
Mi informacion de contacto
Correo[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Esta semana leí un artículo titulado Modelo híbrido de transformador CEEMDAN-FE-LSTM interpretable para predecir concentraciones de fósforo total en aguas superficiales. Este artículo propone un modelo híbrido para la predicción de TP. Este artículo propone un modelo híbrido para la predicción de TP, concretamente el modelo CF-LT. El modelo combina de forma innovadora la descomposición de modo empírico (EMD) totalmente integrada con procesamiento de ruido adaptativo, análisis de entropía difusa, red de memoria a corto plazo (LSTM) y tecnología Transformer. Al introducir la tecnología de reconstrucción por división de frecuencia de datos, este modelo resuelve eficazmente los problemas de sobreajuste y desajuste que suelen ocurrir cuando los modelos tradicionales de aprendizaje automático manejan datos de alta dimensión. Al mismo tiempo, la aplicación del mecanismo de atención permite al modelo CF-LT superar las limitaciones de otros modelos que dificultan el establecimiento de dependencias a largo plazo entre datos al realizar predicciones a largo plazo. Los resultados de la predicción muestran que el modelo CF-LT alcanzó un coeficiente de determinación (R2) de 0,37 a 0,87 en el conjunto de datos de prueba, lo que supuso una mejora significativa de 0,05 a 0,17 (es decir, de 6 % a 85 %) en comparación con el modelo de control. modelo. Además, el modelo CF-LT también mostró el mejor rendimiento de predicción máxima.
El periódico semanal de esta semana descifra el artículo titulado Interpretable CEEMDAN-FE-LSTM-transformer hybrid model for predicting total phosphorus concentrates in surface water. Este artículo presenta un modelo híbrido, CF-LT, específicamente para la predicción de TP. El modelo integra de manera innovadora la descomposición modal empírica de conjunto completo (EMD) con el procesamiento de ruido adaptativo, el análisis de entropía difusa, las redes de memoria a corto y largo plazo (LSTM) y la tecnología de transformadores. Al introducir la división y reconstrucción de frecuencias de datos, CF-LT aborda de manera eficaz los problemas de sobreajuste y subajuste que los modelos de aprendizaje automático tradicionales suelen encontrar al tratar con datos de alta dimensión. Además, la aplicación del mecanismo de atención permite a CF-LT superar las limitaciones de otros modelos al establecer dependencias a largo plazo entre puntos de datos durante las predicciones a largo plazo. Los resultados de predicción demuestran que CF-LT logra un coeficiente de decisión (R2) que oscila entre 0,37 y 0,87 en los conjuntos de datos de prueba, lo que representa una mejora significativa de 0,05 a 0,17 (o del 6 % al 85 %) en comparación con los modelos de control. Además, CF-LT ofrece el mejor rendimiento de predicción de picos.
Ejemplo: Modelo híbrido de transformador CEEMDAN-FE-LSTM interpretable para predecir concentraciones totales de fósforo en aguas superficiales
Autor: Jiefu Yao, Shuai Chen, Xiaohong Ruan
liberar:Revista de hidrología Volumen 629, febrero de 2024, 130609
Fuente: https://www.sciencedirect.com/science/article/pii/S0022169424000039?via%3Dihub
Este artículo propone un modelo híbrido para la predicción de TP. Este modelo (CF-LT) combina descomposición de modo empírico (EMD) totalmente integrada con ruido adaptativo, entropía difusa, memoria a corto plazo y transformador.Reconstrucción de división de frecuencia de datosLa introducción de resuelve eficazmente los problemas de sobreajuste y subajuste que ocurrieron cuando los modelos de aprendizaje automático anteriores enfrentaron datos de alta dimensión.mecanismo de atención Esto supera el problema de que estos modelos no pueden establecer dependencias a largo plazo entre datos y hacer predicciones a largo plazo. Los resultados de la predicción muestran que el modelo CF-LT logra un coeficiente de determinación (R2) de 0,37-0,87 en el conjunto de datos de prueba, que es 0,05-0,17 (6%-85%) mayor que el modelo de control. Además, el modelo CF-LT proporcionó la mejor predicción de picos.
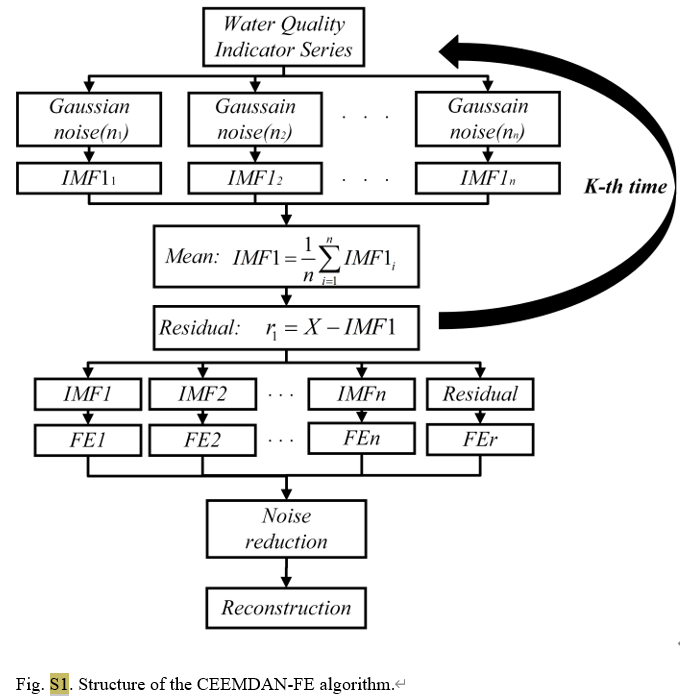
Como método avanzado de análisis de series de tiempo, CEEMDAN reduce efectivamente el problema de alias de modo existente en el EMD tradicional al agregar ruido adaptativo al proceso de descomposición de modo empírico (EMD). Puede descomponer la señal original en una serie de funciones de modo intrínseco (IMF). Cada IMF representa diferentes características de escala de tiempo de la señal, lo que hace que el análisis de señales complejas sea más intuitivo y preciso. En este estudio, se utilizó CEEMDAN para procesar datos diarios de calidad del agua de tres estaciones de monitoreo en el lago Tai, separando la concentración de fósforo total y otros parámetros de calidad del agua, como la temperatura del agua, el pH, el oxígeno disuelto, etc., en señales en diferentes bandas de frecuencia.
Algoritmo S1: Descomposición modal empírica de conjunto completo con ruido adaptativo (CEEMDAN)
yi ( t ) = y ( t ) + ϵ 0 vi ( t ) i = 1 , 2 , … , n (S1) y^{i}(t)=y(t)+epsilon_0v^i(t)quad i=1,2,puntos,ntag{S1}yi(a)=y(a)+ϵ0eni(a)i=1,2,…,norteorteorteorte(S1)
FMI1 i = E 0 ( yi ( t ) ) + r 1 i FMI1 ‾ = 1 n FMI1 i (S2) text{FMI1}_i=E_0(y^i(t))+r^i_1quad overline{text{FMI1}}=frac1ntext{FMI1}_itag{S2}FMI1i=mi0(yi(a))+a1iFMI1=norteorteorteorte1FMI1i(S2)
r 1 = yi ( t ) − FMI1 ‾ (S3) r_1=y^i(t)-overline{text{FMI1}}etiqueta{S3}a1=yi(a)−FMI1(S3)
FMI2 ‾ = 1 n ∑ i = 1 n E 1 ( r 1 + ϵ 1 E 1 ( vi ( t ) ) ) (S4) overline{text{FMI2}}=frac1nsum^n_{i=1}E_1(r_1+epsilon_1E_1(v^i(t))) tag{S4}FMI2=norteorteorteorte1i=1∑norteorteorteortemi1(a1+ϵ1mi1(eni(a)))(S4)
y ( t ) = ∑ l = 1 K − 1 FMI1 ‾ + r K (S5) y(t)=suma^{K-1}_{l=1}overline{text{FMI1}}+r_Ktag{S5}y(a)=yo=1∑K−1FMI1+aK(S5)
Para la parte CEEMDAN-FE, primero dividimos el conjunto de datos original en conjuntos de datos de entrenamiento y prueba, y luego aplicamos CEEMDAN para descomponer cada característica de los dos conjuntos de datos en múltiples funciones de modo intrínseco (IMF). Según la cercanía de los valores FE de cada FMI, se reconstruyen en componentes de alta frecuencia (IMFH), frecuencia intermedia (IMFM), baja frecuencia (IMFL) y término de tendencia (IMFT), que reflejan diferentes aspectos del FMI. .
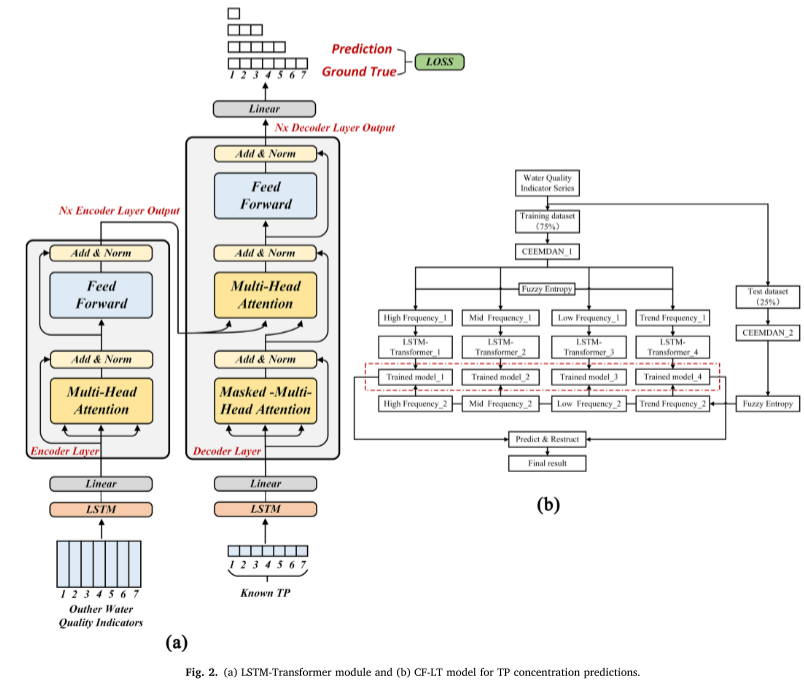
Para la parte LSTM-Transformer, en el codificador y decodificador, la capa oculta de LSTM se reemplaza por la codificación de posición del Transformer para establecer la dependencia temporal entre los datos de entrada. El proceso de cálculo específico es el siguiente (Figura 2a).
SHAP es un método de teoría de juegos para interpretar el resultado de cualquier modelo de ML.Para determinar el impacto de las características de entrada en la salida del modelo, las características de entrada z = [ z 1 , . . . , zp ] z = [z1, ..., zp]el=[el1,...,elpag]Relacionado con el modelo de aprendizaje profundo entrenado F.
F = f ( z ) = ϕ 0 + ∑ i = 1 M ϕ izi (12) F=f(z)=phi_0+sum_{i=1}^M phi_iz_i etiqueta{12}F=F(el)=ϕ0+i=1∑METROETROETROϕieli(12)
φ_i ∈ Rφi∈RIndica la contribución de cada característica al modelo, que viene dada por la siguiente fórmula:
ϕ i ( F , x ) = ∑ z ≤ x ∣ z ∣ ! ( M − ∣ z ∣ − 1 ) ! M ! [ F ( z ) − F ( z / i ) ] (13) phi_i(F,x)=sum_{zleq x}frac{|z|!(M-|z|-1)!}{M!}[F(z)-F(z/i)] etiqueta{13}ϕi(F,X)=el≤X∑METROETROETRO!∣el∣!(METROETROETRO−∣el∣−1)
El estudio propone un nuevo modelo para predecir las concentraciones de fósforo total. El modelo combina las tecnologías CEEM DAN, FE, LSTM y Transformer y utiliza SHAP para interpretar el resultado del modelo. El principal objetivo de este estudio es evaluar el desempeño del modelo CEEMDAN-FE-LSTM-Transformer (CF-LT) propuesto para predecir la concentración de TP en la entrada al lago Tai y aplicar SHAP para interpretar la salida del CF-LT. modelo. Esto debería revelar los factores clave que afectan la concentración de PT en la región y sus mecanismos de respuesta.
La descomposición de datos de alta dimensión puede producir una gran cantidad de componentes modales. Para resolver este problema, la entropía difusa (FE), un método eficiente para calcular la complejidad del tiempo, se puede combinar con CEEMDAN. Esta combinación reconstruye efectivamente las subseñales descompuestas de CEEMDAN, reduciendo así la cantidad de modelos de subfrecuencia.
Los modelos LSTMTransformer pueden capturar relaciones entre puntos de tiempo no adyacentes y al mismo tiempo preservar las características de la serie de tiempo de los datos de entrada.
Los modelos transformadores utilizan mecanismos de atención para identificar correlaciones entre dos ubicaciones en un contexto específico durante el entrenamiento. Esto permite la adquisición eficiente de datos relevantes y reduce la redundancia de información.
Las principales aportaciones de este artículo se dan en cuatro aspectos:
conjunto de datos : La cuenca del lago Taihu está situada en el curso inferior del río Yangtze, con una superficie de 36.900 kilómetros cuadrados, con una densa red fluvial y numerosos lagos. El lago Taihu es un típico lago poco profundo. La cuenca tiene las características de un clima subtropical húmedo del norte, con una temperatura media anual de 15-17°C y una precipitación media anual de 1181 mm. Este estudio utilizó datos de monitoreo de la calidad del agua de la estación Yaoxiangqiao, la estación Zhihugang y la estación Guanduqiao (Figura S2). Estas estaciones de monitoreo están ubicadas en Taihukou, una sección nacional clave de evaluación de la calidad del agua. Los datos provienen del Centro de Monitoreo Ambiental Provincial de Jiangsu.
Criterios de evaluación : La evaluación del desempeño del modelo utiliza varios indicadores clave: coeficiente de determinación (R²), error cuadrático medio (MSE) y error porcentual absoluto medio (MAPE). R² mide el grado de ajuste entre el valor predicho del modelo y el valor real. Cerca de 1 indica que el modelo tiene una gran capacidad de predicción; MSE mide la suma de cuadrados del error de predicción. MAPE refleja el tamaño del error de predicción desde una perspectiva porcentual. El valor más bajo significa predicciones más precisas.
Detalles de implementacion : El proceso experimental incluye preprocesamiento de datos, entrenamiento de modelos y pruebas. Se establece un procedimiento experimental completo para evaluar el desempeño del modelo propuesto en diferentes conjuntos de datos y ventanas de tiempo de predicción. Primero, los datos se preprocesan mediante el método CEEMDAN-FE, que elimina la interferencia de la información agregando una descomposición de modo empírico totalmente integrada con ruido adaptativo, extrae información de múltiples escalas y utiliza entropía difusa para reducir la cantidad de subseñales. A continuación, los datos procesados se dividen en conjuntos de entrenamiento y conjuntos de pruebas en proporciones del 75% y el 25%. En la fase de entrenamiento, el conjunto de datos de entrenamiento preprocesados se ingresa al modelo LSTM-Transformer. Utilice la retropropagación y el optimizador Adam para actualizar los pesos del modelo y utilice la búsqueda de cuadrícula para identificar los mejores hiperparámetros del módulo LSTMTransformer para garantizar el rendimiento óptimo del modelo en diferentes ventanas de tiempo de predicción (7 días, 5 días, 3 días, 1 día).
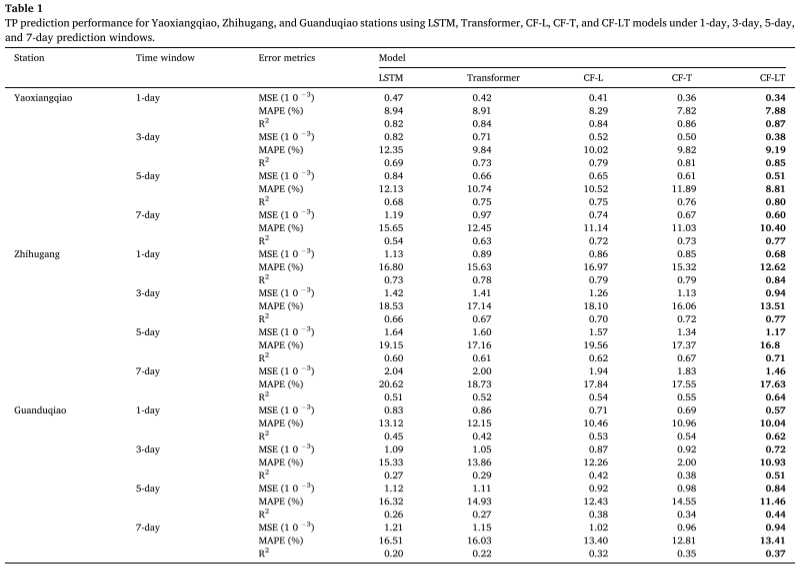
Resultados experimentales : Al aplicar el mejor modelo de entrenamiento al conjunto de datos de prueba, la tabla resume las predicciones de concentración de TP dadas por los modelos CF-LT, LSTM, Transformer, CF-L y CF-T en diferentes sitios y diferentes ventanas de tiempo de predicción. El modelo CF-LT propuesto ofrece los mejores resultados para las tres métricas de evaluación. En términos de R2, el modelo CF-LT oscila entre 0,37 y 0,87, mientras que los siguientes mejores modelos CF-L y CF-T son 0,32-0,84 y 0,35-0,86 respectivamente. Esto muestra que combinar la memoria a largo plazo de LSTM con el mecanismo de atención de Transformer puede mejorar la precisión de la predicción. Comparando los peores modelos LSTM y Transformer con los modelos CF-L y CF-T, el MAPE oscila entre 8,94%-20,62% (LSTM) y 8,91%-18,73% (Transformer) hasta 8,29%-19,56% (CF -L) y 7,82%-17,55% (CF-T). Estos resultados demuestran que la descomposición de datos y el modelado de división de frecuencia mejoran significativamente la precisión de la predicción al capturar más información oculta en los datos originales.
Predicción de factores que afectan la concentración de TP de fósforo total.:
El valor SHAP absoluto promedio (MASV) se utiliza para cuantificar la contribución de las características de entrada (WT, PH, DO, COD, EC, TU, TN, NH3-N, TP) a los resultados de la predicción de TP. Cuanto mayor sea el MASV, mayor. Cuanto mayor sea el impacto en los resultados de la predicción del modelo. Las investigaciones muestran que, además de las series anteriores de concentraciones de TP, el nitrógeno total (TN) y la turbiedad (TU) son los dos factores principales que afectan la predicción de TP. Esto muestra que los cambios en TP no solo se ven afectados directamente por las concentraciones históricas, sino que también están estrechamente relacionados con la dinámica de crecimiento de algas asociada con las emisiones contaminantes de fuentes difusas y la relación nitrógeno-fósforo en el cuerpo de agua. En particular, la correlación significativa entre TN y TP enfatiza el efecto de acoplamiento de los dos en el ciclo de nutrientes del lago y resalta la importancia del aporte de nitrógeno de fuentes difusas para la predicción de la concentración de fósforo.
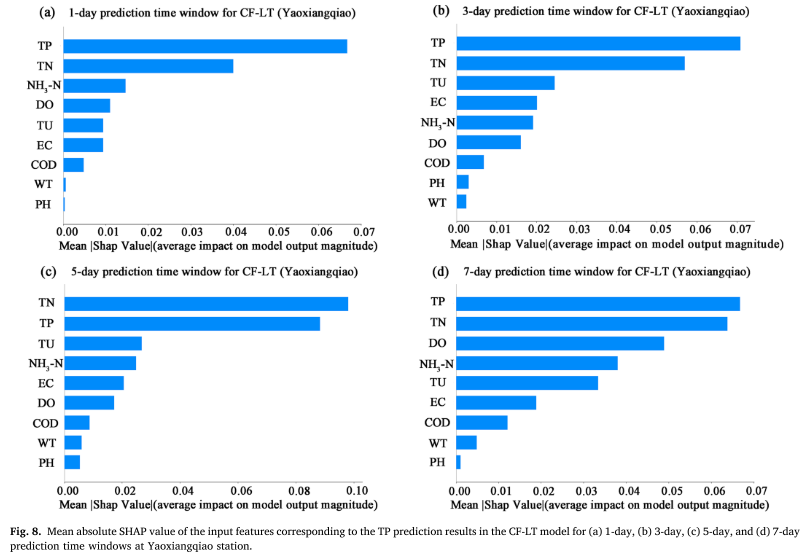
De estos resultados se pueden hacer las siguientes observaciones:
Comparación con la regularización y el desesgo contradictorio : Divida aleatoriamente 50%/25%/25% para conjuntos de datos de entrenamiento, validación y prueba. La Figura 2 muestra las curvas óptimas de Pareto para todos los métodos, donde el punto de la esquina inferior derecha representa el rendimiento ideal (mayor precisión y menor desviación de predicción).
El modelo híbrido CF-LT propuesto en este artículo combina módulos CEEM DAN, FE, LSTM y Transformer para predecir la concentración de TP en aguas superficiales. Este enfoque híbrido resuelve las deficiencias del sobreajuste y el desajuste del modelo causado por datos de alta dimensión y la incapacidad de establecer dependencias a largo plazo entre los datos al realizar predicciones a largo plazo. Además, los valores SHAP se utilizan para interpretar la salida del modelo CF-LT.
El modelo utiliza datos de tres estaciones de monitoreo de la calidad del agua en la cuenca del lago Taihu para generar 9 indicadores de calidad del agua en diferentes ventanas de tiempo de predicción. Como modelos de control se utilizan algoritmos LSTM, Transformer, CF-L y CF-T. El modelo CF-LT tiene un valor R2 de 0,37–0,87, un valor MSE de 0,34 × 10−3–1,46 × 10−3 y un valor MAPE de 7,88%–17,63% en el conjunto de datos de prueba, lo que indica que los tres Los indicadores son mejores que los resultados de LSTM, Transformer, CF-L y CF-T. El modelo CF-LT propuesto también produjo los mejores resultados de predicción de picos. Con base en la interpretación de SHAP, encontramos que TU y TN (excluyendo las series temporales tempranas de concentración de TP) son factores importantes que afectan la predicción de TP, lo que indica que los cambios en TP no solo están relacionados con los niveles tempranos de concentración de TP, sino que también se ven afectados por TP. concentración. La relación entre las emisiones contaminantes de fuentes difusas y las plantas acuáticas en el estuario del lago Taihu. Además, cabe señalar que TN y TU contribuyen más a la predicción de la concentración de TP en la temporada de lluvias. Por lo tanto, los resultados de este estudio indican que el modelo CF-LT proporciona información adicional para comprender el mecanismo de respuesta de TP cuando cambian diferentes condiciones ambientales.
Preprocesamiento de datos CEEMDAN y FE
def ceemdan_fe_preprocessing(data):
# CEEMDAN分解
imfs, residue = ceemdan(data, **ceemdan_params)
# 计算各个IMF的模糊熵
fe_values = []
for imf in imfs:
fe_values.append(fuzzy_entropy(imf)) # 假定fuzzy_entropy为计算模糊熵的函数
# 根据FE值重组IMFs
imfs_sorted = [imf for _, imf in sorted(zip(fe_values, imfs))]
imf_hf, imf_mf, imf_lf, imf_trend = imfs_sorted[:4], imfs_sorted[4:8], imfs_sorted[8:12], imfs_sorted[12:]
return np.concatenate((imf_hf, imf_mf, imf_lf, imf_trend), axis=1)
# 应用到数据上
preprocessed_data = ceemdan_fe_preprocessing(original_data)
LSTM y transformador
def get_positional_encoding(max_len, d_model):
pe = np.zeros((max_len, d_model))
position = np.arange(0, max_len).reshape(-1, 1)
div_term = np.exp(np.arange(0, d_model, 2) * -(np.log(10000.0) / d_model))
pe[:, 0::2] = np.sin(position * div_term)
pe[:, 1::2] = np.cos(position * div_term)
return pe
def transformer_encoder(inputs, d_model, num_heads, ff_dim):
x = MultiHeadAttention(num_heads=num_heads, key_dim=d_model)(inputs, inputs)
x = LayerNormalization()(Add()([inputs, x]))
x = Dense(ff_dim, activation='relu')(x)
x = Dense(d_model)(x)
x = LayerNormalization()(Add()([inputs, x]))
return x
def transformer_decoder(inputs, encoder_outputs, d_model, num_heads, ff_dim):
return decoder_output
input_features = Input(shape=(input_shape))
lstm_out = LSTM(lstm_units)(input_features) # LSTM
pos_encodings = get_positional_encoding(max_seq_length, d_model)
transformer_in = Add()([lstm_out, pos_encodings])
transformer_encoded = transformer_encoder(transformer_in, d_model, num_heads, ff_dim)
decoder_output = transformer_decoder(decoder_input, transformer_encoded, d_model, num_heads, ff_dim)
output_layer = Dense(output_dim, activation='linear')(decoder_output)
model = Model(inputs=input_features, outputs=output_layer)
model.compile(optimizer=Adam(learning_rate), loss='mse')
Este estudio desarrolló un modelo híbrido CEEMDAN-FE-LSTM-Transformer interpretable para la predicción de la concentración de fósforo total en aguas superficiales. El modelo mejoró significativamente la precisión de la predicción mediante la fusión de tecnología avanzada de preprocesamiento de datos y modelos de aprendizaje profundo, y proporciona una explicación clara de las características. a través de SHAP. Los resultados experimentales confirmaron la eficacia del modelo, especialmente la identificación de factores ambientales clave, proporcionando una poderosa herramienta para la gestión de la eutrofización de las masas de agua y el control de la contaminación.
[1] Revista de hidrología Volumen 629, febrero de 2024, 130609

Se ha dedicado a la investigación de tecnología durante más de 30 años y domina varios lenguajes como java, linux, javascript, php, css, etc. Ha realizado muchas contribuciones en el campo del código abierto. Estación de documentación para desarrolladores para compartir algunos problemas en el desarrollo de tecnología para referencia futura.

Correo[email protected]