2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Cette semaine, j'ai lu un article intitulé Modèle hybride interprétable CEEMDAN-FE-LSTM-transformer pour prédire les concentrations de phosphore total dans les eaux de surface. Cet article propose un modèle hybride pour la prédiction de TP. Cet article propose un modèle hybride pour la prédiction de TP, à savoir le modèle CF-LT. Le modèle combine de manière innovante une décomposition en mode empirique (EMD) entièrement intégrée avec un traitement adaptatif du bruit, une analyse d'entropie floue, un réseau de mémoire à long terme (LSTM) et la technologie Transformer. En introduisant la technologie de reconstruction par division de fréquence des données, ce modèle résout efficacement les problèmes de surajustement et de sous-ajustement susceptibles de se produire lorsque les modèles d'apprentissage automatique traditionnels traitent des données de grande dimension. Dans le même temps, l'application du mécanisme d'attention permet au modèle CF-LT de surmonter les limites d'autres modèles qui sont difficiles à établir des dépendances à long terme entre les données lors de l'élaboration de prévisions à long terme. Les résultats de prédiction montrent que le modèle CF-LT a atteint un coefficient de détermination (R2) de 0,37 à 0,87 sur l'ensemble de données de test, ce qui représente une amélioration significative de 0,05 à 0,17 (soit 6 % à 85 %) par rapport au modèle témoin. modèle. De plus, le modèle CF-LT a également montré les meilleures performances de prévision des pics.
Le journal hebdomadaire de cette semaine décrypte l'article intitulé Modèle hybride interprétable CEEMDAN-FE-LSTM-transformateur pour la prédiction des concentrations totales de phosphore dans les eaux de surface. Cet article présente un modèle hybride, CF-LT, spécifiquement destiné à la prédiction du TP. Le modèle intègre de manière innovante la décomposition en mode empirique d'ensemble complet (EMD) avec le traitement adaptatif du bruit, l'analyse d'entropie floue, les réseaux de mémoire à long terme (LSTM) et la technologie du transformateur. En introduisant la division et la reconstruction de la fréquence des données, CF-LT aborde efficacement les problèmes de sur-ajustement et de sous-ajustement que les modèles d'apprentissage automatique traditionnels rencontrent souvent lorsqu'ils traitent des données de grande dimension. De plus, l'application du mécanisme d'attention permet à CF-LT de surmonter les limitations d'autres modèles dans l'établissement de dépendances à long terme entre les points de données lors des prévisions à long terme. Les résultats de prédiction démontrent que CF-LT atteint un coefficient de décision (R2) compris entre 0,37 et 0,87 sur les ensembles de données de test, ce qui représente une amélioration significative de 0,05 à 0,17 (ou 6 % à 85 %) par rapport aux modèles de contrôle. De plus, CF-LT offre les meilleures performances de prédiction de pointe.
Résumé : Modèle hybride interprétable CEEMDAN-FE-LSTM-transformateur pour la prévision des concentrations totales de phosphore dans les eaux de surface
Auteurs : Jiefu Yao, Shuai Chen, Xiaohong Ruan
libérer:Journal d'hydrologie Volume 629, février 2024, 130609
Article précédent : https://www.sciencedirect.com/science/article/pii/S0022169424000039?via%3Dihub
Cet article propose un modèle hybride pour la prédiction de TP. Ce modèle (CF-LT) combine une décomposition en mode empirique (EMD) entièrement intégrée avec un bruit adaptatif, une entropie floue, une mémoire longue à court terme et un transformateur.Reconstruction de la division de fréquence des donnéesL'introduction de résout efficacement les problèmes de surajustement et de sous-ajustement qui se produisaient lorsque les modèles d'apprentissage automatique précédents étaient confrontés à des données de grande dimension.mécanisme d'attention Cela résout le problème selon lequel ces modèles ne peuvent pas établir de dépendances à long terme entre les données et faire des prédictions à long terme. Les résultats de prédiction montrent que le modèle CF-LT atteint un coefficient de détermination (R2) de 0,37 à 0,87 sur l'ensemble de données de test, soit 0,05 à 0,17 (6 % à 85 %) supérieur à celui du modèle de contrôle. De plus, le modèle CF-LT a fourni la meilleure prévision des pics.
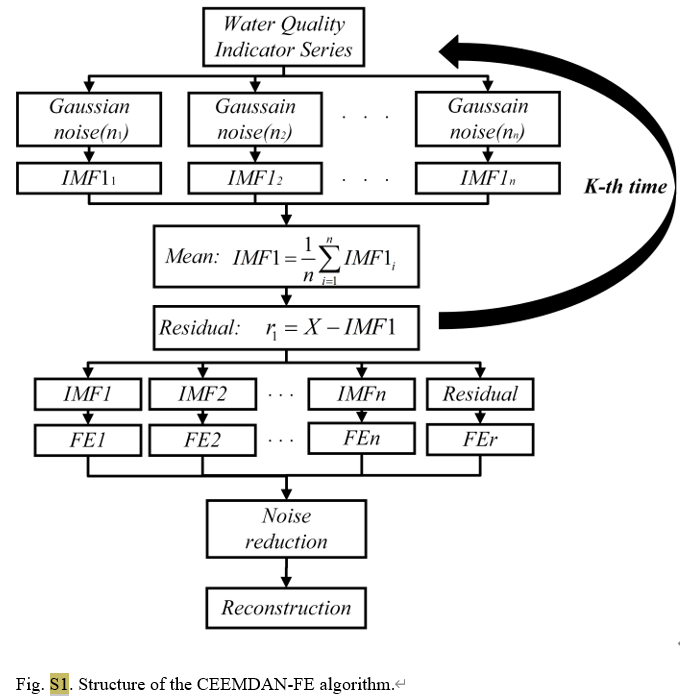
En tant que méthode avancée d'analyse de séries chronologiques, CEEMDAN réduit efficacement le problème d'alias de mode existant dans l'EMD traditionnel en ajoutant du bruit adaptatif au processus de décomposition de mode empirique (EMD). Il peut décomposer le signal d'origine en une série de fonctions de mode intrinsèque (IMF). Chaque IMF représente différentes caractéristiques d'échelle de temps du signal, rendant ainsi l'analyse de signaux complexes plus intuitive et précise. Dans cette étude, CEEMDAN a été utilisé pour traiter les données quotidiennes sur la qualité de l'eau provenant de trois stations de surveillance du lac Tai, en séparant la concentration de phosphore total et d'autres paramètres de qualité de l'eau tels que la température de l'eau, le pH, l'oxygène dissous, etc. en signaux dans différentes bandes de fréquences.
Algorithme S1 : Décomposition en mode empirique d'ensemble complet avec bruit adaptatif (CEEMDAN)
yi ( t ) = y ( t ) + ϵ 0 vi ( t ) i = 1 , 2 , … , n (S1) y^{i}(t)=y(t)+epsilon_0v^i(t)quad i=1,2,points,ntag{S1}etje(t)=et(t)+ϵ0vje(t)je=1,2,…,n(S1)
IMF1 i = E 0 ( yi ( t ) ) + r 1 i IMF1 ‾ = 1 n IMF1 i (S2) texte{IMF1}_i=E_0(y^i(t))+r^i_1quad overline{texte{IMF1}}=frac1ntexte{IMF1}_itag{S2}FMI1je=E0(etje(t))+l1jeFMI1=n1FMI1je(S2)
r 1 = yi ( t ) − IMF1 ‾ (S3) r_1=y^i(t)-overline{texte{IMF1}}balise{S3}l1=etje(t)−FMI1(S3)
FMI2 ‾ = 1 n ∑ i = 1 n E 1 ( r 1 + ϵ 1 E 1 ( vi ( t ) ) ) (S4) overline{texte{FMI2}}=frac1nsum^n_{i=1}E_1(r_1+epsilon_1E_1(v^i(t))) tag{S4}FMI2=n1je=1∑nE1(l1+ϵ1E1(vje(t)))(S4)
y ( t ) = ∑ l = 1 K − 1 IMF1 ‾ + r K (S5) y(t)=somme^{K-1}_{l=1}surligner{texte{IMF1}}+r_Ktag{S5}et(t)=l=1∑K−1FMI1+lK(S5)
Pour la partie CEEMDAN-FE, nous divisons d'abord l'ensemble de données d'origine en ensembles de données de formation et de test, puis appliquons CEEMDAN pour décomposer chaque fonctionnalité des deux ensembles de données en plusieurs fonctions de mode intrinsèque (IMF). En fonction de la proximité des valeurs FE de chaque IMF, elles sont reconstruites en composantes haute fréquence (IMFH), moyenne fréquence (IMFM), basse fréquence (IMFL) et termes de tendance (IMFT), qui reflètent différents aspects. du FMI.
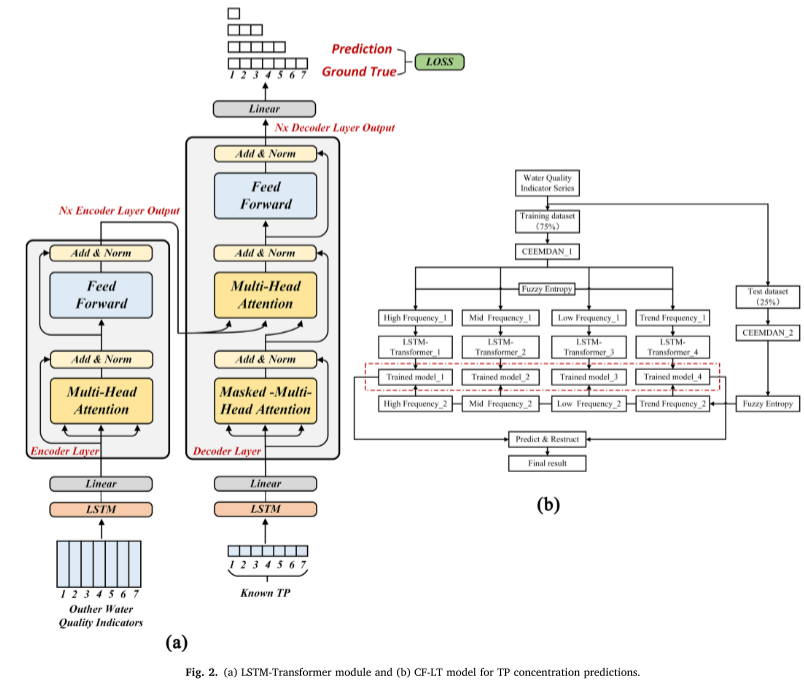
Pour la partie LSTM-Transformer, dans l'encodeur et le décodeur, la couche cachée de LSTM est remplacée par l'encodage de position du transformateur pour établir la dépendance temporelle entre les données d'entrée. Le processus de calcul spécifique est le suivant (Figure 2a).
SHAP est une méthode de théorie des jeux permettant d'interpréter la sortie de n'importe quel modèle ML.Pour déterminer l'impact des entités en entrée sur la sortie du modèle, les entités en entrée z = [ z 1 , . . . , zp ] z = [z1, ..., zp]j=[j1,...,jp]Lié au modèle d'apprentissage profond formé F.
F = f ( z ) = ϕ 0 + ∑ i = 1 M ϕ izi (12) F=f(z)=phi_0+somme_{i=1}^M phi_iz_i balise{12}F=F(j)=ϕ0+je=1∑Mϕjejje(12)
φ i ∈ R φ_i ∈ Rφje∈RIndique la contribution de chaque fonctionnalité au modèle, qui est donnée par la formule suivante :
ϕ i ( F , x ) = ∑ z ≤ x ∣ z ∣ ! ( M − ∣ z ∣ − 1 ) ! M ! [ F ( z ) − F ( z / i ) ] (13) phi_i(F,x)=sum_{zleq x}frac{|z|!(M-|z|-1)!}{M!}[F(z)-F(z/i)] balise{13}ϕje(F,X)=j≤X∑M!∣j∣!(M−∣j∣−1)
L'étude propose un nouveau modèle pour prédire les concentrations de phosphore total. Le modèle combine les technologies CEEM DAN, FE, LSTM et Transformer et utilise SHAP pour interpréter les résultats du modèle. L'objectif principal de cette étude est d'évaluer les performances du modèle CEEMDAN-FE-LSTM-Transformer (CF-LT) proposé pour prédire la concentration de TP à l'entrée du lac Tai et d'appliquer SHAP pour interpréter les résultats du CF-LT. modèle. Cela devrait révéler les facteurs clés affectant la concentration de TP dans la région et leurs mécanismes de réponse.
La décomposition de données en grande dimension peut produire un grand nombre de composants modaux. Pour résoudre ce problème, Fuzzy Entropy (FE), une méthode efficace de calcul de la complexité temporelle, peut être combinée avec CEEMDAN. Cette combinaison reconstruit efficacement les sous-signaux décomposés CEEMDAN, réduisant ainsi le nombre de modèles de sous-fréquence.
Les modèles LSTMTransformer peuvent capturer les relations entre des points temporels non adjacents tout en préservant les caractéristiques des séries chronologiques des données d'entrée.
Les modèles de transformateur utilisent des mécanismes d'attention pour identifier les corrélations entre deux emplacements dans un contexte spécifique pendant la formation. Cela permet une acquisition efficace des données pertinentes et réduit la redondance des informations.
Les principales contributions de cet article portent sur quatre aspects :
base de données : Le bassin du lac Taihu est situé dans le cours inférieur du fleuve Yangtze, couvrant une superficie de 36 900 kilomètres carrés, avec un réseau fluvial dense et de nombreux lacs. Le lac Taihu est un lac peu profond typique. Le bassin présente les caractéristiques d'un climat humide de la zone subtropicale nord, avec une température annuelle moyenne de 15-17°C et des précipitations annuelles moyennes de 1181 mm. Cette étude a utilisé les données de surveillance de la qualité de l'eau des stations Yaoxiangqiao, Zhihugang et Guanduqiao (Figure S2). Ces stations de surveillance sont situées à Taihukou, une section nationale clé d'évaluation de la qualité de l'eau. Les données proviennent du Centre provincial de surveillance de l'environnement du Jiangsu.
Critère d'évaluation : L'évaluation des performances du modèle utilise plusieurs indicateurs clés : coefficient de détermination (R²), erreur quadratique moyenne (MSE) et erreur absolue moyenne en pourcentage (MAPE). R² mesure le degré d'ajustement entre la valeur prédite du modèle et la valeur réelle. Près de 1 indique que le modèle a une forte capacité de prédiction ; MSE mesure la somme des carrés de l'erreur de prédiction. Plus la valeur est petite, plus l'erreur de prédiction est petite ; MAPE reflète la taille de l'erreur de prédiction sous forme de pourcentage. La valeur inférieure signifie des prédictions plus précises.
Détails d'implémentation : Le processus expérimental comprend le prétraitement des données, la formation du modèle et les tests. Une procédure expérimentale complète est établie pour évaluer les performances du modèle proposé sur différents ensembles de données et fenêtres temporelles de prédiction. Premièrement, les données sont prétraitées par la méthode CEEMDAN-FE, qui supprime les interférences d'informations en ajoutant une décomposition en mode empirique entièrement intégrée avec bruit adaptatif, extrait des informations multi-échelles et utilise l'entropie floue pour réduire le nombre de sous-signaux. Ensuite, les données traitées sont divisées en ensemble d'entraînement et ensemble de test dans des proportions de 75 % et 25 %. Dans la phase de formation, l'ensemble de données de formation prétraitées est entré dans le modèle LSTM-Transformer. Utilisez la rétropropagation et l'optimiseur Adam pour mettre à jour les poids du modèle, et utilisez la recherche par grille pour identifier les meilleurs hyperparamètres du module LSTMTransformer afin de garantir les performances du modèle sous différentes fenêtres temporelles de prédiction (7 jours, 5 jours, 3 jours, 1 jour) optimales.
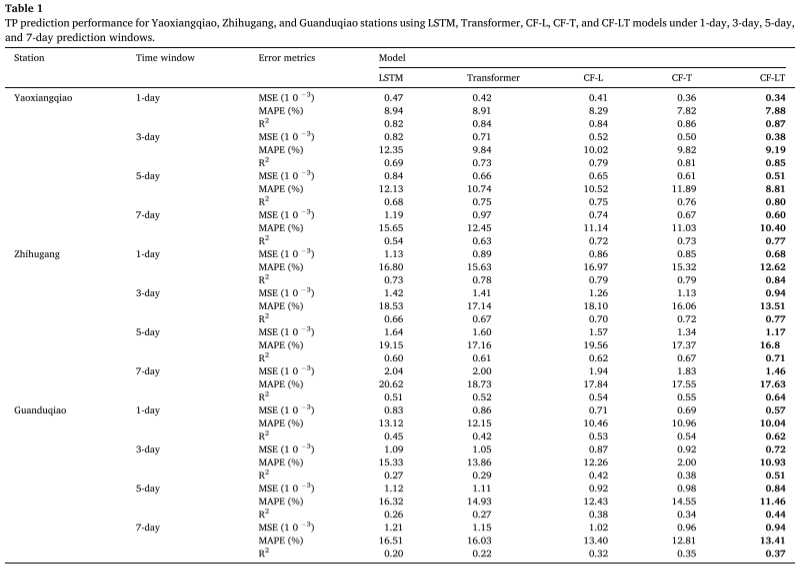
Résultats expérimentaux : En appliquant le meilleur modèle de formation à l'ensemble de données de test, le tableau résume les prévisions de concentration de TP données par les modèles CF-LT, LSTM, Transformer, CF-L et CF-T sur différents sites et différentes fenêtres temporelles de prédiction. Le modèle CF-LT proposé donne les meilleurs résultats pour les trois mesures d'évaluation. En termes de R2, le modèle CF-LT va de 0,37 à 0,87, tandis que les prochains meilleurs modèles CF-L et CF-T sont respectivement de 0,32 à 0,84 et de 0,35 à 0,86. Cela montre que la combinaison de la mémoire à long terme du LSTM avec le mécanisme d’attention de Transformer peut améliorer la précision des prédictions. En comparant les pires modèles LSTM et Transformer avec les modèles CF-L et CF-T, le MAPE varie de 8,94 % à 20,62 % (LSTM) et 8,91 % à 18,73 % (Transformer) à 8,29 % à 19,56 % (CF -L). et 7,82%-17,55% (CF-T). Ces résultats démontrent que la décomposition des données et la modélisation par division de fréquence améliorent considérablement la précision des prévisions en capturant davantage d'informations cachées dans les données originales.
Prédiction des facteurs affectant la concentration totale de phosphore TP:
La valeur SHAP absolue moyenne (MASV) est utilisée pour quantifier la contribution des caractéristiques d'entrée (WT, PH, DO, COD, EC, TU, TN, NH3-N, TP) aux résultats de prédiction TP. plus l'impact sur les résultats de prédiction du modèle est grand. La recherche montre qu'en plus des séries passées de concentrations de TP elles-mêmes, l'azote total (TN) et la turbidité (TU) sont les deux principaux facteurs affectant la prévision du TP. Cela montre que les changements de TP sont non seulement directement affectés par les concentrations historiques, mais sont également étroitement liés à la dynamique de croissance des algues associée aux émissions de pollution diffuse et au rapport azote-phosphore dans le plan d'eau. En particulier, la corrélation significative entre TN et TP souligne l'effet de couplage des deux dans le cycle des éléments nutritifs du lac et met en évidence l'importance de l'apport d'azote de source diffuse pour la prévision de la concentration de phosphore.
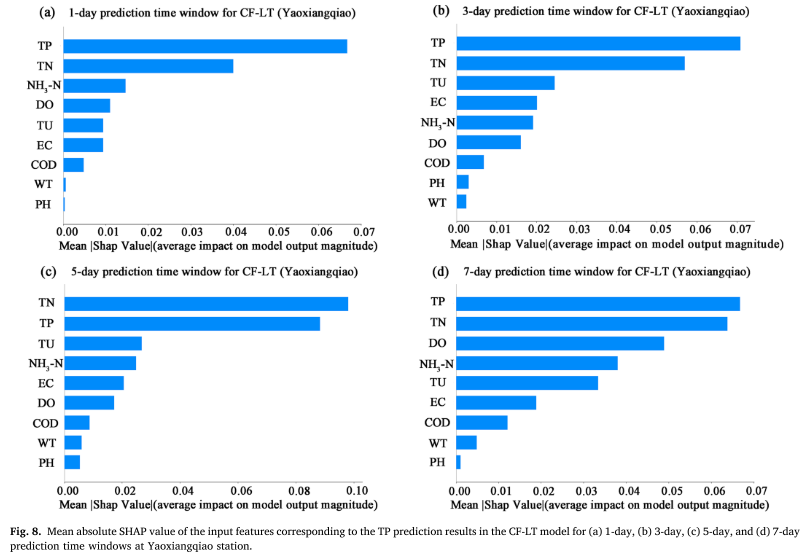
De ces résultats, les observations suivantes peuvent être faites :
Comparaison avec le débiaisme contradictoire et la régularisation : Répartition aléatoire 50 %/25 %/25 % pour les ensembles de données de formation, de validation et de test. La figure 2 montre les courbes optimales de Pareto pour toutes les méthodes, où le point du coin inférieur droit représente la performance idéale (précision la plus élevée et écart de prédiction le plus faible).
Le modèle hybride CF-LT proposé dans cet article combine les modules CEEM DAN, FE, LSTM et Transformer pour prédire la concentration de TP dans les eaux de surface. Cette approche hybride résout les défauts du surajustement et du sous-ajustement du modèle causés par des données de grande dimension et l'incapacité d'établir des dépendances à long terme entre les données lors de l'élaboration de prévisions à long terme. De plus, les valeurs SHAP sont utilisées pour interpréter les résultats du modèle CF-LT.
Le modèle utilise les données de trois stations de surveillance de la qualité de l'eau dans le bassin du lac Taihu pour produire 9 indicateurs de qualité de l'eau dans différentes fenêtres temporelles de prévision. Les algorithmes LSTM, Transformer, CF-L et CF-T sont utilisés comme modèles de contrôle. Le modèle CF-LT a une valeur R2 de 0,37 à 0,87, une valeur MSE de 0,34 × 10−3 à 1,46 × 10−3 et une valeur MAPE de 7,88 % à 17,63 % sur l'ensemble de données de test, ce qui indique que les trois les indicateurs sont meilleurs que les résultats du LSTM, Transformer, CF-L et CF-T. Le modèle CF-LT proposé a également produit les meilleurs résultats de prévision des pics. Sur la base de l'interprétation SHAP, nous avons constaté que TU et TN (à l'exclusion des premières séries chronologiques de concentration de TP) sont des facteurs importants affectant la prédiction de TP, ce qui indique que les changements de TP ne sont pas seulement liés aux premiers niveaux de concentration de TP, mais également affectés par la TP. concentration. La relation entre les émissions de pollution diffuses et les plantes aquatiques dans l'estuaire du lac Taihu. De plus, il convient de noter que TN et TU contribuent davantage à la prévision de la concentration de TP pendant la saison des pluies. Par conséquent, les résultats de cette étude indiquent que le modèle CF-LT fournit des informations supplémentaires pour comprendre le mécanisme de réponse du TP lorsque différentes conditions environnementales changent.
Prétraitement des données CEEMDAN et FE
def ceemdan_fe_preprocessing(data):
# CEEMDAN分解
imfs, residue = ceemdan(data, **ceemdan_params)
# 计算各个IMF的模糊熵
fe_values = []
for imf in imfs:
fe_values.append(fuzzy_entropy(imf)) # 假定fuzzy_entropy为计算模糊熵的函数
# 根据FE值重组IMFs
imfs_sorted = [imf for _, imf in sorted(zip(fe_values, imfs))]
imf_hf, imf_mf, imf_lf, imf_trend = imfs_sorted[:4], imfs_sorted[4:8], imfs_sorted[8:12], imfs_sorted[12:]
return np.concatenate((imf_hf, imf_mf, imf_lf, imf_trend), axis=1)
# 应用到数据上
preprocessed_data = ceemdan_fe_preprocessing(original_data)
LSTM et transformateur
def get_positional_encoding(max_len, d_model):
pe = np.zeros((max_len, d_model))
position = np.arange(0, max_len).reshape(-1, 1)
div_term = np.exp(np.arange(0, d_model, 2) * -(np.log(10000.0) / d_model))
pe[:, 0::2] = np.sin(position * div_term)
pe[:, 1::2] = np.cos(position * div_term)
return pe
def transformer_encoder(inputs, d_model, num_heads, ff_dim):
x = MultiHeadAttention(num_heads=num_heads, key_dim=d_model)(inputs, inputs)
x = LayerNormalization()(Add()([inputs, x]))
x = Dense(ff_dim, activation='relu')(x)
x = Dense(d_model)(x)
x = LayerNormalization()(Add()([inputs, x]))
return x
def transformer_decoder(inputs, encoder_outputs, d_model, num_heads, ff_dim):
return decoder_output
input_features = Input(shape=(input_shape))
lstm_out = LSTM(lstm_units)(input_features) # LSTM
pos_encodings = get_positional_encoding(max_seq_length, d_model)
transformer_in = Add()([lstm_out, pos_encodings])
transformer_encoded = transformer_encoder(transformer_in, d_model, num_heads, ff_dim)
decoder_output = transformer_decoder(decoder_input, transformer_encoded, d_model, num_heads, ff_dim)
output_layer = Dense(output_dim, activation='linear')(decoder_output)
model = Model(inputs=input_features, outputs=output_layer)
model.compile(optimizer=Adam(learning_rate), loss='mse')
Cette étude a développé un modèle hybride interprétable CEEMDAN-FE-LSTM-Transformer pour la prédiction de la concentration totale de phosphore dans les eaux de surface. Le modèle a considérablement amélioré la précision de la prévision grâce à la fusion d'une technologie avancée de prétraitement des données et de modèles d'apprentissage en profondeur, et fournit une explication claire des fonctionnalités. via SHAP. Les résultats expérimentaux ont confirmé l'efficacité du modèle, en particulier l'identification des facteurs environnementaux clés, fournissant un outil puissant pour la gestion de l'eutrophisation des masses d'eau et le contrôle de la pollution.
[1] Journal d'hydrologie Volume 629, février 2024, 130609

Il se consacre à la recherche technologique depuis plus de 30 ans et maîtrise divers langages tels que java, linux, javascript, php, css, etc. Il a apporté de nombreuses contributions dans le domaine de l'open source. station de documentation pour les développeurs pour partager certains problèmes de développement technologique pour référence future.

