2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
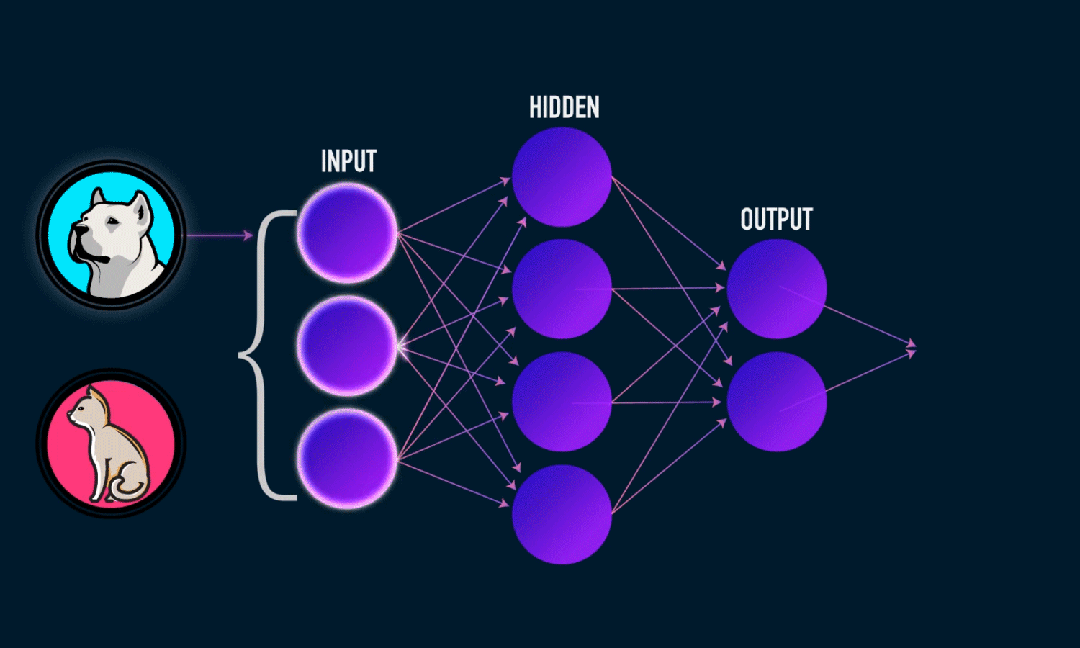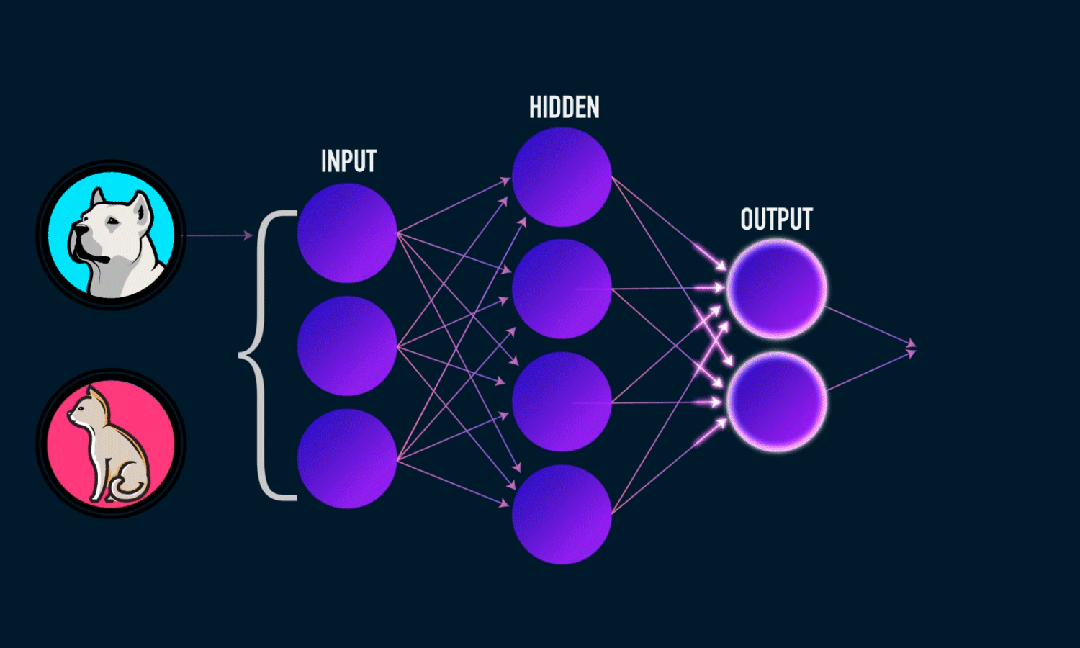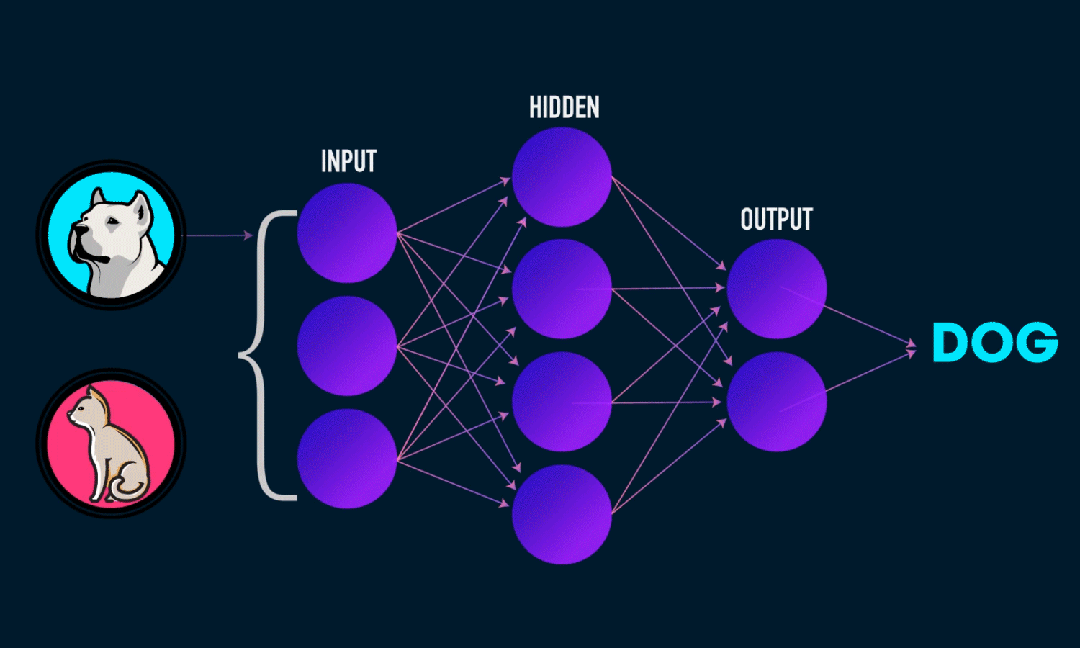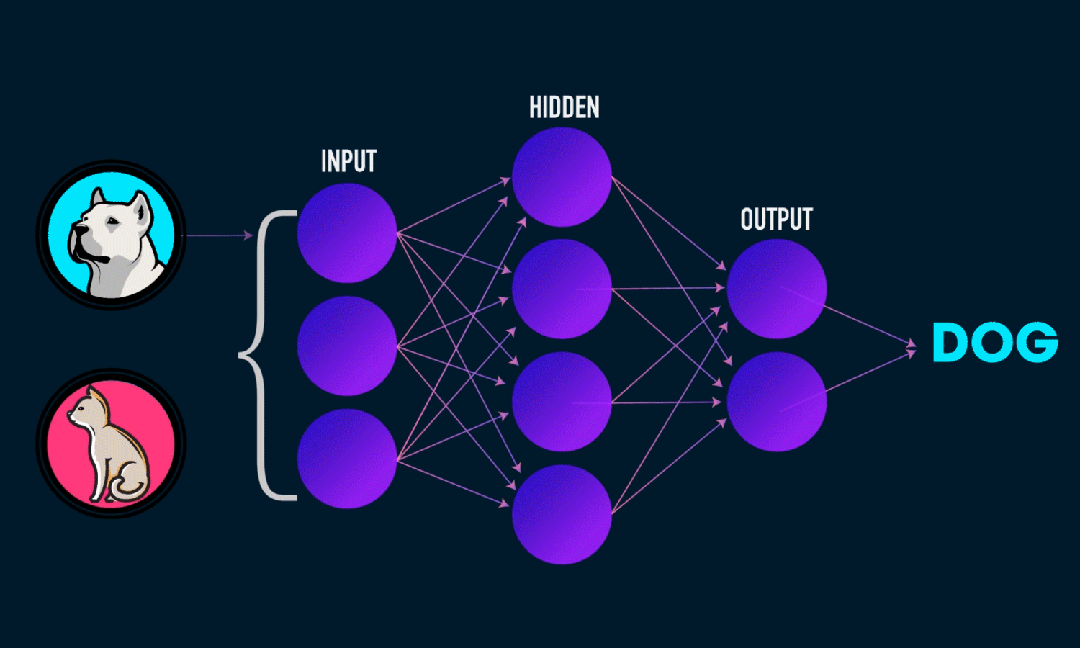
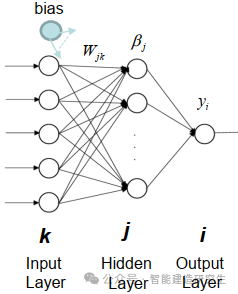
Extreme Learning Machine (ELM) est un simple algorithme d’apprentissage de réseau neuronal à action directe (SLFN) monocouche. En théorie, les algorithmes d'apprentissage automatique extrêmes (ELM) ont tendance à fournir de bonnes performances (appartenant aux algorithmes d'apprentissage automatique) avec des vitesses d'apprentissage extrêmement rapides, et ont été proposés par Huang et al. La principale caractéristique d'ELM est que sa vitesse d'apprentissage est très rapide. Par rapport aux méthodes traditionnelles de descente de gradient (telles que le réseau neuronal BP), ELM ne nécessite pas de processus itératif. Le principe de base est de sélectionner aléatoirement les poids et biais de la couche cachée, puis d'apprendre les poids de sortie en minimisant l'erreur de la couche de sortie.
image
Initialiser de manière aléatoire les poids et les biais entrés dans la couche cachée:
Les poids et biais des couches cachées sont générés aléatoirement et restent constants pendant l'entraînement.
Calculer la matrice de sortie de la couche cachée (c'est-à-dire la sortie de la fonction d'activation):
Calculez la sortie de la couche cachée à l'aide d'une fonction d'activation (telle que sigmoïde, ReLU, etc.).
Calculer le poids de sortie:
Les poids de la couche cachée à la couche de sortie sont calculés par la méthode des moindres carrés.
La formule mathématique d’ELM est la suivante :
Étant donné un ensemble de données d'entraînement, où ,
La formule de calcul de la matrice de sortie de la couche cachée est :
où est la matrice d'entrée, est la matrice de poids entrée dans la couche cachée, est le vecteur de biais et est la fonction d'activation.
La formule de calcul du poids de sortie est la suivante :
Parmi eux, se trouve l'inverse généralisé de la matrice de sortie de la couche cachée et la matrice de sortie.
Traitement d'ensembles de données à grande échelle: ELM fonctionne bien lors du traitement d'ensembles de données à grande échelle car sa vitesse de formation est très rapide et convient aux scénarios qui nécessitent une formation rapide des modèles, tels que la classification d'images à grande échelle, le traitement du langage naturel et d'autres tâches.
Prévisions de l'industrie : ELM a un large éventail d'applications dans le domaine de la prévision industrielle, telles que le contrôle qualité et la prévision des pannes d'équipement dans les processus de production industrielle. Il peut rapidement former des modèles prédictifs et réagir rapidement aux données en temps réel.
Le secteur financier : ELM peut être utilisé pour l'analyse et la prévision de données financières, telles que la prévision du cours des actions, la gestion des risques, la notation de crédit, etc. Étant donné que les données financières sont généralement de grande dimension, la vitesse de formation rapide d'ELM est avantageuse pour le traitement de ces données.
diagnostic médical : Dans le domaine médical, ELM peut être utilisé pour des tâches telles que la prédiction des maladies et l'analyse d'images médicales. Il peut rapidement former des modèles et classer ou régresser les données des patients, aidant ainsi les médecins à établir des diagnostics plus rapides et plus précis.
Système de contrôle intelligent : ELM peut être utilisé dans les systèmes de contrôle intelligents, tels que les maisons intelligentes, les systèmes de transport intelligents, etc. En apprenant les caractéristiques et les modèles de l'environnement, ELM peut aider le système à prendre des décisions intelligentes et à améliorer son efficacité et ses performances.
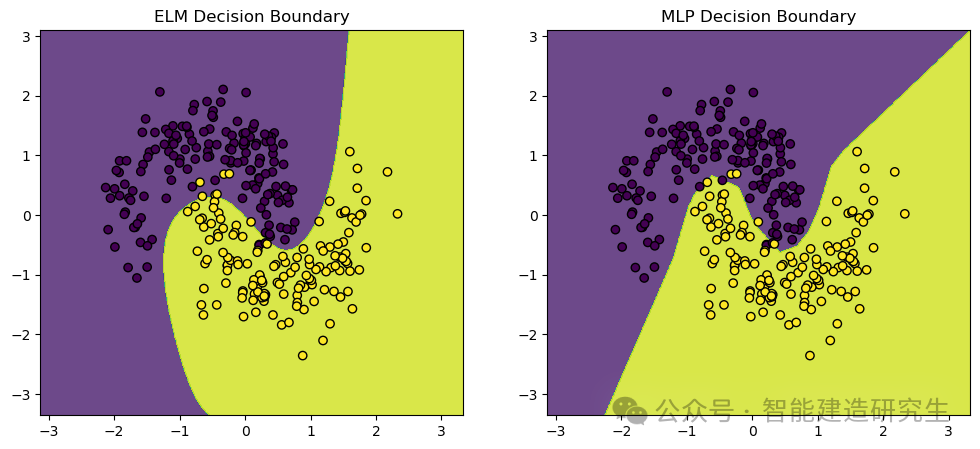
Nous utilisonsmake_moons Ensemble de données, un ensemble de données sur les jouets couramment utilisé pour les tâches de classification d'apprentissage automatique et d'apprentissage profond. Il génère des points répartis en deux formes de demi-lune qui se croisent, idéales pour démontrer les performances et les limites de décision des algorithmes de classification.
- import numpy as np
- import matplotlib.pyplot as plt
- from sklearn.datasets import make_moons
- from sklearn.model_selection import train_test_split
- from sklearn.neural_network import MLPClassifier
- from sklearn.preprocessing import StandardScaler
- from sklearn.metrics import accuracy_score
-
- # 定义极限学习机(ELM)类
- class ELM:
- def __init__(self, n_hidden_units):
- # 初始化隐藏层神经元数量
- self.n_hidden_units = n_hidden_units
-
- def _sigmoid(self, x):
- # 定义Sigmoid激活函数
- return 1 / (1 + np.exp(-x))
-
- def fit(self, X, y):
- # 随机初始化输入权重
- self.input_weights = np.random.randn(X.shape[1], self.n_hidden_units)
- # 随机初始化偏置
- self.biases = np.random.randn(self.n_hidden_units)
- # 计算隐藏层输出矩阵H
- H = self._sigmoid(np.dot(X, self.input_weights) + self.biases)
- # 计算输出权重
- self.output_weights = np.dot(np.linalg.pinv(H), y)
-
- def predict(self, X):
- # 计算隐藏层输出矩阵H
- H = self._sigmoid(np.dot(X, self.input_weights) + self.biases)
- # 返回预测结果
- return np.dot(H, self.output_weights)
-
- # 创建数据集并进行预处理
- X, y = make_moons(n_samples=1000, noise=0.2, random_state=42)
- # 将标签转换为二维数组(ELM需要二维数组作为标签)
- y = y.reshape(-1, 1)
-
- # 标准化数据
- scaler = StandardScaler()
- X_scaled = scaler.fit_transform(X)
-
- # 拆分训练集和测试集
- X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42)
-
- # 训练和比较ELM与MLP
-
- # 训练ELM
- elm = ELM(n_hidden_units=10)
- elm.fit(X_train, y_train)
- y_pred_elm = elm.predict(X_test)
- # 将预测结果转换为类别标签
- y_pred_elm_class = (y_pred_elm > 0.5).astype(int)
- # 计算ELM的准确率
- accuracy_elm = accuracy_score(y_test, y_pred_elm_class)
-
- # 训练MLP
- mlp = MLPClassifier(hidden_layer_sizes=(10,), max_iter=1000, random_state=42)
- mlp.fit(X_train, y_train.ravel())
- # 预测测试集结果
- y_pred_mlp = mlp.predict(X_test)
- # 计算MLP的准确率
- accuracy_mlp = accuracy_score(y_test, y_pred_mlp)
-
- # 打印ELM和MLP的准确率
- print(f"ELM Accuracy: {accuracy_elm}")
- print(f"MLP Accuracy: {accuracy_mlp}")
-
- # 可视化结果
- def plot_decision_boundary(model, X, y, ax, title):
- # 设置绘图范围
- x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
- y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
- # 创建网格
- xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01),
- np.arange(y_min, y_max, 0.01))
- # 预测网格中的所有点
- Z = model(np.c_[xx.ravel(), yy.ravel()])
- Z = (Z > 0.5).astype(int)
- Z = Z.reshape(xx.shape)
- # 画出决策边界
- ax.contourf(xx, yy, Z, alpha=0.8)
- # 画出数据点
- ax.scatter(X[:, 0], X[:, 1], c=y.ravel(), edgecolors='k', marker='o')
- ax.set_title(title)
-
- # 创建图形
- fig, axs = plt.subplots(1, 2, figsize=(12, 5))
-
- # 画出ELM的决策边界
- plot_decision_boundary(lambda x: elm.predict(x), X_test, y_test, axs[0], "ELM Decision Boundary")
- # 画出MLP的决策边界
- plot_decision_boundary(lambda x: mlp.predict(x), X_test, y_test, axs[1], "MLP Decision Boundary")
-
- # 显示图形
- plt.show()
-
- # 输出:
- '''
- ELM Accuracy: 0.9666666666666667
- MLP Accuracy: 0.9766666666666667
- '''
Résultat visuel :
Le contenu ci-dessus est résumé à partir d'Internet. S'il est utile, veuillez le transmettre à la prochaine fois !

Il se consacre à la recherche technologique depuis plus de 30 ans et maîtrise divers langages tels que java, linux, javascript, php, css, etc. Il a apporté de nombreuses contributions dans le domaine de l'open source. station de documentation pour les développeurs pour partager certains problèmes de développement technologique pour référence future.

