2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Tällä viikolla luin artikkelin Tulkittava CEEMDAN-FE-LSTM-muuntajahybridimalli pintaveden kokonaisfosforipitoisuuksien ennustamiseksi. Tässä artikkelissa ehdotetaan hybridimallia TP-ennusteelle. Tässä artikkelissa ehdotetaan hybridimallia TP-ennusteelle, nimittäin CF-LT-mallia. Malli yhdistää innovatiivisesti täysin integroidun empiirisen moodihajoamisen (EMD) adaptiiviseen kohinankäsittelyyn, sumean entropiaanalyysin, pitkän lyhytaikaisen muistiverkon (LSTM) ja muuntajateknologian. Ottamalla käyttöön datataajuusjaon rekonstruktioteknologian tämä malli ratkaisee tehokkaasti yli- ja alisovitusongelmat, joita esiintyy herkästi, kun perinteiset koneoppimismallit käsittelevät korkeadimensionaalista dataa. Samalla huomiomekanismin soveltaminen mahdollistaa CF-LT-mallin ylittämisen muiden mallien rajoituksista, joiden avulla on vaikea määrittää pitkän aikavälin riippuvuuksia datan välillä pitkän aikavälin ennusteita tehtäessä. Ennustetulokset osoittavat, että CF-LT-malli saavutti määrityskertoimen (R2) 0,37 - 0,87 testiaineistossa, mikä oli merkittävä parannus 0,05 - 0,17 (eli 6 % - 85 %) verrattuna kontrolliin. malli. Lisäksi CF-LT-malli osoitti myös parhaan huippusuorituskyvyn.
Tämän viikon viikkolehti purkaa paperin "Interpretable CEEMDAN-FE-LSTM-muuntajahybridimalli" pintaveden kokonaisfosforipitoisuuksien ennustamiseen. Tässä artikkelissa esitellään hybridimalli, CF-LT, erityisesti TP-ennustetta varten. Malli integroi innovatiivisesti Complete Ensemble Empirical Mode Decomposition (EMD) adaptiiviseen kohinankäsittelyyn, sumean entropiaanalyysiin, Long Short-Term Memory (LSTM) -verkkoihin ja Transformer-teknologiaan. Ottamalla käyttöön datan taajuuden jaon ja rekonstruoinnin CF-LT ratkaisee tehokkaasti yli- ja alisovitusongelmia, joita perinteiset koneoppimismallit usein kohtaavat käsitellessään korkeadimensionaalista dataa. Lisäksi huomiomekanismin soveltaminen antaa CF-LT:lle mahdollisuuden voittaa muiden mallien rajoitukset pitkäaikaisten riippuvuuksien määrittämisessä datapisteiden välillä pitkän aikavälin ennusteiden aikana. Ennustetulokset osoittavat, että CF-LT saavuttaa päätöskertoimen (R2), joka vaihtelee välillä 0,37 - 0,87 testiaineistoissa, mikä edustaa merkittävää parannusta 0,05 - 0,17 (tai 6 % - 85 %) verrattuna kontrollimalleihin. Lisäksi CF-LT tarjoaa parhaan huippusuorituskyvyn.
标题: Tulkittava CEEMDAN-FE-LSTM-muuntajahybridimalli pintaveden kokonaisfosforipitoisuuksien ennustamiseen
Kirjoittaja: Jiefu Yao, Shuai Chen, Xiaohong Ruan
julkaisu:Journal of Hydrology Osa 629, helmikuu 2024, 130609
链接: https://www.sciencedirect.com/science/article/pii/S0022169424000039?via%3Dihub
Tässä artikkelissa ehdotetaan hybridimallia TP-ennusteelle. Tämä malli (CF-LT) yhdistää täysin integroidun empiirisen muodon hajotuksen (EMD) mukautuvan kohinan, sumean entropian, pitkän lyhytaikaisen muistin ja muuntajan.Datataajuusjaon rekonstruointiKäyttöönotto ratkaisee tehokkaasti yli- ja alisovitusongelmat, jotka ilmenivät, kun aikaisemmat koneoppimismallit kohtasivat korkeaulotteisen datan.huomiomekanismi Tämä ratkaisee ongelman, että nämä mallit eivät pysty muodostamaan pitkän aikavälin riippuvuuksia tietojen välillä ja tekemään pitkän aikavälin ennusteita. Ennustetulokset osoittavat, että CF-LT-malli saavuttaa testidatasarjan määrityskertoimen (R2) 0,37-0,87, mikä on 0,05-0,17 (6-85 %) korkeampi kuin kontrollimalli. Lisäksi CF-LT-malli tarjosi parhaan huippuennusteen.
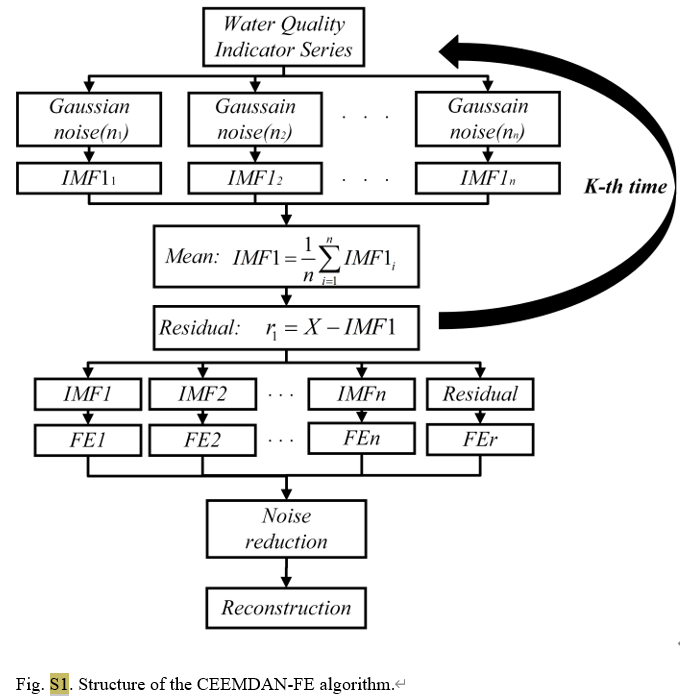
Edistyksellisenä aikasarjaanalyysimenetelmänä CEEMDAN vähentää tehokkaasti perinteisessä EMD:ssä esiintyvää moodialias-ongelmaa lisäämällä adaptiivista kohinaa empiiriseen moodihajotteluprosessiin (EMD). Se voi hajottaa alkuperäisen signaalin sarjaksi luontaisen tilan funktioita (IMF). Jokainen IMF edustaa signaalin eri aikaskaalaominaisuuksia, mikä tekee monimutkaisten signaalien analysoinnista intuitiivisempaa ja tarkempaa. Tässä tutkimuksessa CEEMDAN:ia käytettiin käsittelemään päivittäisiä vedenlaatutietoja kolmelta Taijärven seuranta-asemalta, jakamalla fosforin kokonaispitoisuus ja muut veden laatuparametrit, kuten veden lämpötila, pH, liuennut happi jne., signaaleiksi eri taajuuskaistoilla.
Algoritmi S1: Täydellinen empiirinen muodon hajottaminen adaptiivisen kohinan kanssa (CEEMDAN)
yi (t) = y (t) + ϵ 0 vi (t) i = 1, 2, …, n (S1) y^{i}(t)=y(t)+epsilon_0v^i(t)quad i =1,2,pisteet,ntag{S1}yi(t)=y(t)+ϵ0vi(t)i=1,2,…,n(S1)
IMF1 i = E 0 ( yi ( t ) ) + r 1 i IMF1 ‾ = 1 n IMF1 i (S2) teksti{IMF1}_i=E_0(y^i(t))+r^i_1neliviiva{teksti{IMF1} }=frac1ntext{IMF1}_itag{S2}IMF1i=E0(yi(t))+r1iIMF1=n1IMF1i(S2)
r 1 = yi ( t ) − IMF1 ‾ (S3) r_1=y^i(t)-overline{text{IMF1}}tunniste{S3}r1=yi(t)−IMF1(S3)
IMF2 ‾ = 1 n ∑ i = 1 n E 1 ( r 1 + ϵ 1 E 1 ( vi ( t ) ) ) (S4) overline{text{IMF2}}=frac1nsum^n_{i=1}E_1(r_1+ epsilon_1E_1(v^i(t)))-tunniste{S4}IMF2=n1i=1∑nE1(r1+ϵ1E1(vi(t)))(S4)
y ( t ) = ∑ l = 1 K − 1 IMF1 ‾ + r K (S5) y(t)=summa^{K-1}_{l=1}yliviiva{teksti{IMF1}}+r_Ktag{S5}y(t)=l=1∑K−1IMF1+rK(S5)
CEEMDAN-FE-osan osalta jaamme ensin alkuperäisen tietojoukon koulutus- ja testaustietosarjoiksi ja käytämme sitten CEEMDANia kahden tietojoukon kunkin ominaisuuden hajottamiseksi useiksi sisäisiksi toiminnoiksi (IMF). Kunkin IMF:n FE-arvojen läheisyyden mukaan ne rekonstruoidaan korkeataajuisiksi (IMFH), keskitaajuuksiksi (IMFM), matalataajuisiksi (IMFL) ja trenditermeiksi (IMFT) komponenteiksi, jotka heijastavat eri näkökohtia. IMF:stä.
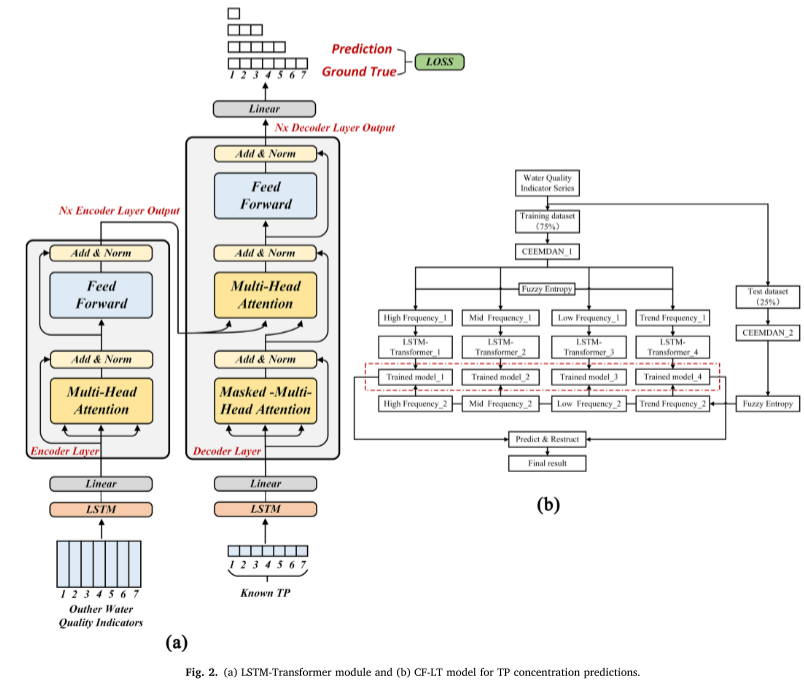
LSTM-Transformer-osassa, kooderissa ja dekooderissa, LSTM:n piilotettu kerros korvataan Transformer position -koodauksella tulodatan välisen ajallisen riippuvuuden määrittämiseksi. Erityinen laskentaprosessi on seuraava (kuva 2a).
SHAP on peliteoriamenetelmä minkä tahansa ML-mallin tulosteen tulkitsemiseen.Syöttöominaisuuksien vaikutuksen määrittämiseksi mallin ulostuloon syöttöominaisuudet z = [ z 1 , . . . , zp ] z = [z1, ..., zp]z=[z1,...,zs]Liittyy koulutettuun syväoppimismalliin F.
F = f ( z ) = ϕ 0 + ∑ i = 1 M ϕ izi (12) F=f(z)=phi_0+sum_{i=1}^M phi_iz_i-tunniste{12}F=f(z)=ϕ0+i=1∑Mϕizi(12)
φ i ∈ R φ_i ∈ Rφi∈RIlmaisee kunkin ominaisuuden panoksen malliin, joka saadaan seuraavalla kaavalla:
ϕ i ( F , x ) = ∑ z ≤ x ∣ z ∣ ! ( M − ∣ z ∣ − 1 ) ! M ! [ F ( z ) − F ( z / i ) ] (13) phi_i(F,x)=summa_{zleq x}frac{|z|!(M-|z|-1)!}{M!}[ F(z)-F(z/i)] -tunniste{13}ϕi(F,x)=z≤x∑M!∣z∣!(M−∣z∣−1)
Tutkimuksessa ehdotetaan uutta mallia kokonaisfosforipitoisuuksien ennustamiseen. Malli yhdistää CEEM DAN-, FE-, LSTM- ja Transformer-teknologiat ja käyttää SHAP:ia mallin tulosteen tulkitsemiseen. Tämän tutkimuksen päätavoitteena on arvioida ehdotetun CEEMDAN-FE-LSTM-Transformer (CF-LT) -mallin suorituskykyä TP-pitoisuuden ennustamisessa Tai-järven suulla ja soveltaa SHAP:ia CF-LT:n tulosten tulkitsemiseen. malli. Tämän pitäisi paljastaa keskeiset tekijät, jotka vaikuttavat TP-pitoisuuteen alueella, ja niiden vastemekanismit.
Korkeadimensionaalinen datan hajottaminen voi tuottaa suuren määrän modaalisia komponentteja. Tämän ongelman ratkaisemiseksi Fuzzy Entropy (FE), tehokas menetelmä ajan monimutkaisuuden laskentaan, voidaan yhdistää CEEMDANin kanssa. Tämä yhdistelmä rekonstruoi tehokkaasti CEEMDANin hajotetut osasignaalit, mikä vähentää alitaajuusmallien määrää.
LSTMT-muuntajamallit voivat siepata suhteita ei-viereisten aikapisteiden välillä säilyttäen samalla syöttötietojen aikasarjan ominaisuudet.
Muuntajamallit käyttävät huomiomekanismeja kahden paikan välisten korrelaatioiden tunnistamiseen tietyssä kontekstissa koulutuksen aikana. Tämä mahdollistaa olennaisen tiedon tehokkaan hankinnan ja vähentää tiedon redundanssia.
Tämän artikkelin tärkeimmät panokset ovat neljällä osa-alueella:
tietojoukko : Taihu-järven allas sijaitsee Jangtse-joen alajuoksulla, ja sen pinta-ala on 36 900 neliökilometriä, tiheä jokiverkosto ja lukuisia järviä. Taihu-järvi on tyypillinen matala järvi. Altaalle on ominaista pohjoisen subtrooppisen vyöhykkeen kostea ilmasto, jonka keskimääräinen vuotuinen lämpötila on 15-17 °C ja keskimääräinen vuotuinen sademäärä 1181 mm. Tässä tutkimuksessa käytettiin Yaoxiangqiaon aseman, Zhihugangin aseman ja Guanduqiaon aseman vedenlaadun seurantatietoja (kuva S2). Nämä seuranta-asemat sijaitsevat Taihukoussa, joka on valtakunnallinen keskeinen vedenlaadun arviointiosasto. Tiedot ovat peräisin Jiangsun maakunnan ympäristönseurantakeskuksesta.
Arviointikriteeri : Mallin suorituskyvyn arvioinnissa käytetään useita avainindikaattoreita: determinaatiokerroin (R²), keskimääräinen neliövirhe (MSE) ja keskimääräinen absoluuttinen prosenttivirhe (MAPE). R² mittaa sovitusasteen mallin ennustetun arvon ja todellisen arvon välillä, mikä tarkoittaa, että mallilla on vahva ennustekyky. MAPE heijastaa ennustevirheen kokoa prosentteina. Arvo Lower tarkoittaa tarkempia ennusteita.
Toteutustiedot : Kokeellinen prosessi sisältää tietojen esikäsittelyn, mallikoulutuksen ja testauksen. Täydellinen kokeellinen menettely on perustettu arvioimaan ehdotetun mallin suorituskykyä eri tietosarjoissa ja ennusteaikaikkunoissa. Ensinnäkin tiedot esikäsitellään CEEMDAN-FE-menetelmällä, joka poistaa informaatiohäiriöt lisäämällä täysin integroidun empiirisen muodon hajottelun adaptiivisella kohinalla, poimii monimittaista tietoa ja käyttää sumeaa entropiaa alisignaalien määrän vähentämiseen. Seuraavaksi käsitellyt tiedot jaetaan harjoitussarjaan ja testisarjaan suhteissa 75 % ja 25 %. Harjoitusvaiheessa esikäsitelty opetustietojoukko syötetään LSTM-Transformer-malliin. Käytä backpropagaatiota ja Adam Optimizer -työkalua mallien painojen päivittämiseen ja käytä ruudukkohakua LSTMTransformer-moduulin parhaiden hyperparametrien tunnistamiseen varmistaaksesi mallin suorituskyvyn eri ennusteaikaikkunoissa (7 päivää, 5 päivää, 3 päivää, 1 päivä) optimaalisesti.
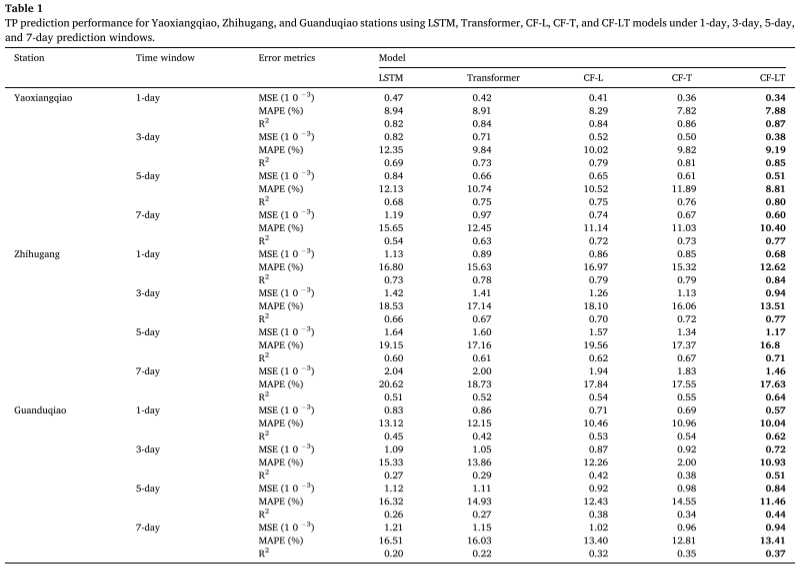
Kokeelliset tulokset : Sovellettaessa parasta harjoitusmallia testiaineistoon taulukossa on yhteenveto CF-LT-, LSTM-, Transformer-, CF-L- ja CF-T-mallien TP-pitoisuusennusteista eri paikoissa ja erilaisissa ennusteaikaikkunoissa. Ehdotettu CF-LT-malli antaa parhaat tulokset kaikille kolmelle arviointimittarille. R2:n suhteen CF-LT-malli vaihtelee välillä 0,37-0,87, kun taas seuraavaksi parhaat CF-L- ja CF-T-mallit ovat 0,32-0,84 ja 0,35-0,86. Tämä osoittaa, että LSTM:n pitkän aikavälin muistin yhdistäminen Transformerin huomiomekanismiin voi parantaa ennusteen tarkkuutta. Kun verrataan huonoimpia LSTM- ja Transformer-malleja CF-L- ja CF-T-malleihin, MAPE vaihtelee välillä 8,94-20,62 % (LSTM) ja 8,91-18,73 % (Transformer) ja 8,29-19,56 % (CF -L). ja 7,82-17,55 % (CF-T). Nämä tulokset osoittavat, että tietojen hajottaminen ja taajuusjakomallinnus parantavat merkittävästi ennusteen tarkkuutta sieppaamalla enemmän alkuperäiseen dataan piilotettua tietoa.
Kokonaisfosforin TP-pitoisuuteen vaikuttavien tekijöiden ennustaminen:
Keskimääräistä absoluuttista SHAP-arvoa (MASV) käytetään määrittämään syöteominaisuuksien (WT, PH, DO, COD, EC, TU, TN, NH3-N, TP) vaikutus TP-ennustetuloksiin sitä suurempi vaikutus mallin ennustetuloksiin. Tutkimukset osoittavat, että itse aiemman TP-pitoisuussarjan lisäksi kokonaistyppi (TN) ja sameus (TU) ovat kaksi pääasiallista TP-ennusteeseen vaikuttavaa tekijää. Tämä osoittaa, että TP:n muutoksiin eivät vaikuta suoraan historialliset pitoisuudet, vaan ne liittyvät myös läheisesti levien kasvudynamiikkaan, joka liittyy ei-pistekuormituspäästöihin ja typpi-fosforisuhteeseen vesistössä. Erityisesti TN:n ja TP:n välinen merkittävä korrelaatio korostaa näiden kahden kytkentävaikutusta järven ravinnekierrossa ja korostaa ei-pistelähteen typen syötteen merkitystä fosforipitoisuuden ennustamisessa.
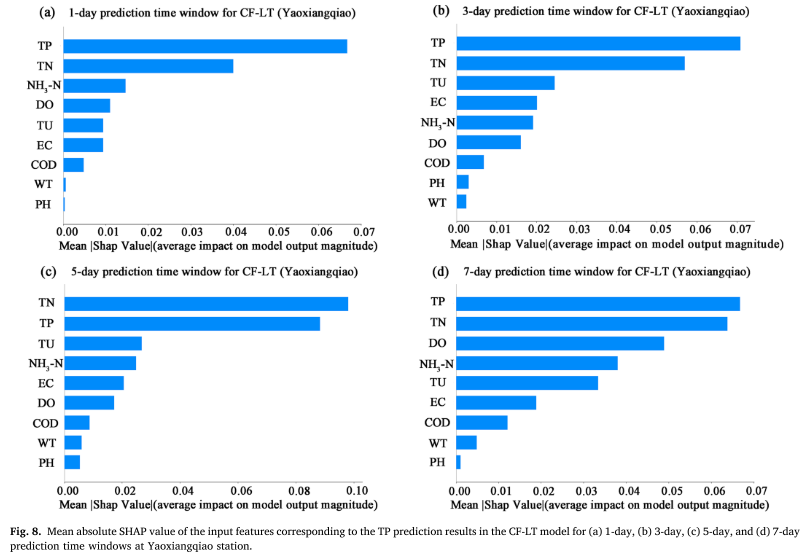
Näistä tuloksista voidaan tehdä seuraavat havainnot:
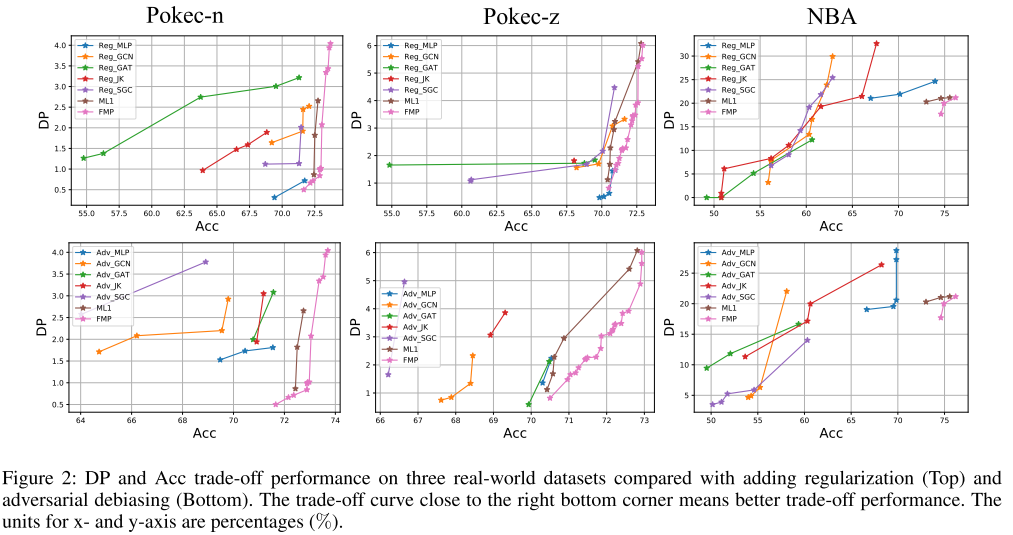
Vertailu kontradiktoriseen vääristelyyn ja laillistamiseen : Jaettu satunnaisesti 50 %/25 %/25 % koulutus-, validointi- ja testitietosarjoille. Kuvassa 2 on esitetty Pareto-optimikäyrät kaikille menetelmille, joissa oikea alakulma edustaa ihanteellista suorituskykyä (korkein tarkkuus ja pienin ennustepoikkeama).
Tässä artikkelissa ehdotettu CF-LT-hybridimalli yhdistää CEEM DAN-, FE-, LSTM- ja Transformer-moduulit pintaveden TP-pitoisuuden ennustamiseksi. Tämä hybridilähestymistapa ratkaisee korkeadimensionaalisten tietojen aiheuttamat mallien yli- ja alisovittamisen puutteet sekä kyvyttömyyden muodostaa pitkän aikavälin riippuvuuksia datan välillä pitkän aikavälin ennusteita tehtäessä. Lisäksi SHAP-arvoja käytetään tulkitsemaan CF-LT-mallin ulostuloa.
Malli käyttää kolmen Taihu-järven altaan vedenlaadun seuranta-aseman tietoja tuottaakseen 9 vedenlaadun indikaattoria eri ennusteaikaikkunoissa. Ohjausmalleina käytetään LSTM-, Transformer-, CF-L- ja CF-T-algoritmeja. CF-LT-mallin R2-arvo on 0,37–0,87, MSE-arvo 0,34 × 10–3–1,46 × 10–3 ja MAPE-arvo 7,88–17,63 % testiaineistossa, mikä osoittaa, että kaikki kolme indikaattorit ovat parempia kuin LSTM, Transformer, CF-L ja CF-T tulokset. Ehdotettu CF-LT-malli tuotti myös parhaat huipputulokset. SHAP-tulkinnan perusteella havaitsimme, että TU ja TN (pois lukien TP-pitoisuuden varhaiset aikasarjat) ovat tärkeitä TP-ennusteeseen vaikuttavia tekijöitä, mikä osoittaa, että muutokset TP:ssä eivät liity pelkästään TP-pitoisuuden varhaisiin tasoihin, vaan myös TP:n vaikutuksiin. keskittyminen. Ei-pisteperäisten saastepäästöjen ja vesikasvien välinen suhde Taihu-järven suistossa. Lisäksi on syytä huomata, että TN ja TU vaikuttavat enemmän TP-pitoisuuden ennustamiseen sadekauden aikana. Siksi tämän tutkimuksen tulokset osoittavat, että CF-LT-malli tarjoaa lisätietoa TP:n vastemekanismin ymmärtämiseksi, kun erilaiset ympäristöolosuhteet muuttuvat.
CEEMDAN ja FE tietojen esikäsittely
def ceemdan_fe_preprocessing(data):
# CEEMDAN分解
imfs, residue = ceemdan(data, **ceemdan_params)
# 计算各个IMF的模糊熵
fe_values = []
for imf in imfs:
fe_values.append(fuzzy_entropy(imf)) # 假定fuzzy_entropy为计算模糊熵的函数
# 根据FE值重组IMFs
imfs_sorted = [imf for _, imf in sorted(zip(fe_values, imfs))]
imf_hf, imf_mf, imf_lf, imf_trend = imfs_sorted[:4], imfs_sorted[4:8], imfs_sorted[8:12], imfs_sorted[12:]
return np.concatenate((imf_hf, imf_mf, imf_lf, imf_trend), axis=1)
# 应用到数据上
preprocessed_data = ceemdan_fe_preprocessing(original_data)
LSTM&Transformer
def get_positional_encoding(max_len, d_model):
pe = np.zeros((max_len, d_model))
position = np.arange(0, max_len).reshape(-1, 1)
div_term = np.exp(np.arange(0, d_model, 2) * -(np.log(10000.0) / d_model))
pe[:, 0::2] = np.sin(position * div_term)
pe[:, 1::2] = np.cos(position * div_term)
return pe
def transformer_encoder(inputs, d_model, num_heads, ff_dim):
x = MultiHeadAttention(num_heads=num_heads, key_dim=d_model)(inputs, inputs)
x = LayerNormalization()(Add()([inputs, x]))
x = Dense(ff_dim, activation='relu')(x)
x = Dense(d_model)(x)
x = LayerNormalization()(Add()([inputs, x]))
return x
def transformer_decoder(inputs, encoder_outputs, d_model, num_heads, ff_dim):
return decoder_output
input_features = Input(shape=(input_shape))
lstm_out = LSTM(lstm_units)(input_features) # LSTM
pos_encodings = get_positional_encoding(max_seq_length, d_model)
transformer_in = Add()([lstm_out, pos_encodings])
transformer_encoded = transformer_encoder(transformer_in, d_model, num_heads, ff_dim)
decoder_output = transformer_decoder(decoder_input, transformer_encoded, d_model, num_heads, ff_dim)
output_layer = Dense(output_dim, activation='linear')(decoder_output)
model = Model(inputs=input_features, outputs=output_layer)
model.compile(optimizer=Adam(learning_rate), loss='mse')
Tässä tutkimuksessa kehitettiin tulkittava CEEMDAN-FE-LSTM-Transformer-hybridimalli pintaveden kokonaisfosforipitoisuuden ennustamiseen. Malli paransi merkittävästi ennustetarkkuutta edistyneen tiedon esikäsittelytekniikan ja syväoppimismallien yhdistämisen ansiosta, ja tarjoaa selkeän ominaisuusselvityksen. SHAPin kautta. Kokeelliset tulokset vahvistivat mallin tehokkuuden, erityisesti keskeisten ympäristötekijöiden tunnistamisen, tarjoten tehokkaan työkalun vesistöjen rehevöitymisen hallintaan ja pilaantumisen hallintaan.
[1] Jiefu Yao, Shuai Chen, Xiaohong Ruan. Tulkittava CEEMDAN-FE-LSTM-muuntajahybridimalli pintaveden kokonaisfosforipitoisuuksien ennustamiseen. [J]Journal of Hydrology Osa 629, helmikuu 2024, 130609

Hän on omistautunut teknologian tutkimukselle yli 30 vuoden ajan ja hallitsee useita kieliä, kuten java, linux, javascript, php, css jne. Hän on tehnyt paljon työtä avoimen lähdekoodin alalla Kehittäjän dokumentaatioasema jakaaksesi joitain teknologian kehittämisen ongelmia tulevaa käyttöä varten

