2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Diese Woche habe ich einen Artikel mit dem Titel Interpretable CEEMDAN-FE-LSTM-Transformer-Hybridmodell zur Vorhersage der Gesamtphosphorkonzentrationen in Oberflächenwasser gelesen. In diesem Artikel wird ein Hybridmodell für die TP-Vorhersage vorgeschlagen. In diesem Artikel wird ein Hybridmodell für die TP-Vorhersage vorgeschlagen, nämlich das CF-LT-Modell. Das Modell kombiniert auf innovative Weise vollständig integrierte empirische Modenzerlegung (EMD) mit adaptiver Rauschverarbeitung, Fuzzy-Entropieanalyse, Long-Short-Term-Memory-Network (LSTM) und Transformer-Technologie. Durch die Einführung der Datenfrequenzteilungsrekonstruktionstechnologie löst dieses Modell effektiv die Überanpassungs- und Unteranpassungsprobleme, die häufig auftreten, wenn herkömmliche Modelle für maschinelles Lernen mit hochdimensionalen Daten arbeiten. Gleichzeitig ermöglicht die Anwendung des Aufmerksamkeitsmechanismus dem CF-LT-Modell, die Einschränkungen anderer Modelle zu überwinden, die es schwierig machen, langfristige Abhängigkeiten zwischen Daten herzustellen, wenn langfristige Vorhersagen getroffen werden. Die Vorhersageergebnisse zeigen, dass das CF-LT-Modell im Testdatensatz ein Bestimmtheitsmaß (R2) von 0,37 bis 0,87 erreichte, was einer signifikanten Verbesserung von 0,05 bis 0,17 (d. h. 6 % bis 85 %) im Vergleich zur Kontrolle entspricht Modell. Darüber hinaus zeigte das CF-LT-Modell auch die beste Peak-Vorhersageleistung.
Die Wochenzeitung dieser Woche entschlüsselt das Papier mit dem Titel „Interpretierbares CEEMDAN-FE-LSTM-Transformer-Hybridmodell zur Vorhersage der Gesamtphosphorkonzentrationen in Oberflächenwasser“. Dieses Papier stellt ein Hybridmodell, CF-LT, speziell für die TP-Vorhersage vor. Das Modell integriert auf innovative Weise Complete Ensemble Empirical Mode Decomposition (EMD) mit adaptiver Rauschverarbeitung, Fuzzy-Entropieanalyse, Long Short-Term Memory (LSTM)-Netzwerken und Transformer-Technologie. Durch die Einführung von Datenfrequenzteilung und -rekonstruktion behebt CF-LT effektiv die Probleme von Über- und Unteranpassung, die bei herkömmlichen maschinellen Lernmodellen beim Umgang mit hochdimensionalen Daten häufig auftreten. Darüber hinaus ermöglicht die Anwendung des Aufmerksamkeitsmechanismus CF-LT, die Einschränkungen anderer Modelle bei der Herstellung langfristiger Abhängigkeiten zwischen Datenpunkten während langfristiger Vorhersagen zu überwinden. Die Vorhersageergebnisse zeigen, dass CF-LT einen Entscheidungskoeffizienten (R2) im Bereich von 0,37 bis 0,87 in den Testdatensätzen erreicht, was einer signifikanten Verbesserung von 0,05 bis 0,17 (oder 6 % bis 85 %) gegenüber den Kontrollmodellen entspricht. Darüber hinaus bietet CF-LT die beste Spitzenvorhersageleistung.
Titel: Interpretierbares CEEMDAN-FE-LSTM-Transformator-Hybridmodell zur Vorhersage der Gesamtphosphorkonzentration in Oberflächenwasser
Autor: Jiefu Yao, Shuai Chen, Xiaohong Ruan
freigeben:Zeitschrift für Hydrologie Band 629, Februar 2024, 130609
Quelle: https://www.sciencedirect.com/science/article/pii/S0022169424000039?via%3Dihub
In diesem Artikel wird ein Hybridmodell für die TP-Vorhersage vorgeschlagen. Dieses Modell (CF-LT) kombiniert vollständig integrierte Empirical Mode Decomposition (EMD) mit adaptivem Rauschen, Fuzzy-Entropie, langem Kurzzeitgedächtnis und Transformer.Rekonstruktion der DatenfrequenzteilungDie Einführung von löst effektiv die Über- und Unteranpassungsprobleme, die auftraten, als frühere Modelle für maschinelles Lernen mit hochdimensionalen Daten konfrontiert wurden.Aufmerksamkeitsmechanismus Dadurch wird das Problem überwunden, dass diese Modelle keine langfristigen Abhängigkeiten zwischen Daten herstellen und langfristige Vorhersagen treffen können. Die Vorhersageergebnisse zeigen, dass das CF-LT-Modell im Testdatensatz einen Bestimmtheitskoeffizienten (R2) von 0,37–0,87 erreicht, was 0,05–0,17 (6 %–85 %) höher ist als das Kontrollmodell. Darüber hinaus lieferte das CF-LT-Modell die beste Spitzenvorhersage.
Als fortschrittliche Zeitreihenanalysemethode reduziert CEEMDAN effektiv das bei herkömmlicher EMD bestehende Mode-Aliasing-Problem, indem adaptives Rauschen zum EMD-Prozess (empirical mode decomposition) hinzugefügt wird. Es kann das Originalsignal in eine Reihe von intrinsischen Modusfunktionen (IMFs) zerlegen. Jede IMF repräsentiert unterschiedliche Zeitskaleneigenschaften des Signals und macht dadurch die Analyse komplexer Signale intuitiver und genauer. In dieser Studie wurde CEEMDAN verwendet, um tägliche Wasserqualitätsdaten von drei Überwachungsstationen im Tai-See zu verarbeiten und dabei die Gesamtphosphorkonzentration und andere Wasserqualitätsparameter wie Wassertemperatur, pH-Wert, gelöster Sauerstoff usw. in Signale in verschiedenen Frequenzbändern aufzuteilen.
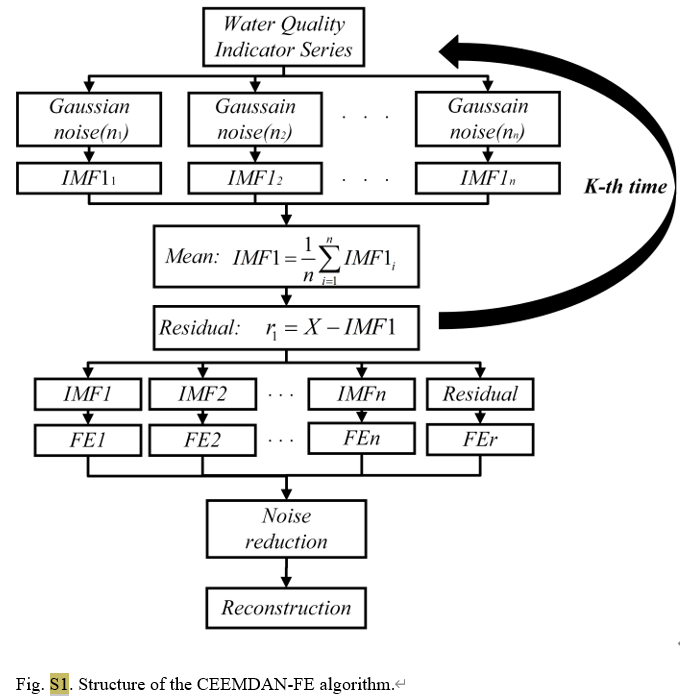
Algorithmus S1: Vollständige Ensemble-Empirische Mode-Zerlegung mit adaptivem Rauschen (CEEMDAN)
yi ( t ) = y ( t ) + ϵ 0 vi ( t ) i = 1 , 2 , … , n (S1) y^{i}(t)=y(t)+epsilon_0v^i(t)quad i=1,2,dots,ntag{S1}jichchchchchchchchchchchchchchchchchch(T)=j(T)+ϵ0gegenichchchchchchchchchchchchchchchchchch(T)ichchchchchchchchchchchchchchchchchch=1,2,…,N(Staffel 1)
IMF1 i = E 0 ( yi ( t ) ) + r 1 i IMF1 ‾ = 1 n IMF1 i (S2) text{IMF1}_i=E_0(y^i(t))+r^i_1quad overline{text{IMF1}}=frac1ntext{IMF1}_itag{S2}IMF1ichchchchchchchchchchchchchchchchchch=E0(jichchchchchchchchchchchchchchchchchch(T))+R1ichchchchchchchchchchchchchchchchchchIMF1=N1IMF1ichchchchchchchchchchchchchchchchchch(Staffel 2)
r1 = yi (t) − IMF1 ‾ (S3) r_1=y^i(t)-overline{text{IMF1}}tag{S3}R1=jichchchchchchchchchchchchchchchchchch(T)−IMF1(S3)
IMF2 ‾ = 1 n ∑ i = 1 n E 1 ( r 1 + ϵ 1 E 1 ( vi ( t ) ) ) (S4) overline{text{IMF2}}=frac1nsum^n_{i=1}E_1(r_1+epsilon_1E_1(v^i(t))) tag{S4}IMF2=N1ichchchchchchchchchchchchchchchchchch=1∑NE1(R1+ϵ1E1(gegenichchchchchchchchchchchchchchchchchch(T)))(Staffel 4)
y ( t ) = ∑ l = 1 K − 1 IMF1 ‾ + r K (S5) y(t)=Summe^{K-1}_{l=1}overline{text{IMF1}}+r_Ktag{S5}j(T)=m=1∑K−1IMF1+RK(Staffel 5)
Für den CEEMDAN-FE-Teil teilen wir zunächst den Originaldatensatz in Trainings- und Testdatensätze auf und wenden dann CEEMDAN an, um jedes Merkmal in den beiden Datensätzen in mehrere intrinsische Modusfunktionen (IMFs) zu zerlegen. Entsprechend der Nähe der FE-Werte jedes IWF werden sie in Hochfrequenz- (IMFH), Zwischenfrequenz- (IMFM), Niederfrequenz- (IMFL) und Trendterm- (IMFT) Komponenten rekonstruiert, die verschiedene Aspekte des IWF widerspiegeln .
Für den LSTM-Transformer-Teil wird im Encoder und Decoder die verborgene Schicht von LSTM durch die Transformer-Positionscodierung ersetzt, um die zeitliche Abhängigkeit zwischen Eingabedaten herzustellen. Der spezifische Berechnungsprozess ist wie folgt (Abbildung 2a).
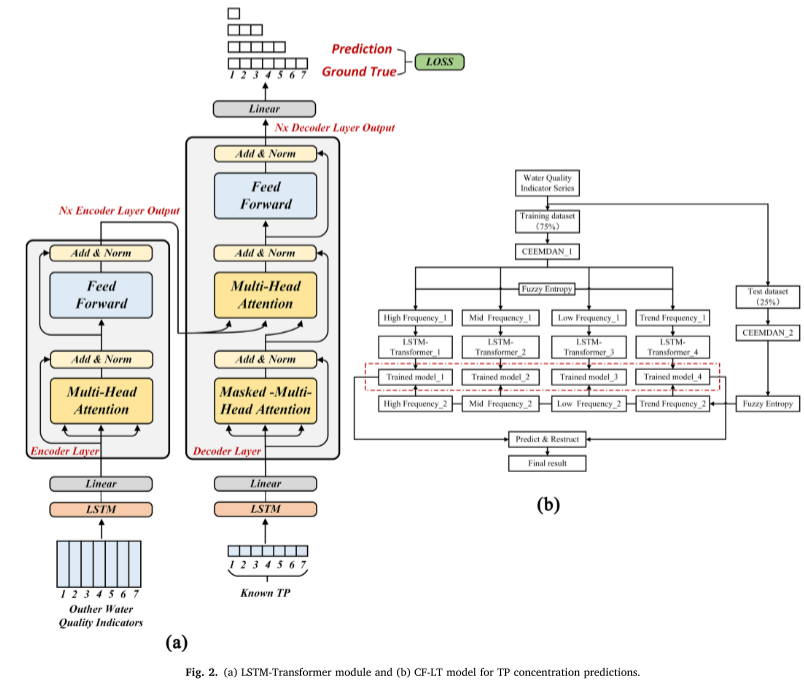
SHAP ist eine spieltheoretische Methode zur Interpretation der Ausgabe eines beliebigen ML-Modells.Um die Auswirkung von Eingabemerkmalen auf die Modellausgabe zu bestimmen, werden die Eingabemerkmale verwendet z = [ z 1 , . . . , zp ] z = [z1, ..., zp]z=[z1,...,zP]Bezogen auf das trainierte Deep-Learning-Modell F.
F = f ( z ) = ϕ 0 + ∑ i = 1 M ϕ izi (12) F=f(z)=phi_0+sum_{i=1}^M phi_iz_i tag{12}F=F(z)=ϕ0+ichchchchchchchchchchchchchchchchchch=1∑Mϕichchchchchchchchchchchchchchchchchchzichchchchchchchchchchchchchchchchchch(12)
φ ich ∈ R φ_i ∈ Rφichchchchchchchchchchchchchchchchchch∈RGibt den Beitrag jedes Features zum Modell an, der durch die folgende Formel angegeben wird:
ϕ i ( F , x ) = ∑ z ≤ x ∣ z ∣ ! ( M − ∣ z ∣ − 1 ) ! M ! [ F ( z ) − F ( z / i ) ] (13) phi_i(F,x)=sum_{zleq x}frac{|z|!(M-|z|-1)!}{M!}[F(z)-F(z/i)] tag{13}ϕichchchchchchchchchchchchchchchchchch(F,X)=z≤X∑M!∣z∣!(M−∣z∣−1)
Die Studie schlägt ein neues Modell zur Vorhersage der Gesamtphosphorkonzentrationen vor. Das Modell kombiniert CEEM DAN-, FE-, LSTM- und Transformer-Technologien und verwendet SHAP zur Interpretation der Modellausgabe. Das Hauptziel dieser Studie besteht darin, die Leistung des vorgeschlagenen CEEMDAN-FE-LSTM-Transformer (CF-LT)-Modells bei der Vorhersage der TP-Konzentration am Eingang zum Lake Tai zu bewerten und SHAP zur Interpretation der Ausgabe des CF-LT anzuwenden Modell. Dies sollte die Schlüsselfaktoren aufdecken, die die TP-Konzentration in der Region beeinflussen, und ihre Reaktionsmechanismen.
Die hochdimensionale Datenzerlegung kann eine große Anzahl modaler Komponenten erzeugen. Um dieses Problem zu lösen, kann Fuzzy Entropy (FE), eine effiziente Methode zur Berechnung der Zeitkomplexität, mit CEEMDAN kombiniert werden. Diese Kombination rekonstruiert effektiv die CEEMDAN-zerlegten Teilsignale und reduziert dadurch die Anzahl der Teilfrequenzmodelle.
LSTMTransformer-Modelle können Beziehungen zwischen nicht benachbarten Zeitpunkten erfassen und gleichzeitig die Zeitreiheneigenschaften der Eingabedaten beibehalten.
Transformer-Modelle nutzen Aufmerksamkeitsmechanismen, um während des Trainings Korrelationen zwischen zwei Standorten in einem bestimmten Kontext zu identifizieren. Dies ermöglicht eine effiziente Erfassung relevanter Daten und reduziert Informationsredundanz.
Die Hauptbeiträge dieses Artikels liegen in vier Aspekten:
Datensatz : Das Taihu-Seebecken liegt im Unterlauf des Jangtsekiang und erstreckt sich über eine Fläche von 36.900 Quadratkilometern, mit einem dichten Flussnetz und zahlreichen Seen. Der Taihu-See ist ein typischer flacher See. Das Becken weist die Merkmale eines feuchten nördlichen subtropischen Klimas mit einer durchschnittlichen Jahrestemperatur von 15–17 °C und einem durchschnittlichen Jahresniederschlag von 1181 mm auf. In dieser Studie wurden Daten zur Wasserqualitätsüberwachung der Stationen Yaoxiangqiao, Zhihugang und Guanduqiao verwendet (Abbildung S2). Diese Überwachungsstationen befinden sich in Taihukou, einem landesweit wichtigen Abschnitt zur Bewertung der Wasserqualität. Die Daten stammen vom Umweltüberwachungszentrum der Provinz Jiangsu.
Evaluationskriterien : Die Leistungsbewertung des Modells verwendet mehrere Schlüsselindikatoren: Bestimmtheitsmaß (R²), mittlerer quadratischer Fehler (MSE) und mittlerer absoluter prozentualer Fehler (MAPE). R² misst den Grad der Übereinstimmung zwischen dem vorhergesagten Wert des Modells und dem tatsächlichen Wert. Nahezu 1 zeigt an, dass das Modell über eine starke Vorhersagefähigkeit verfügt. Je kleiner der Wert, desto kleiner der Vorhersagefehler. MAPE spiegelt die Größe des Vorhersagefehlers aus prozentualer Sicht wider. Der Wert „Niedriger“ bedeutet genauere Vorhersagen.
Implementierungsdetails : Der experimentelle Prozess umfasst Datenvorverarbeitung, Modelltraining und Tests. Es wird ein vollständiges experimentelles Verfahren entwickelt, um die Leistung des vorgeschlagenen Modells anhand verschiedener Datensätze und Vorhersagezeitfenster zu bewerten. Zunächst werden die Daten mit der CEEMDAN-FE-Methode vorverarbeitet, die Informationsinterferenzen durch Hinzufügen einer vollständig integrierten empirischen Modenzerlegung mit adaptivem Rauschen beseitigt, Multiskaleninformationen extrahiert und Fuzzy-Entropie verwendet, um die Anzahl der Untersignale zu reduzieren. Anschließend werden die verarbeiteten Daten im Verhältnis 75 % und 25 % in Trainingssatz und Testsatz aufgeteilt. In der Trainingsphase wird der vorverarbeitete Trainingsdatensatz in das LSTM-Transformer-Modell eingegeben. Verwenden Sie Backpropagation und den Adam-Optimierer, um die Modellgewichte zu aktualisieren, und verwenden Sie die Rastersuche, um die besten Hyperparameter des LSTMTransformer-Moduls zu identifizieren, um sicherzustellen, dass die Leistung des Modells unter verschiedenen Vorhersagezeitfenstern (7 Tage, 5 Tage, 3 Tage, 1 Tag) optimal ist.
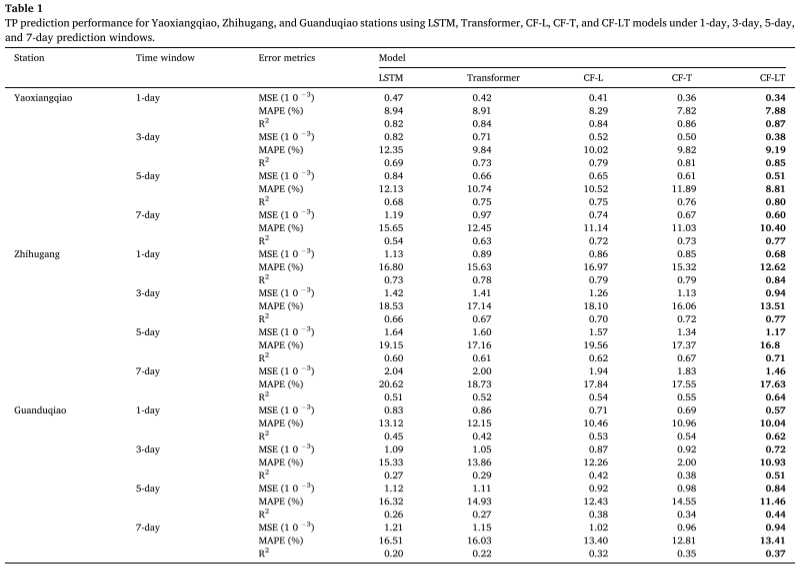
Experimentelle Ergebnisse : Unter Anwendung des besten Trainingsmodells auf den Testdatensatz fasst die Tabelle die TP-Konzentrationsvorhersagen zusammen, die von den Modellen CF-LT, LSTM, Transformer, CF-L und CF-T an verschiedenen Standorten und in verschiedenen Vorhersagezeitfenstern gegeben wurden. Das vorgeschlagene CF-LT-Modell liefert die besten Ergebnisse für alle drei Bewertungsmetriken. In Bezug auf R2 liegt das CF-LT-Modell im Bereich von 0,37 bis 0,87, während die nächstbesten CF-L- und CF-T-Modelle bei 0,32–0,84 bzw. 0,35–0,86 liegen. Dies zeigt, dass die Kombination des Langzeitgedächtnisses von LSTM mit dem Aufmerksamkeitsmechanismus von Transformer die Vorhersagegenauigkeit verbessern kann. Beim Vergleich der schlechtesten LSTM- und Transformer-Modelle mit den CF-L- und CF-T-Modellen liegt der MAPE zwischen 8,94 % und 20,62 % (LSTM) und 8,91 % bis 18,73 % (Transformer) und 8,29 % bis 19,56 % (CF-L). und 7,82 %–17,55 % (CF-T). Diese Ergebnisse zeigen, dass Datenzerlegung und Frequenzteilungsmodellierung die Vorhersagegenauigkeit erheblich verbessern, indem mehr in den Originaldaten verborgene Informationen erfasst werden.
Vorhersage von Faktoren, die die Gesamtphosphor-TP-Konzentration beeinflussen:
Der durchschnittliche absolute SHAP-Wert (MASV) wird verwendet, um den Beitrag von Eingabemerkmalen (WT, PH, DO, COD, EC, TU, TN, NH3-N, TP) zu den TP-Vorhersageergebnissen zu quantifizieren Je größer die Auswirkung auf die Modellvorhersageergebnisse. Untersuchungen zeigen, dass neben der vergangenen TP-Konzentrationsreihe selbst der Gesamtstickstoff (TN) und die Trübung (TU) die beiden Hauptfaktoren sind, die die TP-Vorhersage beeinflussen. Dies zeigt, dass Änderungen der TP nicht nur direkt von historischen Konzentrationen beeinflusst werden, sondern auch eng mit der Dynamik des Algenwachstums verbunden sind, die mit Schadstoffemissionen aus nicht punktuellen Quellen und dem Stickstoff-Phosphor-Verhältnis im Wasserkörper verbunden ist. Insbesondere die signifikante Korrelation zwischen TN und TP unterstreicht den Kopplungseffekt der beiden im Nährstoffkreislauf des Sees und unterstreicht die Bedeutung des Stickstoffeintrags aus nicht punktuellen Quellen für die Vorhersage der Phosphorkonzentration.
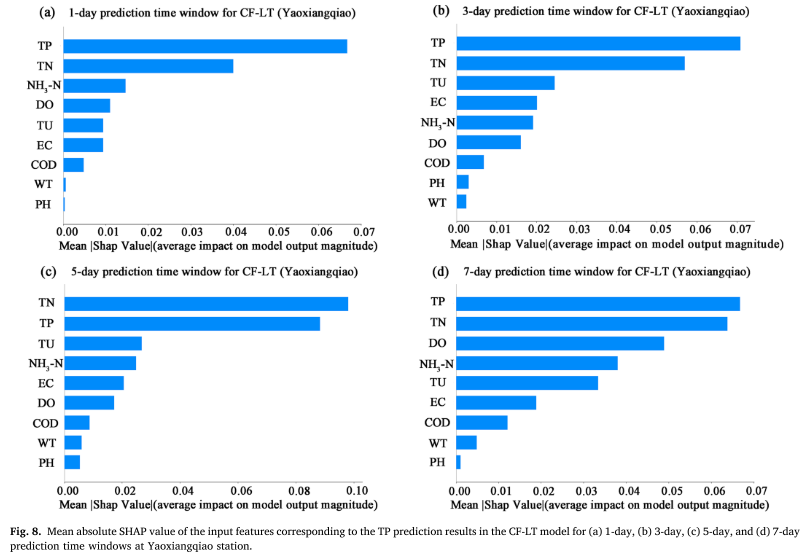
Aus diesen Ergebnissen lassen sich folgende Beobachtungen machen:
Vergleich mit kontradiktorischer Debiasierung und Regularisierung : Zufällige Aufteilung von 50 %/25 %/25 % für Trainings-, Validierungs- und Testdatensätze. Abbildung 2 zeigt die Pareto-Optimumkurven für alle Methoden, wobei der untere rechte Eckpunkt die ideale Leistung darstellt (höchste Genauigkeit und geringste Vorhersageabweichung).
Das in diesem Artikel vorgeschlagene CF-LT-Hybridmodell kombiniert CEEM DAN-, FE-, LSTM- und Transformer-Module, um die TP-Konzentration im Oberflächenwasser vorherzusagen. Dieser hybride Ansatz behebt die durch hochdimensionale Daten verursachten Mängel der Modellüberanpassung und -unteranpassung sowie die Unfähigkeit, bei langfristigen Vorhersagen langfristige Abhängigkeiten zwischen Daten herzustellen. Darüber hinaus werden SHAP-Werte verwendet, um die Ausgabe des CF-LT-Modells zu interpretieren.
Das Modell verwendet Daten von drei Wasserqualitätsüberwachungsstationen im Taihu-Seebecken, um 9 Wasserqualitätsindikatoren in verschiedenen Vorhersagezeitfenstern auszugeben. Als Steuerungsmodelle werden LSTM-, Transformer-, CF-L- und CF-T-Algorithmen verwendet. Das CF-LT-Modell hat einen R2-Wert von 0,37–0,87, einen MSE-Wert von 0,34 × 10–3–1,46 × 10–3 und einen MAPE-Wert von 7,88 %–17,63 % im Testdatensatz, was darauf hinweist, dass alle drei Die Indikatoren sind besser als die Ergebnisse von LSTM, Transformer, CF-L und CF-T. Das vorgeschlagene CF-LT-Modell lieferte auch die besten Spitzenvorhersageergebnisse. Basierend auf der SHAP-Interpretation haben wir herausgefunden, dass TU und TN (mit Ausnahme der frühen Zeitreihen der TP-Konzentration) wichtige Faktoren sind, die die TP-Vorhersage beeinflussen, was darauf hindeutet, dass Änderungen der TP nicht nur mit frühen TP-Konzentrationsniveaus zusammenhängen, sondern auch von TP beeinflusst werden Konzentration. Die Beziehung zwischen Schadstoffemissionen aus nicht-punktuellen Quellen und Wasserpflanzen in der Mündung des Taihu-Sees. Darüber hinaus ist anzumerken, dass TN und TU einen größeren Beitrag zur Vorhersage der TP-Konzentration in der Regenzeit leisten. Daher deuten die Ergebnisse dieser Studie darauf hin, dass das CF-LT-Modell zusätzliche Informationen zum Verständnis des Reaktionsmechanismus von TP bei sich ändernden Umgebungsbedingungen liefert.
CEEMDAN- und FE-Datenvorverarbeitung
def ceemdan_fe_preprocessing(data):
# CEEMDAN分解
imfs, residue = ceemdan(data, **ceemdan_params)
# 计算各个IMF的模糊熵
fe_values = []
for imf in imfs:
fe_values.append(fuzzy_entropy(imf)) # 假定fuzzy_entropy为计算模糊熵的函数
# 根据FE值重组IMFs
imfs_sorted = [imf for _, imf in sorted(zip(fe_values, imfs))]
imf_hf, imf_mf, imf_lf, imf_trend = imfs_sorted[:4], imfs_sorted[4:8], imfs_sorted[8:12], imfs_sorted[12:]
return np.concatenate((imf_hf, imf_mf, imf_lf, imf_trend), axis=1)
# 应用到数据上
preprocessed_data = ceemdan_fe_preprocessing(original_data)
LSTM und Transformator
def get_positional_encoding(max_len, d_model):
pe = np.zeros((max_len, d_model))
position = np.arange(0, max_len).reshape(-1, 1)
div_term = np.exp(np.arange(0, d_model, 2) * -(np.log(10000.0) / d_model))
pe[:, 0::2] = np.sin(position * div_term)
pe[:, 1::2] = np.cos(position * div_term)
return pe
def transformer_encoder(inputs, d_model, num_heads, ff_dim):
x = MultiHeadAttention(num_heads=num_heads, key_dim=d_model)(inputs, inputs)
x = LayerNormalization()(Add()([inputs, x]))
x = Dense(ff_dim, activation='relu')(x)
x = Dense(d_model)(x)
x = LayerNormalization()(Add()([inputs, x]))
return x
def transformer_decoder(inputs, encoder_outputs, d_model, num_heads, ff_dim):
return decoder_output
input_features = Input(shape=(input_shape))
lstm_out = LSTM(lstm_units)(input_features) # LSTM
pos_encodings = get_positional_encoding(max_seq_length, d_model)
transformer_in = Add()([lstm_out, pos_encodings])
transformer_encoded = transformer_encoder(transformer_in, d_model, num_heads, ff_dim)
decoder_output = transformer_decoder(decoder_input, transformer_encoded, d_model, num_heads, ff_dim)
output_layer = Dense(output_dim, activation='linear')(decoder_output)
model = Model(inputs=input_features, outputs=output_layer)
model.compile(optimizer=Adam(learning_rate), loss='mse')
Diese Studie entwickelte ein interpretierbares CEEMDAN-FE-LSTM-Transformer-Hybridmodell für die Vorhersage der gesamten Phosphorkonzentration in Oberflächengewässern. Das Modell verbesserte die Vorhersagegenauigkeit durch die Kombination fortschrittlicher Datenvorverarbeitungstechnologie und Deep-Learning-Modelle erheblich und liefert klare Funktionserklärungen über SHAP. Die experimentellen Ergebnisse bestätigten die Wirksamkeit des Modells, insbesondere die Identifizierung wichtiger Umweltfaktoren, und stellten ein leistungsstarkes Instrument für das Management der Eutrophierung von Gewässern und die Kontrolle der Umweltverschmutzung dar.
[1] Zeitschrift für Hydrologie Band 629, Februar 2024, 130609

Er widmet sich seit mehr als 30 Jahren der Technologieforschung und beherrscht verschiedene Sprachen wie Java, Linux, Javascript, PHP, CSS usw. Er hat viele Beiträge im Open-Source-Bereich geleistet Entwicklerdokumentationsstation, um einige Themen in der Technologieentwicklung als zukünftige Referenz zu teilen

