
minhas informações de contato
Correspondência[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Esta semana li um artigo intitulado Modelo híbrido de transformador CEEMDAN-FE-LSTM interpretável para prever concentrações totais de fósforo em águas superficiais. Este artigo propõe um modelo híbrido para predição de TP. Este artigo propõe um modelo híbrido para predição de TP, nomeadamente o modelo CF-LT. O modelo combina de forma inovadora decomposição em modo empírico (EMD) totalmente integrada com processamento de ruído adaptativo, análise de entropia difusa, rede de memória de longo e curto prazo (LSTM) e tecnologia Transformer. Ao introduzir a tecnologia de reconstrução por divisão de frequência de dados, este modelo resolve efetivamente os problemas de sobreajuste e subajuste que tendem a ocorrer quando os modelos tradicionais de aprendizado de máquina lidam com dados de alta dimensão. Ao mesmo tempo, a aplicação do mecanismo de atenção permite que o modelo CF-LT supere as limitações de outros modelos que são difíceis de estabelecer dependências de longo prazo entre os dados ao fazer previsões de longo prazo. Os resultados da previsão mostram que o modelo CF-LT atingiu um coeficiente de determinação (R2) de 0,37 a 0,87 no conjunto de dados de teste, o que foi uma melhoria significativa de 0,05 a 0,17 (ou seja, 6% a 85%) em comparação com o controle modelo. Além disso, o modelo CF-LT também apresentou o melhor desempenho de predição de pico.
O jornal semanal desta semana decodifica o artigo intitulado Interpretable CEEMDAN-FE-LSTM-transformer hybrid model for predicting totalphosphor concentrations in surface water. Este artigo apresenta um modelo híbrido, CF-LT, especificamente para previsão de TP. O modelo integra de forma inovadora a Decomposição de Modo Empírico de Conjunto Completo (EMD) com processamento de ruído adaptativo, análise de entropia difusa, redes de Memória de Longo Prazo (LSTM) e tecnologia Transformer. Ao introduzir a divisão e reconstrução de frequência de dados, o CF-LT aborda efetivamente os problemas de overfitting e underfitting que os modelos tradicionais de aprendizado de máquina geralmente encontram ao lidar com dados de alta dimensão. Além disso, a aplicação do mecanismo de atenção permite que o CF-LT supere as limitações de outros modelos no estabelecimento de dependências de longo prazo entre pontos de dados durante previsões de longo prazo. Os resultados da predição demonstram que o CF-LT atinge um coeficiente de decisão (R2) variando de 0,37 a 0,87 nos conjuntos de dados de teste, representando uma melhoria significativa de 0,05 a 0,17 (ou 6% a 85%) em comparação aos modelos de controle. Além disso, o CF-LT fornece o melhor desempenho de predição de pico.
标题:Modelo híbrido CEEMDAN-FE-LSTM-transformador interpretável para prever concentrações totais de fósforo em águas superficiais
Autor: Jiefu Yao, Shuai Chen, Xiaohong Ruan
liberar:Revista de Hidrologia Volume 629, Fevereiro de 2024, 130609
Fonte: https://www.sciencedirect.com/science/article/pii/S0022169424000039?via%3Dihub
Este artigo propõe um modelo híbrido para predição de TP. Este modelo (CF-LT) combina decomposição de modo empírico (EMD) totalmente integrada com ruído adaptativo, entropia difusa, memória de longo curto prazo e transformador.Reconstrução de divisão de frequência de dadosA introdução resolve efetivamente os problemas de sobreajuste e subajuste que ocorreram quando os modelos anteriores de aprendizado de máquina enfrentaram dados de alta dimensão.mecanismo de atenção Isto supera o problema de que estes modelos não conseguem estabelecer dependências de longo prazo entre os dados e fazer previsões de longo prazo. Os resultados da previsão mostram que o modelo CF-LT atinge um coeficiente de determinação (R2) de 0,37-0,87 no conjunto de dados de teste, que é 0,05-0,17 (6%-85%) superior ao modelo de controle. Além disso, o modelo CF-LT forneceu a melhor previsão de pico.
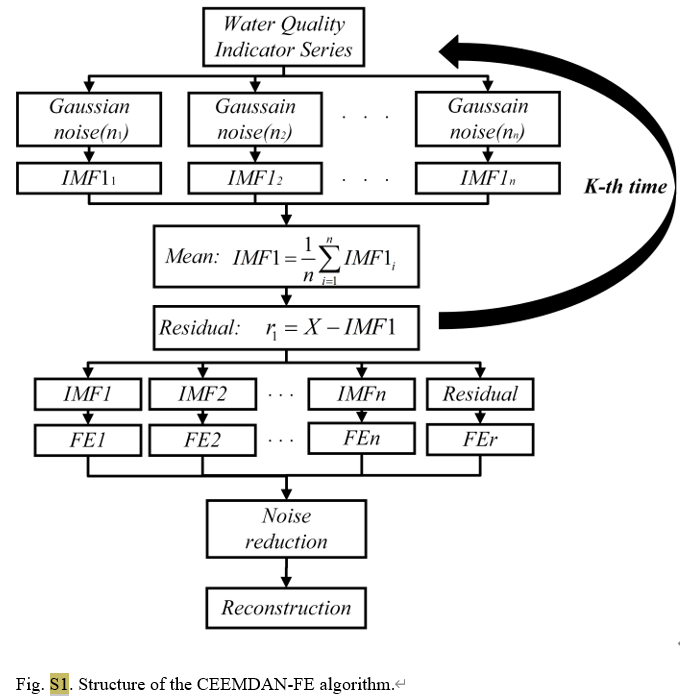
Como um método avançado de análise de série temporal, o CEEMDAN reduz efetivamente o problema de aliasing de modo existente no EMD tradicional, adicionando ruído adaptativo ao processo de decomposição de modo empírico (EMD). Ele pode decompor o sinal original em uma série de funções de modo intrínseco (FMIs). Cada FMI representa diferentes características da escala de tempo do sinal, tornando assim a análise de sinais complexos mais intuitiva e precisa. Neste estudo, o CEEMDAN foi usado para processar dados diários de qualidade da água de três estações de monitoramento no Lago Tai, separando a concentração total de fósforo e outros parâmetros de qualidade da água, como temperatura da água, pH, oxigênio dissolvido, etc., em sinais em diferentes bandas de frequência.
Algoritmo S1: Decomposição de Modo Empírico de Conjunto Completo com Ruído Adaptativo (CEEMDAN)
yi ( t ) = y ( t ) + ϵ 0 vi ( t ) i = 1 , 2 , … , n (S1) y^{i}(t)=y(t)+epsilon_0v^i(t)quad i=1,2,pontos,ntag{S1}eeu(para)=e(para)+ϵ0vocêocêocêeu(para)eu=1,2,…,e(S1)
IMF1 i = E 0 ( yi ( t ) ) + r 1 i IMF1 ‾ = 1 n IMF1 i (S2) texto{IMF1}_i=E_0(y^i(t))+r^i_1quad overline{text{IMF1}}=frac1ntext{IMF1}_itag{S2}FMI1eu=E0(eeu(para))+r1euFMI1=e1FMI1eu(S2)
r 1 = yi ( t ) − FMI1 ‾ (S3) r_1=y^i(t)-overline{text{FMI1}}tag{S3}r1=eeu(para)−FMI1(S3)
IMF2 ‾ = 1 n ∑ i = 1 n E 1 ( r 1 + ϵ 1 E 1 ( vi ( t ) ) ) (S4) overline{text{IMF2}}=frac1nsum^n_{i=1}E_1(r_1+epsilon_1E_1(v^i(t))) tag{S4}FMI2=e1eu=1∑eE1(r1+ϵ1E1(vocêocêocêeu(para)))(S4)
y ( t ) = ∑ l = 1 K − 1 FMI1 ‾ + r K (S5) y(t)=soma^{K-1}_{l=1}sobrelinha{texto{FMI1}}+r_Ktag{S5}e(para)=eu=1∑E−1FMI1+rE(S5)
Para a parte CEEMDAN-FE, primeiro dividimos o conjunto de dados original em conjuntos de dados de treinamento e teste e, em seguida, aplicamos o CEEMDAN para decompor cada característica nos dois conjuntos de dados em múltiplas funções de modo intrínseco (FMI). De acordo com a proximidade dos valores FE de cada FMI, eles são reconstruídos em componentes de alta frequência (IMFH), frequência intermediária (IMFM), baixa frequência (IMFL) e termo de tendência (IMFT), que refletem diferentes aspectos do FMI .
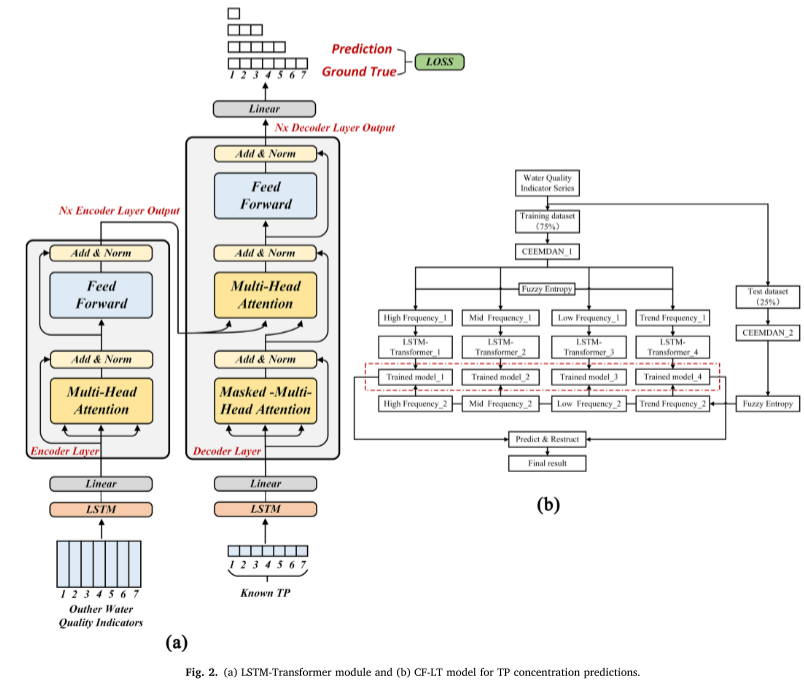
Para a parte do Transformador LSTM, no codificador e decodificador, a camada oculta do LSTM é substituída pela codificação de posição do Transformador para estabelecer a dependência temporal entre os dados de entrada. O processo de cálculo específico é o seguinte (Figura 2a).
SHAP é um método de teoria dos jogos para interpretar a saída de qualquer modelo de ML.Para determinar o impacto dos recursos de entrada na saída do modelo, os recursos de entrada z = [ z 1 , . . . , zp ] z = [z1, ..., zp]por=[por1,...,porp]Relacionado ao modelo de aprendizagem profunda treinado F.
F = f ( z ) = ϕ 0 + ∑ i = 1 M ϕ izi (12) F=f(z)=phi_0+sum_{i=1}^M phi_iz_i tag{12}F=e(por)=ϕ0+eu=1∑Mϕeuporeu(12)
φ eu ∈ R φ_i ∈ Rφeu∈RIndica a contribuição de cada feature para o modelo, que é dada pela seguinte fórmula:
ϕ i ( F , x ) = ∑ z ≤ x ∣ z ∣ ! ( M − ∣ z ∣ − 1 ) ! M ! [ F ( z ) − F ( z / i ) ] (13) phi_i(F,x)=sum_{zleq x}frac{|z|!(M-|z|-1)!}{M!}[F(z)-F(z/i)] tag{13}ϕeu(F,x)=por≤x∑M!∣por∣!(M−∣por∣−1)
O estudo propõe um novo modelo para prever as concentrações totais de fósforo. O modelo combina as tecnologias CEEM DAN, FE, LSTM e Transformer e usa SHAP para interpretar a saída do modelo. O objetivo principal deste estudo é avaliar o desempenho do modelo proposto CEEMDAN-FE-LSTM-Transformer (CF-LT) na previsão da concentração de TP na entrada do Lago Tai e aplicar SHAP para interpretar a saída do CF-LT modelo. Isto deverá revelar os principais factores que afectam a concentração de TP na região e os seus mecanismos de resposta.
A decomposição de dados em alta dimensão pode produzir um grande número de componentes modais. Para resolver este problema, a Entropia Fuzzy (FE), um método eficiente para calcular a complexidade do tempo, pode ser combinada com o CEEMDAN. Esta combinação reconstrói efetivamente os subsinais decompostos do CEEMDAN, reduzindo assim o número de modelos de subfrequência.
Os modelos LSTMTransformer podem capturar relacionamentos entre pontos de tempo não adjacentes, preservando as características da série temporal dos dados de entrada.
Os modelos transformadores usam mecanismos de atenção para identificar correlações entre dois locais em um contexto específico durante o treinamento. Isto permite a aquisição eficiente de dados relevantes e reduz a redundância de informações.
As principais contribuições deste artigo estão em quatro aspectos:
conjunto de dados : A Bacia do Lago Taihu está localizada no curso inferior do rio Yangtze, cobrindo uma área de 36.900 quilômetros quadrados, com uma densa rede fluvial e numerosos lagos. O Lago Taihu é um típico lago raso. A bacia tem as características de um clima subtropical norte úmido, com temperatura média anual de 15-17°C e precipitação média anual de 1181 mm. Este estudo utilizou dados de monitoramento da qualidade da água da Estação Yaoxiangqiao, Estação Zhihugang e Estação Guanduqiao (Figura S2). Estas estações de monitorização estão localizadas em Taihukou, uma importante secção nacional de avaliação da qualidade da água. Os dados vêm do Centro Provincial de Monitoramento Ambiental de Jiangsu.
Critério de avaliação : A avaliação de desempenho do modelo utiliza vários indicadores-chave: coeficiente de determinação (R²), erro quadrático médio (MSE) e erro percentual médio absoluto (MAPE). R² mede o grau de ajuste entre o valor previsto do modelo e o valor real Perto de 1 indica que o modelo tem forte capacidade de previsão; MAPE reflete o tamanho do erro de previsão de uma perspectiva percentual. O valor mais baixo significa previsões mais precisas.
Detalhes de implementação : O processo experimental inclui pré-processamento de dados, treinamento e teste de modelo. Um procedimento experimental completo é estabelecido para avaliar o desempenho do modelo proposto em diferentes conjuntos de dados e janelas de tempo de previsão. Primeiro, os dados são pré-processados pelo método CEEMDAN-FE, que remove a interferência de informações adicionando decomposição de modo empírico totalmente integrado com ruído adaptativo, extrai informações em várias escalas e usa entropia difusa para reduzir o número de subsinais. A seguir, os dados processados são divididos em conjunto de treinamento e conjunto de teste nas proporções de 75% e 25%. Na fase de treinamento, o conjunto de dados de treinamento pré-processado é inserido no modelo LSTM-Transformer. Use retropropagação e otimizador Adam para atualizar os pesos do modelo e use a pesquisa de grade para identificar os melhores hiperparâmetros do módulo LSTMTransformer para garantir o desempenho do modelo sob diferentes janelas de tempo de previsão (7 dias, 5 dias, 3 dias, 1 dia) ideal.
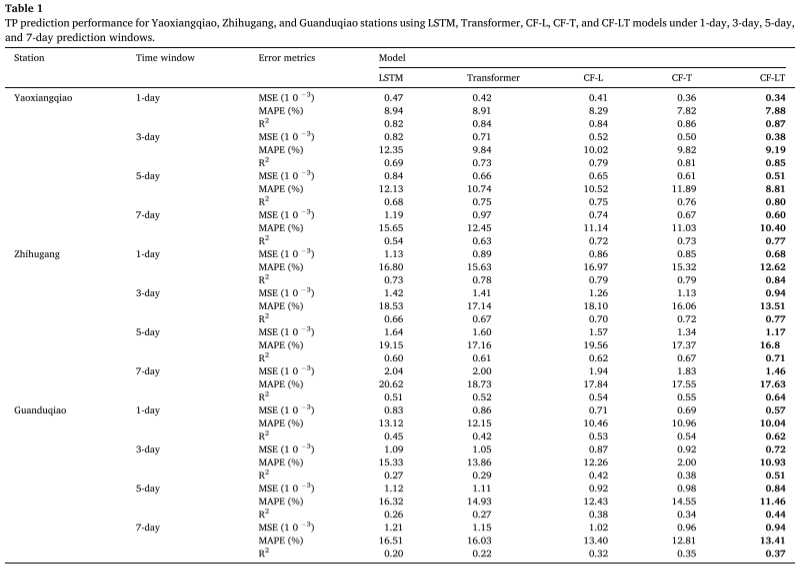
Resultados experimentais : Aplicando o melhor modelo de treinamento ao conjunto de dados de teste, a tabela resume as previsões de concentração de TP fornecidas pelos modelos CF-LT, LSTM, Transformer, CF-L e CF-T em diferentes locais e diferentes janelas de tempo de previsão. O modelo CF-LT proposto apresenta os melhores resultados para todas as três métricas de avaliação. Em termos de R2, o modelo CF-LT varia de 0,37 a 0,87, enquanto os próximos melhores modelos CF-L e CF-T são 0,32-0,84 e 0,35-0,86, respectivamente. Isto mostra que combinar a memória de longo prazo do LSTM com o mecanismo de atenção do Transformer pode melhorar a precisão da previsão. Comparando os piores modelos LSTM e Transformer com os modelos CF-L e CF-T, o MAPE varia de 8,94%-20,62% (LSTM) e 8,91%-18,73% (Transformer) a 8,29%-19,56% (CF -L) e 7,82%-17,55% (CF-T). Esses resultados demonstram que a decomposição de dados e a modelagem por divisão de frequência melhoram significativamente a precisão da previsão, capturando mais informações ocultas nos dados originais.
Previsão de fatores que afetam a concentração total de fósforo TP:
O valor SHAP absoluto médio (MASV) é usado para quantificar a contribuição dos recursos de entrada (WT, PH, DO, COD, EC, TU, TN, NH3-N, TP) para os resultados de previsão de TP. maior o impacto nos resultados da previsão do modelo. A pesquisa mostra que, além das próprias séries anteriores de concentração de TP, o nitrogênio total (TN) e a turbidez (TU) são os dois principais fatores que afetam a previsão de TP. Isto mostra que as alterações na TP não são apenas directamente afectadas pelas concentrações históricas, mas também estão intimamente relacionadas com a dinâmica de crescimento de algas associadas às emissões de poluição de fontes difusas e à relação azoto-fósforo na massa de água. Em particular, a correlação significativa entre TN e TP enfatiza o efeito de acoplamento dos dois na ciclagem de nutrientes do lago e destaca a importância da entrada de nitrogênio de fonte não pontual para a previsão da concentração de fósforo.
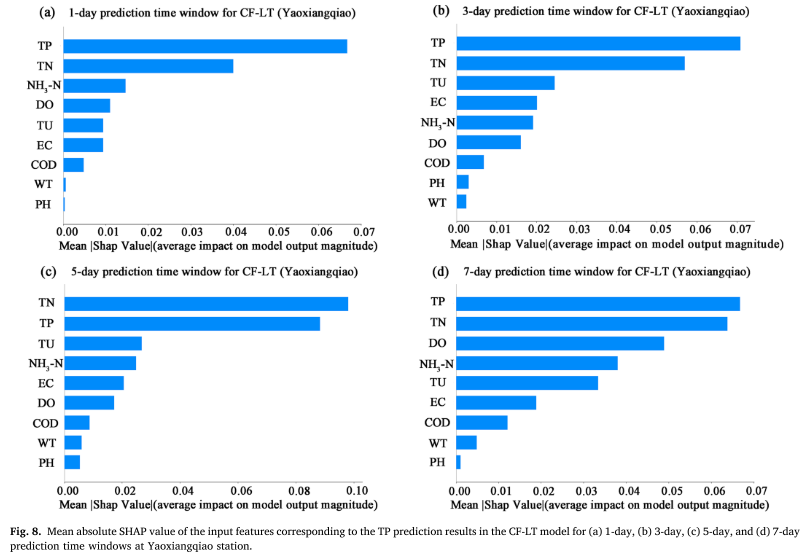
A partir desses resultados, as seguintes observações podem ser feitas:
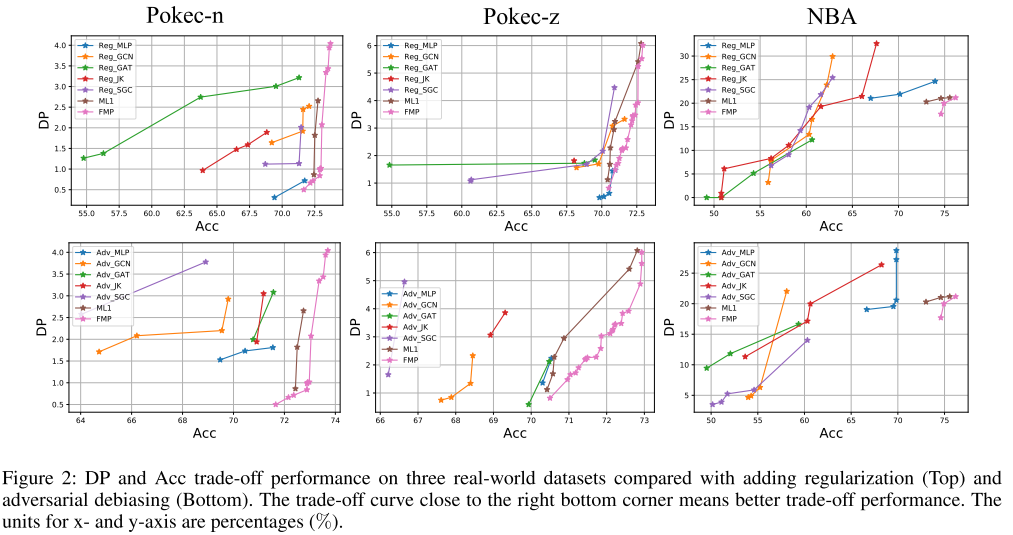
Comparação com desvirtuação e regularização adversária : Divida aleatoriamente 50%/25%/25% para conjuntos de dados de treinamento, validação e teste. A Figura 2 mostra as curvas ótimas de Pareto para todos os métodos, onde o ponto do canto inferior direito representa o desempenho ideal (maior precisão e menor desvio de predição).
O modelo híbrido CF-LT proposto neste artigo combina módulos CEEM DAN, FE, LSTM e Transformer para prever a concentração de TP em águas superficiais. Esta abordagem híbrida resolve as deficiências de sobreajuste e subajuste do modelo causadas por dados de alta dimensão e a incapacidade de estabelecer dependências de longo prazo entre os dados ao fazer previsões de longo prazo. Além disso, os valores SHAP são usados para interpretar a saída do modelo CF-LT.
O modelo utiliza dados de três estações de monitoramento da qualidade da água na Bacia do Lago Taihu para produzir 9 indicadores de qualidade da água em diferentes janelas de tempo de previsão. Algoritmos LSTM, Transformer, CF-L e CF-T são usados como modelos de controle. O modelo CF-LT tem um valor R2 de 0,37–0,87, um valor MSE de 0,34 × 10−3–1,46 × 10−3 e um valor MAPE de 7,88%–17,63% no conjunto de dados de teste, indicando que todos os três os indicadores são melhores que os resultados de LSTM, Transformer, CF-L e CF-T. O modelo CF-LT proposto também produziu os melhores resultados de previsão de pico. Com base na interpretação do SHAP, descobrimos que TU e TN (excluindo as séries temporais iniciais de concentração de TP) são fatores importantes que afetam a previsão de TP, o que indica que as mudanças no TP não estão apenas relacionadas aos níveis iniciais de concentração de TP, mas também afetadas pelo TP concentração. A relação entre emissões de poluição de fontes difusas e plantas aquáticas no estuário do Lago Taihu. Além disso, vale ressaltar que TN e TU contribuem mais para a previsão da concentração de TP no período chuvoso. Portanto, os resultados deste estudo indicam que o modelo CF-LT fornece informações adicionais para a compreensão do mecanismo de resposta do TP quando diferentes condições ambientais mudam.
Pré-processamento de dados CEEMDAN e FE
def ceemdan_fe_preprocessing(data):
# CEEMDAN分解
imfs, residue = ceemdan(data, **ceemdan_params)
# 计算各个IMF的模糊熵
fe_values = []
for imf in imfs:
fe_values.append(fuzzy_entropy(imf)) # 假定fuzzy_entropy为计算模糊熵的函数
# 根据FE值重组IMFs
imfs_sorted = [imf for _, imf in sorted(zip(fe_values, imfs))]
imf_hf, imf_mf, imf_lf, imf_trend = imfs_sorted[:4], imfs_sorted[4:8], imfs_sorted[8:12], imfs_sorted[12:]
return np.concatenate((imf_hf, imf_mf, imf_lf, imf_trend), axis=1)
# 应用到数据上
preprocessed_data = ceemdan_fe_preprocessing(original_data)
LSTM&Transformador
def get_positional_encoding(max_len, d_model):
pe = np.zeros((max_len, d_model))
position = np.arange(0, max_len).reshape(-1, 1)
div_term = np.exp(np.arange(0, d_model, 2) * -(np.log(10000.0) / d_model))
pe[:, 0::2] = np.sin(position * div_term)
pe[:, 1::2] = np.cos(position * div_term)
return pe
def transformer_encoder(inputs, d_model, num_heads, ff_dim):
x = MultiHeadAttention(num_heads=num_heads, key_dim=d_model)(inputs, inputs)
x = LayerNormalization()(Add()([inputs, x]))
x = Dense(ff_dim, activation='relu')(x)
x = Dense(d_model)(x)
x = LayerNormalization()(Add()([inputs, x]))
return x
def transformer_decoder(inputs, encoder_outputs, d_model, num_heads, ff_dim):
return decoder_output
input_features = Input(shape=(input_shape))
lstm_out = LSTM(lstm_units)(input_features) # LSTM
pos_encodings = get_positional_encoding(max_seq_length, d_model)
transformer_in = Add()([lstm_out, pos_encodings])
transformer_encoded = transformer_encoder(transformer_in, d_model, num_heads, ff_dim)
decoder_output = transformer_decoder(decoder_input, transformer_encoded, d_model, num_heads, ff_dim)
output_layer = Dense(output_dim, activation='linear')(decoder_output)
model = Model(inputs=input_features, outputs=output_layer)
model.compile(optimizer=Adam(learning_rate), loss='mse')
Este estudo desenvolveu um modelo híbrido interpretável CEEMDAN-FE-LSTM-Transformer para a previsão da concentração total de fósforo em águas superficiais. O modelo melhorou significativamente a precisão da previsão por meio da fusão de tecnologia avançada de pré-processamento de dados e modelos de aprendizagem profunda, e fornece uma explicação clara dos recursos. através do SHAP. Os resultados experimentais confirmaram a eficácia do modelo, especialmente na identificação dos principais fatores ambientais, fornecendo uma ferramenta poderosa para a gestão da eutrofização de corpos d'água e controle da poluição.
[1] Revista de Hidrologia Volume 629, Fevereiro de 2024, 130609

Ele se dedica à pesquisa de tecnologia há mais de 30 anos e é proficiente em diversas linguagens como java, linux, javascript, php, css, etc. estação de documentação do desenvolvedor para compartilhar alguns problemas no desenvolvimento de tecnologia para referência futura.

Correspondência[email protected]