
私の連絡先情報
郵便メール:
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
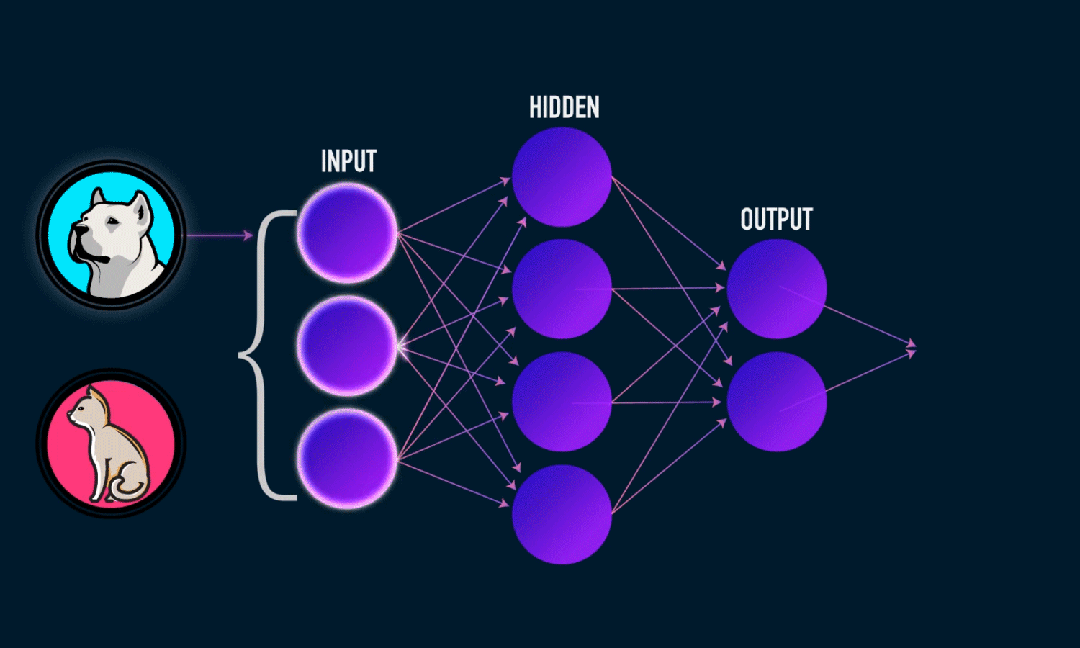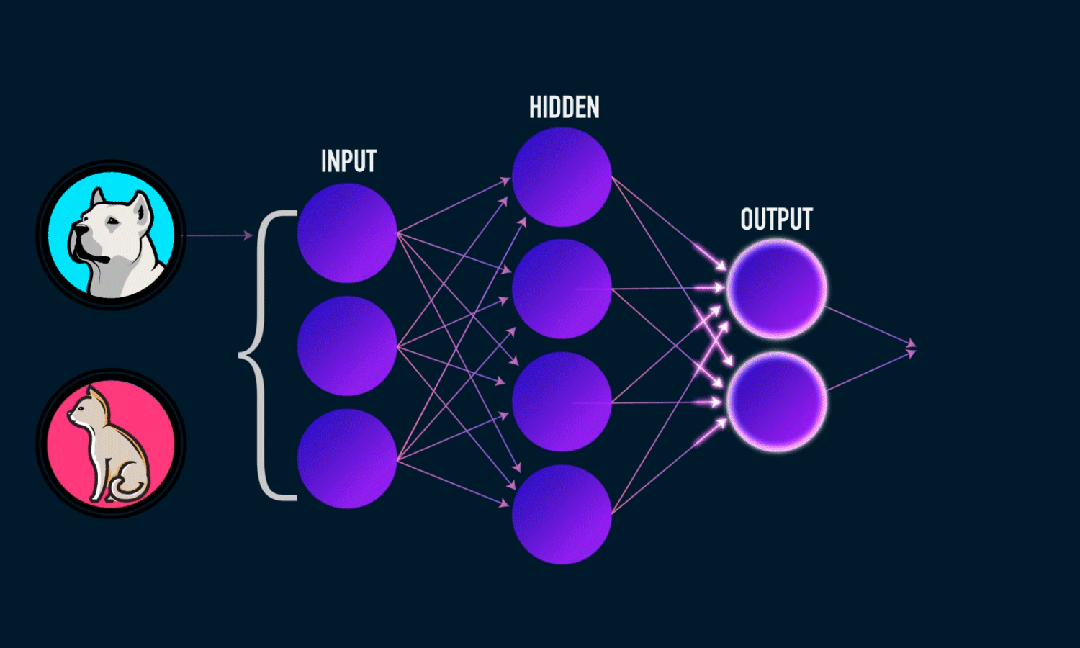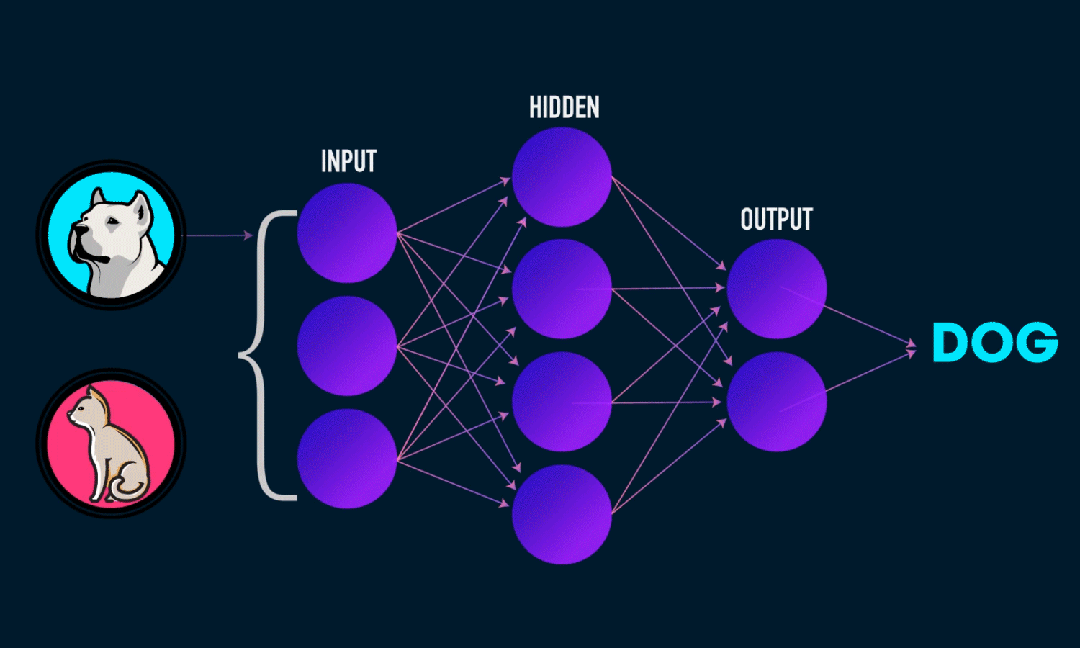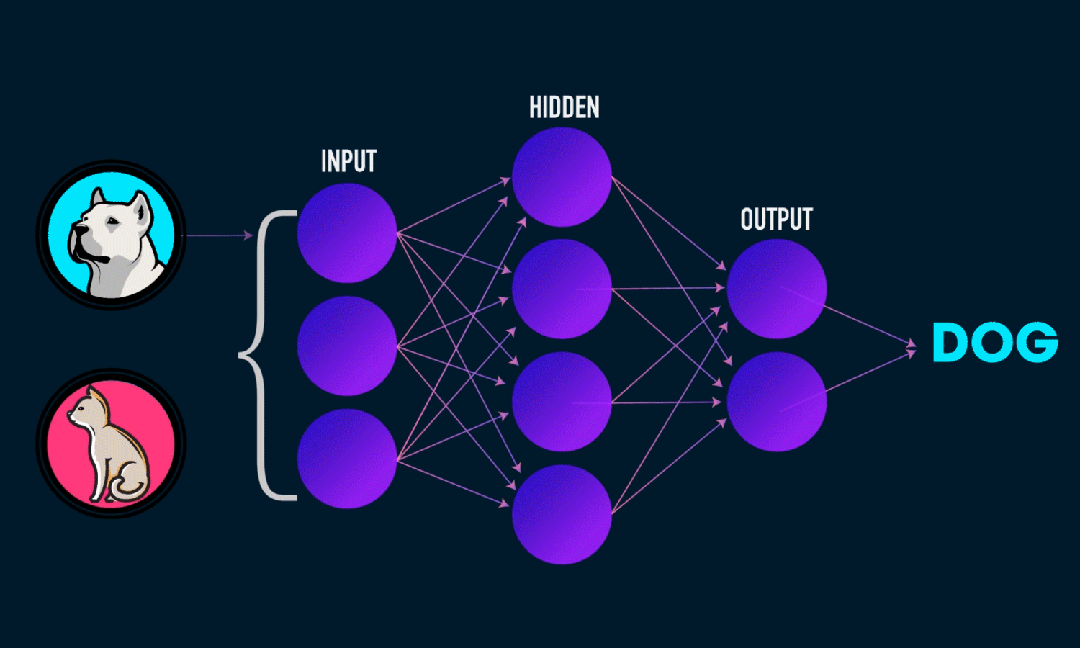
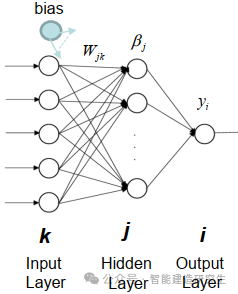
Extreme Learning Machine (ELM) は、シンプルな単層フィードフォワード ニューラル ネットワーク (SLFN) 学習アルゴリズムです。理論的には、極限学習機械アルゴリズム (ELM) は、非常に速い学習速度で (機械学習アルゴリズムに属する) 優れたパフォーマンスを提供する傾向があり、Huang らによって提案されました。 ELM の主な特徴は、従来の勾配降下法 (BP ニューラル ネットワークなど) と比較して、反復プロセスが必要ないことです。基本原理は、隠れ層の重みとバイアスをランダムに選択し、出力層の誤差を最小限に抑えて出力重みを学習することです。
画像
隠れ層への重みとバイアス入力をランダムに初期化します。:
隠れ層の重みとバイアスはランダムに生成され、トレーニング中は一定のままです。
隠れ層の出力行列 (つまり、活性化関数の出力) を計算します。:
活性化関数 (シグモイド、ReLU など) を使用して隠れ層の出力を計算します。
出力重量の計算:
隠れ層から出力層までの重みは最小二乗法で計算されます。
ELM の数式は次のとおりです。
与えられたトレーニング データセット 、ここで、
隠れ層の出力行列の計算式は次のとおりです。
ここで、 は入力行列、 は隠れ層への重み行列入力、 はバイアス ベクトル、 は活性化関数です。
出力重みの計算式は次のとおりです。
その中で、 は隠れ層出力行列の一般化逆行列であり、 は出力行列です。
大規模なデータセットの処理: ELM は、トレーニング速度が非常に速いため、大規模なデータ セットを処理する場合に優れたパフォーマンスを発揮し、大規模な画像分類、自然言語処理、その他のタスクなど、モデルの高速トレーニングが必要なシナリオに適しています。
業界の予測 :ELMは、工業生産プロセスにおける品質管理や設備の故障予測など、産業予測の分野で幅広い用途があります。予測モデルを迅速にトレーニングし、リアルタイム データに迅速に対応できます。
金融セクター : ELM は、株価予測、リスク管理、信用スコアリングなどの財務データの分析と予測に使用できます。財務データは通常高次元であるため、ELM のトレーニング速度が速いことは、これらのデータの処理に有利です。
医療診断 :医療分野では、ELMは病気の予測や医療画像解析などの業務に活用できます。モデルを迅速にトレーニングし、患者データを分類または回帰できるため、医師がより迅速かつ正確な診断を行えるようになります。
インテリジェント制御システム : ELM は、スマート ホーム、高度道路交通システムなどのインテリジェント制御システムで使用できます。 ELM は、環境の特性とパターンを学習することで、システムがインテリジェントな意思決定を行い、システムの効率とパフォーマンスを向上させるのに役立ちます。
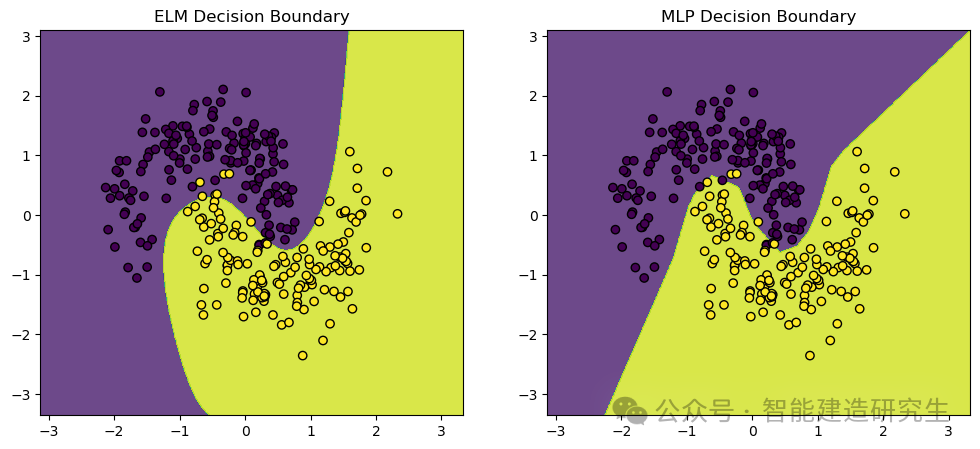
を使用しておりますmake_moonsデータセット。機械学習および深層学習の分類タスクに一般的に使用されるおもちゃのデータセット。 2 つの交差する半月形に分散された点を生成します。これは、分類アルゴリズムのパフォーマンスと決定境界を実証するのに最適です。
- import numpy as np
- import matplotlib.pyplot as plt
- from sklearn.datasets import make_moons
- from sklearn.model_selection import train_test_split
- from sklearn.neural_network import MLPClassifier
- from sklearn.preprocessing import StandardScaler
- from sklearn.metrics import accuracy_score
-
- # 定义极限学习机(ELM)类
- class ELM:
- def __init__(self, n_hidden_units):
- # 初始化隐藏层神经元数量
- self.n_hidden_units = n_hidden_units
-
- def _sigmoid(self, x):
- # 定义Sigmoid激活函数
- return 1 / (1 + np.exp(-x))
-
- def fit(self, X, y):
- # 随机初始化输入权重
- self.input_weights = np.random.randn(X.shape[1], self.n_hidden_units)
- # 随机初始化偏置
- self.biases = np.random.randn(self.n_hidden_units)
- # 计算隐藏层输出矩阵H
- H = self._sigmoid(np.dot(X, self.input_weights) + self.biases)
- # 计算输出权重
- self.output_weights = np.dot(np.linalg.pinv(H), y)
-
- def predict(self, X):
- # 计算隐藏层输出矩阵H
- H = self._sigmoid(np.dot(X, self.input_weights) + self.biases)
- # 返回预测结果
- return np.dot(H, self.output_weights)
-
- # 创建数据集并进行预处理
- X, y = make_moons(n_samples=1000, noise=0.2, random_state=42)
- # 将标签转换为二维数组(ELM需要二维数组作为标签)
- y = y.reshape(-1, 1)
-
- # 标准化数据
- scaler = StandardScaler()
- X_scaled = scaler.fit_transform(X)
-
- # 拆分训练集和测试集
- X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42)
-
- # 训练和比较ELM与MLP
-
- # 训练ELM
- elm = ELM(n_hidden_units=10)
- elm.fit(X_train, y_train)
- y_pred_elm = elm.predict(X_test)
- # 将预测结果转换为类别标签
- y_pred_elm_class = (y_pred_elm > 0.5).astype(int)
- # 计算ELM的准确率
- accuracy_elm = accuracy_score(y_test, y_pred_elm_class)
-
- # 训练MLP
- mlp = MLPClassifier(hidden_layer_sizes=(10,), max_iter=1000, random_state=42)
- mlp.fit(X_train, y_train.ravel())
- # 预测测试集结果
- y_pred_mlp = mlp.predict(X_test)
- # 计算MLP的准确率
- accuracy_mlp = accuracy_score(y_test, y_pred_mlp)
-
- # 打印ELM和MLP的准确率
- print(f"ELM Accuracy: {accuracy_elm}")
- print(f"MLP Accuracy: {accuracy_mlp}")
-
- # 可视化结果
- def plot_decision_boundary(model, X, y, ax, title):
- # 设置绘图范围
- x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
- y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
- # 创建网格
- xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01),
- np.arange(y_min, y_max, 0.01))
- # 预测网格中的所有点
- Z = model(np.c_[xx.ravel(), yy.ravel()])
- Z = (Z > 0.5).astype(int)
- Z = Z.reshape(xx.shape)
- # 画出决策边界
- ax.contourf(xx, yy, Z, alpha=0.8)
- # 画出数据点
- ax.scatter(X[:, 0], X[:, 1], c=y.ravel(), edgecolors='k', marker='o')
- ax.set_title(title)
-
- # 创建图形
- fig, axs = plt.subplots(1, 2, figsize=(12, 5))
-
- # 画出ELM的决策边界
- plot_decision_boundary(lambda x: elm.predict(x), X_test, y_test, axs[0], "ELM Decision Boundary")
- # 画出MLP的决策边界
- plot_decision_boundary(lambda x: mlp.predict(x), X_test, y_test, axs[1], "MLP Decision Boundary")
-
- # 显示图形
- plt.show()
-
- # 输出:
- '''
- ELM Accuracy: 0.9666666666666667
- MLP Accuracy: 0.9766666666666667
- '''
視覚的な出力:
上記の内容はインターネットからまとめたものです。お役に立ちましたら、また次回お楽しみください。

彼は 30 年以上テクノロジーの研究に専念しており、java、linux、javascript、php、css などのさまざまな言語に堪能であり、オープンソース分野で多くの貢献を行っています。将来の参考のために技術開発におけるいくつかの問題を共有する開発者ドキュメント ステーション。

郵便メール: