2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Die Vektordatenbank ist die Kernkomponente der heutigen Praxis zum Abrufen großer Wissensdatenbanken. Die folgende Abbildung ist ein Architekturdiagramm für den Aufbau der Wissensdatenbank: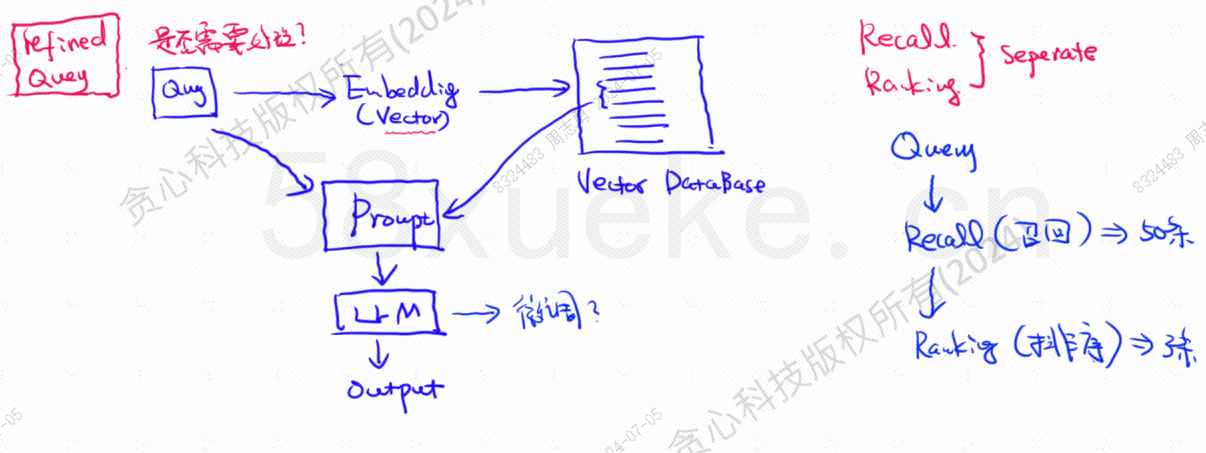
Die Ähnlichkeit zwischen Vektorabfragedaten und Abfrage wirkt sich direkt auf die Qualität der Eingabeaufforderung aus. In diesem Artikel werden die auf dem Markt vorhandenen Vektordatenbanken kurz vorgestellt und anschließend die darin verwendeten Indizierungsmethoden erläutert, einschließlich invertierter Index, KNN, ungefährer KNN, Produktquantisierung. HSNW usw. werden die Entwurfskonzepte und Methoden dieser Algorithmen erläutern.
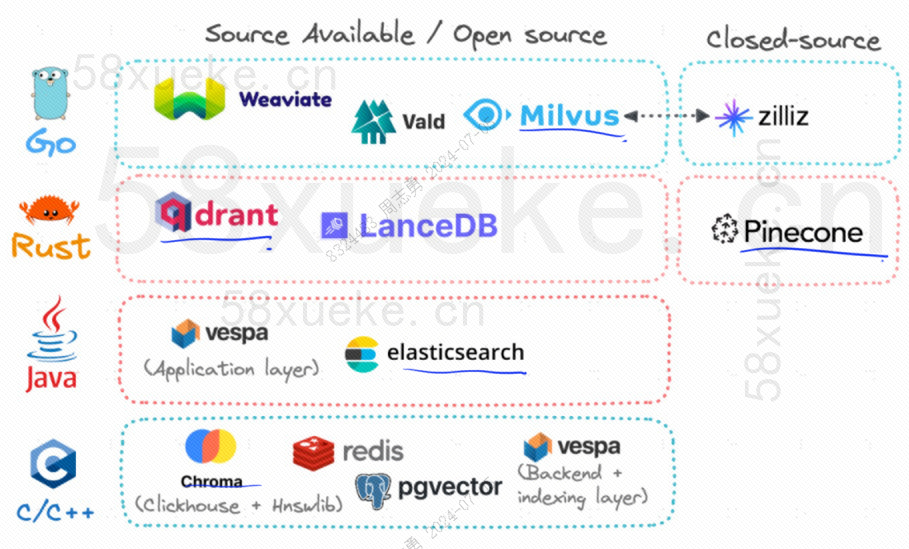
Derzeit sind die drei beliebtesten Open-Source-Vektordatenbanken Chroma, Milvus und Weaviate. Wenn Sie interessiert sind, können Sie diesen Artikel lesen.Konkurrenz zwischen drei großen Open-Source-Vektordatenbanken。
Das Folgende ist die Entwicklungsgeschichte von Open-Source-Vektordatenbanken: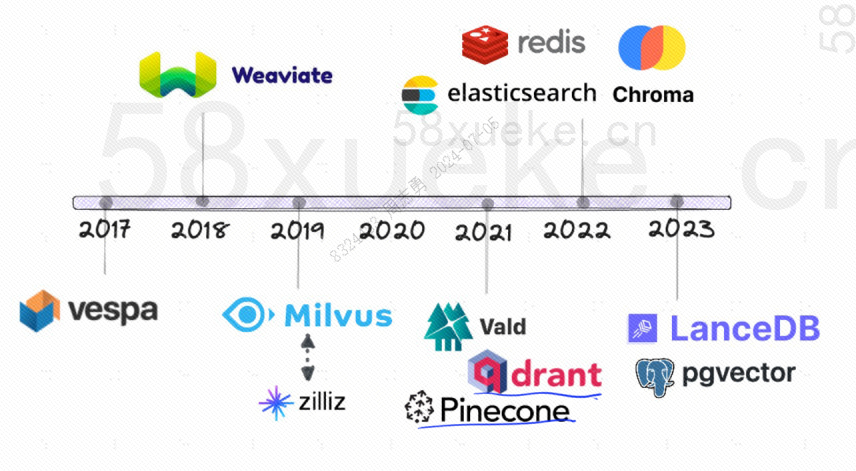
Die von ihnen verwendeten Indizierungsmethoden sind wie folgt:

Wenn ich jetzt eine Datenbank habe, die einen invertierten Index verwendet, der 10 ^ 12 Indexdaten speichert, teilen wir die Daten auf, wenn wir sie in der Datenbank speichern, und zeichnen dann die Wörter auf, die den geteilten Wörtern entsprechen Da dieselben Wörter in verschiedenen Sätzen vorkommen können, entspricht jedes Wort einem Indexsatz:
Angenommen, ich habe jetzt eine Frage: Welche Entwicklungen wird es im Jahr 2024 bei der Anwendung großer Modelle geben?
Die Datenbank unterteilt unsere Abfrageanweisung in drei Schlüsselwörter: großes Modell, 2024, Entwicklung.Fragen Sie dann die Indexkombination ab, die jedem Wort entspricht, und suchen Sie den Schnittpunkt. Dieser Abfragevorgang wird aufgerufenabrufen.
Zu diesem Zeitpunkt haben wir die mit der Abfrage verknüpften Daten erhalten, aber die Ähnlichkeit zwischen diesen Daten und der Abfrageanweisung ist unterschiedlich. Wir müssen sie sortieren und TOP N erhalten.
Diese Art von Abfrage, die Textdaten direkt dem Index zuordnet, ist jedoch nicht sehr effizient. Gibt es eine Möglichkeit, den Ähnlichkeitsabruf zu beschleunigen?
Zu diesem Zeitpunkt erschien der vektorisierte Abruf, bei dem Daten in Vektoren konvertiert und dann der Vektor berechnet wurdenÄhnlichkeitUndDistanzSuchen Sie auf zwei Arten: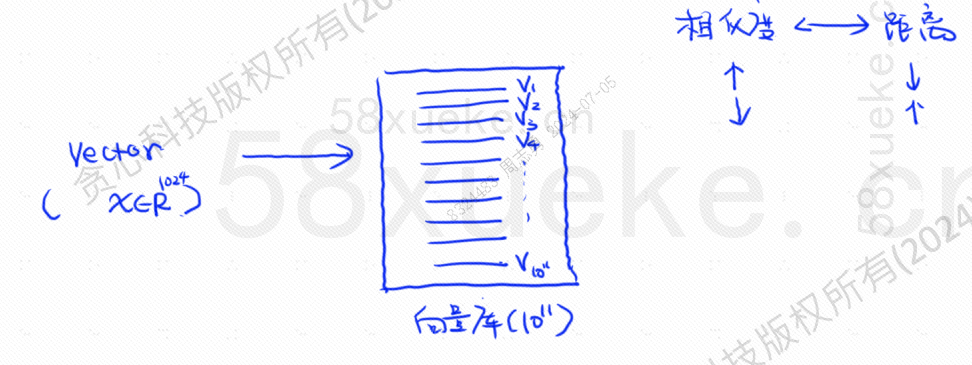
Die KNN-Suche wird als K-Nachbarnsuche bezeichnet. Sie wandelt die Abfrageanweisung in einen Vektor um und findet dann den Vektor und den Vektor in der Datenbank.Die höchste Ähnlichkeit und der geringste AbstandVektorsatz.
Die Zeitkomplexität beträgt O(N)*O(d), d ist die Dimension und die Dimensionsdaten sind im Allgemeinen fest. Angenommen, 10.000 Vektordaten sind in der Datenbank gespeichert und die Dimensionen sind alle 1024, dann die Abfrage maxSim(q,v)(höchste Ähnlichkeit),minDist(q,v)Die zeitliche Komplexität des (nächsten) Vektors beträgt O(10000)*O(1024).
Der Vorteil dieser Abrufmethode besteht darin, dass die gefundenen Daten sehr genau sind, der Nachteil besteht jedoch darin, dass sie langsam ist.
Die ungefähre KNN-Suche besteht darin, den Suchraum von Punkten auf Blöcke zu ändern und dann den nächsten Punkt mit der höchsten Ähnlichkeit im schnellen Raum zu finden. Die linke Seite der Abbildung unten ist die KNN-Suche ungefähre KNN-Suche: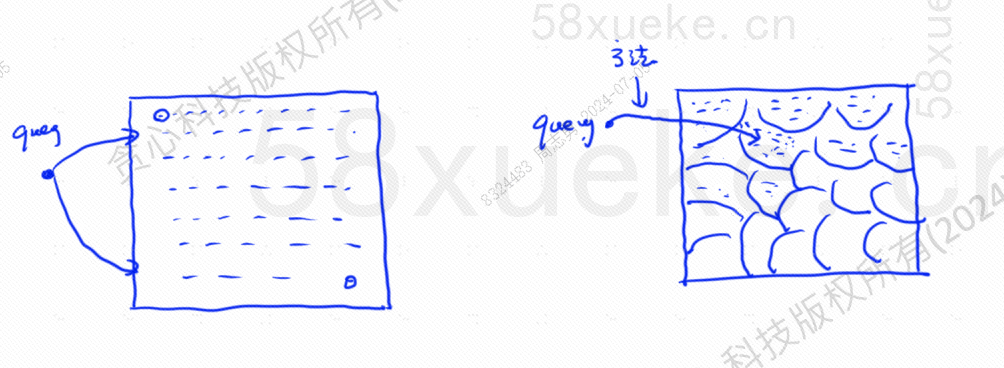
In jedem Block gibt es einen Mittelpunkt. Bei der Berechnung des Abstands zwischen dem Abfragepunkt und dem Block wird der Abstand vom Abfragepunkt zum Mittelpunkt jedes Blocks berechnet: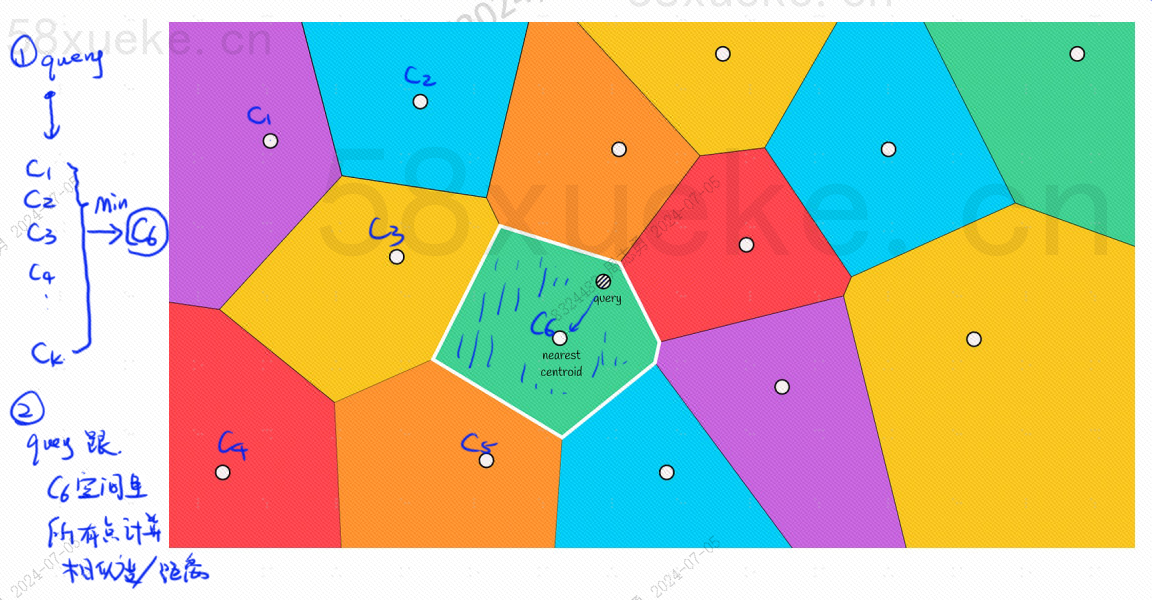
Die Abfrageschritte im Bild oben lauten beispielsweise wie folgt:
Mit bloßem Auge können wir jedoch erkennen, dass die Mittelpunkte der roten und orangefarbenen Blöcke zwar weit vom Abfragepunkt entfernt sind, die Punkte in ihren Blöcken jedoch nahe am Abfragepunkt liegen. Zu diesem Zeitpunkt müssen wir den Umfang erweitern des Suchblocks: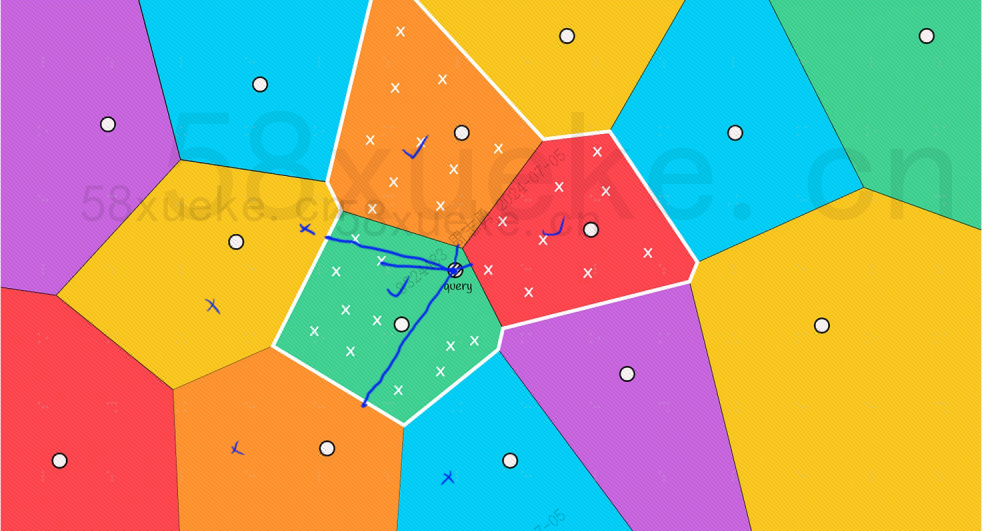
Das Folgende ist die Algorithmusformel zum Ermitteln der höchsten Ähnlichkeit (COS_SIM). Es gibt zwei Algorithmen für die größte Ähnlichkeit, den europäischen Algorithmus und den Manhattan-Algorithmus :
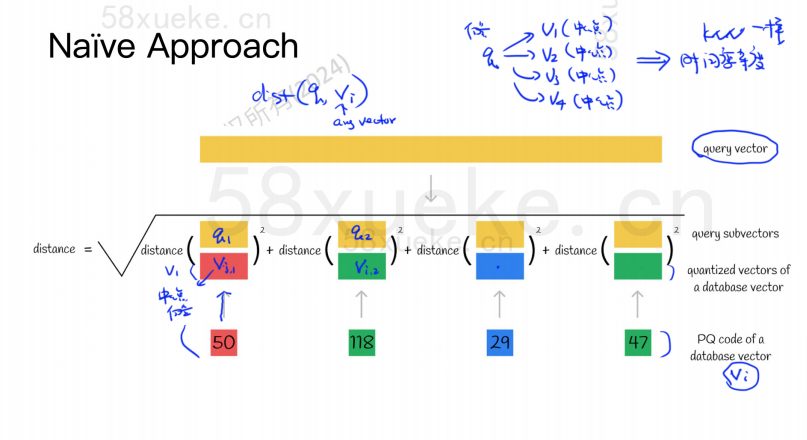
Der PQ-Algorithmus unterteilt zunächst alle Vektoren in mehrere Unterräume. Wie beim ungefähren KNN hat jeder Unterraum einen Mittelpunkt (Schwerpunkt).
Dann wird der ursprüngliche hochdimensionale Vektor in mehrere niedrigdimensionale Vektor-Untervektoren aufgeteilt und der dem Untervektor am nächsten liegende Mittelpunkt wird als PQ-ID des Untervektors verwendet. Dann wird ein hochdimensionaler Vektor erstellt aus mehreren PQ-IDs bestehen, was den Speicherplatz stark komprimiert.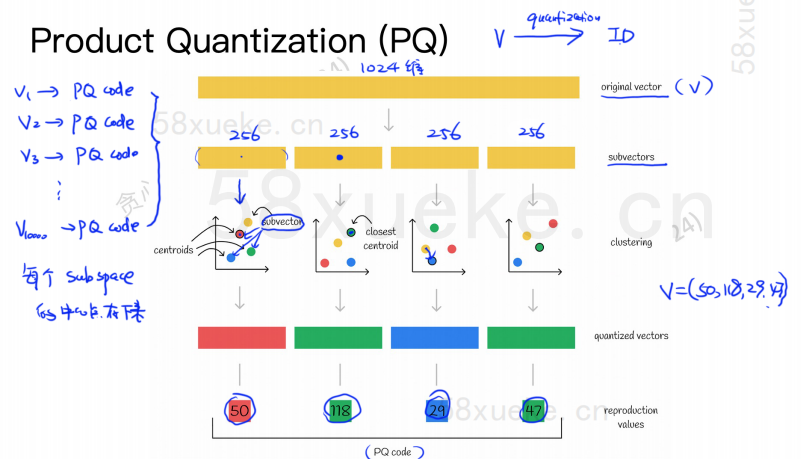
Beispielsweise ist der 1024-dimensionale Vektor in der obigen Abbildung in vier 256-dimensionale Untervektoren aufgeteilt, und die nächsten Mittelpunkte dieser vier Untervektoren sind: 50, 118, 29, 47. Daher kann der 1024-dimensionale Vektor durch V=(50,118,29,47) dargestellt werden, und sein PQ-Code ist ebenfalls (50,118,29,47).
Daher muss die Vektordatenbank, die den PQ-Algorithmus verwendet, die Informationen aller Mittelpunkte und den PQ-Code aller hochdimensionalen Vektoren speichern.
Angenommen, wir haben jetzt eine Abfrageanweisung, die den Vektor mit der höchsten Ähnlichkeit aus der Vektordatenbank abfragen muss. Wie fragt man den PQ-Algorithmus ab?
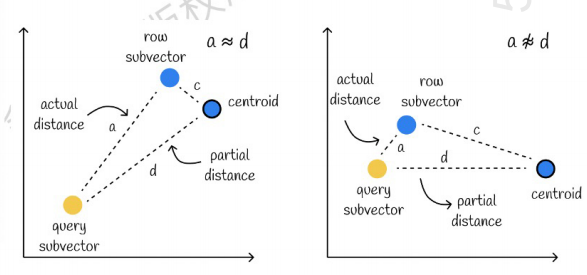
Im linken Fall ist der Fehler sehr klein, im rechten Fall ist der Fehler relativ groß. Im Allgemeinen treten einige Fehler auf, die meisten Fehler sind jedoch relativ klein.
Verwenden Sie Caching, um Berechnungen zu beschleunigen
Wenn der ursprüngliche Abfragevektor und der PQ-Code jedes Untervektors eine Distanzberechnung erfordern, gibt es keinen großen Unterschied zum ungefähren KNN-Algorithmus. Die Raumkomplexität beträgt O(n)*O(k), dann ist die Bedeutung davon Algorithmus ist was? Dient es nur der Komprimierung und der Reduzierung des Speicherplatzes?
Angenommen, alle Vektoren sind in K Unterräume unterteilt und es gibt n Punkte in jedem Unterraum. Wir berechnen im Voraus den Abstand vom Punkt in jedem Unterraum, fügen ihn in eine zweidimensionale Matrix ein und fragen dann den Vektor ab Korrespondenz Wir können den Abstand jedes Subvektors zum Mittelpunkt direkt aus der Matrix abfragen, wie in der folgenden Abbildung dargestellt: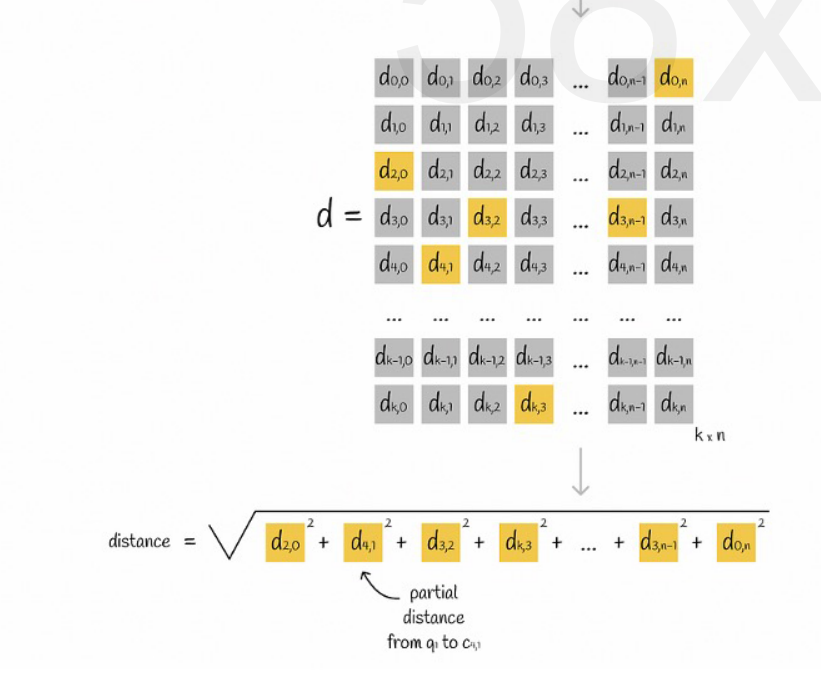
Zum Schluss müssen wir nur noch die Quadratwurzeln der Abstände jedes Untervektors addieren.
Ungefährer KNN kombiniert mit PQ-Algorithmus
Diese beiden Algorithmen stehen nicht in Konflikt. Sie können zunächst alle Vektoren mithilfe von Näherungs-KNN in mehrere Unterräume aufteilen und dann den Abfragevektor im entsprechenden Unterraum lokalisieren.
Auf diese Weise wird der PQ-Algorithmus im Unterraum verwendet, um die Berechnung zu beschleunigen.
In einem bestimmten Vektordatensatz werden K-Vektoren (K-Nearest Neighbor, KNN), die nahe am Abfragevektor liegen, gemäß einer bestimmten Messmethode abgerufen. Aufgrund der übermäßigen Berechnung von KNN konzentrieren wir uns jedoch normalerweise nur auf die Näherungswerte Problem der nächsten Nachbarn (Approximate Nearest Neighbor, ANN).
Beim Zusammenstellen eines Bildes wählt NSW zufällig Punkte aus und fügt sie dem Bild hinzu. Jedes Mal, wenn ein Punkt hinzugefügt wird, werden m Punkte als sein nächster Nachbar ermittelt, um eine Kante hinzuzufügen. Die endgültige Struktur wird wie in der folgenden Abbildung dargestellt gebildet:
Bei der Suche nach NSW-Karten beginnen wir mit vordefinierten Einstiegspunkten. Dieser Einstiegspunkt ist mit mehreren nahegelegenen Eckpunkten verbunden. Wir bestimmen, welcher dieser Eckpunkte unserem Abfragevektor am nächsten liegt, und bewegen uns dorthin.
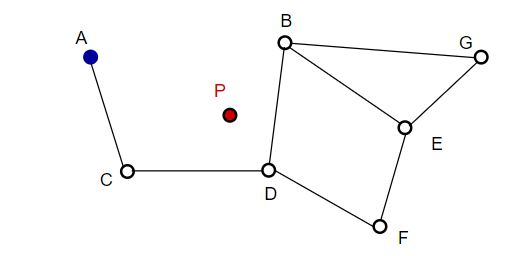
Ausgehend von A wird beispielsweise der Nachbarpunkt C von A näher an P aktualisiert. Dann ist der benachbarte Punkt D von C näher an P, und dann sind die benachbarten Punkte B und F von D nicht näher, und das Programm stoppt, was Punkt D ist.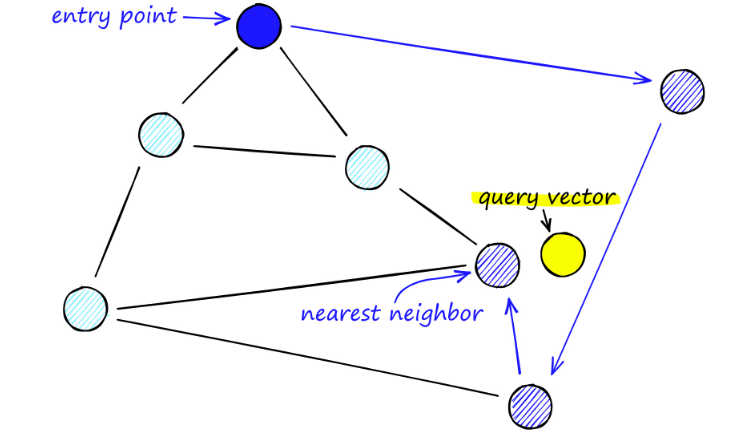
Der Aufbau des Diagramms beginnt auf der obersten Ebene. Im Diagramm durchläuft der Algorithmus gierig die Kanten, um den ef-Nachbarn zu finden, der dem von uns eingefügten Vektor q am nächsten liegt – zu diesem Zeitpunkt ist ef = 1.
Sobald ein lokales Minimum gefunden wurde, wird es auf die nächste Ebene verschoben (genau wie bei der Suche). Wiederholen Sie diesen Vorgang, bis wir die Einfügungsebene unserer Wahl erreichen. Hier beginnt der zweite Bauabschnitt.
Der ef-Wert wird auf den von uns festgelegten efConstruction-Parameter erhöht, was bedeutet, dass mehr nächste Nachbarn zurückgegeben werden. In der zweiten Stufe sind diese nächsten Nachbarn Kandidaten für Links zum neu eingefügten Element q und dienen als Einstiegspunkte zur nächsten Schicht.
Nach vielen Iterationen müssen beim Hinzufügen von Links zwei weitere Parameter berücksichtigt werden. M_max, der die maximale Anzahl von Links definiert, die ein Scheitelpunkt haben kann, und M_max0, der die maximale Anzahl von Verbindungen für einen Scheitelpunkt in Schicht 0 definiert.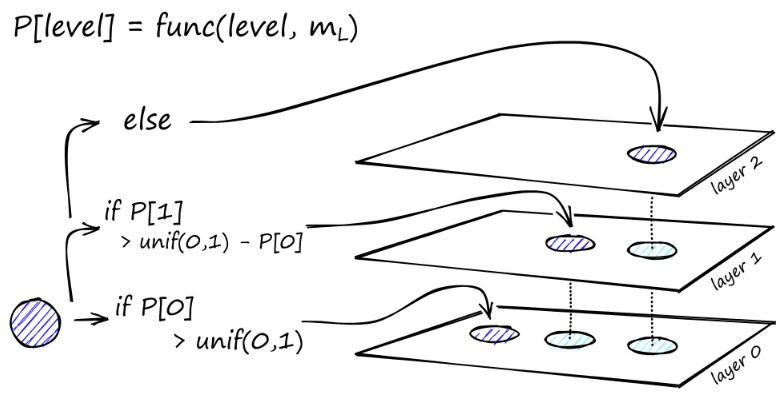
HNSW steht für Hierarchical Navigable Small World, ein mehrschichtiger Graph. Jedes Objekt in der Datenbank wird auf der untersten Ebene erfasst (Ebene 0 im Bild). Diese Datenobjekte sind sehr gut miteinander verbunden. Auf jeder Ebene über der untersten Ebene werden weniger Datenpunkte dargestellt. Diese Datenpunkte stimmen mit den unteren Schichten überein, aber in jeder höheren Schicht gibt es exponentiell weniger Punkte. Bei einer Suchanfrage werden die nächstgelegenen Datenpunkte auf der obersten Ebene gefunden. Im Beispiel unten ist dies nur ein weiterer Datenpunkt. Dann geht es eine Ebene tiefer und findet den Datenpunkt, der dem ersten auf der höchsten Ebene am nächsten liegt, und sucht von dort aus nach nächsten Nachbarn. Auf der tiefsten Ebene wird das tatsächliche Datenobjekt gefunden, das der Suchanfrage am nächsten liegt.
HNSW ist eine sehr schnelle und speichereffiziente Ähnlichkeitssuchmethode, da nur die höchste Schicht (oberste Schicht) im Cache gespeichert wird und nicht alle Datenpunkte in der untersten Schicht. Es werden nur die Datenpunkte geladen, die der Suchanfrage am nächsten liegen, nachdem sie von höheren Schichten angefordert wurden, sodass nur wenig Speicher reserviert werden muss.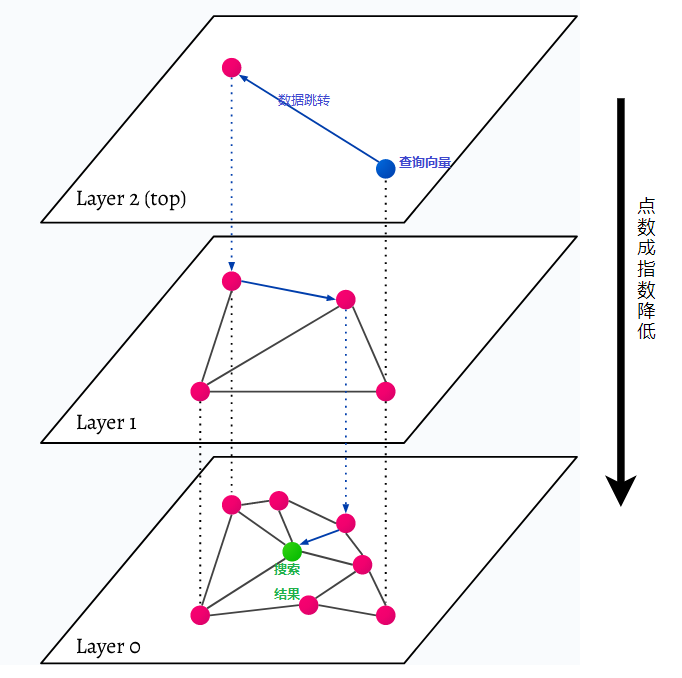

Er widmet sich seit mehr als 30 Jahren der Technologieforschung und beherrscht verschiedene Sprachen wie Java, Linux, Javascript, PHP, CSS usw. Er hat viele Beiträge im Open-Source-Bereich geleistet, Entwicklerdokumentationsstation, um einige Themen in der Technologieentwicklung als zukünftige Referenz zu teilen
