
プライベートな連絡先の最初の情報
送料メール:
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
今週私は、地表水中の総リン濃度を予測するための解釈可能な CEEMDAN-FE-LSTM-変圧器ハイブリッド モデルというタイトルの論文を読みました。この論文では、TP 予測のためのハイブリッド モデルを提案します。本稿では、TP予測のためのハイブリッドモデル、すなわちCF-LTモデルを提案する。このモデルは、完全に統合された経験的モード分解 (EMD) と適応ノイズ処理、ファジー エントロピー分析、長短期記憶ネットワーク (LSTM)、およびトランスフォーマー テクノロジーを革新的に組み合わせています。このモデルは、データ周波数分割再構成技術を導入することにより、従来の機械学習モデルが高次元データを扱う場合に発生しがちな過学習および過小学習の問題を効果的に解決します。同時に、アテンション メカニズムの適用により、CF-LT モデルは、長期予測を行う際にデータ間の長期依存関係を確立することが難しい他のモデルの制限を克服できます。予測結果は、CF-LT モデルがテスト データセットで決定係数 (R2) 0.37 ~ 0.87 に達し、対照と比較して 0.05 ~ 0.17 (つまり 6% ~ 85%) の大幅な改善であることを示しています。モデル。さらに、CF-LT モデルは最高のピーク予測性能も示しました。
今週の週刊新聞は、表層水中の全リン濃度を予測するための解釈可能な CEEMDAN-FE-LSTM-トランスフォーマー ハイブリッド モデルと題する論文を解読します。この論文では、TP 予測に特化したハイブリッド モデル CF-LT を紹介しています。このモデルは、Complete Ensemble Empirical Mode Decomposition (EMD) と適応型ノイズ処理、ファジー エントロピー分析、Long Short-Term Memory (LSTM) ネットワーク、および Transformer テクノロジーを革新的に統合しています。データ周波数分割と再構築を導入することで、CF-LT は、従来の機械学習モデルが高次元データを扱う際によく遭遇するオーバーフィッティングとアンダーフィッティングの問題に効果的に対処します。さらに、アテンション メカニズムを適用することで、CF-LT は長期予測中にデータ ポイント間の長期依存関係を確立する際の他のモデルの制限を克服できます。 予測結果では、CF-LT がテスト データセットで 0.37 ~ 0.87 の範囲の決定係数 (R2) を達成し、コントロール モデルと比較して 0.05 ~ 0.17 (または 6% ~ 85%) の大幅な改善を示していることが示されています。さらに、CF-LT は最高のピーク予測パフォーマンスを提供します。
問題:表層水中の総リン濃度を予測するための解釈可能な CEEMDAN-FE-LSTM-トランスフォーマーハイブリッドモデル
著者: Jiefu Yao、Shuai Chen、Xiaohong Ruan
リリース:水文学ジャーナル 第629巻、2024年2月、130609
リンク:https://www.sciencedirect.com/science/article/pii/S0022169424000039?via%3Dihub
この論文では、TP 予測のためのハイブリッド モデルを提案します。このモデル (CF-LT) は、完全に統合された経験的モード分解 (EMD) と、適応ノイズ、ファジー エントロピー、長期短期記憶、およびトランスフォーマーを組み合わせています。データ周波数分割再構成の導入により、以前の機械学習モデルが高次元データに直面したときに発生した過学習および過小学習の問題が効果的に解決されます。注意メカニズムこれにより、これらのモデルがデータ間の長期的な依存関係を確立できず、長期的な予測を行うことができないという問題が解決されます。予測結果は、CF-LT モデルがテスト データセットで 0.37 ~ 0.87 の決定係数 (R2) を達成し、これは対照モデルよりも 0.05 ~ 0.17 (6% ~ 85%) 高いことを示しています。さらに、CF-LT モデルは最良のピーク予測を提供しました。
高度な時系列解析手法である CEEMDAN は、経験的モード分解 (EMD) プロセスに適応ノイズを追加することで、従来の EMD に存在するモード エイリアシング問題を効果的に軽減します。元の信号を一連の固有モード関数 (IMF) に分解し、各 IMF が信号の異なるタイム スケール特性を表すため、複雑な信号の分析がより直観的かつ正確になります。この研究では、CEEMDAN を使用して太湖の 3 つの監視所からの毎日の水質データを処理し、総リン濃度と、水温、pH、溶存酸素などの他の水質パラメータを異なる周波数帯域の信号に分離しました。
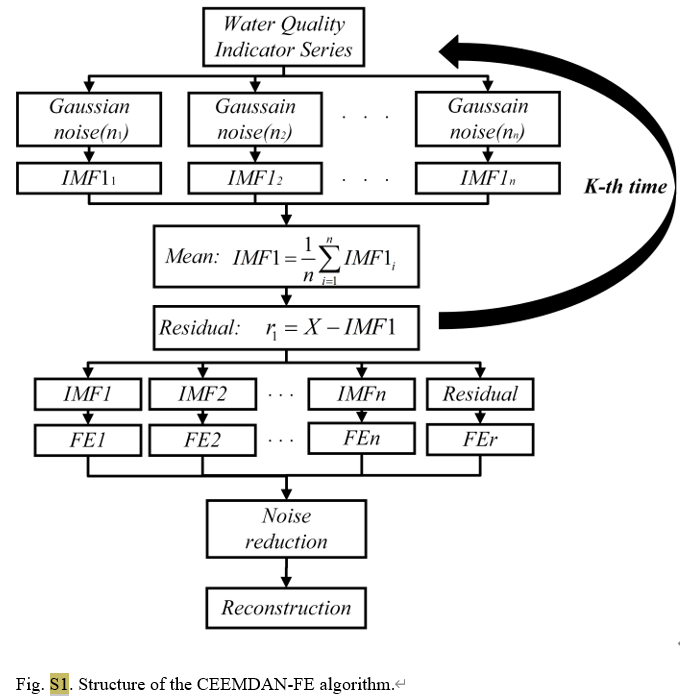
アルゴリズム S1: 適応ノイズによる完全なアンサンブル経験的モード分解 (CEEMDAN)
yi ( t ) = y ( t ) + ϵ 0 vi ( t ) i = 1 , 2 , … , n (S1) y^{i}(t)=y(t)+epsilon_0v^i(t)quad i=1,2,dots,ntag{S1}ええ私(t)=ええ(t)+ϵ0ヴ私(t)私=1,2,…,ん(S1)
IMF1 i = E 0 ( yi ( t ) ) + r 1 i IMF1 ‾ = 1 n IMF1 i (S2) text{IMF1}_i=E_0(y^i(t))+r^i_1quad overline{text{IMF1}}=frac1ntext{IMF1}_itag{S2}IMF1私=え0(ええ私(t))+r1私IMF1=ん1IMF1私(シーズン2)
r 1 = yi ( t ) − IMF1 ‾ (S3) r_1=y^i(t)-overline{text{IMF1}}tag{S3}r1=ええ私(t)−IMF1(S3)
IMF2 ‾ = 1 n ∑ i = 1 n E 1 ( r 1 + ϵ 1 E 1 ( vi ( t ) ) ) (S4) overline{text{IMF2}}=frac1nsum^n_{i=1}E_1(r_1+epsilon_1E_1(v^i(t))) tag{S4}IMF2=ん1私=1∑んえ1(r1+ϵ1え1(ヴ私(t)))(S4)
y ( t ) = ∑ l = 1 K − 1 IMF1 ‾ + r K (S5) y(t)=sum^{K-1}_{l=1}overline{text{IMF1}}+r_Ktag{S5}ええ(t)=l=1∑け−1IMF1+rけ(S5)
CEEMDAN-FE 部分では、まず元のデータセットをトレーニング データセットとテスト データセットに分割し、次に CEEMDAN を適用して 2 つのデータセット内の各特徴を複数の固有モード関数 (IMF) に分解します。各 IMF の FE 値の近さに従って、それらは高周波 (IMFH)、中間周波 (IMFM)、低周波 (IMFL)、およびトレンド項 (IMFT) コンポーネントに再構築され、IMF のさまざまな側面を反映します。 。
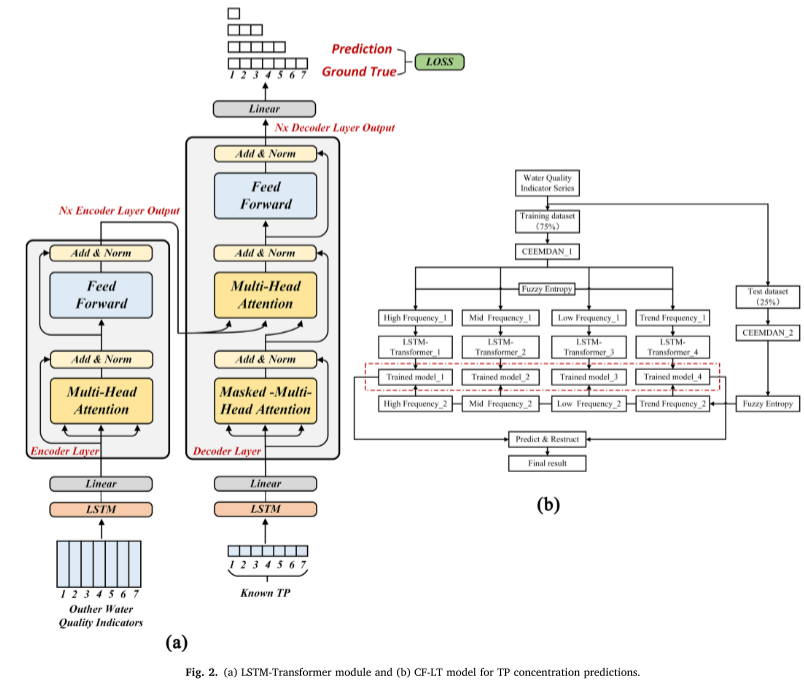
LSTM-Transformer 部分では、エンコーダとデコーダで、LSTM の隠れ層が Transformer 位置エンコーディングによって置き換えられ、入力データ間の時間的依存性が確立されます。具体的な計算プロセスは次のとおりです (図 2a)。
SHAP は、ML モデルの出力を解釈するためのゲーム理論手法です。入力フィーチャがモデル出力に及ぼす影響を判断するには、入力フィーチャ z = [ z 1 , . 。 。 , zp ] z = [z1, ..., zp]ず=[ず1,...,ずp]トレーニングされた深層学習モデルに関連する F.
F = f ( z ) = ϕ 0 + ∑ i = 1 M ϕ izi (12) F=f(z)=phi_0+sum_{i=1}^M phi_iz_i タグ{12}ふ=ふ(ず)=ϕ0+私=1∑まϕ私ず私(12)
φ i ∈ R φ_i ∈ Rφ私∈Rモデルに対する各機能の寄与度を示します。これは次の式で求められます。
ϕ i ( F , x ) = ∑ z ≤ x ∣ z ∣ ! ( M − ∣ z ∣ − 1 ) ! M ! [ F ( z ) − F ( z / i ) ] (13) phi_i(F,x)=sum_{zleq x}frac{|z|!(M-|z|-1)!}{M!}[F(z)-F(z/i)] タグ{13}ϕ私(ふ,バツ)=ず≤バツ∑ま!∣ず∣!(ま−∣ず∣−1)
この研究は、総リン濃度を予測するための新しいモデルを提案しています。このモデルは、CEEM DAN、FE、LSTM、および Transformer テクノロジーを組み合わせており、SHAP を使用してモデル出力を解釈します。この研究の主な目的は、太湖入口における TP 濃度の予測における提案された CEEMDAN-FE-LSTM-Transformer (CF-LT) モデルのパフォーマンスを評価し、SHAP を適用して CF-LT の出力を解釈することです。モデル。これにより、この地域の TP 濃度に影響を与える主要な要因とその応答メカニズムが明らかになるはずです。
高次元データ分解では、多数のモーダル コンポーネントが生成される場合があります。この問題を解決するには、時間計算量を計算する効率的な方法であるファジー エントロピー (FE) を CEEMDAN と組み合わせることができます。この組み合わせにより、CEEMDAN 分解されたサブ信号が効果的に再構築され、サブ周波数モデルの数が削減されます。
LSTMTransformer モデルは、入力データの時系列特性を維持しながら、隣接しない時点間の関係をキャプチャできます。
Transformer モデルは、アテンション メカニズムを使用して、トレーニング中に特定のコンテキストにおける 2 つの場所間の相関関係を特定します。これにより、関連データの効率的な取得が可能になり、情報の重複が軽減されます。
この記事の主な貢献は次の 4 つの側面です。
データセット : 太湖盆地は長江の下流に位置し、面積は 36,900 平方キロメートルで、緻密な河川網と多数の湖があります。太湖は典型的な浅い湖です。この盆地は湿潤な北方亜熱帯気候の特徴を持ち、年間平均気温は 15 ~ 17 ℃、年間平均降水量は 1181 mm です。この研究では、Yaxiangqiao ステーション、Zhihugang ステーション、Guanduqiao ステーションの水質モニタリングデータを使用しました (図 S2)。これらの監視ステーションは、国家の主要な水質評価セクションである太湖口にあります。データは江蘇省環境監視センターから取得したものです。
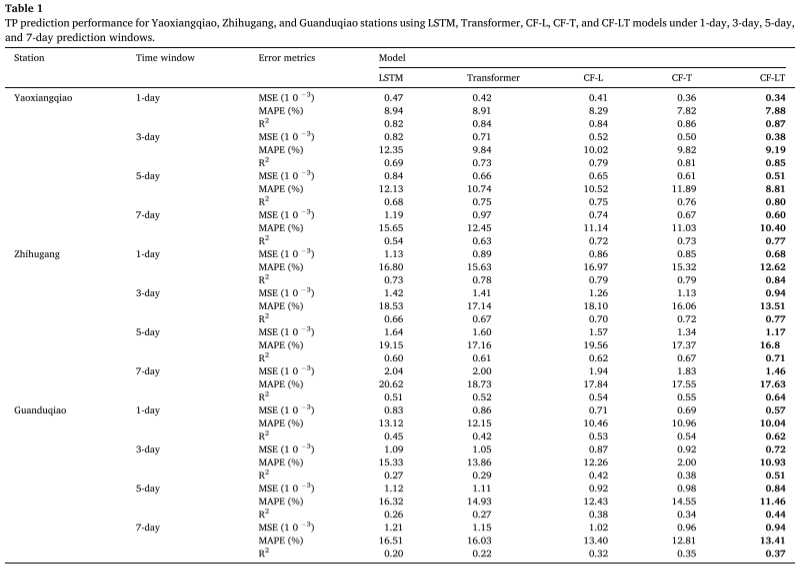
評価基準 : モデルのパフォーマンス評価では、決定係数 (R²)、平均二乗誤差 (MSE)、平均絶対パーセント誤差 (MAPE) などのいくつかの重要な指標が使用されます。 R² は、モデルの予測値と実際の値の間の適合度を測定します。1 に近い場合、MSE は予測誤差の二乗和を測定します。値が小さいほど、予測誤差は小さくなります。 MAPE は、パーセンテージの観点から予測誤差のサイズを反映します。値が低いほど、予測がより正確であることを意味します。
実装の詳細 : 実験プロセスには、データの前処理、モデルのトレーニング、テストが含まれます。さまざまなデータセットと予測時間ウィンドウで提案されたモデルのパフォーマンスを評価するための完全な実験手順が確立されています。まず、データは CEEMDAN-FE メソッドによって前処理されます。このメソッドは、適応ノイズによる完全に統合された経験的モード分解を追加することで情報干渉を除去し、マルチスケール情報を抽出し、ファジー エントロピーを使用してサブ信号の数を削減します。次に、処理されたデータは、75% と 25% の割合でトレーニング セットとテスト セットに分割されます。トレーニング フェーズでは、前処理されたトレーニング データ セットが LSTM-Transformer モデルに入力されます。バックプロパゲーションと Adam オプティマイザーを使用してモデルの重みを更新し、グリッド検索を使用して LSTMTransformer モジュールの最適なハイパーパラメーターを特定し、さまざまな予測時間枠 (7 日、5 日、3 日、1 日) の下でモデルのパフォーマンスが最適になるようにします。
実験結果 : 最適なトレーニング モデルをテスト データ セットに適用し、さまざまなサイトおよびさまざまな予測時間枠での CF-LT、LSTM、Transformer、CF-L、および CF-T モデルによって得られた TP 濃度予測を表にまとめています。提案された CF-LT モデルは、3 つの評価指標すべてに対して最良の結果をもたらします。 R2 に関しては、CF-LT モデルの範囲は 0.37 ~ 0.87 ですが、次に優れた CF-L モデルと CF-T モデルはそれぞれ 0.32 ~ 0.84 と 0.35 ~ 0.86 です。これは、LSTM の長期記憶と Transformer の注意メカニズムを組み合わせることで、予測精度を向上できることを示しています。最悪の LSTM および Transformer モデルを CF-L および CF-T モデルと比較すると、MAPE の範囲は 8.94% ~ 20.62% (LSTM)、8.91% ~ 18.73% (Transformer) から 8.29% ~ 19.56% (CF -L) です。および 7.82% ~ 17.55% (CF-T)。これらの結果は、データ分解と周波数分割モデリングが元のデータに隠されているより多くの情報を捕捉することで予測精度を大幅に向上させることを示しています。
総リンTP濃度に影響を与える要因の予測:
平均絶対 SHAP 値 (MASV) は、TP 予測結果に対する入力特徴 (WT、PH、DO、COD、EC、TU、TN、NH3-N、TP) の寄与を定量化するために使用されます。MASV が大きいほど、モデルの予測結果への影響が大きくなります。研究によると、過去の TP 濃度シリーズ自体に加えて、全窒素 (TN) と濁度 (TU) が TP 予測に影響を与える 2 つの主な要因であることが示されています。これは、TP の変化が過去の濃度に直接影響されるだけでなく、非点源汚染排出や水域内の窒素 - リン比に関連する藻類の成長動態にも密接に関係していることを示しています。特に、TN と TP 間の有意な相関関係は、湖の栄養循環における 2 つの結合効果を強調し、リン濃度予測における非点源窒素入力の重要性を強調しています。
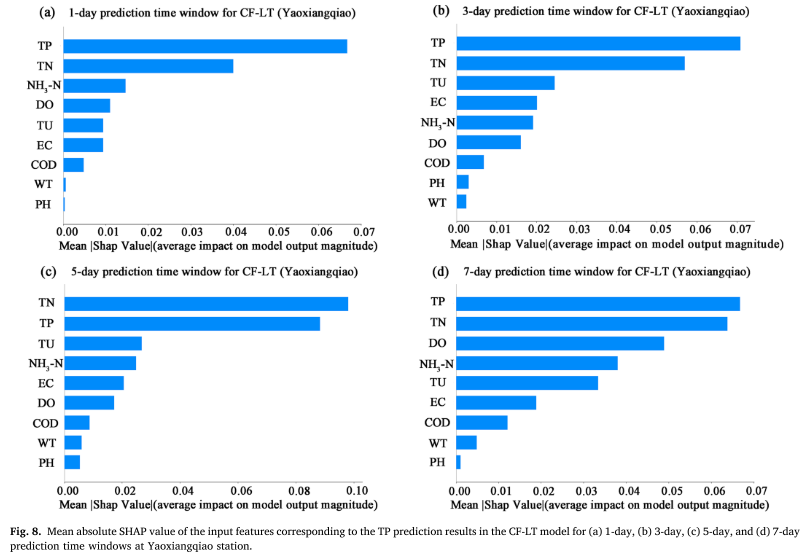
これらの結果から、次のことがわかります。
敵対的なバイアス緩和と正則化との比較 : トレーニング、検証、テストのデータセットに対して 50%/25%/25% をランダムに分割します。図 2 は、すべての手法のパレート最適曲線を示しています。ここで、右下隅の点は理想的なパフォーマンス (最高の精度と最低の予測偏差) を表します。
この記事で提案する CF-LT ハイブリッド モデルは、CEEM DAN、FE、LSTM、および変圧器モジュールを組み合わせて、地表水中の TP 濃度を予測します。このハイブリッド アプローチは、高次元データによって引き起こされるモデルの過適合と過適合、および長期予測を行うときにデータ間の長期依存関係を確立できないという欠点を解決します。さらに、SHAP 値は、CF-LT モデルの出力を解釈するために使用されます。
このモデルは、太湖流域の 3 つの水質監視所からのデータを使用して、異なる予測時間枠で 9 つの水質指標を出力します。 LSTM、Transformer、CF-L、CF-T アルゴリズムが制御モデルとして使用されます。 CF-LT モデルのテスト データ セットの R2 値は 0.37 ~ 0.87、MSE 値は 0.34 × 10-3 ~ 1.46 × 10-3、MAPE 値は 7.88% ~ 17.63% であり、3 つすべてが一致していることを示しています。インジケーターは、LSTM、Transformer、CF-L、CF-T の結果よりも優れています。提案された CF-LT モデルも最良のピーク予測結果を生成しました。 SHAP 解釈に基づいて、TU と TN (TP 濃度の初期時系列を除く) が TP 予測に影響を与える重要な因子であることがわかりました。これは、TP の変化が TP 濃度の初期レベルに関連するだけでなく、TP の影響も受けることを示しています。集中。太湖河口における非点源汚染排出量と水生植物の関係。さらに、TN と TU は雨期の TP 濃度の予測により多く寄与することは注目に値します。したがって、この研究の結果は、CF-LT モデルが、さまざまな環境条件が変化したときの TP の応答メカニズムを理解するための追加情報を提供することを示しています。
CEEMDAN および FE データの前処理
def ceemdan_fe_preprocessing(data):
# CEEMDAN分解
imfs, residue = ceemdan(data, **ceemdan_params)
# 计算各个IMF的模糊熵
fe_values = []
for imf in imfs:
fe_values.append(fuzzy_entropy(imf)) # 假定fuzzy_entropy为计算模糊熵的函数
# 根据FE值重组IMFs
imfs_sorted = [imf for _, imf in sorted(zip(fe_values, imfs))]
imf_hf, imf_mf, imf_lf, imf_trend = imfs_sorted[:4], imfs_sorted[4:8], imfs_sorted[8:12], imfs_sorted[12:]
return np.concatenate((imf_hf, imf_mf, imf_lf, imf_trend), axis=1)
# 应用到数据上
preprocessed_data = ceemdan_fe_preprocessing(original_data)
LSTMとトランスフォーマー
def get_positional_encoding(max_len, d_model):
pe = np.zeros((max_len, d_model))
position = np.arange(0, max_len).reshape(-1, 1)
div_term = np.exp(np.arange(0, d_model, 2) * -(np.log(10000.0) / d_model))
pe[:, 0::2] = np.sin(position * div_term)
pe[:, 1::2] = np.cos(position * div_term)
return pe
def transformer_encoder(inputs, d_model, num_heads, ff_dim):
x = MultiHeadAttention(num_heads=num_heads, key_dim=d_model)(inputs, inputs)
x = LayerNormalization()(Add()([inputs, x]))
x = Dense(ff_dim, activation='relu')(x)
x = Dense(d_model)(x)
x = LayerNormalization()(Add()([inputs, x]))
return x
def transformer_decoder(inputs, encoder_outputs, d_model, num_heads, ff_dim):
return decoder_output
input_features = Input(shape=(input_shape))
lstm_out = LSTM(lstm_units)(input_features) # LSTM
pos_encodings = get_positional_encoding(max_seq_length, d_model)
transformer_in = Add()([lstm_out, pos_encodings])
transformer_encoded = transformer_encoder(transformer_in, d_model, num_heads, ff_dim)
decoder_output = transformer_decoder(decoder_input, transformer_encoded, d_model, num_heads, ff_dim)
output_layer = Dense(output_dim, activation='linear')(decoder_output)
model = Model(inputs=input_features, outputs=output_layer)
model.compile(optimizer=Adam(learning_rate), loss='mse')
この研究では、地表水中の総リン濃度を予測するための解釈可能な CEEMDAN-FE-LSTM-Transformer ハイブリッド モデルを開発しました。このモデルは、高度なデータ前処理技術と深層学習モデルの融合によって予測精度を大幅に向上させ、明確な機能説明を提供します。 SHAP経由で。実験結果により、このモデルの有効性、特に主要な環境要因の特定が確認され、水域の富栄養化管理と汚染制御に強力なツールを提供することが確認されました。

彼は 30 年以上テクノロジーの研究に専念しており、Java、linux、javascript、php、css などのさまざまな言語に堪能であり、オープンソース分野で多くの貢献を行っています。将来の参考のために技術開発におけるいくつかの問題を共有する開発者ドキュメント ステーション。

送料メール: