
yhteystietoni
Mailmesophia@protonmail.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
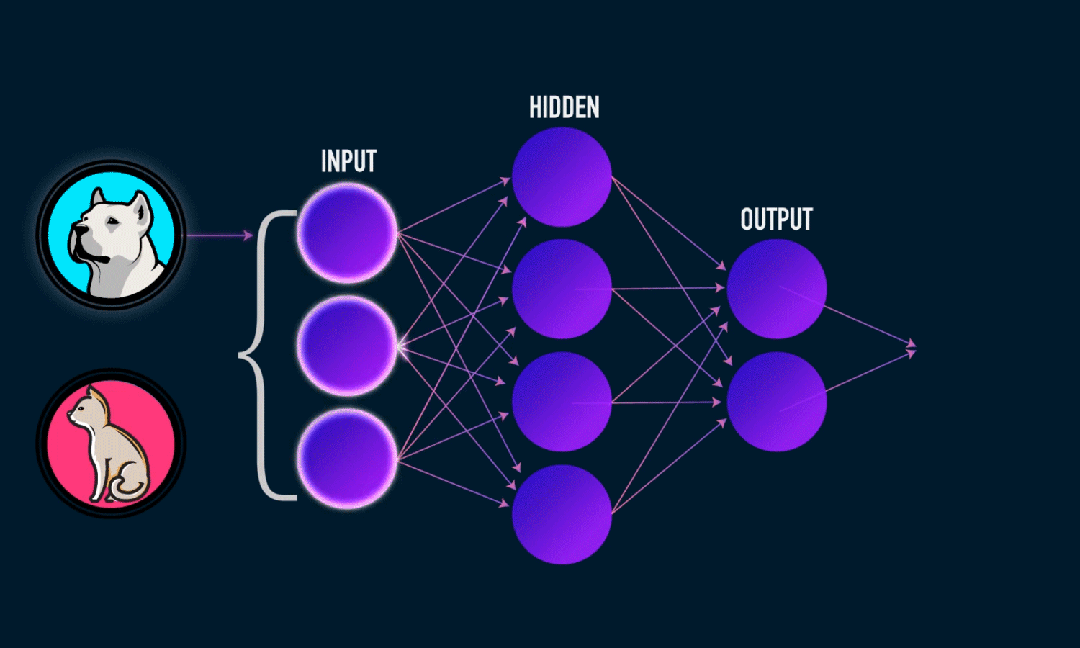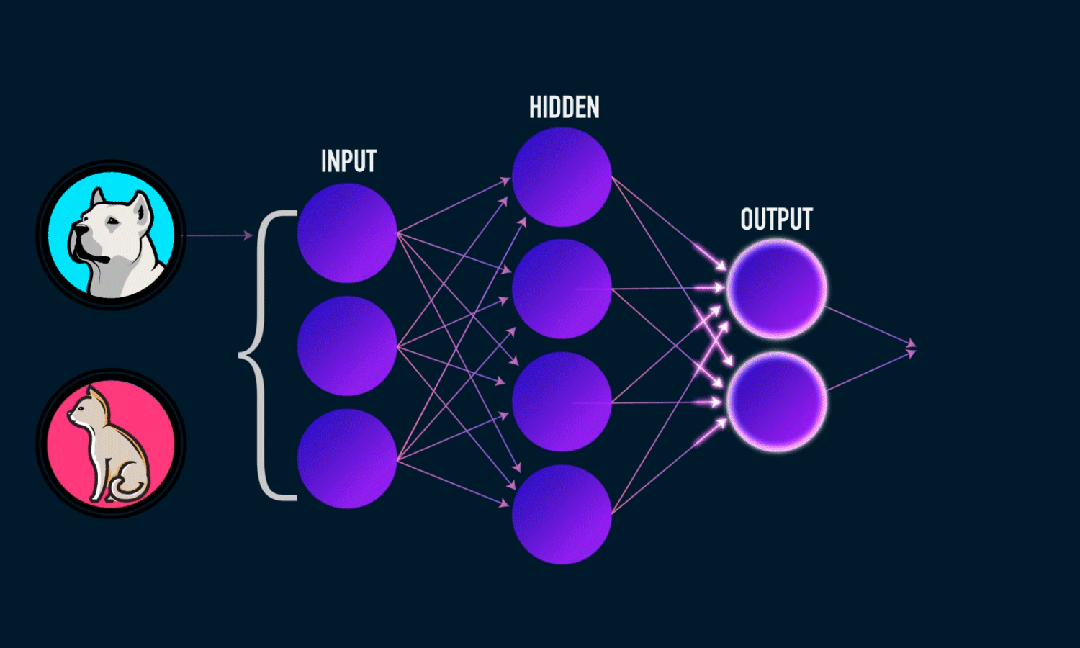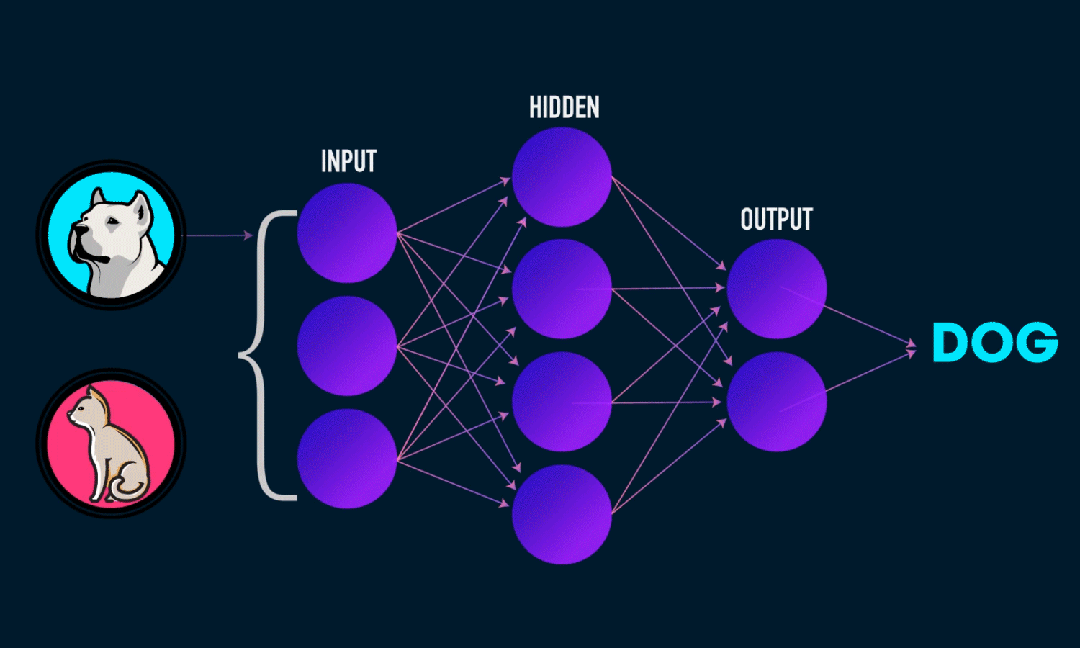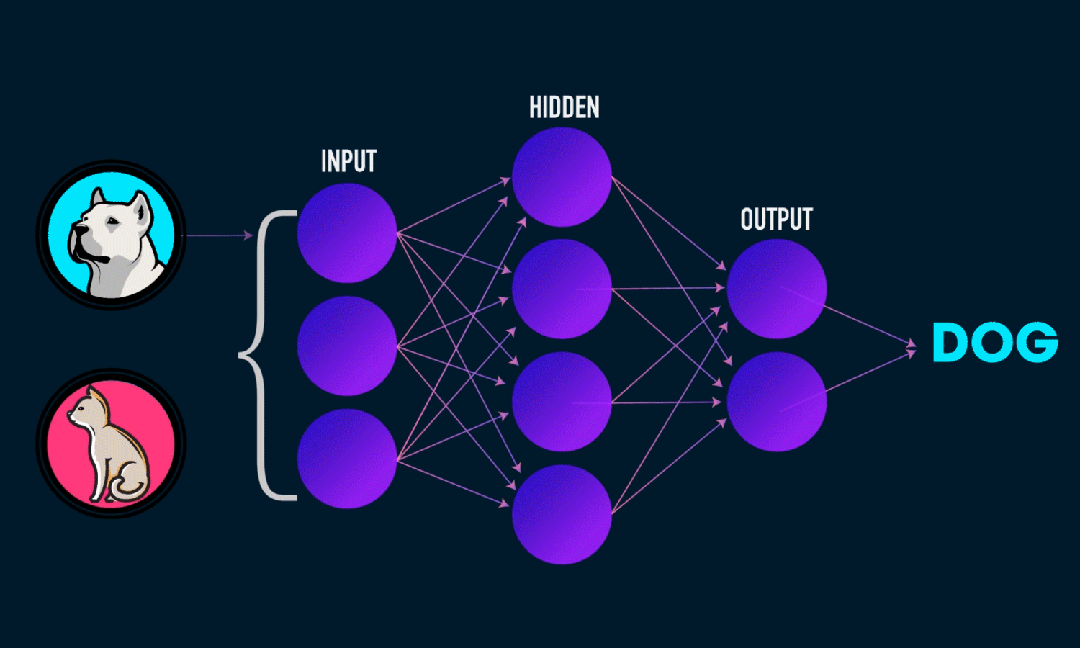
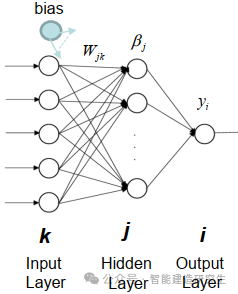
Extreme Learning Machine (ELM) on yksinkertainen yksikerroksinen feedforward hermoverkon (SLFN) oppimisalgoritmi. Teoriassa äärimmäiset oppimiskonealgoritmit (ELM) tarjoavat yleensä hyvän suorituskyvyn (kuuluvat koneoppimisalgoritmeihin) erittäin nopeilla oppimisnopeuksilla, ja niitä ehdottivat Huang et al. ELM:n pääominaisuus on, että sen oppimisnopeus on erittäin nopea verrattuna perinteisiin gradienttilaskeutumismenetelmiin (kuten BP-hermoverkkoon), ELM ei vaadi iteratiivista prosessia. Perusperiaate on valita satunnaisesti piilotetun kerroksen painot ja biasit ja sitten oppia tulosten painot minimoimalla tulostuskerroksen virhe.
img
Alusta satunnaisesti piilotetun kerroksen painot ja poikkeamat:
Piilotettujen kerrosten painot ja poikkeamat luodaan satunnaisesti ja pysyvät vakioina harjoituksen aikana.
Laske piilotetun kerroksen lähtömatriisi (eli aktivointifunktion tulos):
Laske piilotetun kerroksen tulos aktivointifunktiolla (kuten sigmoid, ReLU jne.).
Laske lähtöpaino:
Piilotetun kerroksen painot tuloskerrokseen lasketaan pienimmän neliösumman menetelmällä.
ELM:n matemaattinen kaava on seuraava:
Kun annetaan harjoitustietojoukko, jossa
Piilotetun kerroksen tulosmatriisin laskentakaava on:
missä on syöttömatriisi, on painomatriisi, joka on syötetty piilotettuun kerrokseen, on bias-vektori ja on aktivointifunktio.
Lähtöpainon laskentakaava on:
Niiden joukossa on piilokerroksen lähtömatriisin yleinen käänteis ja on lähtömatriisi.
Laajamittainen tietojoukon käsittely: ELM toimii hyvin suuren mittakaavan tietojoukkojen käsittelyssä, koska sen opetusnopeus on erittäin nopea ja sopii skenaarioihin, jotka vaativat nopeaa mallien harjoittelua, kuten suuren mittakaavan kuvien luokittelu, luonnollisen kielen käsittely ja muut tehtävät.
Toimialan ennuste : ELM:llä on laaja valikoima sovelluksia teollisen ennustamisen alalla, kuten laadunvalvonta ja laitevikojen ennustaminen teollisissa tuotantoprosesseissa. Se voi nopeasti kouluttaa ennakoivia malleja ja reagoida nopeasti reaaliaikaiseen dataan.
Rahoitussektori : ELM:ää voidaan käyttää taloudellisten tietojen analysointiin ja ennustamiseen, kuten osakekurssien ennustamiseen, riskienhallintaan, luottopisteytykseen jne. Koska taloustiedot ovat yleensä suuriulotteisia, ELM:n nopea harjoittelunopeus on edullinen näiden tietojen käsittelyssä.
lääketieteellinen diagnoosi : Lääketieteen alalla ELM:ää voidaan käyttää tehtäviin, kuten sairauksien ennustamiseen ja lääketieteellisen kuvan analysointiin. Se voi nopeasti kouluttaa malleja ja luokitella tai regressoida potilastietoja, mikä auttaa lääkäreitä tekemään nopeampia ja tarkempia diagnooseja.
Älykäs ohjausjärjestelmä : ELM:ää voidaan käyttää älykkäissä ohjausjärjestelmissä, kuten älykodeissa, älykkäissä kuljetusjärjestelmissä jne. Oppimalla ympäristön ominaisuudet ja mallit ELM voi auttaa järjestelmää tekemään älykkäitä päätöksiä ja parantamaan järjestelmän tehokkuutta ja suorituskykyä.
Käytämmemake_moons Tietojoukko, lelutietojoukko, jota käytetään yleisesti koneoppimiseen ja syväoppimisen luokittelutehtäviin. Se luo pisteitä, jotka on jaettu kahteen risteävään puolikuun muotoon, mikä on ihanteellinen luokitusalgoritmien suorituskyvyn ja päätösrajojen osoittamiseen.
- import numpy as np
- import matplotlib.pyplot as plt
- from sklearn.datasets import make_moons
- from sklearn.model_selection import train_test_split
- from sklearn.neural_network import MLPClassifier
- from sklearn.preprocessing import StandardScaler
- from sklearn.metrics import accuracy_score
-
- # 定义极限学习机(ELM)类
- class ELM:
- def __init__(self, n_hidden_units):
- # 初始化隐藏层神经元数量
- self.n_hidden_units = n_hidden_units
-
- def _sigmoid(self, x):
- # 定义Sigmoid激活函数
- return 1 / (1 + np.exp(-x))
-
- def fit(self, X, y):
- # 随机初始化输入权重
- self.input_weights = np.random.randn(X.shape[1], self.n_hidden_units)
- # 随机初始化偏置
- self.biases = np.random.randn(self.n_hidden_units)
- # 计算隐藏层输出矩阵H
- H = self._sigmoid(np.dot(X, self.input_weights) + self.biases)
- # 计算输出权重
- self.output_weights = np.dot(np.linalg.pinv(H), y)
-
- def predict(self, X):
- # 计算隐藏层输出矩阵H
- H = self._sigmoid(np.dot(X, self.input_weights) + self.biases)
- # 返回预测结果
- return np.dot(H, self.output_weights)
-
- # 创建数据集并进行预处理
- X, y = make_moons(n_samples=1000, noise=0.2, random_state=42)
- # 将标签转换为二维数组(ELM需要二维数组作为标签)
- y = y.reshape(-1, 1)
-
- # 标准化数据
- scaler = StandardScaler()
- X_scaled = scaler.fit_transform(X)
-
- # 拆分训练集和测试集
- X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42)
-
- # 训练和比较ELM与MLP
-
- # 训练ELM
- elm = ELM(n_hidden_units=10)
- elm.fit(X_train, y_train)
- y_pred_elm = elm.predict(X_test)
- # 将预测结果转换为类别标签
- y_pred_elm_class = (y_pred_elm > 0.5).astype(int)
- # 计算ELM的准确率
- accuracy_elm = accuracy_score(y_test, y_pred_elm_class)
-
- # 训练MLP
- mlp = MLPClassifier(hidden_layer_sizes=(10,), max_iter=1000, random_state=42)
- mlp.fit(X_train, y_train.ravel())
- # 预测测试集结果
- y_pred_mlp = mlp.predict(X_test)
- # 计算MLP的准确率
- accuracy_mlp = accuracy_score(y_test, y_pred_mlp)
-
- # 打印ELM和MLP的准确率
- print(f"ELM Accuracy: {accuracy_elm}")
- print(f"MLP Accuracy: {accuracy_mlp}")
-
- # 可视化结果
- def plot_decision_boundary(model, X, y, ax, title):
- # 设置绘图范围
- x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
- y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
- # 创建网格
- xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01),
- np.arange(y_min, y_max, 0.01))
- # 预测网格中的所有点
- Z = model(np.c_[xx.ravel(), yy.ravel()])
- Z = (Z > 0.5).astype(int)
- Z = Z.reshape(xx.shape)
- # 画出决策边界
- ax.contourf(xx, yy, Z, alpha=0.8)
- # 画出数据点
- ax.scatter(X[:, 0], X[:, 1], c=y.ravel(), edgecolors='k', marker='o')
- ax.set_title(title)
-
- # 创建图形
- fig, axs = plt.subplots(1, 2, figsize=(12, 5))
-
- # 画出ELM的决策边界
- plot_decision_boundary(lambda x: elm.predict(x), X_test, y_test, axs[0], "ELM Decision Boundary")
- # 画出MLP的决策边界
- plot_decision_boundary(lambda x: mlp.predict(x), X_test, y_test, axs[1], "MLP Decision Boundary")
-
- # 显示图形
- plt.show()
-
- # 输出:
- '''
- ELM Accuracy: 0.9666666666666667
- MLP Accuracy: 0.9766666666666667
- '''
Visuaalinen tulos:
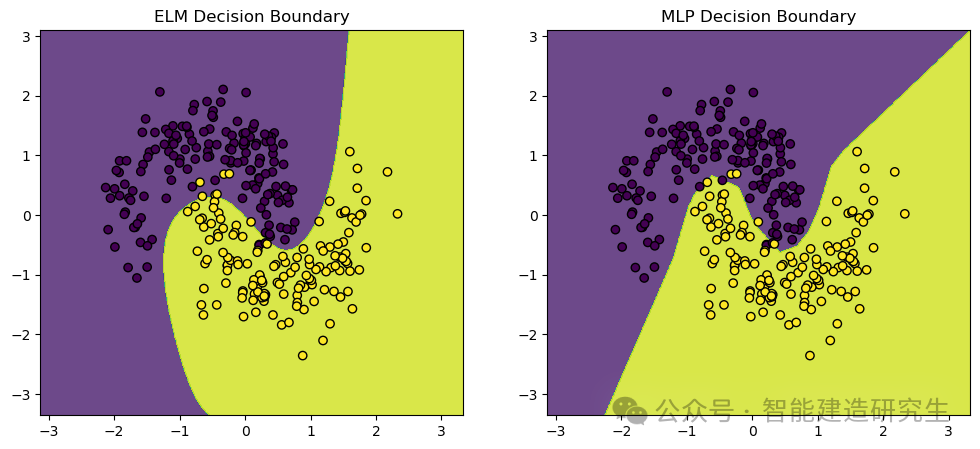
Yllä oleva sisältö on tiivistetty Internetistä, jos siitä on apua, lähetä se eteenpäin.

Hän on omistautunut teknologian tutkimukselle yli 30 vuoden ajan ja hallitsee useita kieliä, kuten java, linux, javascript, php, css jne. Hän on tehnyt paljon työtä avoimen lähdekoodin alalla Kehittäjän dokumentaatioasema jakaaksesi joitain teknologian kehityksen ongelmia tulevaa käyttöä varten

Mailmesophia@protonmail.com