
τα στοιχεία επικοινωνίας μου
Ταχυδρομείο[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
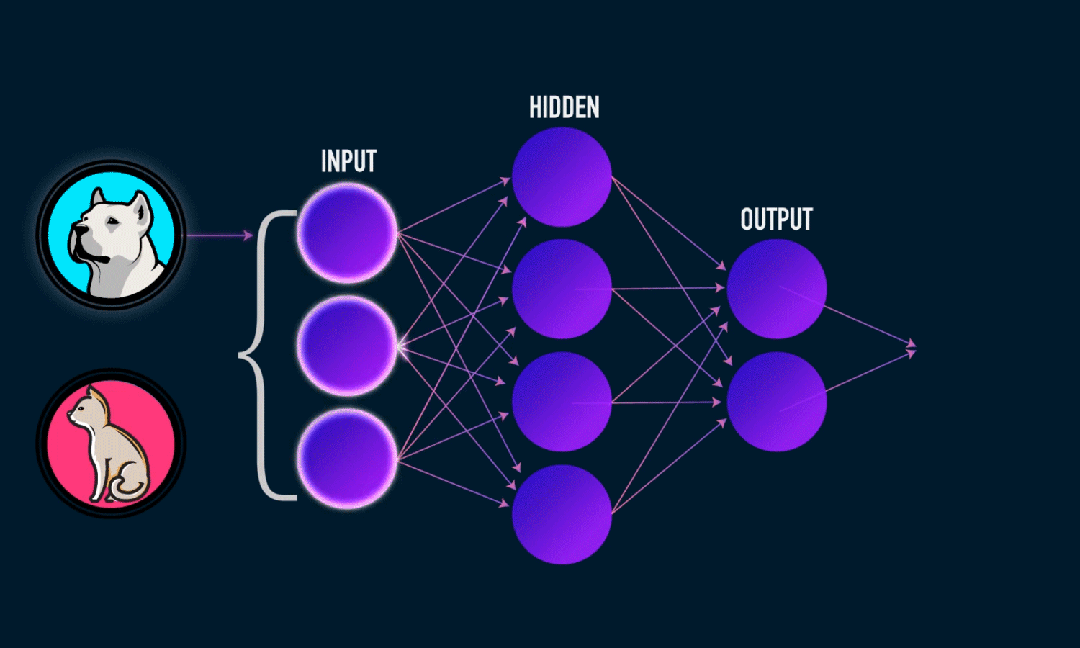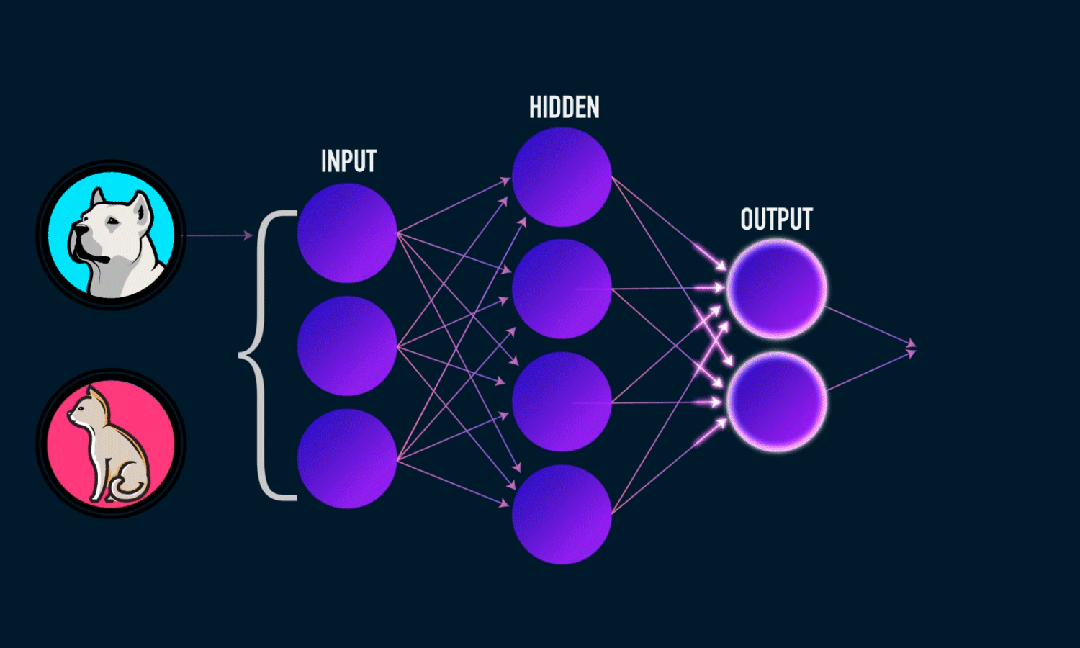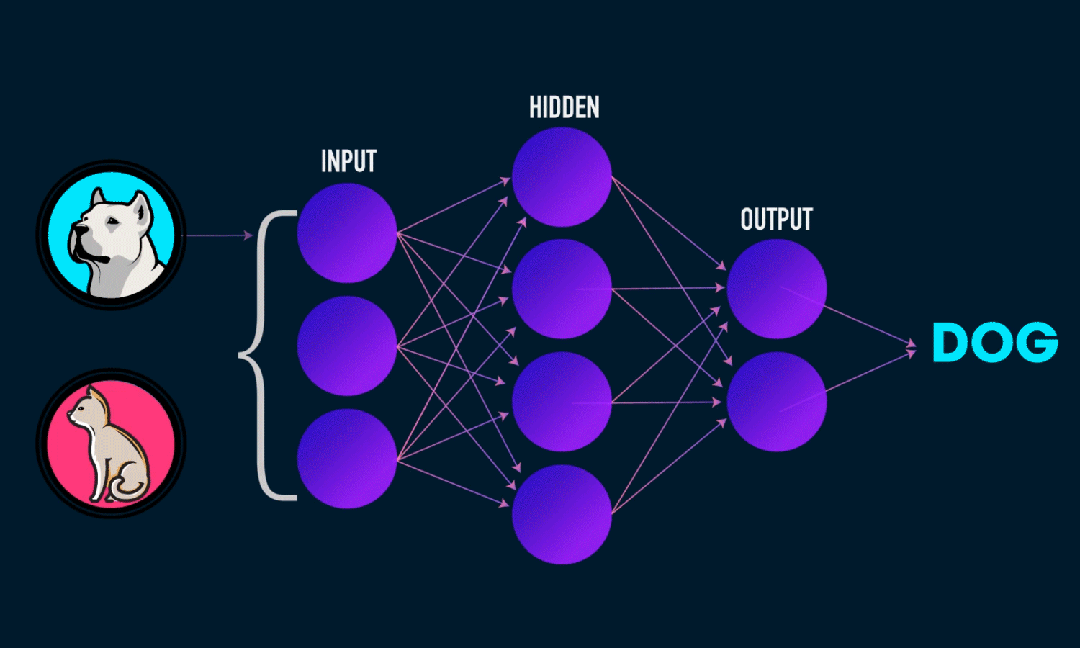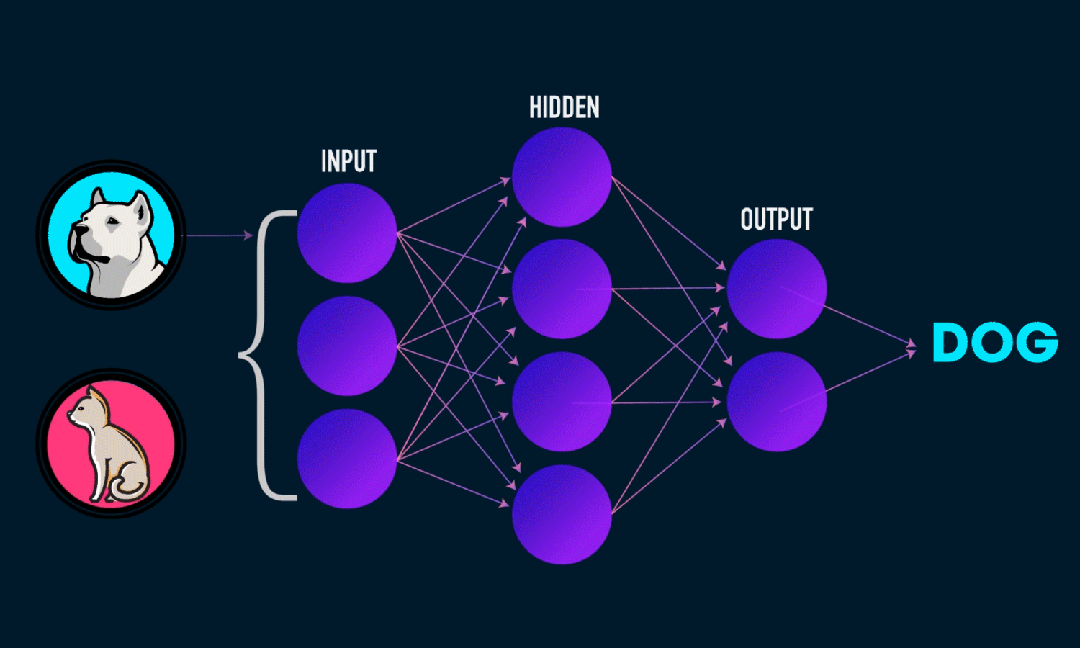
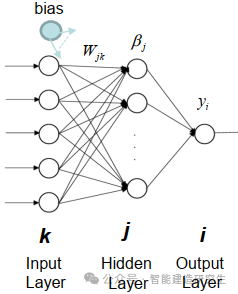
Το Extreme Learning Machine (ELM) είναι ένας απλός αλγόριθμος εκμάθησης ενός απλού επιπέδου νευρωνικού δικτύου (SLFN). Θεωρητικά, οι αλγόριθμοι μηχανών ακραίας μάθησης (ELM) τείνουν να παρέχουν καλή απόδοση (που ανήκουν σε αλγόριθμους μηχανικής μάθησης) με εξαιρετικά γρήγορες ταχύτητες εκμάθησης και προτάθηκαν από τους Huang et al. Το κύριο χαρακτηριστικό του ELM είναι ότι η ταχύτητα εκμάθησής του είναι πολύ γρήγορη Σε σύγκριση με τις παραδοσιακές μεθόδους gradient descent (όπως το νευρωνικό δίκτυο BP), το ELM δεν απαιτεί επαναληπτική διαδικασία. Η βασική αρχή είναι να επιλέξετε τυχαία τα βάρη και τις προκαταλήψεις του κρυφού στρώματος και στη συνέχεια να μάθετε τα βάρη εξόδου ελαχιστοποιώντας το σφάλμα του επιπέδου εξόδου.
img
Αρχικοποιήστε τυχαία τα βάρη και τις προκαταλήψεις που εισάγονται στο κρυφό στρώμα:
Τα βάρη και οι προκαταλήψεις των κρυφών στρωμάτων δημιουργούνται τυχαία και παραμένουν σταθερά κατά τη διάρκεια της προπόνησης.
Υπολογίστε τον πίνακα εξόδου του κρυφού στρώματος (δηλαδή την έξοδο της συνάρτησης ενεργοποίησης):
Υπολογίστε την έξοδο του κρυφού στρώματος χρησιμοποιώντας μια συνάρτηση ενεργοποίησης (όπως σιγμοειδές, ReLU, κ.λπ.).
Υπολογίστε το βάρος εξόδου:
Τα βάρη από το κρυφό στρώμα στο επίπεδο εξόδου υπολογίζονται με τη μέθοδο των ελαχίστων τετραγώνων.
Ο μαθηματικός τύπος του ELM έχει ως εξής:
Δεδομένου ενός συνόλου δεδομένων εκπαίδευσης , όπου ,
Ο τύπος υπολογισμού του πίνακα εξόδου του κρυφού στρώματος είναι:
όπου είναι ο πίνακας εισόδου, είναι η είσοδος του πίνακα βάρους στο κρυφό στρώμα, είναι το διάνυσμα πόλωσης και είναι η συνάρτηση ενεργοποίησης.
Ο τύπος υπολογισμού του βάρους εξόδου είναι:
Μεταξύ αυτών, είναι το γενικευμένο αντίστροφο του πίνακα εξόδου κρυφού στρώματος και είναι ο πίνακας εξόδου.
Επεξεργασία συνόλων δεδομένων μεγάλης κλίμακας: Το ELM αποδίδει καλά κατά την επεξεργασία συνόλων δεδομένων μεγάλης κλίμακας επειδή η ταχύτητα εκπαίδευσής του είναι πολύ γρήγορη και είναι κατάλληλη για σενάρια που απαιτούν γρήγορη εκπαίδευση μοντέλων, όπως ταξινόμηση εικόνων μεγάλης κλίμακας, επεξεργασία φυσικής γλώσσας και άλλες εργασίες.
Πρόβλεψη Βιομηχανίας : Η ELM έχει ένα ευρύ φάσμα εφαρμογών στον τομέα της βιομηχανικής πρόβλεψης, όπως ο ποιοτικός έλεγχος και η πρόβλεψη αστοχίας εξοπλισμού σε διαδικασίες βιομηχανικής παραγωγής. Μπορεί να εκπαιδεύσει γρήγορα προγνωστικά μοντέλα και να ανταποκριθεί γρήγορα σε δεδομένα σε πραγματικό χρόνο.
Ο χρηματοπιστωτικός τομέας : Το ELM μπορεί να χρησιμοποιηθεί για ανάλυση και πρόβλεψη οικονομικών δεδομένων, όπως πρόβλεψη τιμών μετοχών, διαχείριση κινδύνου, πιστοληπτική αξιολόγηση κ.λπ. Δεδομένου ότι τα οικονομικά δεδομένα είναι συνήθως υψηλών διαστάσεων, η γρήγορη ταχύτητα εκπαίδευσης του ELM είναι επωφελής για την επεξεργασία αυτών των δεδομένων.
ιατρική διάγνωση : Στον ιατρικό τομέα, το ELM μπορεί να χρησιμοποιηθεί για εργασίες όπως η πρόβλεψη ασθενειών και η ανάλυση ιατρικής εικόνας. Μπορεί να εκπαιδεύσει γρήγορα μοντέλα και να ταξινομήσει ή να μειώσει τα δεδομένα ασθενών, βοηθώντας τους γιατρούς να κάνουν ταχύτερες και ακριβέστερες διαγνώσεις.
Έξυπνο σύστημα ελέγχου : Το ELM μπορεί να χρησιμοποιηθεί σε έξυπνα συστήματα ελέγχου, όπως έξυπνα σπίτια, έξυπνα συστήματα μεταφορών κ.λπ. Μαθαίνοντας τα χαρακτηριστικά και τα πρότυπα του περιβάλλοντος, το ELM μπορεί να βοηθήσει το σύστημα να λάβει έξυπνες αποφάσεις και να βελτιώσει την αποδοτικότητα και την απόδοση του συστήματος.
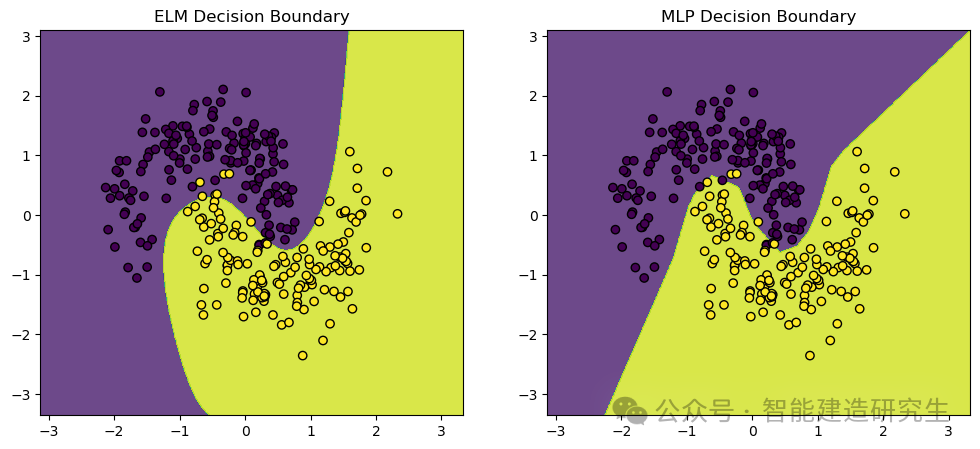
Χρησιμοποιούμεmake_moons Σύνολο δεδομένων, ένα σύνολο δεδομένων παιχνιδιών που χρησιμοποιείται συνήθως για εργασίες ταξινόμησης μηχανικής μάθησης και βαθιάς μάθησης. Δημιουργεί σημεία που κατανέμονται σε δύο τεμνόμενα σχήματα μισής Σελήνης, ιδανικά για την επίδειξη των ορίων απόδοσης και απόφασης των αλγορίθμων ταξινόμησης.
- import numpy as np
- import matplotlib.pyplot as plt
- from sklearn.datasets import make_moons
- from sklearn.model_selection import train_test_split
- from sklearn.neural_network import MLPClassifier
- from sklearn.preprocessing import StandardScaler
- from sklearn.metrics import accuracy_score
-
- # 定义极限学习机(ELM)类
- class ELM:
- def __init__(self, n_hidden_units):
- # 初始化隐藏层神经元数量
- self.n_hidden_units = n_hidden_units
-
- def _sigmoid(self, x):
- # 定义Sigmoid激活函数
- return 1 / (1 + np.exp(-x))
-
- def fit(self, X, y):
- # 随机初始化输入权重
- self.input_weights = np.random.randn(X.shape[1], self.n_hidden_units)
- # 随机初始化偏置
- self.biases = np.random.randn(self.n_hidden_units)
- # 计算隐藏层输出矩阵H
- H = self._sigmoid(np.dot(X, self.input_weights) + self.biases)
- # 计算输出权重
- self.output_weights = np.dot(np.linalg.pinv(H), y)
-
- def predict(self, X):
- # 计算隐藏层输出矩阵H
- H = self._sigmoid(np.dot(X, self.input_weights) + self.biases)
- # 返回预测结果
- return np.dot(H, self.output_weights)
-
- # 创建数据集并进行预处理
- X, y = make_moons(n_samples=1000, noise=0.2, random_state=42)
- # 将标签转换为二维数组(ELM需要二维数组作为标签)
- y = y.reshape(-1, 1)
-
- # 标准化数据
- scaler = StandardScaler()
- X_scaled = scaler.fit_transform(X)
-
- # 拆分训练集和测试集
- X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42)
-
- # 训练和比较ELM与MLP
-
- # 训练ELM
- elm = ELM(n_hidden_units=10)
- elm.fit(X_train, y_train)
- y_pred_elm = elm.predict(X_test)
- # 将预测结果转换为类别标签
- y_pred_elm_class = (y_pred_elm > 0.5).astype(int)
- # 计算ELM的准确率
- accuracy_elm = accuracy_score(y_test, y_pred_elm_class)
-
- # 训练MLP
- mlp = MLPClassifier(hidden_layer_sizes=(10,), max_iter=1000, random_state=42)
- mlp.fit(X_train, y_train.ravel())
- # 预测测试集结果
- y_pred_mlp = mlp.predict(X_test)
- # 计算MLP的准确率
- accuracy_mlp = accuracy_score(y_test, y_pred_mlp)
-
- # 打印ELM和MLP的准确率
- print(f"ELM Accuracy: {accuracy_elm}")
- print(f"MLP Accuracy: {accuracy_mlp}")
-
- # 可视化结果
- def plot_decision_boundary(model, X, y, ax, title):
- # 设置绘图范围
- x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
- y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
- # 创建网格
- xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01),
- np.arange(y_min, y_max, 0.01))
- # 预测网格中的所有点
- Z = model(np.c_[xx.ravel(), yy.ravel()])
- Z = (Z > 0.5).astype(int)
- Z = Z.reshape(xx.shape)
- # 画出决策边界
- ax.contourf(xx, yy, Z, alpha=0.8)
- # 画出数据点
- ax.scatter(X[:, 0], X[:, 1], c=y.ravel(), edgecolors='k', marker='o')
- ax.set_title(title)
-
- # 创建图形
- fig, axs = plt.subplots(1, 2, figsize=(12, 5))
-
- # 画出ELM的决策边界
- plot_decision_boundary(lambda x: elm.predict(x), X_test, y_test, axs[0], "ELM Decision Boundary")
- # 画出MLP的决策边界
- plot_decision_boundary(lambda x: mlp.predict(x), X_test, y_test, axs[1], "MLP Decision Boundary")
-
- # 显示图形
- plt.show()
-
- # 输出:
- '''
- ELM Accuracy: 0.9666666666666667
- MLP Accuracy: 0.9766666666666667
- '''
Οπτική έξοδος:
Το παραπάνω περιεχόμενο συνοψίζεται από το Διαδίκτυο, εάν είναι χρήσιμο, προωθήστε το την επόμενη φορά.

Έχει αφοσιωθεί στην έρευνα της τεχνολογίας για περισσότερα από 30 χρόνια και είναι ικανός σε διάφορες γλώσσες όπως java, linux, javascript, php, css κ.λπ. Έχει κάνει πολλές συνεισφορές στον τομέα του ανοιχτού κώδικα σταθμός τεκμηρίωσης προγραμματιστή για να μοιραστείτε ορισμένα ζητήματα στην ανάπτυξη τεχνολογίας για μελλοντική αναφορά

Ταχυδρομείο[email protected]