
τα στοιχεία επικοινωνίας μου
Ταχυδρομείο[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Αυτή την εβδομάδα διάβασα μια εργασία με τίτλο Ερμηνευτικό υβριδικό μοντέλο μετασχηματιστή CEEMDAN-FE-LSTM για την πρόβλεψη συνολικών συγκεντρώσεων φωσφόρου στα επιφανειακά ύδατα. Αυτή η εργασία προτείνει ένα υβριδικό μοντέλο για την πρόβλεψη TP. Αυτή η εργασία προτείνει ένα υβριδικό μοντέλο για την πρόβλεψη TP, δηλαδή το μοντέλο CF-LT. Το μοντέλο συνδυάζει καινοτόμα την πλήρως ενσωματωμένη εμπειρική αποσύνθεση (EMD) με προσαρμοστική επεξεργασία θορύβου, ανάλυση ασαφούς εντροπίας, δίκτυο βραχυπρόθεσμης μνήμης (LSTM) και τεχνολογία Transformer. Με την εισαγωγή της τεχνολογίας ανακατασκευής διαίρεσης συχνότητας δεδομένων, αυτό το μοντέλο επιλύει αποτελεσματικά τα προβλήματα υπερβολικής προσαρμογής και υποπροσαρμογής που είναι πιθανό να προκύψουν όταν τα παραδοσιακά μοντέλα μηχανικής εκμάθησης ασχολούνται με δεδομένα υψηλών διαστάσεων. Ταυτόχρονα, η εφαρμογή του μηχανισμού προσοχής επιτρέπει στο μοντέλο CF-LT να ξεπεράσει τους περιορισμούς άλλων μοντέλων που είναι δύσκολο να δημιουργηθούν μακροπρόθεσμες εξαρτήσεις μεταξύ των δεδομένων όταν γίνονται μακροπρόθεσμες προβλέψεις. Τα αποτελέσματα πρόβλεψης δείχνουν ότι το μοντέλο CF-LT έφτασε σε συντελεστή προσδιορισμού (R2) από 0,37 έως 0,87 στο σύνολο δεδομένων δοκιμής, που ήταν σημαντική βελτίωση 0,05 έως 0,17 (δηλαδή, 6% έως 85%) σε σύγκριση με τον έλεγχο μοντέλο. Επιπλέον, το μοντέλο CF-LT έδειξε επίσης την καλύτερη απόδοση πρόβλεψης αιχμής.
Η εβδομαδιαία εφημερίδα αυτής της εβδομάδας αποκωδικοποιεί την εφημερίδα με τίτλο Ερμηνευτικό υβριδικό μοντέλο μετασχηματιστή CEEMDAN-FE-LSTM για την πρόβλεψη συνολικών συγκεντρώσεων φωσφόρου στα επιφανειακά νερά. Αυτή η εργασία εισάγει ένα υβριδικό μοντέλο, το CF-LT, ειδικά για την πρόβλεψη TP. Το μοντέλο ενσωματώνει καινοτόμα το Complete Ensemble Empirical Mode Decomposition (EMD) με προσαρμοστική επεξεργασία θορύβου, ανάλυση ασαφούς εντροπίας, δίκτυα Long Short-Term Memory (LSTM) και τεχνολογία Transformer. Με την εισαγωγή της διαίρεσης και της ανακατασκευής συχνότητας δεδομένων, το CF-LT αντιμετωπίζει αποτελεσματικά τα ζητήματα της υπερπροσαρμογής και της υποπροσαρμογής που αντιμετωπίζουν συχνά τα παραδοσιακά μοντέλα μηχανικής εκμάθησης όταν ασχολούνται με δεδομένα υψηλών διαστάσεων. Επιπλέον, η εφαρμογή του μηχανισμού προσοχής επιτρέπει στο CF-LT να ξεπεράσει τους περιορισμούς άλλων μοντέλων για τη δημιουργία μακροπρόθεσμων εξαρτήσεων μεταξύ σημείων δεδομένων κατά τη διάρκεια μακροπρόθεσμων προβλέψεων. Τα αποτελέσματα πρόβλεψης δείχνουν ότι το CF-LT επιτυγχάνει έναν συντελεστή απόφασης (R2) που κυμαίνεται από 0,37 έως 0,87 στα σύνολα δεδομένων δοκιμής, που αντιπροσωπεύει σημαντική βελτίωση από 0,05 έως 0,17 (ή 6% έως 85%) σε σύγκριση με τα μοντέλα ελέγχου. Επιπλέον, το CF-LT παρέχει την καλύτερη απόδοση πρόβλεψης αιχμής.
Ερμηνεύσιμο υβριδικό μοντέλο μετασχηματιστή CEEMDAN-FE-LSTM για την πρόβλεψη συνολικών συγκεντρώσεων φωσφόρου στα επιφανειακά ύδατα
Συγγραφέας: Jiefu Yao, Shuai Chen, Xiaohong Ruan
ελευθέρωση:Journal of Hydrology Τόμος 629, Φεβρουάριος 2024, 130609
链接:https://www.sciencedirect.com/science/article/pii/S0022169424000039?via%3Dihub
Αυτή η εργασία προτείνει ένα υβριδικό μοντέλο για την πρόβλεψη TP. Αυτό το μοντέλο (CF-LT) συνδυάζει πλήρως ενσωματωμένη Εμπειρική Αποσύνθεση Τρόπου (EMD) με προσαρμοστικό θόρυβο, ασαφή εντροπία, μακροπρόθεσμη μνήμη και μετασχηματιστή.Ανακατασκευή διαίρεσης συχνότητας δεδομένωνΗ εισαγωγή του επιλύει αποτελεσματικά τα προβλήματα υπερβολικής προσαρμογής και υποπροσαρμογής που εμφανίστηκαν όταν προηγούμενα μοντέλα μηχανικής εκμάθησης αντιμετώπιζαν δεδομένα υψηλών διαστάσεων.μηχανισμός προσοχής Αυτό ξεπερνά το πρόβλημα ότι αυτά τα μοντέλα δεν μπορούν να δημιουργήσουν μακροπρόθεσμες εξαρτήσεις μεταξύ των δεδομένων και να κάνουν μακροπρόθεσμες προβλέψεις. Τα αποτελέσματα πρόβλεψης δείχνουν ότι το μοντέλο CF-LT επιτυγχάνει συντελεστή προσδιορισμού (R2) 0,37-0,87 στο σύνολο δεδομένων δοκιμής, ο οποίος είναι 0,05-0,17 (6%-85%) υψηλότερος από το μοντέλο ελέγχου. Επιπλέον, το μοντέλο CF-LT παρείχε την καλύτερη πρόβλεψη κορυφής.
Ως προηγμένη μέθοδος ανάλυσης χρονοσειρών, το CEEMDAN μειώνει αποτελεσματικά το πρόβλημα αλιοποίησης τρόπου που υπάρχει στην παραδοσιακή EMD προσθέτοντας προσαρμοστικό θόρυβο στη διαδικασία αποσύνθεσης εμπειρικού τρόπου λειτουργίας (EMD). Μπορεί να αποσυνθέσει το αρχικό σήμα σε μια σειρά από εγγενείς λειτουργίες λειτουργίας (IMFs). Σε αυτή τη μελέτη, το CEEMDAN χρησιμοποιήθηκε για την επεξεργασία ημερήσιων δεδομένων ποιότητας νερού από τρεις σταθμούς παρακολούθησης στη λίμνη Tai, διαχωρίζοντας τη συγκέντρωση ολικού φωσφόρου και άλλες παραμέτρους ποιότητας του νερού όπως θερμοκρασία νερού, pH, διαλυμένο οξυγόνο κ.λπ. σε σήματα σε διαφορετικές ζώνες συχνοτήτων.
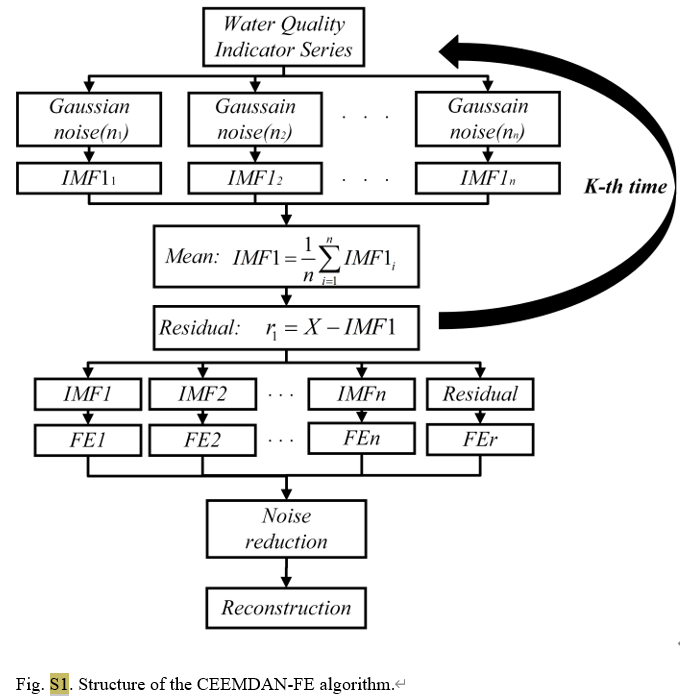
Αλγόριθμος S1: Ολοκληρωμένη αποσύνθεση εμπειρικής λειτουργίας συνόλου με προσαρμοστικό θόρυβο (CEEMDAN)
yi ( t ) = y ( t ) + ϵ 0 vi ( t ) i = 1 , 2 , … , n (S1) y^{i}(t)=y(t)+epsilon_0v^i(t)quad i =1,2,dots,tag{S1}yΕγώ(t)=y(t)+ϵ0vΕγώ(t)Εγώ=1,2,…,n(S1)
IMF1 i = E 0 ( yi ( t ) ) + r 1 i IMF1 ‾ = 1 n IMF1 i (S2) κείμενο{IMF1}_i=E_0(y^i(t))+r^i_1τετράγωνη επικάλυψη{κείμενο{IMF1} }=frac1ntext{IMF1}_itag{S2}ΔΝΤ 1Εγώ=μι0(yΕγώ(t))+r1ΕγώΔΝΤ 1=n1ΔΝΤ 1Εγώ(S2)
r 1 = yi ( t ) − IMF1 ‾ (S3) r_1=y^i(t)-overline{text{IMF1}}tag{S3}r1=yΕγώ(t)−ΔΝΤ 1(S3)
IMF2 ‾ = 1 n ∑ i = 1 n E 1 ( r 1 + ϵ 1 E 1 ( vi ( t ) ) ) (S4) overline{text{IMF2}}=frac1nsum^n_{i=1}E_1(r_1+ epsilon_1E_1(v^i(t))) ετικέτα{S4}ΔΝΤ2=n1Εγώ=1∑nμι1(r1+ϵ1μι1(vΕγώ(t)))(S4)
y ( t ) = ∑ l = 1 K − 1 IMF1 ‾ + r K (S5) y(t)=sum^{K-1}_{l=1}overline{text{IMF1}}+r_Ktag{S5}y(t)=μεγάλο=1∑κ−1ΔΝΤ 1+rκ(S5)
Για το τμήμα CEEMDAN-FE, πρώτα διαιρούμε το αρχικό σύνολο δεδομένων σε σύνολα δεδομένων εκπαίδευσης και δοκιμής και, στη συνέχεια, εφαρμόζουμε το CEEMDAN για να αποσυνθέσουμε κάθε χαρακτηριστικό στα δύο σύνολα δεδομένων σε πολλαπλές εγγενείς συναρτήσεις λειτουργίας (IMF). Σύμφωνα με την εγγύτητα των τιμών FE κάθε ΔΝΤ, ανακατασκευάζονται σε στοιχεία υψηλής συχνότητας (IMFH), ενδιάμεσης συχνότητας (IMFM), χαμηλής συχνότητας (IMFL) και όρου τάσης (IMFT), τα οποία αντικατοπτρίζουν διαφορετικές πτυχές του ΔΝΤ. .
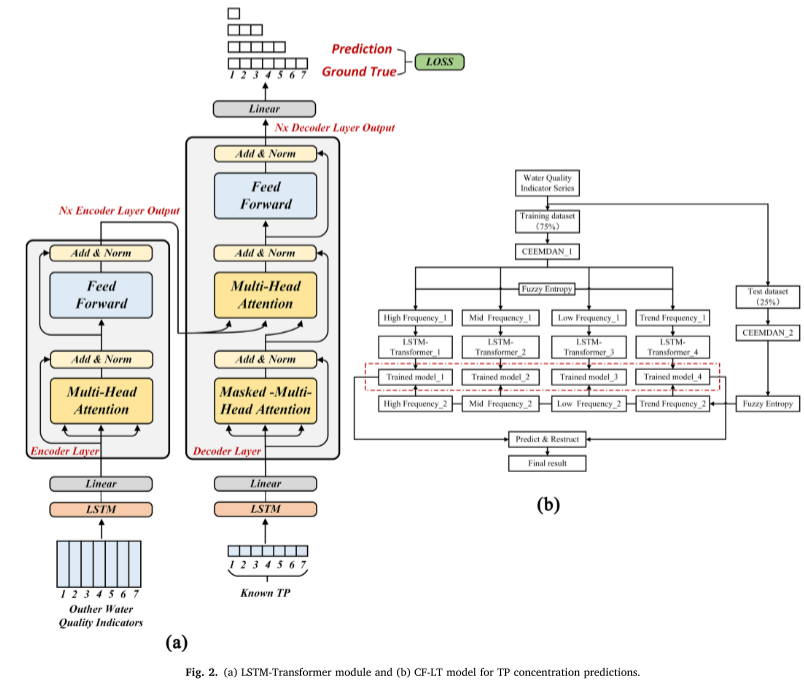
Για το τμήμα LSTM-Transformer, στον κωδικοποιητή και στον αποκωδικοποιητή, το κρυφό στρώμα του LSTM αντικαθίσταται από κωδικοποίηση θέσης μετασχηματιστή για να εδραιωθεί η χρονική εξάρτηση μεταξύ των δεδομένων εισόδου. Η συγκεκριμένη διαδικασία υπολογισμού έχει ως εξής (Εικόνα 2α).
Το SHAP είναι μια μέθοδος θεωρίας παιγνίων για την ερμηνεία της εξόδου οποιουδήποτε μοντέλου ML.Για να προσδιορίσετε την επίδραση των χαρακτηριστικών εισόδου στην έξοδο του μοντέλου, τα χαρακτηριστικά εισόδου z = [ z 1 , . . . , zp ] z = [z1, ..., zp]z=[z1,...,zΠ]Σχετίζεται με το εκπαιδευμένο μοντέλο βαθιάς μάθησης F.
F = f ( z ) = ϕ 0 + ∑ i = 1 M ϕ izi (12) F=f(z)=phi_0+sum_{i=1}^M phi_iz_i ετικέτα{12}φά=φά(z)=ϕ0+Εγώ=1∑ΜϕΕγώzΕγώ(12)
φ i ∈ R φ_i ∈ RφΕγώ∈RΥποδεικνύει τη συνεισφορά κάθε χαρακτηριστικού στο μοντέλο, η οποία δίνεται από τον ακόλουθο τύπο:
ϕ i ( F , x ) = ∑ z ≤ x ∣ z ∣ ! ( M − ∣ z ∣ − 1 ) ! Μ ! [ F ( z ) − F ( z / i ) ] (13) phi_i(F,x)=sum_{zleq x}frac{|z|!(M-|z|-1)!}{M!}[ Ετικέτα F(z)-F(z/i)]{13}ϕΕγώ(φά,Χ)=z≤Χ∑Μ!∣z∣!(Μ−∣z∣−1)
Η μελέτη προτείνει ένα νέο μοντέλο για την πρόβλεψη των συνολικών συγκεντρώσεων φωσφόρου. Το μοντέλο συνδυάζει τεχνολογίες CEEM DAN, FE, LSTM και Transformer και χρησιμοποιεί SHAP για να ερμηνεύσει την έξοδο του μοντέλου. Ο κύριος στόχος αυτής της μελέτης είναι να αξιολογήσει την απόδοση του προτεινόμενου μοντέλου CEEMDAN-FE-LSTM-Transformer (CF-LT) στην πρόβλεψη συγκέντρωσης TP στην είσοδο της λίμνης Tai και να εφαρμόσει το SHAP για να ερμηνεύσει την έξοδο του CF-LT μοντέλο. Αυτό θα πρέπει να αποκαλύψει τους βασικούς παράγοντες που επηρεάζουν τη συγκέντρωση ΤΡ στην περιοχή και τους μηχανισμούς απόκρισής τους.
Η αποσύνθεση δεδομένων υψηλών διαστάσεων μπορεί να παράγει μεγάλο αριθμό τροπικών στοιχείων. Για την επίλυση αυτού του προβλήματος, η Fuzzy Entropy (FE), μια αποτελεσματική μέθοδος για τον υπολογισμό της πολυπλοκότητας του χρόνου, μπορεί να συνδυαστεί με το CEEMDAN. Αυτός ο συνδυασμός αναδομεί αποτελεσματικά τα αποσυντιθέμενα υποσήματα CEEMDAN, μειώνοντας έτσι τον αριθμό των μοντέλων υποσυχνοτήτων.
Τα μοντέλα μετασχηματιστή LSTMT μπορούν να συλλάβουν σχέσεις μεταξύ μη γειτονικών χρονικών σημείων διατηρώντας παράλληλα τα χαρακτηριστικά χρονοσειρών των δεδομένων εισόδου.
Τα μοντέλα μετασχηματιστών χρησιμοποιούν μηχανισμούς προσοχής για τον εντοπισμό συσχετισμών μεταξύ δύο θέσεων σε ένα συγκεκριμένο πλαίσιο κατά τη διάρκεια της εκπαίδευσης. Αυτό επιτρέπει την αποτελεσματική απόκτηση σχετικών δεδομένων και μειώνει τον πλεονασμό πληροφοριών.
Οι κύριες συνεισφορές αυτού του άρθρου είναι σε τέσσερις πτυχές:
σύνολο δεδομένων : Η λεκάνη της λίμνης Taihu βρίσκεται στον κάτω ρου του ποταμού Yangtze, σε έκταση 36.900 τετραγωνικών χιλιομέτρων, με πυκνό δίκτυο ποταμών και πολυάριθμες λίμνες. Η λίμνη Taihu είναι μια τυπική ρηχή λίμνη. Η λεκάνη έχει τα χαρακτηριστικά ενός υγρού βόρειου υποτροπικού κλίματος, με μέση ετήσια θερμοκρασία 15-17°C και μέση ετήσια βροχόπτωση 1181 mm. Αυτή η μελέτη χρησιμοποίησε δεδομένα παρακολούθησης της ποιότητας του νερού από το σταθμό Yaoxiangqiao, τον σταθμό Zhihugang και τον σταθμό Guanduqiao (Εικόνα S2). Αυτοί οι σταθμοί παρακολούθησης βρίσκονται στο Taihukou, ένα εθνικό βασικό τμήμα αξιολόγησης της ποιότητας του νερού. Τα δεδομένα προέρχονται από το Επαρχιακό Κέντρο Περιβαλλοντικής Παρακολούθησης του Jiangsu.
Κριτήρια αξιολόγησης : Η αξιολόγηση απόδοσης του μοντέλου χρησιμοποιεί διάφορους βασικούς δείκτες: συντελεστής προσδιορισμού (R²), μέσο τετραγωνικό σφάλμα (MSE) και μέσο απόλυτο ποσοστό σφάλματος (MAPE). Το R² μετρά τον βαθμό προσαρμογής μεταξύ της προβλεπόμενης τιμής του μοντέλου και της πραγματικής τιμής, δείχνει ότι το μοντέλο έχει ισχυρή ικανότητα πρόβλεψης. Το MAPE αντικατοπτρίζει το μέγεθος του σφάλματος πρόβλεψης από την άποψη του ποσοστού Η τιμή Lower σημαίνει πιο ακριβείς προβλέψεις.
Λεπτομέρειες υλοποίησης : Η πειραματική διαδικασία περιλαμβάνει προεπεξεργασία δεδομένων, εκπαίδευση μοντέλων και δοκιμή. Καθιερώνεται μια πλήρης πειραματική διαδικασία για την αξιολόγηση της απόδοσης του προτεινόμενου μοντέλου σε διαφορετικά σύνολα δεδομένων και χρονικά παράθυρα πρόβλεψης. Πρώτον, τα δεδομένα προεπεξεργάζονται με τη μέθοδο CEEMDAN-FE, η οποία αφαιρεί τις παρεμβολές πληροφοριών προσθέτοντας πλήρως ενσωματωμένη εμπειρική αποσύνθεση με προσαρμοστικό θόρυβο, εξάγει πληροφορίες πολλαπλής κλίμακας και χρησιμοποιεί ασαφή εντροπία για τη μείωση του αριθμού των υποσημάτων. Στη συνέχεια, τα επεξεργασμένα δεδομένα χωρίζονται σε σετ εκπαίδευσης και σετ δοκιμών σε αναλογίες 75% και 25%. Στη φάση εκπαίδευσης, το προεπεξεργασμένο σύνολο δεδομένων εκπαίδευσης εισάγεται στο μοντέλο LSTM-Transformer. Χρησιμοποιήστε backpropagation και Adam optimizer για να ενημερώσετε τα βάρη μοντέλων και χρησιμοποιήστε την αναζήτηση πλέγματος για να εντοπίσετε τις καλύτερες υπερπαραμέτρους της μονάδας LSTMTtransformer για να διασφαλίσετε την απόδοση του μοντέλου σε διαφορετικά χρονικά παράθυρα πρόβλεψης (7 ημέρες, 5 ημέρες, 3 ημέρες, 1 ημέρα).
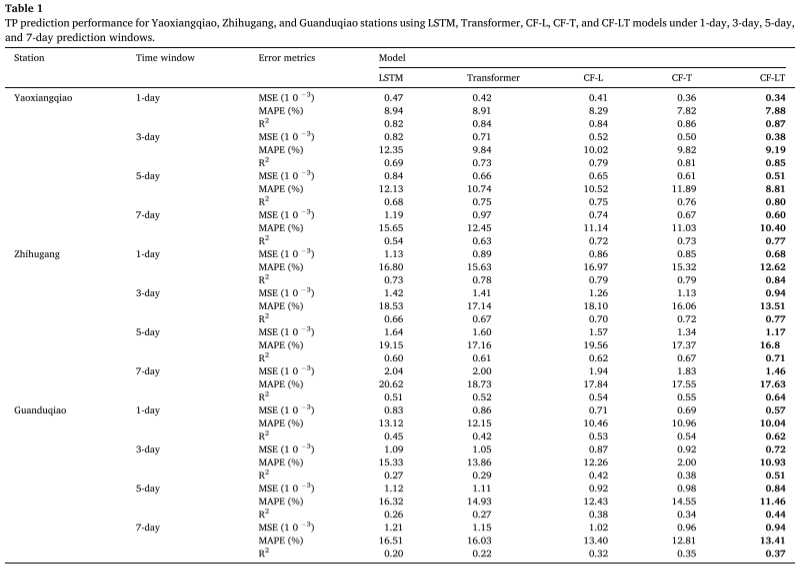
Πειραματικά αποτελέσματα : Εφαρμόζοντας το καλύτερο μοντέλο εκπαίδευσης στο σύνολο δεδομένων δοκιμής, ο πίνακας συνοψίζει τις προβλέψεις συγκέντρωσης TP που δίνονται από τα μοντέλα CF-LT, LSTM, Transformer, CF-L και CF-T σε διαφορετικές τοποθεσίες και διαφορετικά χρονικά παράθυρα πρόβλεψης. Το προτεινόμενο μοντέλο CF-LT δίνει τα καλύτερα αποτελέσματα και για τις τρεις μετρήσεις αξιολόγησης. Όσον αφορά το R2, το μοντέλο CF-LT κυμαίνεται από 0,37 έως 0,87, ενώ τα επόμενα καλύτερα μοντέλα CF-L και CF-T είναι 0,32-0,84 και 0,35-0,86 αντίστοιχα. Αυτό δείχνει ότι ο συνδυασμός της μακροπρόθεσμης μνήμης του LSTM με τον μηχανισμό προσοχής του Transformer μπορεί να βελτιώσει την ακρίβεια πρόβλεψης. Συγκρίνοντας τα χειρότερα μοντέλα LSTM και Transformer με τα μοντέλα CF-L και CF-T, το MAPE κυμαίνεται από 8,94%-20,62% (LSTM) και 8,91%-18,73% (Transformer) έως 8,29%-19,56% (CF -L) και 7,82%-17,55% (CF-T). Αυτά τα αποτελέσματα καταδεικνύουν ότι η αποσύνθεση δεδομένων και η μοντελοποίηση διαίρεσης συχνότητας βελτιώνουν σημαντικά την ακρίβεια πρόβλεψης συλλαμβάνοντας περισσότερες πληροφορίες που κρύβονται στα αρχικά δεδομένα.
Πρόβλεψη παραγόντων που επηρεάζουν τη συγκέντρωση ΤΡ ολικού φωσφόρου:
Η μέση απόλυτη τιμή SHAP (MASV) χρησιμοποιείται για να ποσοτικοποιήσει τη συμβολή των χαρακτηριστικών εισόδου (WT, PH, DO, COD, EC, TU, TN, NH3-N, TP) στα αποτελέσματα πρόβλεψης TP μεγαλύτερος ο αντίκτυπος στα αποτελέσματα της πρόβλεψης του μοντέλου. Η έρευνα δείχνει ότι εκτός από την προηγούμενη σειρά συγκεντρώσεων TP, το ολικό άζωτο (TN) και η θολότητα (TU) είναι οι δύο κύριοι παράγοντες που επηρεάζουν την πρόβλεψη TP. Αυτό δείχνει ότι οι αλλαγές στο TP δεν επηρεάζονται μόνο άμεσα από τις ιστορικές συγκεντρώσεις, αλλά σχετίζονται επίσης στενά με τη δυναμική ανάπτυξης των φυκών που σχετίζεται με τις εκπομπές ρύπανσης από μη σημειακές πηγές και την αναλογία αζώτου-φωσφόρου στο υδάτινο σώμα. Ειδικότερα, η σημαντική συσχέτιση μεταξύ TN και TP υπογραμμίζει το αποτέλεσμα σύζευξης των δύο στον κύκλο των θρεπτικών συστατικών της λίμνης και υπογραμμίζει τη σημασία της εισαγωγής αζώτου από μη σημειακή πηγή για την πρόβλεψη συγκέντρωσης φωσφόρου.
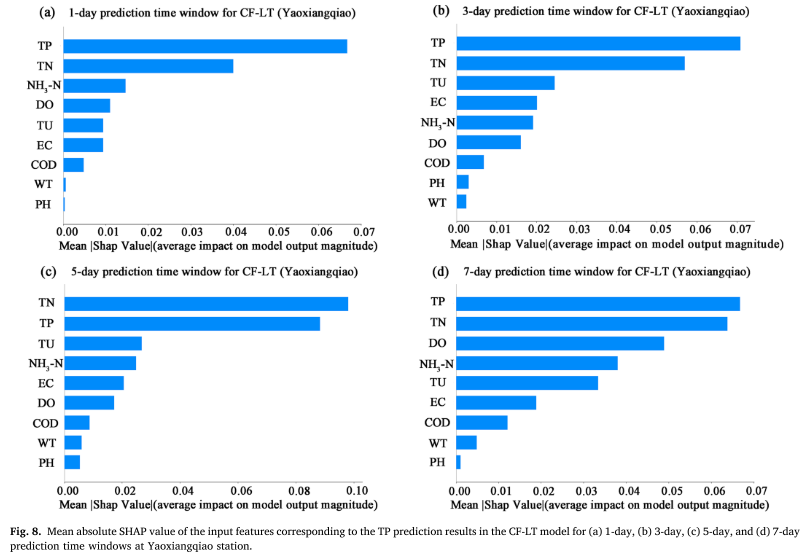
Από αυτά τα αποτελέσματα μπορούν να γίνουν οι ακόλουθες παρατηρήσεις:
Σύγκριση με την αντίθετη προκατάληψη και τακτοποίηση : Τυχαία διαίρεση 50%/25%/25% για σύνολα δεδομένων εκπαίδευσης, επικύρωσης και δοκιμής. Το σχήμα 2 δείχνει τις βέλτιστες καμπύλες Pareto για όλες τις μεθόδους, όπου το κάτω δεξιά γωνιακό σημείο αντιπροσωπεύει την ιδανική απόδοση (μεγαλύτερη ακρίβεια και χαμηλότερη απόκλιση πρόβλεψης).
Το υβριδικό μοντέλο CF-LT που προτείνεται σε αυτό το άρθρο συνδυάζει μονάδες CEEM DAN, FE, LSTM και Transformer για την πρόβλεψη της συγκέντρωσης TP στα επιφανειακά νερά. Αυτή η υβριδική προσέγγιση επιλύει τα μειονεκτήματα της υπερπροσαρμογής και της υποπροσαρμογής του μοντέλου που προκαλούνται από δεδομένα υψηλών διαστάσεων και την αδυναμία δημιουργίας μακροπρόθεσμων εξαρτήσεων μεταξύ των δεδομένων όταν γίνονται μακροπρόθεσμες προβλέψεις. Επιπλέον, οι τιμές SHAP χρησιμοποιούνται για την ερμηνεία της εξόδου του μοντέλου CF-LT.
Το μοντέλο χρησιμοποιεί δεδομένα από τρεις σταθμούς παρακολούθησης της ποιότητας του νερού στη λεκάνη της λίμνης Taihu για να παράγει 9 δείκτες ποιότητας νερού σε διαφορετικά χρονικά παράθυρα πρόβλεψης. Ως μοντέλα ελέγχου χρησιμοποιούνται αλγόριθμοι LSTM, Transformer, CF-L και CF-T. Το μοντέλο CF-LT έχει τιμή R2 0,37–0,87, τιμή MSE 0,34 × 10−3–1,46 × 10−3 και τιμή MAPE 7,88%–17,63% στο σύνολο δεδομένων δοκιμής, υποδεικνύοντας ότι και τα τρία Οι δείκτες είναι καλύτεροι από τα αποτελέσματα LSTM, Transformer, CF-L και CF-T. Το προτεινόμενο μοντέλο CF-LT παρήγαγε επίσης τα καλύτερα αποτελέσματα πρόβλεψης κορυφής. Με βάση την ερμηνεία του SHAP, βρήκαμε ότι οι TU και TN (εξαιρουμένων της πρώιμης χρονοσειράς συγκέντρωσης TP) είναι σημαντικοί παράγοντες που επηρεάζουν την πρόβλεψη TP, γεγονός που δείχνει ότι οι αλλαγές στο TP δεν σχετίζονται μόνο με τα πρώιμα επίπεδα συγκέντρωσης TP, αλλά επηρεάζονται επίσης από το TP συγκέντρωση. Η σχέση μεταξύ των εκπομπών ρύπανσης από μη σημειακές πηγές και των υδρόβιων φυτών στις εκβολές της λίμνης Taihu. Επιπλέον, αξίζει να σημειωθεί ότι η TN και η TU συμβάλλουν περισσότερο στην πρόβλεψη της συγκέντρωσης TP στην περίοδο των βροχών. Επομένως, τα αποτελέσματα αυτής της μελέτης δείχνουν ότι το μοντέλο CF-LT παρέχει πρόσθετες πληροφορίες για την κατανόηση του μηχανισμού απόκρισης του TP όταν αλλάζουν διαφορετικές περιβαλλοντικές συνθήκες.
Προεπεξεργασία δεδομένων CEEMDAN και FE
def ceemdan_fe_preprocessing(data):
# CEEMDAN分解
imfs, residue = ceemdan(data, **ceemdan_params)
# 计算各个IMF的模糊熵
fe_values = []
for imf in imfs:
fe_values.append(fuzzy_entropy(imf)) # 假定fuzzy_entropy为计算模糊熵的函数
# 根据FE值重组IMFs
imfs_sorted = [imf for _, imf in sorted(zip(fe_values, imfs))]
imf_hf, imf_mf, imf_lf, imf_trend = imfs_sorted[:4], imfs_sorted[4:8], imfs_sorted[8:12], imfs_sorted[12:]
return np.concatenate((imf_hf, imf_mf, imf_lf, imf_trend), axis=1)
# 应用到数据上
preprocessed_data = ceemdan_fe_preprocessing(original_data)
LSTM & Transformer
def get_positional_encoding(max_len, d_model):
pe = np.zeros((max_len, d_model))
position = np.arange(0, max_len).reshape(-1, 1)
div_term = np.exp(np.arange(0, d_model, 2) * -(np.log(10000.0) / d_model))
pe[:, 0::2] = np.sin(position * div_term)
pe[:, 1::2] = np.cos(position * div_term)
return pe
def transformer_encoder(inputs, d_model, num_heads, ff_dim):
x = MultiHeadAttention(num_heads=num_heads, key_dim=d_model)(inputs, inputs)
x = LayerNormalization()(Add()([inputs, x]))
x = Dense(ff_dim, activation='relu')(x)
x = Dense(d_model)(x)
x = LayerNormalization()(Add()([inputs, x]))
return x
def transformer_decoder(inputs, encoder_outputs, d_model, num_heads, ff_dim):
return decoder_output
input_features = Input(shape=(input_shape))
lstm_out = LSTM(lstm_units)(input_features) # LSTM
pos_encodings = get_positional_encoding(max_seq_length, d_model)
transformer_in = Add()([lstm_out, pos_encodings])
transformer_encoded = transformer_encoder(transformer_in, d_model, num_heads, ff_dim)
decoder_output = transformer_decoder(decoder_input, transformer_encoded, d_model, num_heads, ff_dim)
output_layer = Dense(output_dim, activation='linear')(decoder_output)
model = Model(inputs=input_features, outputs=output_layer)
model.compile(optimizer=Adam(learning_rate), loss='mse')
Αυτή η μελέτη ανέπτυξε ένα ερμηνεύσιμο υβριδικό μοντέλο CEEMDAN-FE-LSTM-Transformer για την πρόβλεψη της συνολικής συγκέντρωσης φωσφόρου στα επιφανειακά ύδατα. μέσω SHAP. Τα πειραματικά αποτελέσματα επιβεβαίωσαν την αποτελεσματικότητα του μοντέλου, ιδιαίτερα τον εντοπισμό βασικών περιβαλλοντικών παραγόντων, παρέχοντας ένα ισχυρό εργαλείο για τη διαχείριση του ευτροφισμού των υδάτινων σωμάτων και τον έλεγχο της ρύπανσης.
[1] Jiefu Yao, Shuai Chen, Xiaohong Ruan. Ερμηνεύσιμο υβριδικό μοντέλο μετασχηματιστή CEEMDAN-FE-LSTM για την πρόβλεψη ολικών συγκεντρώσεων φωσφόρου στα επιφανειακά νερά. [J]Journal of Hydrology Τόμος 629, Φεβρουάριος 2024, 130609

Έχει αφοσιωθεί στην έρευνα της τεχνολογίας για περισσότερα από 30 χρόνια και είναι ικανός σε διάφορες γλώσσες όπως java, linux, javascript, php, css κ.λπ. Έχει κάνει πολλές συνεισφορές στον τομέα του ανοιχτού κώδικα σταθμός τεκμηρίωσης προγραμματιστή για να μοιραστείτε ορισμένα ζητήματα στην ανάπτυξη τεχνολογίας για μελλοντική αναφορά

Ταχυδρομείο[email protected]