmente i pesi e i bias immessi nel livello nascosto:
I pesi e i bias degli strati nascosti vengono generati casualmente e rimangono costanti durante l'allenamento.
Calcolare la matrice di output dello strato nascosto (ovvero l'output della funzione di attivazione):
Calcola l'output del livello nascosto utilizzando una funzione di attivazione (come sigmoide, ReLU, ecc.).
Calcolare il peso in uscita:
I pesi dallo strato nascosto allo strato di output vengono calcolati con il metodo dei minimi quadrati.
La formula matematica dell'ELM è la seguente:
Dato un set di dati di addestramento, dove,
La formula di calcolo della matrice di output dello strato nascosto è:
dove è la matrice di input, è la matrice dei pesi in input allo strato nascosto, è il vettore di polarizzazione ed è la funzione di attivazione.
La formula di calcolo del peso in uscita è:
dove è l'inverso generalizzato della matrice di output dello strato nascosto ed è la matrice di output.
Elaborazione di set di dati su larga scala: ELM funziona bene durante l'elaborazione di set di dati su larga scala perché la sua velocità di addestramento è molto elevata ed è adatta a scenari che richiedono un addestramento rapido di modelli, come la classificazione di immagini su larga scala, l'elaborazione del linguaggio naturale e altre attività.
Previsioni del settore : ELM ha una vasta gamma di applicazioni nel campo della previsione industriale, come il controllo di qualità e la previsione dei guasti delle apparecchiature nei processi di produzione industriale. Può addestrare rapidamente modelli predittivi e rispondere rapidamente ai dati in tempo reale.
Il settore finanziario : ELM può essere utilizzato per l'analisi e la previsione dei dati finanziari, come la previsione del prezzo delle azioni, la gestione del rischio, il credit scoring, ecc. Poiché i dati finanziari sono generalmente ad alta dimensione, l'elevata velocità di addestramento di ELM è vantaggiosa per l'elaborazione di questi dati.
diagnosi medica : In campo medico, l'ELM può essere utilizzato per attività quali la previsione delle malattie e l'analisi delle immagini mediche. Può addestrare rapidamente modelli e classificare o regredire i dati dei pazienti, aiutando i medici a effettuare diagnosi più rapide e accurate.
Sistema di controllo intelligente : L'ELM può essere utilizzato in sistemi di controllo intelligenti, come case intelligenti, sistemi di trasporto intelligenti, ecc. Apprendendo le caratteristiche e i modelli dell'ambiente, ELM può aiutare il sistema a prendere decisioni intelligenti e migliorare l'efficienza e le prestazioni del sistema.
Noi usiamomake_moons Set di dati, un set di dati giocattolo comunemente utilizzato per attività di classificazione di machine learning e deep learning. Genera punti distribuiti in due forme a mezzaluna intersecanti, ideali per dimostrare le prestazioni e i limiti decisionali degli algoritmi di classificazione.
- import numpy as np
- import matplotlib.pyplot as plt
- from sklearn.datasets import make_moons
- from sklearn.model_selection import train_test_split
- from sklearn.neural_network import MLPClassifier
- from sklearn.preprocessing import StandardScaler
- from sklearn.metrics import accuracy_score
-
- # 定义极限学习机(ELM)类
- class ELM:
- def __init__(self, n_hidden_units):
- # 初始化隐藏层神经元数量
- self.n_hidden_units = n_hidden_units
-
- def _sigmoid(self, x):
- # 定义Sigmoid激活函数
- return 1 / (1 + np.exp(-x))
-
- def fit(self, X, y):
- # 随机初始化输入权重
- self.input_weights = np.random.randn(X.shape[1], self.n_hidden_units)
- # 随机初始化偏置
- self.biases = np.random.randn(self.n_hidden_units)
- # 计算隐藏层输出矩阵H
- H = self._sigmoid(np.dot(X, self.input_weights) + self.biases)
- # 计算输出权重
- self.output_weights = np.dot(np.linalg.pinv(H), y)
-
- def predict(self, X):
- # 计算隐藏层输出矩阵H
- H = self._sigmoid(np.dot(X, self.input_weights) + self.biases)
- # 返回预测结果
- return np.dot(H, self.output_weights)
-
- # 创建数据集并进行预处理
- X, y = make_moons(n_samples=1000, noise=0.2, random_state=42)
- # 将标签转换为二维数组(ELM需要二维数组作为标签)
- y = y.reshape(-1, 1)
-
- # 标准化数据
- scaler = StandardScaler()
- X_scaled = scaler.fit_transform(X)
-
- # 拆分训练集和测试集
- X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42)
-
- # 训练和比较ELM与MLP
-
- # 训练ELM
- elm = ELM(n_hidden_units=10)
- elm.fit(X_train, y_train)
- y_pred_elm = elm.predict(X_test)
- # 将预测结果转换为类别标签
- y_pred_elm_class = (y_pred_elm > 0.5).astype(int)
- # 计算ELM的准确率
- accuracy_elm = accuracy_score(y_test, y_pred_elm_class)
-
- # 训练MLP
- mlp = MLPClassifier(hidden_layer_sizes=(10,), max_iter=1000, random_state=42)
- mlp.fit(X_train, y_train.ravel())
- # 预测测试集结果
- y_pred_mlp = mlp.predict(X_test)
- # 计算MLP的准确率
- accuracy_mlp = accuracy_score(y_test, y_pred_mlp)
-
- # 打印ELM和MLP的准确率
- print(f"ELM Accuracy: {accuracy_elm}")
- print(f"MLP Accuracy: {accuracy_mlp}")
-
- # 可视化结果
- def plot_decision_boundary(model, X, y, ax, title):
- # 设置绘图范围
- x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
- y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
- # 创建网格
- xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01),
- np.arange(y_min, y_max, 0.01))
- # 预测网格中的所有点
- Z = model(np.c_[xx.ravel(), yy.ravel()])
- Z = (Z > 0.5).astype(int)
- Z = Z.reshape(xx.shape)
- # 画出决策边界
- ax.contourf(xx, yy, Z, alpha=0.8)
- # 画出数据点
- ax.scatter(X[:, 0], X[:, 1], c=y.ravel(), edgecolors='k', marker='o')
- ax.set_title(title)
-
- # 创建图形
- fig, axs = plt.subplots(1, 2, figsize=(12, 5))
-
- # 画出ELM的决策边界
- plot_decision_boundary(lambda x: elm.predict(x), X_test, y_test, axs[0], "ELM Decision Boundary")
- # 画出MLP的决策边界
- plot_decision_boundary(lambda x: mlp.predict(x), X_test, y_test, axs[1], "MLP Decision Boundary")
-
- # 显示图形
- plt.show()
-
- # 输出:
- '''
- ELM Accuracy: 0.9666666666666667
- MLP Accuracy: 0.9766666666666667
- '''
Uscita visiva:
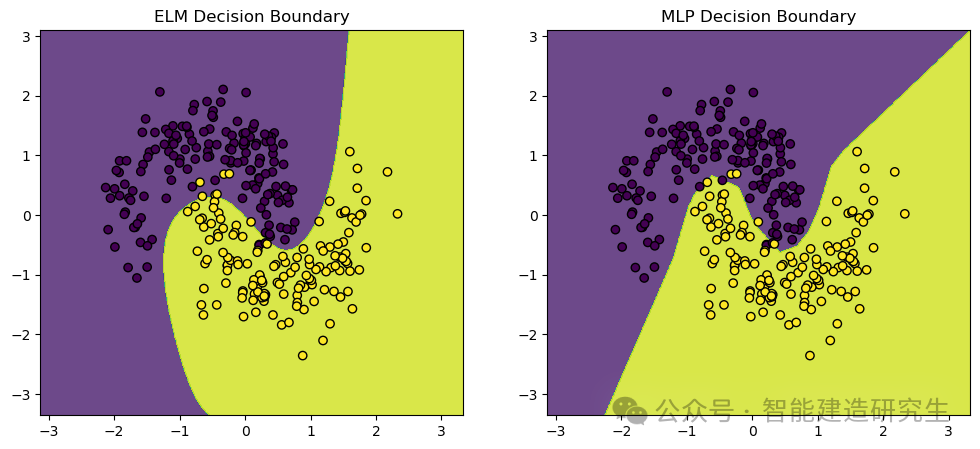
Il contenuto di cui sopra è un riepilogo da Internet. Se è utile, inoltralo. Alla prossima.

Si dedica alla ricerca tecnologica da più di 30 anni ed è esperto in vari linguaggi come Java, Linux, Javascript, php, css, ecc. Ha dato numerosi contributi nel campo dell'open source stazione di documentazione per gli sviluppatori per condividere alcuni problemi nello sviluppo della tecnologia per riferimento futuro

Posta[email protected]