
моя контактная информация
Почтамезофия@protonmail.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
На этой неделе я прочитал статью под названием «Интерпретируемая гибридная модель CEEMDAN-FE-LSTM для прогнозирования общей концентрации фосфора в поверхностных водах». В этой статье предлагается гибридная модель прогнозирования TP. В этой статье предлагается гибридная модель прогнозирования TP, а именно модель CF-LT. Модель инновационным образом сочетает в себе полностью интегрированную декомпозицию эмпирических мод (EMD) с адаптивной обработкой шума, нечетким энтропийным анализом, сетью долгосрочной краткосрочной памяти (LSTM) и технологией Transformer. Благодаря внедрению технологии реконструкции с частотным разделением данных эта модель эффективно решает проблемы переобучения и недостаточного подбора, которые могут возникнуть, когда традиционные модели машинного обучения имеют дело с многомерными данными. В то же время применение механизма внимания позволяет модели CF-LT преодолеть ограничения других моделей, которым сложно установить долгосрочные зависимости между данными при составлении долгосрочных прогнозов. Результаты прогнозирования показывают, что модель CF-LT достигла коэффициента детерминации (R2) от 0,37 до 0,87 на тестовом наборе данных, что представляет собой значительное улучшение от 0,05 до 0,17 (т.е. от 6% до 85%) по сравнению с контролем. модель. Кроме того, модель CF-LT также показала лучшую производительность прогнозирования пиков.
Еженедельная газета этой недели расшифровывает статью под названием «Интерпретируемая гибридная модель CEEMDAN-FE-LSTM-transformer для прогнозирования общей концентрации фосфора в поверхностных водах». В этой статье представлена гибридная модель CF-LT, специально предназначенная для прогнозирования TP. Модель инновационно объединяет полную ансамблевую эмпирическую модовую декомпозицию (EMD) с адаптивной обработкой шума, нечетким энтропийным анализом, сетями с долговременной краткосрочной памятью (LSTM) и технологией Transformer. Вводя частотное разделение и реконструкцию данных, CF-LT эффективно решает проблемы переобучения и недообучения, с которыми часто сталкиваются традиционные модели машинного обучения при работе с данными высокой размерности. Кроме того, применение механизма внимания позволяет CF-LT преодолевать ограничения других моделей при установлении долгосрочных зависимостей между точками данных во время долгосрочных прогнозов. Результаты прогнозирования показывают, что CF-LT достигает коэффициента решения (R2) в диапазоне от 0,37 до 0,87 на тестовых наборах данных, что представляет собой значительное улучшение от 0,05 до 0,17 (или от 6% до 85%) по сравнению с контрольными моделями. Кроме того, CF-LT обеспечивает наилучшую пиковую производительность прогнозирования.
Подробнее: Интерпретируемая гибридная модель CEEMDAN-FE-LSTM-transformer для прогнозирования общей концентрации фосфора в поверхностных водах
Автор: Цзефу Яо, Шуай Чен, Сяохун Жуань
выпускать:Журнал гидрологии Том 629, Февраль 2024, 130609
Источник: https://www.sciencedirect.com/science/article/pii/S0022169424000039?via%3Dihub
В этой статье предлагается гибридная модель прогнозирования TP. Эта модель (CF-LT) сочетает в себе полностью интегрированную декомпозицию эмпирического режима (EMD) с адаптивным шумом, нечеткой энтропией, длинной кратковременной памятью и трансформатором.Реконструкция частотного разделения данныхВнедрение эффективно решает проблемы переобучения и недостаточного подбора, которые возникали, когда предыдущие модели машинного обучения сталкивались с многомерными данными.механизм внимания Это решает проблему, заключающуюся в том, что эти модели не могут устанавливать долгосрочные зависимости между данными и делать долгосрочные прогнозы. Результаты прогнозирования показывают, что модель CF-LT достигает коэффициента детерминации (R2) 0,37–0,87 на тестовом наборе данных, что на 0,05–0,17 (6–85%) выше, чем у контрольной модели. Более того, модель CF-LT обеспечила лучший прогноз пиков.
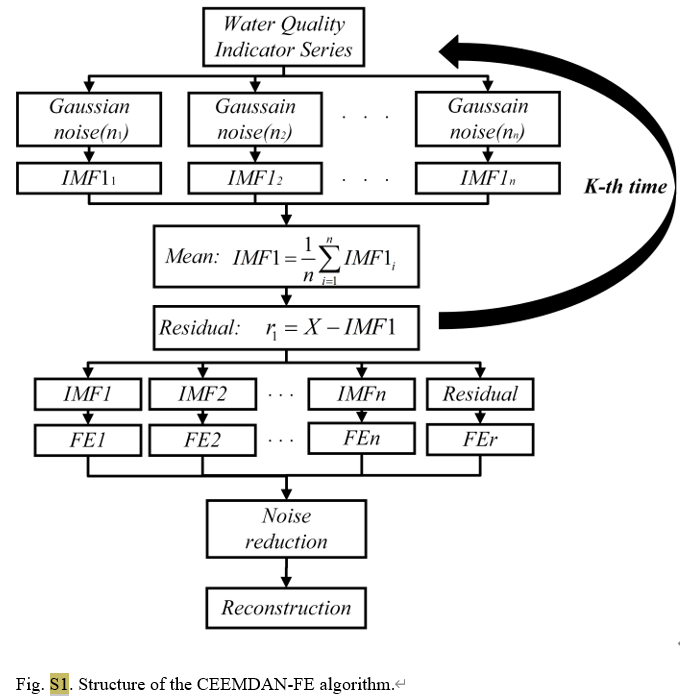
Являясь передовым методом анализа временных рядов, CEEMDAN эффективно уменьшает проблему наложения режимов, существующую в традиционном EMD, путем добавления адаптивного шума к процессу эмпирического разложения мод (EMD). Он может разложить исходный сигнал на ряд внутренних функций режима (IMF). Каждая IMF представляет различные временные характеристики сигнала, что делает анализ сложных сигналов более интуитивным и точным. В этом исследовании CEEMDAN использовался для обработки ежедневных данных о качестве воды с трех станций мониторинга на озере Тай, разделяя общую концентрацию фосфора и другие параметры качества воды, такие как температура воды, pH, растворенный кислород и т. д., на сигналы в разных частотных диапазонах.
Алгоритм S1: Полная ансамблевая эмпирическая модовая декомпозиция с адаптивным шумом (CEEMDAN)
yi ( t ) = y ( t ) + ϵ 0 vi ( t ) i = 1 , 2 , … , n (S1) y^{i}(t)=y(t)+epsilon_0v^i(t)quad i=1,2,точки,ntag{S1}уя(т)=у(т)+ϵ0вя(т)я=1,2,…,н(С1)
IMF1 i = E 0 ( yi ( t ) ) + r 1 i IMF1 ‾ = 1 n IMF1 i (S2) text{IMF1}_i=E_0(y^i(t))+r^i_1quad overline{text{IMF1}}=frac1ntext{IMF1}_itag{S2}МВФ1я=Э0(уя(т))+р1яМВФ1=н1МВФ1я(С2)
r 1 = yi ( t ) − IMF1 ‾ (S3) r_1=y^i(t)-overline{text{IMF1}}тег{S3}р1=уя(т)−МВФ1(С3)
IMF2 ‾ = 1 n ∑ i = 1 n E 1 ( r 1 + ϵ 1 E 1 ( vi ( t ) ) ) (S4) overline{text{IMF2}}=frac1nsum^n_{i=1}E_1(r_1+epsilon_1E_1(v^i(t))) тег{S4}МВФ2=н1я=1∑нЭ1(р1+ϵ1Э1(вя(т)))(С4)
y ( t ) = ∑ l = 1 K − 1 IMF1 ‾ + r K (S5) y(t)=sum^{K-1}_{l=1}overline{text{IMF1}}+r_Ktag{S5}у(т)=л=1∑К−1МВФ1+рК(С5)
Что касается части CEEMDAN-FE, мы сначала делим исходный набор данных на наборы обучающих и тестовых данных, а затем применяем CEEMDAN для разложения каждого объекта в двух наборах данных на несколько функций внутреннего режима (IMF). По близости значений КЭ каждого МВФ они реконструируются на высокочастотную (МВФГ), среднечастотную (МВФМ), низкочастотную (ИМФЛ) и трендовую (ИМФТ) составляющие, отражающие разные аспекты. МВФ.
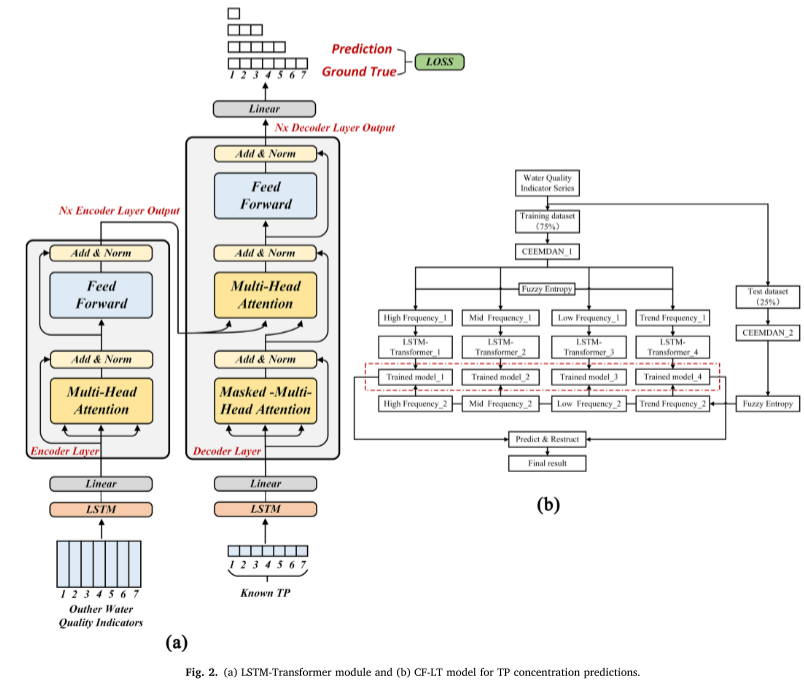
Для части LSTM-Transformer в кодере и декодере скрытый уровень LSTM заменяется кодированием положения трансформатора, чтобы установить временную зависимость между входными данными. Конкретный процесс расчета выглядит следующим образом (рис. 2а).
SHAP — это метод теории игр для интерпретации результатов любой модели ML.Чтобы определить влияние входных функций на выходные данные модели, входные функции z = [ z 1 , . . . , zp ] z = [z1, ..., zp]з=[з1,...,зп]Что касается обученной модели глубокого обучения F.
F = f ( z ) = ϕ 0 + ∑ i = 1 M ϕ izi (12) F=f(z)=phi_0+sum_{i=1}^M phi_iz_i тег{12}Ф=ф(з)=ϕ0+я=1∑Мϕязя(12)
φ i ∈ R φ_i ∈ Rφя∈рУказывает вклад каждой функции в модель, который определяется следующей формулой:
ϕ i ( F , x ) = ∑ z ≤ x ∣ z ∣ ! ( M − ∣ z ∣ − 1 ) ! M ! [ F ( z ) − F ( z / i ) ] (13) phi_i(F,x)=sum_{zleq x}frac{|z|!(M-|z|-1)!}{M!}[F(z)-F(z/i)] тег{13}ϕя(Ф,Икс)=з≤Икс∑М!∣з∣!(М−∣з∣−1)
В исследовании предлагается новая модель для прогнозирования концентрации общего фосфора. Модель сочетает в себе технологии CEEM DAN, FE, LSTM и Transformer и использует SHAP для интерпретации результатов модели. Основная цель этого исследования — оценить эффективность предлагаемой модели CEEMDAN-FE-LSTM-Transformer (CF-LT) при прогнозировании концентрации TP на входе в озеро Тай и применить SHAP для интерпретации выходных данных CF-LT. модель. Это должно выявить ключевые факторы, влияющие на концентрацию ТП в регионе, и механизмы их реагирования.
Многомерная декомпозиция данных может создавать большое количество модальных компонентов. Чтобы решить эту проблему, можно объединить нечеткую энтропию (FE), эффективный метод расчета временной сложности, с CEEMDAN. Эта комбинация эффективно восстанавливает разложенные подсигналы CEEMDAN, тем самым уменьшая количество подчастотных моделей.
Модели LSTMTransformer могут фиксировать отношения между несмежными точками времени, сохраняя при этом характеристики временных рядов входных данных.
Модели-трансформеры используют механизмы внимания для выявления корреляций между двумя местоположениями в определенном контексте во время обучения. Это обеспечивает эффективный сбор соответствующих данных и снижает избыточность информации.
Основной вклад этой статьи заключается в четырех аспектах:
набор данных : Бассейн озера Тайху расположен в нижнем течении реки Янцзы, занимает площадь 36 900 квадратных километров, с густой речной сетью и многочисленными озерами. Озеро Тайху — типичное мелководное озеро. Бассейн имеет характеристики влажного климата северной субтропической зоны со среднегодовой температурой 15-17°С и среднегодовым количеством осадков 1181 мм. В этом исследовании использовались данные мониторинга качества воды со станций Яосянцяо, Чжихуган и Гуандуцяо (рисунок S2). Эти станции мониторинга расположены в Тайхукоу, ключевом национальном участке оценки качества воды. Данные предоставлены Центром экологического мониторинга провинции Цзянсу.
Критерии оценки : Оценка производительности модели использует несколько ключевых показателей: коэффициент детерминации (R²), среднеквадратическую ошибку (MSE) и среднюю абсолютную процентную ошибку (MAPE). R² измеряет степень соответствия между прогнозируемым значением модели и фактическим значением. Значение, близкое к 1, указывает на то, что модель имеет высокую способность прогнозирования; MSE измеряет сумму квадратов ошибки прогнозирования. MAPE отражает размер ошибки прогноза в процентном отношении. Значение «Нижнее» означает более точные прогнозы.
Детали реализации : Экспериментальный процесс включает предварительную обработку данных, обучение и тестирование модели. Установлена полная экспериментальная процедура для оценки эффективности предлагаемой модели на различных наборах данных и временных окнах прогнозирования. Во-первых, данные предварительно обрабатываются методом CEEMDAN-FE, который устраняет информационную интерференцию за счет добавления полностью интегрированного разложения по эмпирическим модам с адаптивным шумом, извлекает многомасштабную информацию и использует нечеткую энтропию для уменьшения количества субсигналов. Далее обработанные данные делятся на обучающую и тестовую выборку в пропорциях 75% и 25%. На этапе обучения предварительно обработанный набор обучающих данных вводится в модель LSTM-Transformer. Используйте обратное распространение ошибки и оптимизатор Адама для обновления весов модели, а также используйте поиск по сетке для определения лучших гиперпараметров модуля LSTMTransformer, чтобы обеспечить оптимальную производительность модели в различных временных окнах прогнозирования (7 дней, 5 дней, 3 дня, 1 день).
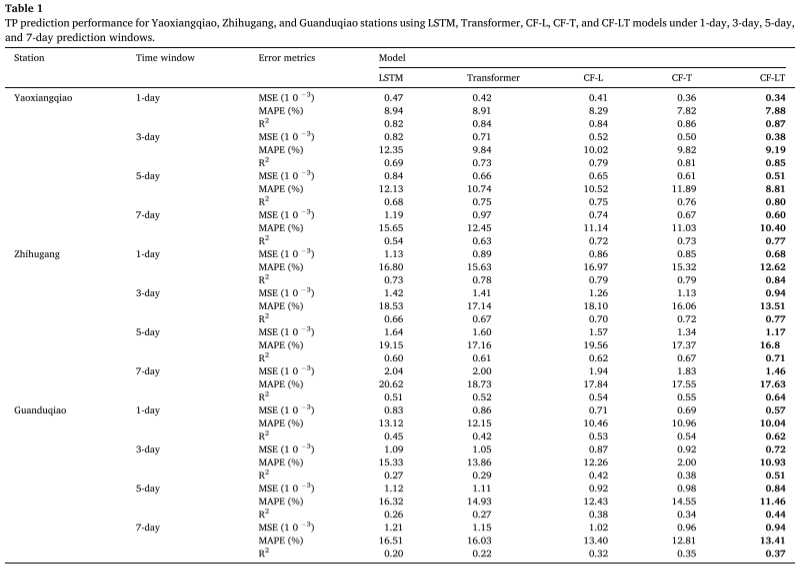
Результаты эксперимента : Применяя лучшую обучающую модель к набору тестовых данных, в таблице суммируются прогнозы концентрации TP, данные моделями CF-LT, LSTM, Transformer, CF-L и CF-T на разных участках и в разных временных окнах прогнозирования. Предложенная модель CF-LT дает наилучшие результаты по всем трем показателям оценки. Что касается R2, модель CF-LT находится в диапазоне от 0,37 до 0,87, тогда как следующие лучшие модели CF-L и CF-T составляют 0,32-0,84 и 0,35-0,86 соответственно. Это показывает, что сочетание долговременной памяти LSTM с механизмом внимания Transformer может повысить точность прогнозирования. При сравнении худших моделей LSTM и Transformer с моделями CF-L и CF-T MAPE колеблется от 8,94%-20,62% (LSTM) и 8,91%-18,73% (Transformer) до 8,29%-19,56% (CF-L). и 7,82%-17,55% (CF-T). Эти результаты демонстрируют, что декомпозиция данных и моделирование с частотным разделением значительно повышают точность прогнозирования за счет сбора большего количества информации, скрытой в исходных данных.
Прогнозирование факторов, влияющих на концентрацию общего фосфора ТФ:
Среднее абсолютное значение SHAP (MASV) используется для количественной оценки вклада входных характеристик (WT, PH, DO, COD, EC, TU, TN, NH3-N, TP) в результаты прогнозирования TP. Чем больше MASV, тем больше. большее влияние на результаты прогнозирования модели. Чем больше. Исследования показывают, что в дополнение к самим прошлым рядам концентраций TP, общий азот (TN) и мутность (TU) являются двумя основными факторами, влияющими на прогнозирование TP. Это показывает, что на изменения TP не только напрямую влияют исторические концентрации, но они также тесно связаны с динамикой роста водорослей, связанной с выбросами загрязнения из неточечных источников и соотношением азота и фосфора в водоеме. В частности, значительная корреляция между TN и TP подчеркивает эффект связи этих двух факторов в круговороте питательных веществ в озере и подчеркивает важность поступления азота из неточечных источников для прогнозирования концентрации фосфора.
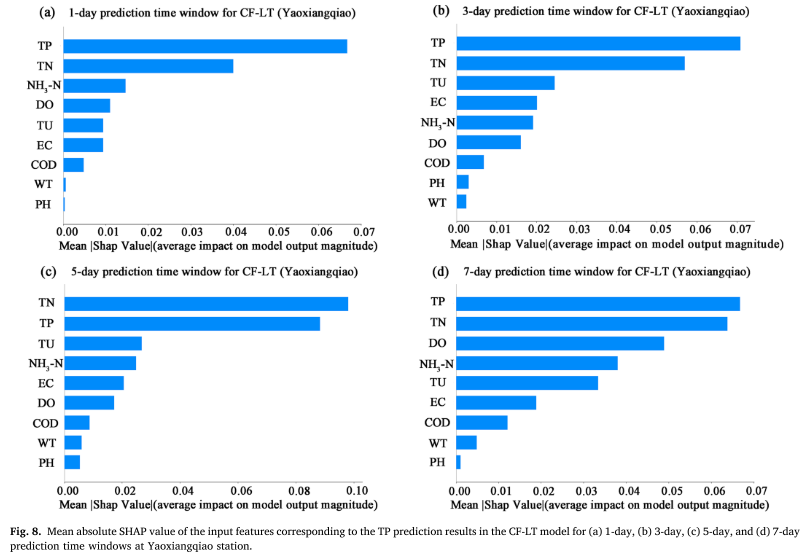
По этим результатам можно сделать следующие наблюдения:
Сравнение с состязательным смещением и регуляризацией : Случайное разделение 50%/25%/25% для наборов данных обучения, проверки и тестирования. На рисунке 2 показаны оптимальные по Парето кривые для всех методов, где нижняя правая угловая точка представляет идеальную производительность (наивысшую точность и наименьшее отклонение прогноза).
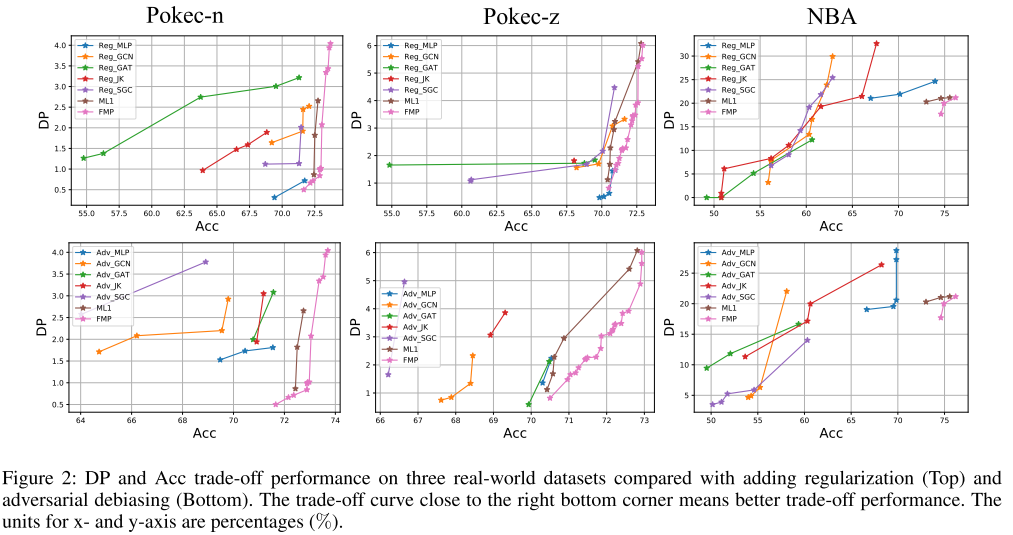
Гибридная модель CF-LT, предложенная в этой статье, объединяет модули CEEM DAN, FE, LSTM и Transformer для прогнозирования концентрации TP в поверхностных водах. Этот гибридный подход решает недостатки переоснащения и недостаточного подбора модели, вызванные многомерными данными и невозможностью установить долгосрочные зависимости между данными при составлении долгосрочных прогнозов. Кроме того, значения SHAP используются для интерпретации результатов модели CF-LT.
Модель использует данные трех станций мониторинга качества воды в бассейне озера Тайху для вывода 9 показателей качества воды в различных временных окнах прогнозирования. В качестве моделей управления используются алгоритмы LSTM, Transformer, CF-L и CF-T. Модель CF-LT имеет значение R2 0,37–0,87, значение MSE 0,34 × 10–3–1,46 × 10–3 и значение MAPE 7,88–17,63% в наборе тестовых данных, что указывает на то, что все три показатели лучше, чем результаты LSTM, Transformer, CF-L и CF-T. Предложенная модель CF-LT также дала лучшие результаты прогнозирования пиков. Основываясь на интерпретации SHAP, мы обнаружили, что TU и TN (исключая ранние временные ряды концентрации TP) являются важными факторами, влияющими на прогнозирование TP, что указывает на то, что изменения TP не только связаны с ранними уровнями концентрации TP, но также зависят от TP. концентрация. Взаимосвязь между выбросами загрязнения из неточечных источников и водными растениями в устье озера Тайху. Кроме того, стоит отметить, что TN и TU больше способствуют прогнозу концентрации ТП в сезон дождей. Таким образом, результаты этого исследования показывают, что модель CF-LT предоставляет дополнительную информацию для понимания механизма реакции TP при изменении различных условий окружающей среды.
Предварительная обработка данных CEEMDAN и FE
def ceemdan_fe_preprocessing(data):
# CEEMDAN分解
imfs, residue = ceemdan(data, **ceemdan_params)
# 计算各个IMF的模糊熵
fe_values = []
for imf in imfs:
fe_values.append(fuzzy_entropy(imf)) # 假定fuzzy_entropy为计算模糊熵的函数
# 根据FE值重组IMFs
imfs_sorted = [imf for _, imf in sorted(zip(fe_values, imfs))]
imf_hf, imf_mf, imf_lf, imf_trend = imfs_sorted[:4], imfs_sorted[4:8], imfs_sorted[8:12], imfs_sorted[12:]
return np.concatenate((imf_hf, imf_mf, imf_lf, imf_trend), axis=1)
# 应用到数据上
preprocessed_data = ceemdan_fe_preprocessing(original_data)
LSTM&Трансформатор
def get_positional_encoding(max_len, d_model):
pe = np.zeros((max_len, d_model))
position = np.arange(0, max_len).reshape(-1, 1)
div_term = np.exp(np.arange(0, d_model, 2) * -(np.log(10000.0) / d_model))
pe[:, 0::2] = np.sin(position * div_term)
pe[:, 1::2] = np.cos(position * div_term)
return pe
def transformer_encoder(inputs, d_model, num_heads, ff_dim):
x = MultiHeadAttention(num_heads=num_heads, key_dim=d_model)(inputs, inputs)
x = LayerNormalization()(Add()([inputs, x]))
x = Dense(ff_dim, activation='relu')(x)
x = Dense(d_model)(x)
x = LayerNormalization()(Add()([inputs, x]))
return x
def transformer_decoder(inputs, encoder_outputs, d_model, num_heads, ff_dim):
return decoder_output
input_features = Input(shape=(input_shape))
lstm_out = LSTM(lstm_units)(input_features) # LSTM
pos_encodings = get_positional_encoding(max_seq_length, d_model)
transformer_in = Add()([lstm_out, pos_encodings])
transformer_encoded = transformer_encoder(transformer_in, d_model, num_heads, ff_dim)
decoder_output = transformer_decoder(decoder_input, transformer_encoded, d_model, num_heads, ff_dim)
output_layer = Dense(output_dim, activation='linear')(decoder_output)
model = Model(inputs=input_features, outputs=output_layer)
model.compile(optimizer=Adam(learning_rate), loss='mse')
В этом исследовании была разработана интерпретируемая гибридная модель CEEMDAN-FE-LSTM-Transformer для прогнозирования общей концентрации фосфора в поверхностных водах. Модель значительно повысила точность прогноза за счет сочетания передовых технологий предварительной обработки данных и моделей глубокого обучения, а также обеспечивает четкое объяснение функций. через ШАП. Результаты экспериментов подтвердили эффективность модели, особенно при выявлении ключевых факторов окружающей среды, что представляет собой мощный инструмент для управления эвтрофикацией водных объектов и контроля загрязнения.
[1] Журнал гидрологии Том 629, Февраль 2024, 130609

Он посвятил себя исследованию технологий более 30 лет и владеет различными языками, такими как Java, Linux, Javascript, php, css и т. д. Он внес большой вклад в область открытого исходного кода. Станция документации для разработчиков, где можно поделиться некоторыми проблемами в разработке технологий для дальнейшего использования. Все ознакомьтесь.

Почтамезофия@protonmail.com