
informasi kontak saya
Surat[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Minggu ini saya membaca makalah berjudul Model hibrida transformator CEEMDAN-FE-LSTM yang dapat ditafsirkan untuk memprediksi konsentrasi total fosfor dalam air permukaan. Makalah ini mengusulkan model hybrid untuk prediksi TP. Makalah ini mengusulkan model hybrid untuk prediksi TP, yaitu model CF-LT. Model ini secara inovatif menggabungkan dekomposisi mode empiris (EMD) terintegrasi penuh dengan pemrosesan kebisingan adaptif, analisis entropi fuzzy, jaringan memori jangka pendek (LSTM) dan teknologi Transformer. Dengan memperkenalkan teknologi rekonstruksi pembagian frekuensi data, model ini secara efektif memecahkan masalah over-fitting dan under-fitting yang cenderung terjadi ketika model pembelajaran mesin tradisional menangani data berdimensi tinggi. Pada saat yang sama, penerapan mekanisme perhatian memungkinkan model CF-LT mengatasi keterbatasan model lain yang sulit membangun ketergantungan jangka panjang antar data saat membuat prediksi jangka panjang. Hasil prediksi menunjukkan bahwa model CF-LT mencapai koefisien determinasi (R2) sebesar 0,37 hingga 0,87 pada kumpulan data pengujian, yang merupakan peningkatan signifikan sebesar 0,05 hingga 0,17 (yaitu 6% hingga 85%) dibandingkan dengan kontrol. model. Selain itu, model CF-LT juga menunjukkan performa prediksi puncak terbaik.
Koran mingguan minggu ini menguraikan makalah berjudul Model hibrida transformator CEEMDAN-FE-LSTM yang dapat ditafsirkan untuk memprediksi konsentrasi fosfor total dalam air permukaan. Makalah ini memperkenalkan model hibrida, CF-LT, khususnya untuk prediksi TP. Model ini secara inovatif mengintegrasikan Complete Ensemble Empirical Mode Decomposition (EMD) dengan pemrosesan derau adaptif, analisis entropi fuzzy, jaringan Long Short-Term Memory (LSTM), dan teknologi Transformer. Dengan memperkenalkan pembagian dan rekonstruksi frekuensi data, CF-LT secara efektif mengatasi masalah overfitting dan underfitting yang sering ditemui model pembelajaran mesin tradisional saat menangani data berdimensi tinggi. Selain itu, penerapan mekanisme perhatian memungkinkan CF-LT untuk mengatasi keterbatasan model lain dalam membangun ketergantungan jangka panjang antara titik data selama prediksi jangka panjang. Hasil prediksi menunjukkan bahwa CF-LT mencapai koefisien keputusan (R2) berkisar antara 0,37 hingga 0,87 pada kumpulan data uji, yang menunjukkan peningkatan signifikan sebesar 0,05 hingga 0,17 (atau 6% hingga 85%) dibandingkan dengan model kontrol. Lebih jauh, CF-LT memberikan kinerja prediksi puncak terbaik.
Subjek: Model hibrida transformator CEEMDAN-FE-LSTM yang dapat diinterpretasikan untuk memprediksi konsentrasi total fosfor dalam air permukaan
Penulis: Jiefu Yao, Shuai Chen, Xiaohong Ruan
melepaskan:Jurnal Hidrologi Jilid 629Februari 2024, 130609
Sumber: https://www.sciencedirect.com/science/article/pii/S0022169424000039?via%3Dihub
Makalah ini mengusulkan model hybrid untuk prediksi TP. Model ini (CF-LT) menggabungkan Dekomposisi Mode Empiris (EMD) yang terintegrasi penuh dengan noise adaptif, entropi fuzzy, memori jangka pendek, dan Transformer.Rekonstruksi pembagian frekuensi dataPengenalan secara efektif memecahkan masalah over-fitting dan under-fitting yang terjadi ketika model pembelajaran mesin sebelumnya menghadapi data berdimensi tinggi.mekanisme perhatian Hal ini mengatasi masalah dimana model ini tidak dapat membangun ketergantungan jangka panjang antar data dan membuat prediksi jangka panjang. Hasil prediksi menunjukkan bahwa model CF-LT memperoleh koefisien determinasi (R2) sebesar 0,37-0,87 pada kumpulan data uji, yaitu 0,05-0,17 (6%-85%) lebih tinggi dibandingkan model kontrol. Selain itu, model CF-LT memberikan prediksi puncak terbaik.
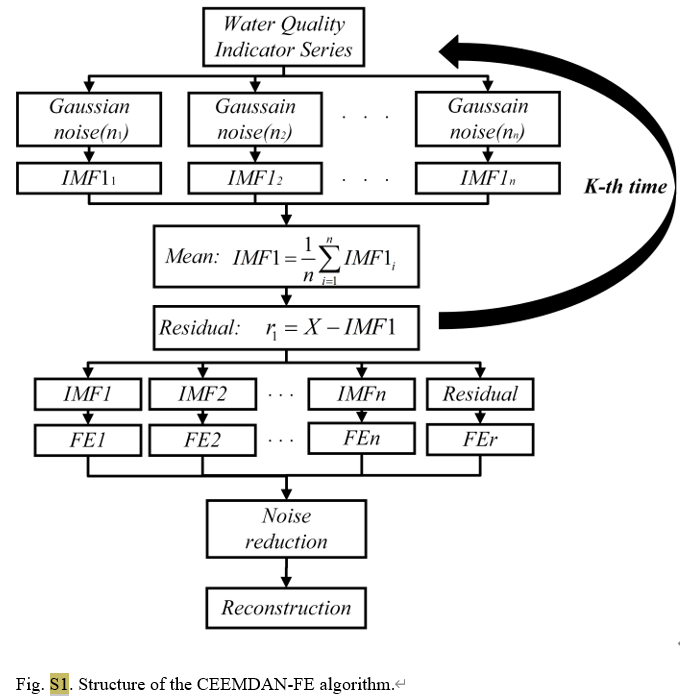
Sebagai metode analisis deret waktu tingkat lanjut, CEEMDAN secara efektif mengurangi masalah mode aliasing yang ada pada EMD tradisional dengan menambahkan noise adaptif ke proses dekomposisi mode empiris (EMD). Ini dapat menguraikan sinyal asli menjadi serangkaian fungsi mode intrinsik (IMF). Setiap IMF mewakili karakteristik skala waktu sinyal yang berbeda, sehingga membuat analisis sinyal kompleks menjadi lebih intuitif dan akurat. Dalam studi ini, CEEMDAN digunakan untuk mengolah data kualitas air harian dari tiga stasiun pemantauan di Danau Tai, memisahkan konsentrasi total fosfor dan parameter kualitas air lainnya seperti suhu air, pH, oksigen terlarut, dll. menjadi sinyal dalam pita frekuensi yang berbeda.
Algoritma S1: Dekomposisi Modus Empiris Ensemble Lengkap dengan Adaptive Noise (CEEMDAN)
yi ( t ) = y ( t ) + ϵ 0 vi ( t ) i = 1 , 2 , … , n (S1) y^{i}(t)=y(t)+epsilon_0v^i(t)quad i=1,2,titik,ntag{S1}kamuSaya(T)=kamu(T)+ϵ0kitaSaya(T)Saya=1,2,…,N(S1)
Bahasa Indonesia: IMF1 i = E 0 ( yi ( t ) ) + r 1 i IMF1 ‾ = 1 n IMF1 i (S2) teks{IMF1}_i=E_0(y^i(t))+r^i_1quad overline{teks{IMF1}}=frac1nteks{IMF1}_itag{S2}IMF1Saya=Bahasa Inggris0(kamuSaya(T))+R1SayaIMF1=N1IMF1Saya(S2)
r 1 = yi ( t ) − IMF1 ‾ (S3) r_1=y^i(t)-garis atas{teks{IMF1}}tag{S3}R1=kamuSaya(T)−IMF1(S3)
IMF2 ‾ = 1 n ∑ i = 1 n E 1 ( r 1 + ϵ 1 E 1 ( vi ( t ) ) ) (S4) overline{teks{IMF2}}=frac1njumlah^n_{i=1}E_1(r_1+epsilon_1E_1(v^i(t))) tag{S4}Dana Moneter Internasional (IMF)2=N1Saya=1∑NBahasa Inggris1(R1+ϵ1Bahasa Inggris1(kitaSaya(T)))(Ukuran S4)
y ( t ) = ∑ l = 1 K − 1 IMF1 ‾ + r K (S5) y(t)=jumlah^{K-1}_{l=1}garis atas{teks{IMF1}}+r_Ktag{S5}kamu(T)=aku=1∑Bahasa Inggris: Bahasa Inggris: Bahasa Inggris: K−1IMF1+RBahasa Inggris: Bahasa Inggris: Bahasa Inggris: K(S5)
Untuk bagian CEEMDAN-FE, pertama-tama kami membagi kumpulan data asli menjadi kumpulan data pelatihan dan pengujian, lalu menerapkan CEEMDAN untuk menguraikan setiap fitur dalam dua kumpulan data menjadi beberapa fungsi mode intrinsik (IMF). Berdasarkan kedekatan nilai FE masing-masing IMF, mereka direkonstruksi menjadi komponen frekuensi tinggi (IMFH), frekuensi menengah (IMFM), frekuensi rendah (IMFL) dan istilah tren (IMFT), yang mencerminkan aspek yang berbeda. dari IMF.
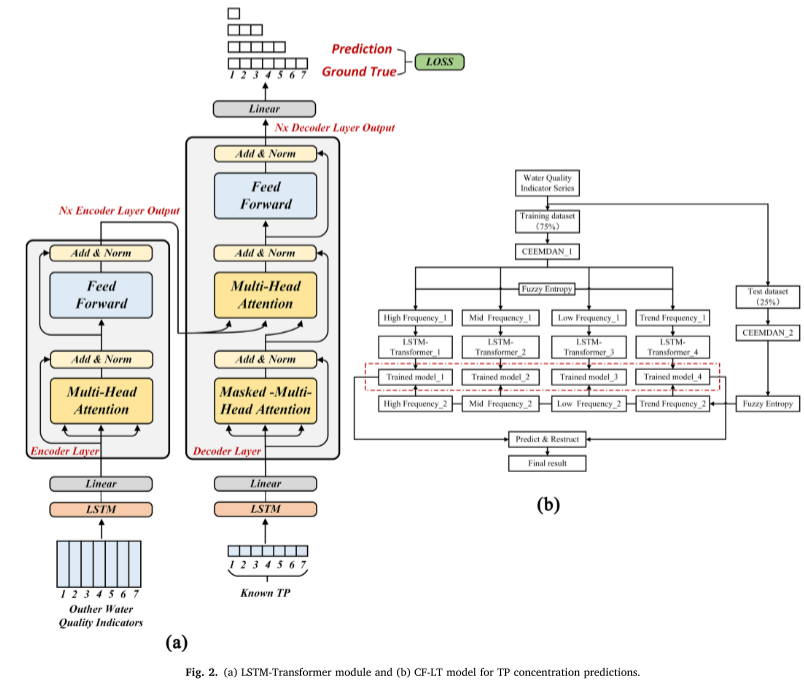
Untuk bagian LSTM-Transformer, pada encoder dan decoder, lapisan tersembunyi LSTM diganti dengan pengkodean posisi Transformer untuk membentuk ketergantungan temporal antara data masukan. Proses perhitungan spesifiknya adalah sebagai berikut (Gambar 2a).
SHAP adalah metode teori permainan untuk menafsirkan keluaran model ML apa pun.Untuk menentukan dampak fitur masukan pada keluaran model, fitur masukan Bahasa Indonesia: z = [ z 1 , . . . Bahasa Indonesia: , zp ] z = [z1, ..., zp]dari=[dari1,...,dariP]Terkait dengan model pembelajaran mendalam yang dilatih F.
F = f ( z ) = ϕ 0 + ∑ i = 1 M ϕ izi (12) F=f(z)=phi_0+jumlah_{i=1}^M phi_iz_i tag{12}F=F(dari)=ϕ0+Saya=1∑MϕSayadariSaya(12)
φi ∈ R φ_i ∈ RφSaya∈RMenunjukkan kontribusi setiap fitur pada model, yang diberikan dengan rumus berikut:
Bahasa Indonesia: ϕ i ( F , x ) = ∑ z ≤ x ∣ z ∣ ! ( M − ∣ z ∣ − 1 ) ! M ! [ F ( z ) − F ( z / i ) ] (13) phi_i(F,x)=jumlah_{zleq x}frac{|z|!(M-|z|-1)!}{M!}[F(z)-F(z/i)] tag{13}ϕSaya(F,X)=dari≤X∑M!∣dari∣!(M−∣dari∣−1)
Studi ini mengusulkan model baru untuk memprediksi konsentrasi total fosfor. Model ini menggabungkan teknologi CEEM DAN, FE, LSTM dan Transformer dan menggunakan SHAP untuk menafsirkan keluaran model. Tujuan utama dari penelitian ini adalah untuk mengevaluasi kinerja model CEEMDAN-FE-LSTM-Transformer (CF-LT) yang diusulkan dalam memprediksi konsentrasi TP di pintu masuk Danau Tai dan menerapkan SHAP untuk menginterpretasikan keluaran CF-LT model. Hal ini harus mengungkap faktor-faktor kunci yang mempengaruhi konsentrasi TP di wilayah tersebut dan mekanisme responsnya.
Dekomposisi data berdimensi tinggi dapat menghasilkan komponen modal dalam jumlah besar. Untuk mengatasi masalah ini, Fuzzy Entropy (FE), sebuah metode yang efisien untuk menghitung kompleksitas waktu, dapat dikombinasikan dengan CEEMDAN. Kombinasi ini secara efektif merekonstruksi sub-sinyal CEEMDAN yang terdekomposisi, sehingga mengurangi jumlah model sub-frekuensi.
Model LSTMTransformer dapat menangkap hubungan antara titik waktu yang tidak berdekatan sambil mempertahankan karakteristik deret waktu dari data masukan.
Model transformator menggunakan mekanisme perhatian untuk mengidentifikasi korelasi antara dua lokasi dalam konteks tertentu selama pelatihan. Hal ini memungkinkan perolehan data yang relevan secara efisien dan mengurangi redundansi informasi.
Kontribusi utama artikel ini ada pada empat aspek:
Himpunan data : Cekungan Danau Taihu terletak di hilir Sungai Yangtze, seluas 36.900 kilometer persegi, dengan jaringan sungai yang padat dan banyak danau. Danau Taihu adalah danau dangkal yang khas. Cekungan ini mempunyai ciri-ciri iklim lembab di zona subtropis utara, dengan suhu rata-rata tahunan 15-17°C dan curah hujan tahunan rata-rata 1181 mm. Penelitian ini menggunakan data pemantauan kualitas air dari Stasiun Yaoxiangqiao, Stasiun Zhihugang, dan Stasiun Guanduqiao (Gambar S2). Stasiun pemantauan ini berlokasi di Taihukou, bagian penilaian kualitas air utama nasional. Data tersebut berasal dari Pusat Pemantauan Lingkungan Provinsi Jiangsu.
Kriteria evaluasi : Evaluasi kinerja model menggunakan beberapa indikator utama: koefisien determinasi (R²), mean square error (MSE), dan mean absolute persentase error (MAPE). R² mengukur tingkat kesesuaian antara nilai prediksi model dan nilai sebenarnya.Mendekati 1 menunjukkan bahwa model memiliki kemampuan prediksi yang kuat; MSE mengukur jumlah kuadrat kesalahan prediksi. MAPE mencerminkan besarnya kesalahan prediksi dari perspektif persentase. Nilai yang lebih rendah berarti prediksi yang lebih akurat.
Detail implementasi : Proses eksperimen meliputi prapemrosesan data, pelatihan model, dan pengujian. Prosedur eksperimental lengkap dibuat untuk mengevaluasi kinerja model yang diusulkan pada kumpulan data dan jangka waktu prediksi yang berbeda. Pertama, data diproses terlebih dahulu dengan metode CEEMDAN-FE, yang menghilangkan gangguan informasi dengan menambahkan dekomposisi mode empiris terintegrasi penuh dengan noise adaptif, mengekstrak informasi multi-skala, dan menggunakan entropi fuzzy untuk mengurangi jumlah sub-sinyal. Selanjutnya data yang diolah dibagi menjadi training set dan test set dengan proporsi 75% dan 25%. Pada fase pelatihan, kumpulan data pelatihan yang telah diproses sebelumnya dimasukkan ke dalam model LSTM-Transformer. Gunakan backpropagation dan pengoptimal Adam untuk memperbarui bobot model, dan gunakan pencarian grid untuk mengidentifikasi hyperparameter terbaik dari modul LSTMTransformer untuk memastikan performa model dalam rentang waktu prediksi yang berbeda (7 hari, 5 hari, 3 hari, 1 hari) optimal.
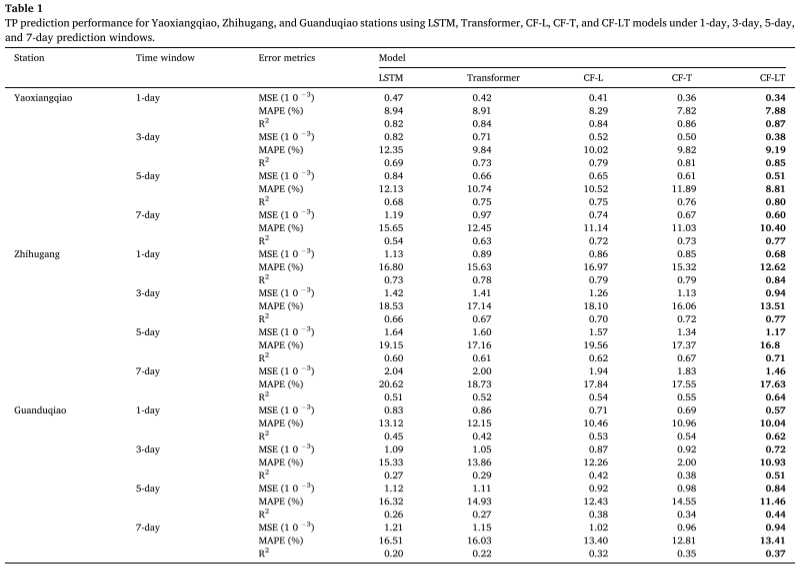
Hasil percobaan : Menerapkan model pelatihan terbaik pada kumpulan data pengujian, tabel ini merangkum prediksi konsentrasi TP yang diberikan oleh model CF-LT, LSTM, Transformer, CF-L, dan CF-T di lokasi berbeda dan jendela waktu prediksi berbeda. Model CF-LT yang diusulkan memberikan hasil terbaik untuk ketiga metrik evaluasi. Dari segi R2, model CF-LT berkisar antara 0,37 hingga 0,87, sedangkan model CF-L dan CF-T terbaik berikutnya masing-masing adalah 0,32-0,84 dan 0,35-0,86. Hal ini menunjukkan bahwa menggabungkan memori jangka panjang LSTM dengan mekanisme perhatian Transformer dapat meningkatkan akurasi prediksi. Jika dibandingkan model LSTM dan Transformer terburuk dengan model CF-L dan CF-T, MAPE berkisar antara 8,94%-20,62% (LSTM) dan 8,91%-18,73% (Transformer) hingga 8,29%-19,56% (CF -L) dan 7,82%-17,55% (CF-T). Hasil ini menunjukkan bahwa dekomposisi data dan pemodelan pembagian frekuensi secara signifikan meningkatkan akurasi prediksi dengan menangkap lebih banyak informasi yang tersembunyi dalam data asli.
Prediksi faktor yang mempengaruhi konsentrasi total fosfor TP:
Nilai SHAP absolut rata-rata (MASV) digunakan untuk mengukur kontribusi fitur input (WT, PH, DO, COD, EC, TU, TN, NH3-N, TP) terhadap hasil prediksi TP semakin besar dampaknya terhadap hasil prediksi model. Penelitian menunjukkan bahwa selain rangkaian konsentrasi TP sebelumnya, total nitrogen (TN) dan kekeruhan (TU) adalah dua faktor utama yang mempengaruhi prediksi TP. Hal ini menunjukkan bahwa perubahan TP tidak hanya dipengaruhi secara langsung oleh konsentrasi historis, namun juga terkait erat dengan dinamika pertumbuhan alga yang terkait dengan emisi polusi non-point source dan rasio nitrogen-fosfor di badan air. Secara khusus, korelasi yang signifikan antara TN dan TP menekankan efek penggabungan keduanya dalam siklus nutrisi danau dan menyoroti pentingnya masukan nitrogen sumber non-titik untuk prediksi konsentrasi fosfor.
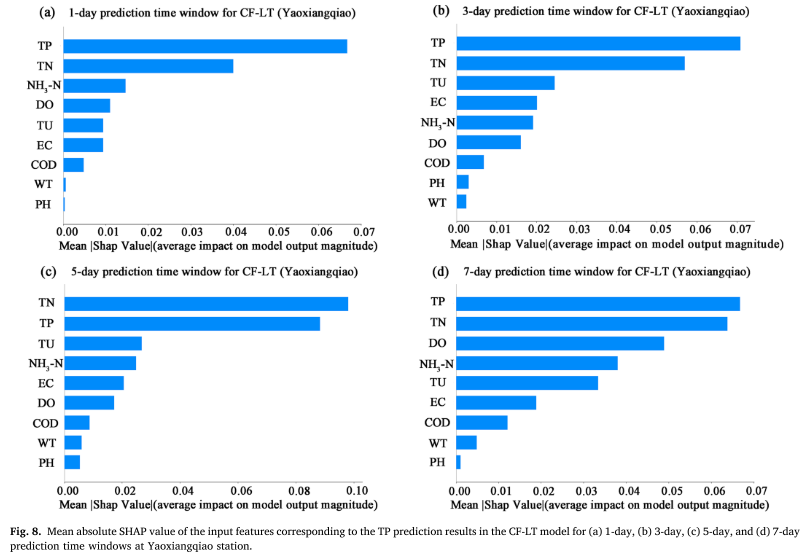
Dari hasil tersebut dapat dilakukan pengamatan sebagai berikut:
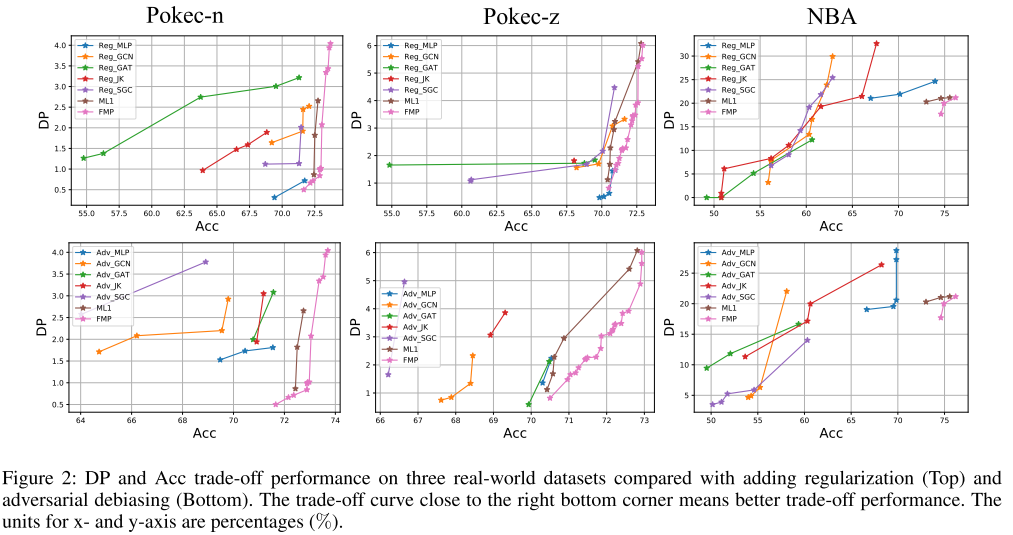
Perbandingan dengan debiasing dan regularisasi permusuhan : Bagi secara acak 50%/25%/25% untuk kumpulan data pelatihan, validasi, dan pengujian. Gambar 2 menunjukkan kurva optimal Pareto untuk semua metode, di mana titik sudut kanan bawah mewakili kinerja ideal (akurasi tertinggi dan deviasi prediksi terendah).
Model hibrida CF-LT yang diusulkan dalam artikel ini menggabungkan modul CEEM DAN, FE, LSTM dan Transformer untuk memprediksi konsentrasi TP di air permukaan. Pendekatan hibrid ini memecahkan kekurangan model overfitting dan underfitting yang disebabkan oleh data berdimensi tinggi dan ketidakmampuan untuk membangun ketergantungan jangka panjang antar data saat membuat prediksi jangka panjang. Selain itu, nilai SHAP digunakan untuk menginterpretasikan keluaran model CF-LT.
Model ini menggunakan data dari tiga stasiun pemantauan kualitas air di Cekungan Danau Taihu untuk menghasilkan 9 indikator kualitas air dalam rentang waktu prediksi yang berbeda. Algoritma LSTM, Transformer, CF-L dan CF-T digunakan sebagai model kontrol. Model CF-LT memiliki nilai R2 sebesar 0,37–0,87, nilai MSE sebesar 0,34 × 10−3–1,46 × 10−3, dan nilai MAPE sebesar 7,88%–17,63% pada kumpulan data pengujian, yang menunjukkan bahwa ketiganya indikatornya lebih baik dibandingkan hasil LSTM, Transformer, CF-L dan CF-T. Model CF-LT yang diusulkan juga memberikan hasil prediksi puncak terbaik. Berdasarkan interpretasi SHAP, kami menemukan bahwa TU dan TN (tidak termasuk rangkaian waktu awal konsentrasi TP) merupakan faktor penting yang mempengaruhi prediksi TP, yang menunjukkan bahwa perubahan TP tidak hanya terkait dengan tingkat awal konsentrasi TP, namun juga dipengaruhi oleh TP. konsentrasi. Hubungan antara emisi polusi non-point source dan tanaman air di muara Danau Taihu. Selain itu, perlu dicatat bahwa TN dan TU berkontribusi lebih besar terhadap prediksi konsentrasi TP di musim hujan. Oleh karena itu, hasil penelitian ini menunjukkan bahwa model CF-LT memberikan informasi tambahan untuk memahami mekanisme respons TP ketika kondisi lingkungan berbeda berubah.
Pemrosesan awal data CEEMDAN dan FE
def ceemdan_fe_preprocessing(data):
# CEEMDAN分解
imfs, residue = ceemdan(data, **ceemdan_params)
# 计算各个IMF的模糊熵
fe_values = []
for imf in imfs:
fe_values.append(fuzzy_entropy(imf)) # 假定fuzzy_entropy为计算模糊熵的函数
# 根据FE值重组IMFs
imfs_sorted = [imf for _, imf in sorted(zip(fe_values, imfs))]
imf_hf, imf_mf, imf_lf, imf_trend = imfs_sorted[:4], imfs_sorted[4:8], imfs_sorted[8:12], imfs_sorted[12:]
return np.concatenate((imf_hf, imf_mf, imf_lf, imf_trend), axis=1)
# 应用到数据上
preprocessed_data = ceemdan_fe_preprocessing(original_data)
LSTM &Transformator
def get_positional_encoding(max_len, d_model):
pe = np.zeros((max_len, d_model))
position = np.arange(0, max_len).reshape(-1, 1)
div_term = np.exp(np.arange(0, d_model, 2) * -(np.log(10000.0) / d_model))
pe[:, 0::2] = np.sin(position * div_term)
pe[:, 1::2] = np.cos(position * div_term)
return pe
def transformer_encoder(inputs, d_model, num_heads, ff_dim):
x = MultiHeadAttention(num_heads=num_heads, key_dim=d_model)(inputs, inputs)
x = LayerNormalization()(Add()([inputs, x]))
x = Dense(ff_dim, activation='relu')(x)
x = Dense(d_model)(x)
x = LayerNormalization()(Add()([inputs, x]))
return x
def transformer_decoder(inputs, encoder_outputs, d_model, num_heads, ff_dim):
return decoder_output
input_features = Input(shape=(input_shape))
lstm_out = LSTM(lstm_units)(input_features) # LSTM
pos_encodings = get_positional_encoding(max_seq_length, d_model)
transformer_in = Add()([lstm_out, pos_encodings])
transformer_encoded = transformer_encoder(transformer_in, d_model, num_heads, ff_dim)
decoder_output = transformer_decoder(decoder_input, transformer_encoded, d_model, num_heads, ff_dim)
output_layer = Dense(output_dim, activation='linear')(decoder_output)
model = Model(inputs=input_features, outputs=output_layer)
model.compile(optimizer=Adam(learning_rate), loss='mse')
Studi ini mengembangkan model hibrida CEEMDAN-FE-LSTM-Transformer yang dapat ditafsirkan untuk prediksi konsentrasi total fosfor dalam air permukaan. Model ini secara signifikan meningkatkan akurasi prediksi melalui perpaduan teknologi pra-pemrosesan data canggih dan model pembelajaran mendalam, dan Memberikan penjelasan fitur yang jelas. melalui SHAP. Hasil percobaan mengkonfirmasi efektivitas model, terutama identifikasi faktor lingkungan utama, yang menyediakan alat yang ampuh untuk pengelolaan eutrofikasi badan air dan pengendalian polusi.
[1] Jurnal Hidrologi Jilid 629Februari 2024, 130609

Ia telah mengabdikan dirinya untuk meneliti teknologi selama lebih dari 30 tahun, dan mahir dalam berbagai bahasa seperti java, linux, javascript, php, css, dll. Ia telah memberikan banyak kontribusi di bidang open source stasiun dokumentasi pengembang untuk berbagi beberapa masalah dalam pengembangan teknologi untuk referensi di masa mendatang. Semua orang memeriksanya

Surat[email protected]