
le mie informazioni di contatto
Posta[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Questa settimana ho letto un articolo intitolato Modello ibrido interpretabile del trasformatore CEEMDAN-FE-LSTM per prevedere le concentrazioni di fosforo totale nelle acque superficiali. Questo articolo propone un modello ibrido per la previsione del TP. Questo articolo propone un modello ibrido per la previsione del TP, vale a dire il modello CF-LT. Il modello combina in modo innovativo la decomposizione in modalità empirica (EMD) completamente integrata con l'elaborazione adattiva del rumore, l'analisi entropica fuzzy, la rete di memoria a lungo termine (LSTM) e la tecnologia Transformer. Introducendo la tecnologia di ricostruzione della divisione della frequenza dei dati, questo modello risolve efficacemente i problemi di over-fitting e under-fitting che tendono a verificarsi quando i modelli tradizionali di machine learning gestiscono dati ad alta dimensione. Allo stesso tempo, l’applicazione del meccanismo di attenzione consente al modello CF-LT di superare i limiti di altri modelli che rendono difficile stabilire dipendenze a lungo termine tra i dati quando si effettuano previsioni a lungo termine. I risultati della previsione mostrano che il modello CF-LT ha raggiunto un coefficiente di determinazione (R2) compreso tra 0,37 e 0,87 sul set di dati del test, che rappresenta un miglioramento significativo compreso tra 0,05 e 0,17 (ovvero, dal 6% all'85%) rispetto al controllo modello. Inoltre, il modello CF-LT ha mostrato anche le migliori prestazioni di previsione dei picchi.
Il settimanale di questa settimana decodifica il documento intitolato Interpretable CEEMDAN-FE-LSTM-transformer hybrid model for predicting total phosphorus concentrations in surface water. Questo documento introduce un modello ibrido, CF-LT, specificamente per la previsione di TP. Il modello integra in modo innovativo Complete Ensemble Empirical Mode Decomposition (EMD) con elaborazione del rumore adattiva, analisi dell'entropia fuzzy, reti Long Short-Term Memory (LSTM) e tecnologia Transformer. Introducendo la divisione e la ricostruzione della frequenza dei dati, CF-LT affronta efficacemente i problemi di overfitting e underfitting che i modelli di apprendimento automatico tradizionali incontrano spesso quando hanno a che fare con dati ad alta dimensionalità. Inoltre, l'applicazione del meccanismo di attenzione consente a CF-LT di superare i limiti di altri modelli nello stabilire dipendenze a lungo termine tra punti dati durante le previsioni a lungo termine. I risultati della previsione dimostrano che CF-LT raggiunge un coefficiente di decisione (R2) che va da 0,37 a 0,87 sui set di dati di prova, rappresentando un miglioramento significativo da 0,05 a 0,17 (o dal 6% all'85%) rispetto ai modelli di controllo. Inoltre, CF-LT fornisce le migliori prestazioni di previsione di picco.
Argomento: Modello ibrido CEEMDAN-FE-LSTM-trasformatore interpretabile per la previsione delle concentrazioni totali di fosforo nelle acque superficiali
Autore: Jiefu Yao, Shuai Chen, Xiaohong Ruan
pubblicazione:Rivista di idrologia Volume 629, febbraio 2024, 130609
Fonte: https://www.sciencedirect.com/science/article/pii/S0022169424000039?via%3Dihub
Questo articolo propone un modello ibrido per la previsione del TP. Questo modello (CF-LT) combina la decomposizione in modalità empirica (EMD) completamente integrata con rumore adattivo, entropia fuzzy, memoria a lungo termine e trasformatore.Ricostruzione della divisione di frequenza dei datiL'introduzione di risolve in modo efficace i problemi di over-fitting e under-fitting che si verificavano quando i precedenti modelli di machine learning si confrontavano con dati ad alta dimensione.meccanismo di attenzione Ciò supera il problema che questi modelli non possono stabilire dipendenze a lungo termine tra i dati e fare previsioni a lungo termine. I risultati della previsione mostrano che il modello CF-LT raggiunge un coefficiente di determinazione (R2) di 0,37-0,87 sul set di dati del test, che è 0,05-0,17 (6%-85%) superiore rispetto al modello di controllo. Inoltre, il modello CF-LT ha fornito la migliore previsione del picco.
Essendo un metodo avanzato di analisi delle serie temporali, CEEMDAN riduce efficacemente il problema dell'aliasing modale esistente nell'EMD tradizionale aggiungendo rumore adattivo al processo di decomposizione empirica della modalità (EMD). Può scomporre il segnale originale in una serie di funzioni di modalità intrinseca (IMF). Ciascun IMF rappresenta diverse caratteristiche di scala temporale del segnale, rendendo così l'analisi di segnali complessi più intuitiva e accurata. In questo studio, CEEMDAN è stato utilizzato per elaborare i dati giornalieri sulla qualità dell'acqua provenienti da tre stazioni di monitoraggio nel lago Tai, separando la concentrazione totale di fosforo e altri parametri di qualità dell'acqua come temperatura dell'acqua, pH, ossigeno disciolto, ecc. in segnali in diverse bande di frequenza.
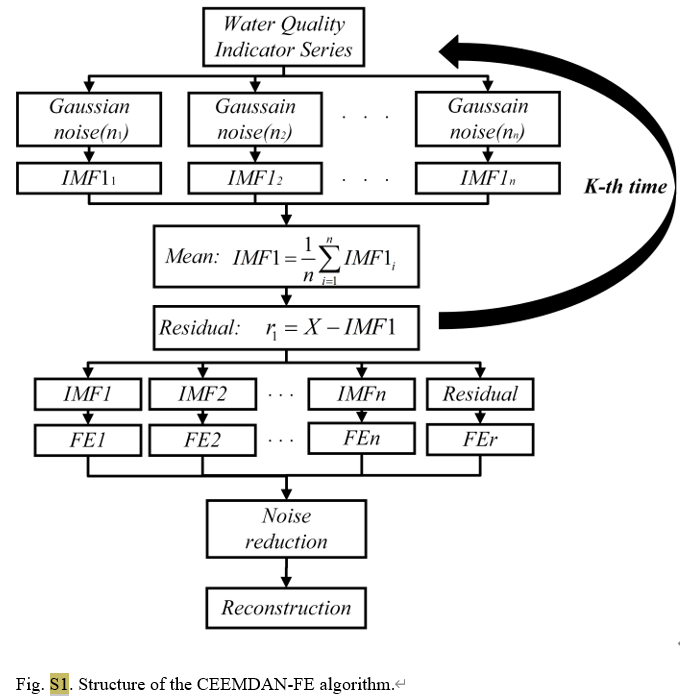
Algoritmo S1: Decomposizione completa della modalità empirica dell'insieme con rumore adattivo (CEEMDAN)
yi ( t ) = y ( t ) + ϵ 0 vi ( t ) i = 1 , 2 , … , n (S1) y^{i}(t)=y(t)+epsilon_0v^i(t)quad i=1,2,punti,ntag{S1}eioooooooooooooooooo(T)=e(T)+ϵ0laioooooooooooooooooo(T)ioooooooooooooooooo=1,2,…,N(S1)
FMI1 i = E 0 ( yi ( t ) ) + r 1 i FMI1 ‾ = 1 n FMI1 i (S2) testo{FMI1}_i=E_0(y^i(t))+r^i_1quad overline{testo{FMI1}}=frac1ntesto{FMI1}_itag{S2}FMI1ioooooooooooooooooo=E0(eioooooooooooooooooo(T))+R1iooooooooooooooooooFMI1=N1FMI1ioooooooooooooooooo(S2)
r 1 = yi ( t ) − FMI1 ‾ (S3) r_1=y^i(t)-overline{testo{FMI1}}tag{S3}R1=eioooooooooooooooooo(T)−FMI1(S3)
FMI2 ‾ = 1 n ∑ i = 1 n E 1 ( r 1 + ϵ 1 E 1 ( vi ( t ) ) ) (S4) overline{testo{FMI2}}=frac1nsum^n_{i=1}E_1(r_1+epsilon_1E_1(v^i(t))) tag{S4}FMI2=N1ioooooooooooooooooo=1∑NE1(R1+ϵ1E1(laioooooooooooooooooo(T)))(S4)
y ( t ) = ∑ l = 1 K − 1 FMI1 ‾ + r K (S5) y(t)=somma^{K-1}_{l=1}sopra{testo{FMI1}}+r_Ktag{S5}e(T)=l=1∑K−1FMI1+RK(S5)
Per la parte CEEMDAN-FE, dividiamo prima il set di dati originale in set di dati di addestramento e test, quindi applichiamo CEEMDAN per scomporre ciascuna caratteristica nei due set di dati in più funzioni in modalità intrinseca (IMF). A seconda della vicinanza dei valori FE di ciascun FMI, questi vengono ricostruiti in componenti ad alta frequenza (IMFH), frequenza intermedia (IMFM), bassa frequenza (IMFL) e termine di tendenza (IMFT), che riflettono diversi aspetti del FMI .
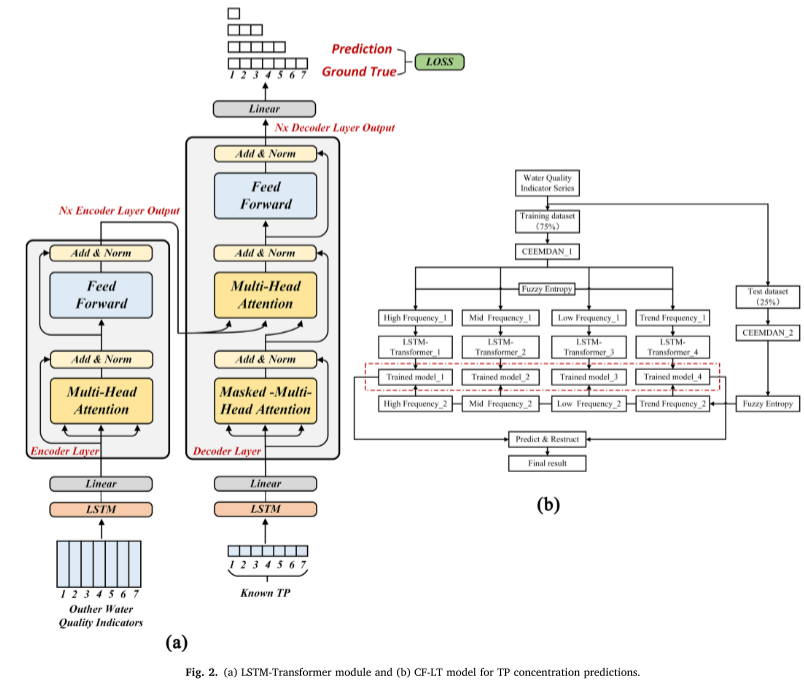
Per la parte LSTM-Transformer, nel codificatore e nel decodificatore, lo strato nascosto di LSTM è sostituito dalla codifica della posizione del trasformatore per stabilire la dipendenza temporale tra i dati di input. Il processo di calcolo specifico è il seguente (Figura 2a).
SHAP è un metodo della teoria dei giochi per interpretare l'output di qualsiasi modello ML.Per determinare l'impatto delle funzionalità di input sull'output del modello, le funzionalità di input z = z 1 , . . . , zp] z = [z1, ..., zp]lo=[lo1,...,loP]Relativo al modello di deep learning addestrato F.
F = f ( z ) = ϕ 0 + ∑ i = 1 M ϕ izi (12) F=f(z)=phi_0+sum_{i=1}^M phi_iz_i tag{12}F=F(lo)=ϕ0+ioooooooooooooooooo=1∑Mϕiooooooooooooooooooloioooooooooooooooooo(12)
φi ∈ R φ_i ∈ Rφioooooooooooooooooo∈RIndica il contributo di ciascuna caratteristica al modello, che è dato dalla seguente formula:
ϕ i ( F , x ) = ∑ z ≤ x ∣ z ∣ ! ( M − ∣ z ∣ − 1 ) ! M ! [ F ( z ) − F ( z / i ) ] (13) phi_i(F,x)=somma_{zleq x}frazione{|z|!(M-|z|-1)!}{M!}[F(z)-F(z/i)] tag{13}ϕioooooooooooooooooo(F,X)=lo≤X∑M!∣lo∣!(M−∣lo∣−1)
Lo studio propone un nuovo modello per prevedere le concentrazioni totali di fosforo. Il modello combina le tecnologie CEEM DAN, FE, LSTM e Transformer e utilizza SHAP per interpretare l'output del modello. L'obiettivo principale di questo studio è valutare le prestazioni del modello CEEMDAN-FE-LSTM-Transformer (CF-LT) proposto nel prevedere la concentrazione di TP all'ingresso del Lago Tai e applicare SHAP per interpretare l'output del CF-LT modello. Ciò dovrebbe rivelare i fattori chiave che influenzano la concentrazione di TP nella regione e i loro meccanismi di risposta.
La scomposizione dei dati ad alta dimensione può produrre un gran numero di componenti modali. Per risolvere questo problema, è possibile combinare con CEEMDAN il metodo Fuzzy Entropy (FE), un metodo efficiente per il calcolo della complessità temporale. Questa combinazione ricostruisce efficacemente i sottosegnali scomposti CEEMDAN, riducendo così il numero di modelli di sottofrequenza.
I modelli LSTMTransformer possono acquisire relazioni tra punti temporali non adiacenti preservando le caratteristiche della serie temporale dei dati di input.
I modelli del trasformatore utilizzano meccanismi di attenzione per identificare le correlazioni tra due posizioni in un contesto specifico durante l'addestramento. Ciò consente un'acquisizione efficiente dei dati rilevanti e riduce la ridondanza delle informazioni.
I principali contributi di questo articolo riguardano quattro aspetti:
insieme di dati : Il bacino del lago Taihu si trova nel corso inferiore del fiume Yangtze, coprendo un'area di 36.900 chilometri quadrati, con una fitta rete fluviale e numerosi laghi. Il lago Taihu è un tipico lago poco profondo. Il bacino ha le caratteristiche di un clima subtropicale settentrionale umido, con una temperatura media annua di 15-17°C e una precipitazione media annua di 1181 mm. Questo studio ha utilizzato i dati di monitoraggio della qualità dell'acqua provenienti dalla stazione Yaoxiangqiao, dalla stazione Zhihugang e dalla stazione Guanduqiao (Figura S2). Queste stazioni di monitoraggio si trovano a Taihukou, una sezione nazionale chiave per la valutazione della qualità dell'acqua. I dati provengono dal Centro di monitoraggio ambientale provinciale di Jiangsu.
Criteri di valutazione : La valutazione delle prestazioni del modello utilizza diversi indicatori chiave: coefficiente di determinazione (R²), errore quadratico medio (MSE) ed errore percentuale assoluto medio (MAPE). R² misura il grado di adattamento tra il valore previsto del modello e il valore effettivo. Vicino a 1 indica che il modello ha una forte capacità di previsione; MSE misura la somma dei quadrati dell'errore di previsione. MAPE riflette la dimensione dell'errore di previsione da una prospettiva percentuale. Il valore inferiore indica previsioni più accurate.
Dettagli di implementazione : Il processo sperimentale include la preelaborazione dei dati, l'addestramento e il test del modello. Viene stabilita una procedura sperimentale completa per valutare le prestazioni del modello proposto su diversi set di dati e finestre temporali di previsione. Innanzitutto, i dati vengono preelaborati dal metodo CEEMDAN-FE, che rimuove l'interferenza delle informazioni aggiungendo una scomposizione in modalità empirica completamente integrata con rumore adattivo, estrae informazioni multiscala e utilizza l'entropia fuzzy per ridurre il numero di sottosegnali. Successivamente, i dati elaborati vengono suddivisi in set di addestramento e set di test in proporzioni del 75% e 25%. Nella fase di addestramento, il set di dati di addestramento preelaborato viene immesso nel modello LSTM-Transformer. Utilizza la backpropagation e l'ottimizzatore Adam per aggiornare i pesi del modello e utilizza la ricerca nella griglia per identificare i migliori iperparametri del modulo LSTMTransformer per garantire le prestazioni del modello in diverse finestre temporali di previsione (7 giorni, 5 giorni, 3 giorni, 1 giorno) ottimali.
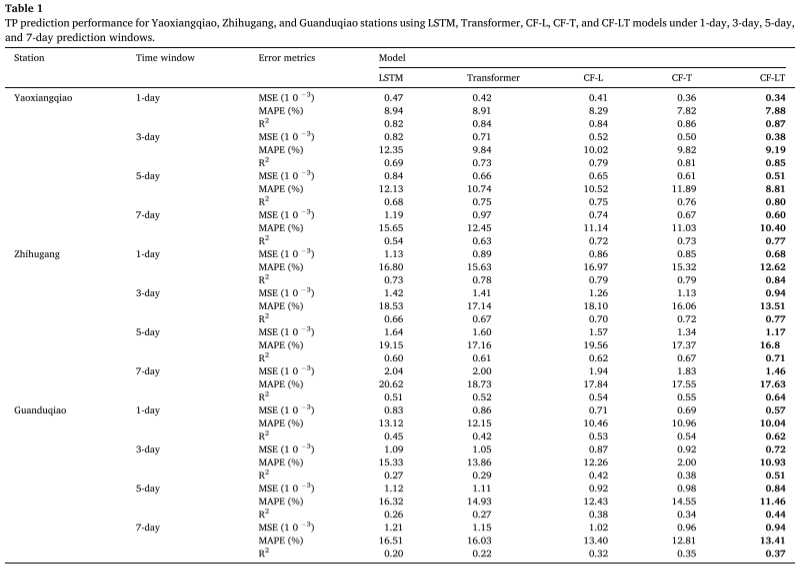
Risultati sperimentali : Applicando il miglior modello di addestramento al set di dati del test, la tabella riassume le previsioni di concentrazione di TP fornite dai modelli CF-LT, LSTM, Transformer, CF-L e CF-T in diversi siti e diverse finestre temporali di previsione. Il modello CF-LT proposto fornisce i migliori risultati per tutti e tre i parametri di valutazione. In termini di R2, il modello CF-LT varia da 0,37 a 0,87, mentre i successivi migliori modelli CF-L e CF-T sono rispettivamente 0,32-0,84 e 0,35-0,86. Ciò dimostra che la combinazione della memoria a lungo termine di LSTM con il meccanismo di attenzione di Transformer può migliorare l’accuratezza della previsione. Confrontando i peggiori modelli LSTM e Transformer con i modelli CF-L e CF-T, il MAPE varia da 8,94%-20,62% (LSTM) e 8,91%-18,73% (Transformer) a 8,29%-19,56% (CF -L) e 7,82%-17,55% (CF-T). Questi risultati dimostrano che la scomposizione dei dati e la modellazione della divisione di frequenza migliorano significativamente l’accuratezza della previsione acquisendo più informazioni nascoste nei dati originali.
Previsione dei fattori che influenzano la concentrazione totale di fosforo TP:
Il valore SHAP assoluto medio (MASV) viene utilizzato per quantificare il contributo delle caratteristiche di input (WT, PH, DO, COD, EC, TU, TN, NH3-N, TP) ai risultati della previsione TP maggiore è l'impatto sui risultati della previsione del modello. La ricerca mostra che oltre alle serie di concentrazioni di TP passate, l’azoto totale (TN) e la torbidità (TU) sono i due fattori principali che influenzano la previsione del TP. Ciò dimostra che i cambiamenti nel TP non sono solo direttamente influenzati dalle concentrazioni storiche, ma sono anche strettamente correlati alle dinamiche di crescita delle alghe associate alle emissioni di inquinamento da fonti non puntuali e al rapporto azoto-fosforo nel corpo idrico. In particolare, la correlazione significativa tra TN e TP enfatizza l’effetto di accoppiamento dei due nel ciclo dei nutrienti del lago ed evidenzia l’importanza dell’input di azoto da fonti non puntuali per la previsione della concentrazione di fosforo.
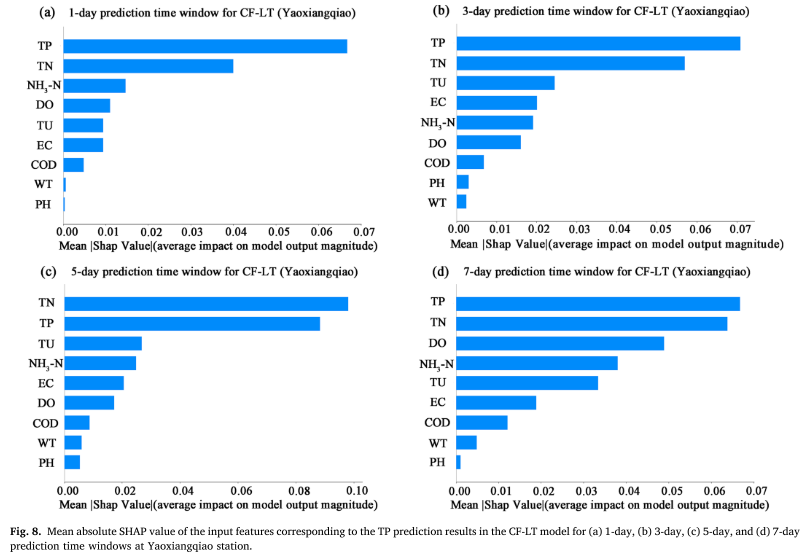
Da questi risultati si possono fare le seguenti osservazioni:
Confronto con il debiasing e la regolarizzazione del contraddittorio : suddiviso casualmente 50%/25%/25% per set di dati di training, convalida e test. La Figura 2 mostra le curve Pareto ottimali per tutti i metodi, dove il punto nell'angolo in basso a destra rappresenta la prestazione ideale (massima precisione e deviazione di previsione minima).
Il modello ibrido CF-LT proposto in questo articolo combina i moduli CEEM DAN, FE, LSTM e Transformer per prevedere la concentrazione di TP nelle acque superficiali. Questo approccio ibrido risolve i limiti dell’overfitting e dell’underfitting del modello causati da dati ad alta dimensionalità e dall’incapacità di stabilire dipendenze a lungo termine tra i dati quando si effettuano previsioni a lungo termine. Inoltre, i valori SHAP vengono utilizzati per interpretare l'output del modello CF-LT.
Il modello utilizza i dati provenienti da tre stazioni di monitoraggio della qualità dell'acqua nel bacino del lago Taihu per produrre 9 indicatori di qualità dell'acqua in diverse finestre temporali di previsione. Come modelli di controllo vengono utilizzati gli algoritmi LSTM, Transformer, CF-L e CF-T. Il modello CF-LT ha un valore R2 di 0,37–0,87, un valore MSE di 0,34 × 10−3–1,46 × 10−3 e un valore MAPE di 7,88%–17,63% sul set di dati di test, indicando che tutti e tre gli indicatori sono migliori dei risultati LSTM, Transformer, CF-L e CF-T. Il modello CF-LT proposto ha anche prodotto i migliori risultati di previsione dei picchi. Sulla base dell'interpretazione SHAP, abbiamo scoperto che TU e TN (escluse le prime serie temporali della concentrazione di TP) sono fattori importanti che influenzano la previsione di TP, il che indica che i cambiamenti in TP non sono solo correlati ai primi livelli di concentrazione di TP, ma sono anche influenzati da TP concentrazione. La relazione tra le emissioni di inquinamento da fonti non puntuali e le piante acquatiche nell'estuario del lago Taihu. Inoltre, vale la pena notare che TN e TU contribuiscono maggiormente alla previsione della concentrazione di TP nella stagione delle piogge. Pertanto, i risultati di questo studio indicano che il modello CF-LT fornisce informazioni aggiuntive per comprendere il meccanismo di risposta del TP quando cambiano le diverse condizioni ambientali.
Preelaborazione dati CEEMDAN e FE
def ceemdan_fe_preprocessing(data):
# CEEMDAN分解
imfs, residue = ceemdan(data, **ceemdan_params)
# 计算各个IMF的模糊熵
fe_values = []
for imf in imfs:
fe_values.append(fuzzy_entropy(imf)) # 假定fuzzy_entropy为计算模糊熵的函数
# 根据FE值重组IMFs
imfs_sorted = [imf for _, imf in sorted(zip(fe_values, imfs))]
imf_hf, imf_mf, imf_lf, imf_trend = imfs_sorted[:4], imfs_sorted[4:8], imfs_sorted[8:12], imfs_sorted[12:]
return np.concatenate((imf_hf, imf_mf, imf_lf, imf_trend), axis=1)
# 应用到数据上
preprocessed_data = ceemdan_fe_preprocessing(original_data)
LSTM e Trasformatore
def get_positional_encoding(max_len, d_model):
pe = np.zeros((max_len, d_model))
position = np.arange(0, max_len).reshape(-1, 1)
div_term = np.exp(np.arange(0, d_model, 2) * -(np.log(10000.0) / d_model))
pe[:, 0::2] = np.sin(position * div_term)
pe[:, 1::2] = np.cos(position * div_term)
return pe
def transformer_encoder(inputs, d_model, num_heads, ff_dim):
x = MultiHeadAttention(num_heads=num_heads, key_dim=d_model)(inputs, inputs)
x = LayerNormalization()(Add()([inputs, x]))
x = Dense(ff_dim, activation='relu')(x)
x = Dense(d_model)(x)
x = LayerNormalization()(Add()([inputs, x]))
return x
def transformer_decoder(inputs, encoder_outputs, d_model, num_heads, ff_dim):
return decoder_output
input_features = Input(shape=(input_shape))
lstm_out = LSTM(lstm_units)(input_features) # LSTM
pos_encodings = get_positional_encoding(max_seq_length, d_model)
transformer_in = Add()([lstm_out, pos_encodings])
transformer_encoded = transformer_encoder(transformer_in, d_model, num_heads, ff_dim)
decoder_output = transformer_decoder(decoder_input, transformer_encoded, d_model, num_heads, ff_dim)
output_layer = Dense(output_dim, activation='linear')(decoder_output)
model = Model(inputs=input_features, outputs=output_layer)
model.compile(optimizer=Adam(learning_rate), loss='mse')
Questo studio ha sviluppato un modello ibrido interpretabile CEEMDAN-FE-LSTM-Transformer per la previsione della concentrazione totale di fosforo nelle acque superficiali. Il modello ha migliorato significativamente l'accuratezza della previsione attraverso la fusione di tecnologia avanzata di preelaborazione dei dati e modelli di deep learning e fornisce una chiara spiegazione delle caratteristiche. tramite SHAP. I risultati sperimentali hanno confermato l’efficacia del modello, in particolare l’identificazione dei fattori ambientali chiave, fornendo un potente strumento per la gestione dell’eutrofizzazione dei corpi idrici e il controllo dell’inquinamento.
[1] Rivista di idrologia Volume 629, febbraio 2024, 130609

Si dedica alla ricerca tecnologica da più di 30 anni ed è esperto in vari linguaggi come Java, Linux, Javascript, php, css, ecc. Ha dato numerosi contributi nel campo dell'open source stazione di documentazione per gli sviluppatori per condividere alcuni problemi nello sviluppo della tecnologia per riferimento futuro

Posta[email protected]