τα στοιχεία επικοινωνίας μου
Ταχυδρομείο[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Η διανυσματική βάση δεδομένων είναι το βασικό συστατικό της σημερινής πρακτικής ανάκτησης βάσης γνώσης μεγάλου μοντέλου Το παρακάτω σχήμα είναι ένα διάγραμμα αρχιτεκτονικής για την ανάκτηση βάσης γνώσεων.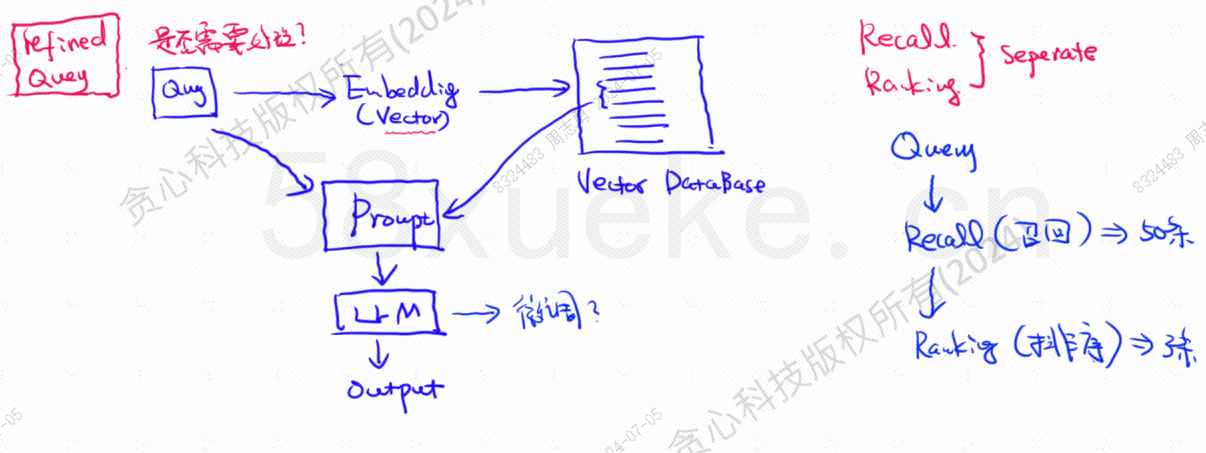
Η ομοιότητα μεταξύ διανυσματικών δεδομένων ερωτήματος και ερωτήματος επηρεάζει άμεσα την ποιότητα του μηνύματος. Το HSNW, κ.λπ., θα εξηγήσει τις έννοιες και τις μεθόδους σχεδιασμού αυτών των αλγορίθμων.
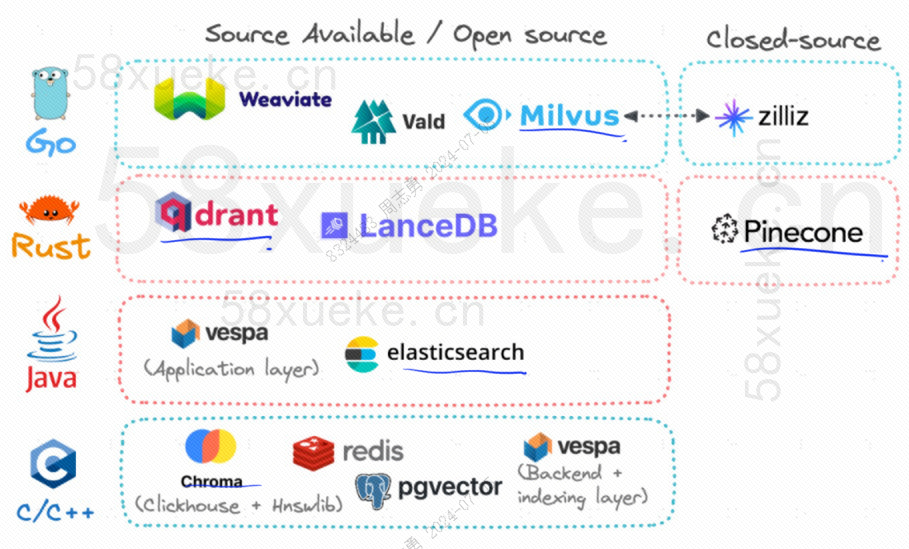
Επί του παρόντος, οι τρεις δημοφιλείς διανυσματικές βάσεις δεδομένων ανοιχτού κώδικα είναι οι Chroma, Milvus και Weaviate, νομίζω ότι αυτό το άρθρο σχετικά με την εισαγωγή και τις διαφορές τους είναι καλό, αν σας ενδιαφέρει.Ανταγωνισμός μεταξύ τριών μεγάλων διανυσματικών βάσεων δεδομένων ανοιχτού κώδικα。
Ακολουθεί το ιστορικό ανάπτυξης διανυσματικών βάσεων δεδομένων ανοιχτού κώδικα: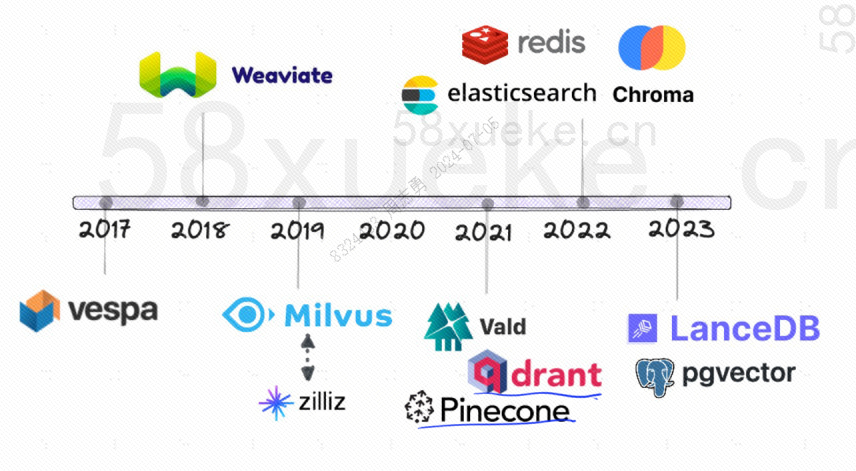
Οι μέθοδοι ευρετηρίασης που χρησιμοποιούν είναι οι εξής:

Εάν τώρα έχω μια βάση δεδομένων που χρησιμοποιεί ένα ανεστραμμένο ευρετήριο, το οποίο αποθηκεύει 10^12 δεδομένα ευρετηρίου, όταν αποθηκεύουμε τα δεδομένα στη βάση δεδομένων, θα διαχωρίσουμε τα δεδομένα και στη συνέχεια θα καταγράψουμε τις λέξεις που αντιστοιχούν στις διαχωρισμένες λέξεις θέσεις Επειδή οι ίδιες λέξεις μπορεί να εμφανίζονται σε διαφορετικές προτάσεις, κάθε λέξη αντιστοιχεί σε ένα σύνολο ευρετηρίου:
Ας υποθέσουμε ότι τώρα έχω ένα ερώτημα: Τι εξελίξεις θα έχει η εφαρμογή μεγάλων μοντέλων το 2024;
Η βάση δεδομένων χωρίζει τη δήλωση ερωτήματός μας σε τρεις λέξεις-κλειδιά: μεγάλο μοντέλο, 2024, ανάπτυξη.Στη συνέχεια, κάντε ερώτημα στον συνδυασμό ευρετηρίου που αντιστοιχεί σε κάθε λέξη και βρείτε τη διασταύρωση Αυτή η διαδικασία ερωτήματος καλείταιανάκληση.
Αυτή τη στιγμή, έχουμε λάβει τα δεδομένα που σχετίζονται με το ερώτημα, αλλά η ομοιότητα μεταξύ αυτών των δεδομένων και της δήλωσης ερωτήματος είναι διαφορετική. Πρέπει να τα ταξινομήσουμε και να πάρουμε το TOP N.
Ωστόσο, αυτό το είδος ερωτήματος που αντιστοιχεί άμεσα σε δεδομένα κειμένου στο ευρετήριο δεν είναι πολύ αποτελεσματικό. Υπάρχει κάποιος τρόπος να επιταχύνουμε την ανάκτηση ομοιότητας;
Αυτή τη στιγμή, εμφανίστηκε διανυσματική ανάκτηση, μετατροπή δεδομένων σε διανύσματα και στη συνέχεια υπολογισμός του διανύσματοςΟμοιότητακαιαπόστασηΑναζήτηση με δύο τρόπους: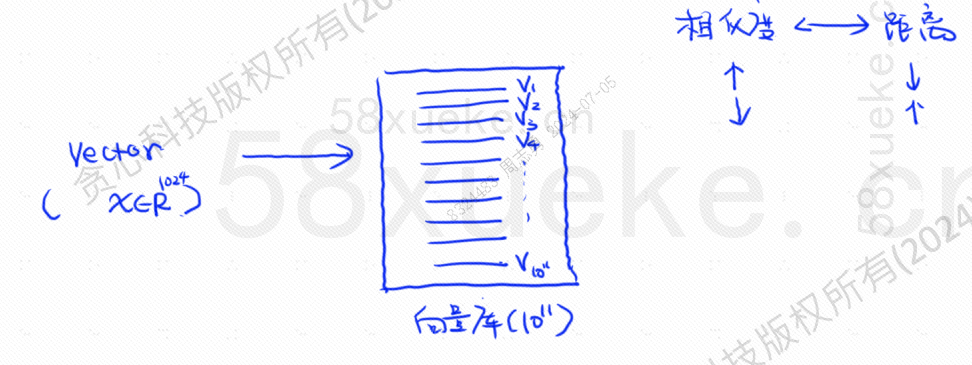
Η αναζήτηση KNN ονομάζεται αναζήτηση του πλησιέστερου γείτονα K Μετατρέπει τη δήλωση ερωτήματος σε διάνυσμα και στη συνέχεια βρίσκει το διάνυσμα και το διάνυσμα στη βάση δεδομένων.Η μεγαλύτερη ομοιότητα και η κοντινότερη απόστασηδιάνυσμα σύνολο.
Η χρονική πολυπλοκότητα είναι O(N)*O(d), d είναι η διάσταση και τα δεδομένα διαστάσεων είναι γενικά σταθερά Ας υποθέσουμε ότι 10.000 διανυσματικά δεδομένα αποθηκεύονται στη βάση δεδομένων και οι διαστάσεις είναι όλες 1024, τότε το ερώτημα. maxSim(q,v)(μεγαλύτερη ομοιότητα),minDist(q,v)Η χρονική πολυπλοκότητα του (πλησιέστερου) διανύσματος είναι O(10000)*O(1024).
Το πλεονέκτημα αυτής της μεθόδου ανάκτησης είναι ότι τα δεδομένα που βρέθηκαν είναι εξαιρετικά ακριβή, αλλά το μειονέκτημα είναι ότι είναι αργή.
Η κατά προσέγγιση αναζήτηση KNN είναι η αλλαγή του χώρου αναζήτησης από σημεία σε μπλοκ και, στη συνέχεια, βρείτε το πλησιέστερο σημείο με την υψηλότερη ομοιότητα στο γρήγορο διάστημα κατά προσέγγιση αναζήτηση KNN: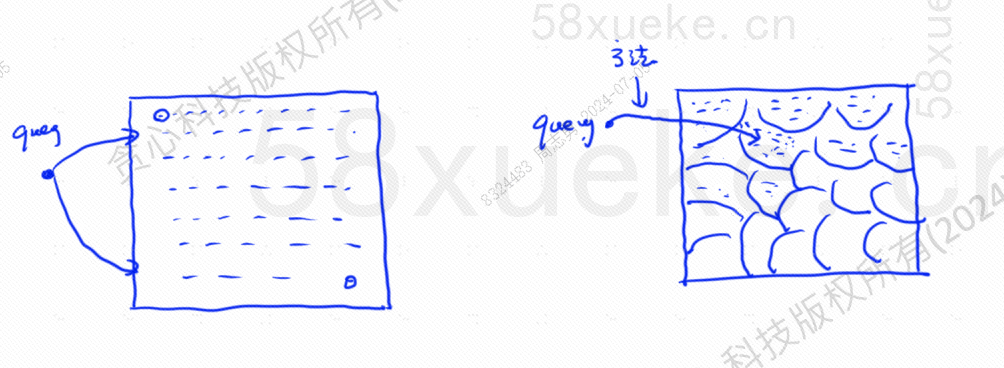
Θα υπάρχει ένα κεντρικό σημείο σε κάθε μπλοκ Ο υπολογισμός της απόστασης μεταξύ του σημείου ερωτήματος και του μπλοκ είναι ο υπολογισμός της απόστασης από το σημείο ερωτήματος στο κεντρικό σημείο κάθε μπλοκ.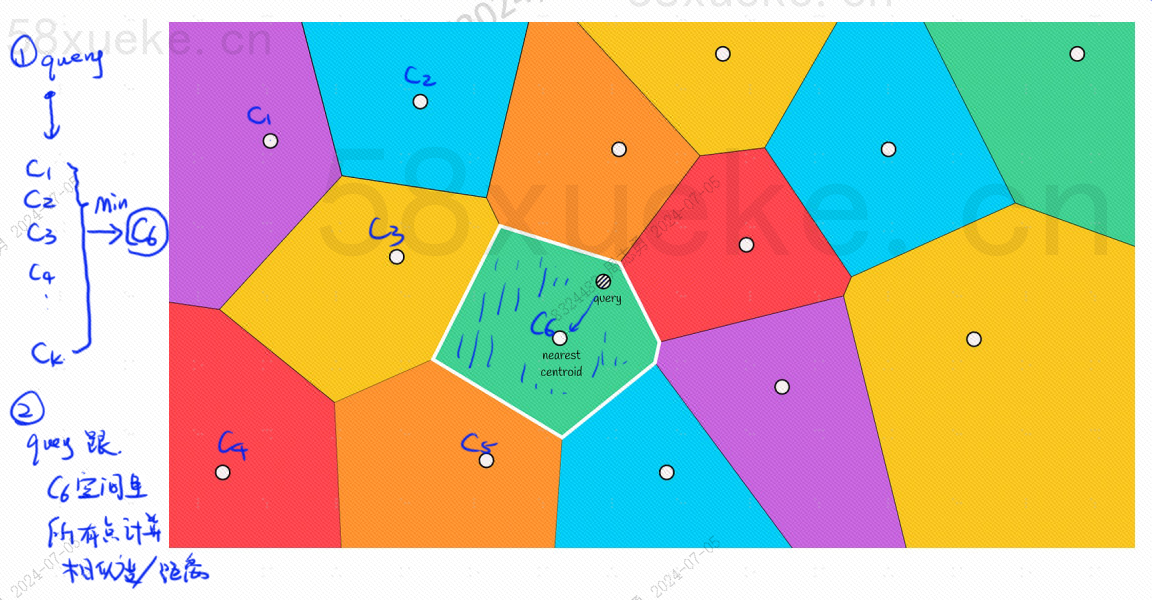
Για παράδειγμα, τα βήματα του ερωτήματος στην παραπάνω εικόνα είναι τα εξής:
Ωστόσο, μπορούμε να δούμε με γυμνό μάτι ότι παρόλο που τα κεντρικά σημεία του κόκκινου και του πορτοκαλί μπλοκ είναι πολύ μακριά από το σημείο ερωτήματος, τα σημεία στα μπλοκ τους είναι κοντά στο σημείο του ερωτήματος αυτήν τη στιγμή, πρέπει να επεκτείνουμε το πεδίο εφαρμογής του μπλοκ αναζήτησης: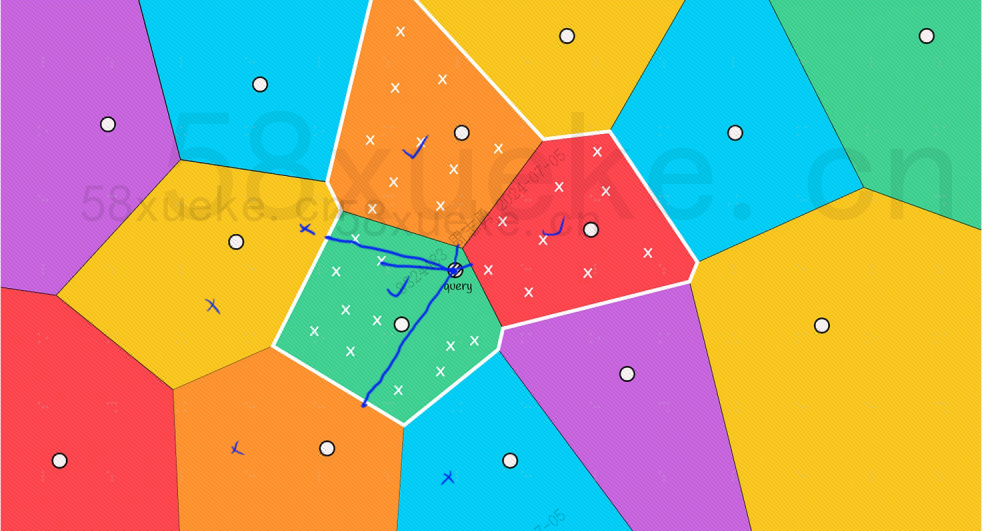
Ακολουθεί ο τύπος του αλγόριθμου για την εύρεση της υψηλότερης ομοιότητας και της πλησιέστερης απόστασης :
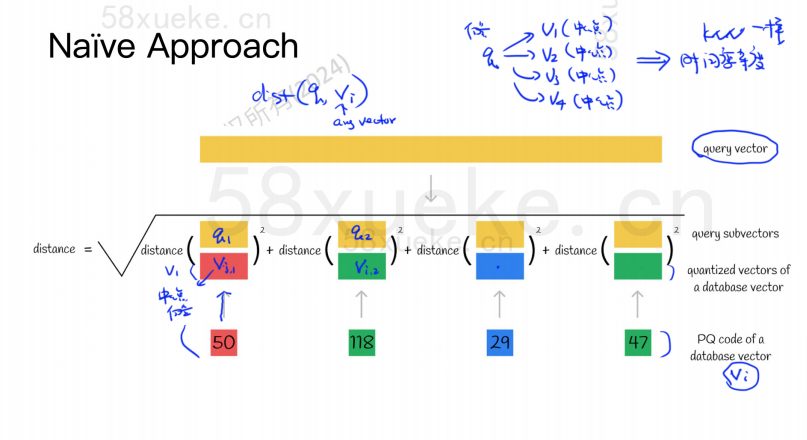
Ο αλγόριθμος PQ διαιρεί πρώτα όλα τα διανύσματα σε πολλαπλούς υποχώρους, όπως και ο κατά προσέγγιση KNN, κάθε υποχώρος έχει ένα κεντρικό σημείο (κεντρικό).
Στη συνέχεια, το αρχικό διάνυσμα υψηλής διάστασης θα χωριστεί σε πολλαπλά διανύσματα χαμηλής διάστασης και το κεντρικό σημείο που βρίσκεται πιο κοντά στο υποδιάνυσμα θα χρησιμοποιηθεί ως το αναγνωριστικό PQ του υποδιανύσματος να αποτελείται από πολλαπλά αναγνωριστικά PQ, τα οποία συμπιέζουν πολύ τον χώρο.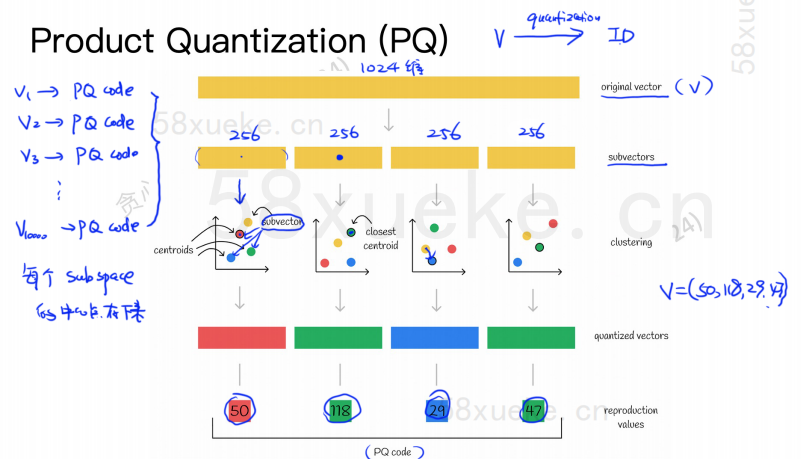
Για παράδειγμα, το διάνυσμα 1024 διαστάσεων στο παραπάνω σχήμα χωρίζεται σε τέσσερα υποδιανύσματα 256 διαστάσεων και τα πλησιέστερα κεντρικά σημεία αυτών των τεσσάρων υποδιανυσμάτων είναι: 50, 118, 29, 47. Επομένως, το διάνυσμα 1024 διαστάσεων μπορεί να αναπαρασταθεί με V=(50,118,29,47), και ο κωδικός PQ του είναι επίσης (50,118,29,47).
Επομένως, η διανυσματική βάση δεδομένων που χρησιμοποιεί τον αλγόριθμο PQ πρέπει να αποθηκεύει τις πληροφορίες όλων των κεντρικών σημείων και τον κωδικό PQ όλων των διανυσμάτων υψηλών διαστάσεων.
Ας υποθέσουμε ότι τώρα έχουμε μια δήλωση ερωτήματος που πρέπει να κάνει ερώτημα στο διάνυσμα με την υψηλότερη ομοιότητα από τη διανυσματική βάση δεδομένων Πώς να κάνετε ερώτημα χρησιμοποιώντας τον αλγόριθμο PQ;
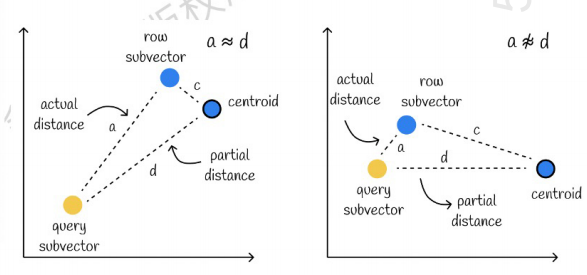
Το ένα στα αριστερά είναι μια περίπτωση όπου το σφάλμα είναι πολύ μικρό, και το ένα στα δεξιά είναι μια περίπτωση όπου το σφάλμα είναι σχετικά μεγάλο Γενικά, θα υπάρχουν μερικά σφάλματα, αλλά τα περισσότερα από τα σφάλματα είναι σχετικά μικρά.
Χρήση προσωρινής αποθήκευσης για επιτάχυνση των υπολογισμών
Εάν το αρχικό διάνυσμα ερωτήματος και ο κωδικός PQ κάθε υποδιανύσματος απαιτούν έναν υπολογισμό απόστασης, τότε δεν υπάρχει μεγάλη διαφορά από τον κατά προσέγγιση αλγόριθμο KNN. Η πολυπλοκότητα του χώρου είναι O(n)*O(k), τότε το νόημα αυτού τι είναι ο αλγόριθμος; Είναι μόνο για συμπίεση και μείωση αποθήκευσης χώρου;
Ας υποθέσουμε ότι όλα τα διανύσματα χωρίζονται σε K υποχώρους και υπάρχουν n σημεία σε κάθε υποχώρο Υπολογίζουμε εκ των προτέρων την απόσταση από το σημείο σε κάθε υποχώρο μέχρι το κεντρικό του σημείο, το βάζουμε σε έναν δισδιάστατο πίνακα και, στη συνέχεια, ρωτάμε το διάνυσμα. αντιστοιχία Μπορούμε να ρωτήσουμε την απόσταση από κάθε υποδιάνυσμα στο κεντρικό σημείο απευθείας από τον πίνακα, όπως φαίνεται στο παρακάτω σχήμα: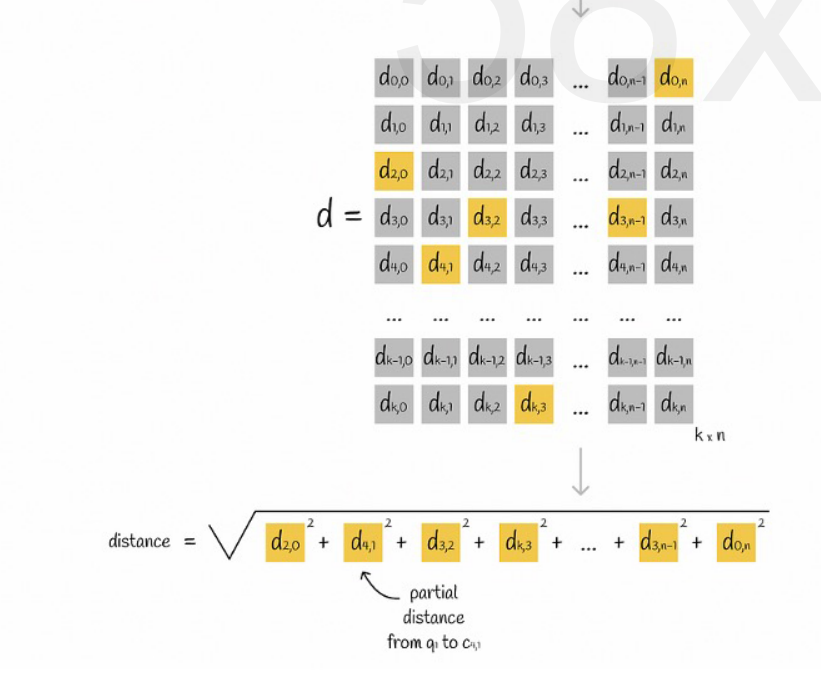
Τέλος, χρειάζεται απλώς να προσθέσουμε τις τετραγωνικές ρίζες των αποστάσεων κάθε υποδιανύσματος.
Κατά προσέγγιση KNN σε συνδυασμό με αλγόριθμο PQ
Αυτοί οι δύο αλγόριθμοι δεν έρχονται σε σύγκρουση Μπορείτε πρώτα να χρησιμοποιήσετε το κατά προσέγγιση KNN για να διαιρέσετε όλα τα διανύσματα σε πολλαπλούς υποχώρους και, στη συνέχεια, να εντοπίσετε το διάνυσμα ερωτήματος στον αντίστοιχο υποχώρο.
Με αυτόν τον τρόπο, ο αλγόριθμος PQ χρησιμοποιείται στον υποχώρο για να επιταχύνει τον υπολογισμό.
Σε ένα δεδομένο διανυσματικό σύνολο δεδομένων, τα διανύσματα K (K-Nearest Neighbor, KNN) που βρίσκονται κοντά στο διάνυσμα ερωτήματος ανακτώνται σύμφωνα με μια συγκεκριμένη μέθοδο μέτρησης, ωστόσο, λόγω του υπερβολικού υπολογισμού του KNN, εστιάζουμε συνήθως μόνο στο κατά προσέγγιση πλησιέστερος γείτονας (Προσέγγιστος Γείτονας, ANN).
Κατά τη σύνθεση μιας εικόνας, η NSW επιλέγει τυχαία σημεία και τα προσθέτει στην εικόνα. Κάθε φορά που προστίθεται ένα σημείο, τα m σημεία αναζητούνται για τους πλησιέστερους γείτονές του για προσθήκη ακμών. Η τελική δομή διαμορφώνεται όπως φαίνεται στο παρακάτω σχήμα:
Όταν αναζητούμε χάρτες NSW, ξεκινάμε από προκαθορισμένα σημεία εισόδου. Αυτό το σημείο εισόδου συνδέεται με πολλές κοντινές κορυφές. Καθορίζουμε ποια από αυτές τις κορυφές είναι πιο κοντά στο διάνυσμα του ερωτήματός μας και μετακινούμαστε εκεί.
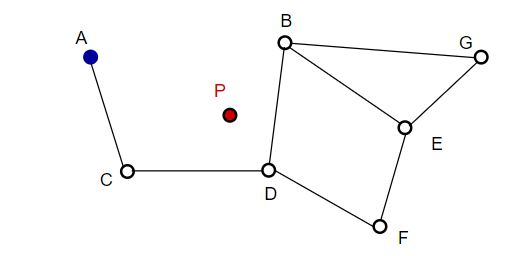
Για παράδειγμα, ξεκινώντας από το Α, το γειτονικό σημείο Γ του Α ενημερώνεται πιο κοντά στο P. Τότε το διπλανό σημείο D του C είναι πιο κοντά στο P, και τότε τα διπλανά σημεία B και F του D δεν είναι πιο κοντά, και το πρόγραμμα σταματά, που είναι το σημείο D.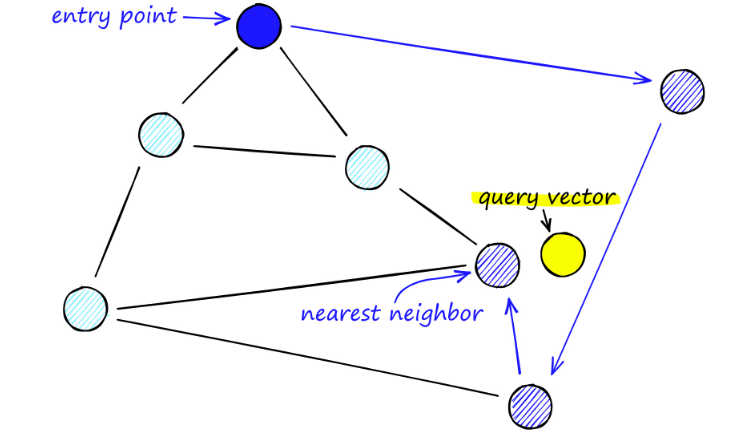
Η κατασκευή του γραφήματος ξεκινά από το ανώτερο επίπεδο. Μόλις μπει στο γράφημα, ο αλγόριθμος διασχίζει άπληστα τις άκρες για να βρει τον πλησιέστερο γείτονα ef στο διάνυσμα q που εισαγάγαμε - αυτή τη στιγμή ef = 1.
Μόλις βρεθεί ένα τοπικό ελάχιστο, μετακινείται στο επόμενο επίπεδο (όπως ακριβώς έγινε κατά την αναζήτηση). Επαναλάβετε αυτή τη διαδικασία μέχρι να φτάσουμε στο στρώμα εισαγωγής της επιλογής μας. Εδώ ξεκινά η δεύτερη φάση κατασκευής.
Η τιμή ef αυξάνεται στην παράμετρο efConstruction που ορίσαμε, πράγμα που σημαίνει ότι θα επιστραφούν περισσότεροι πλησιέστεροι γείτονες. Στο δεύτερο στάδιο, αυτοί οι πλησιέστεροι γείτονες είναι υποψήφιοι για συνδέσμους στο νεοεισαχθέν στοιχείο q και χρησιμεύουν ως σημεία εισόδου στο επόμενο επίπεδο.
Μετά από πολλές επαναλήψεις, υπάρχουν δύο ακόμη παράμετροι που πρέπει να λάβετε υπόψη κατά την προσθήκη συνδέσμων. M_max, που ορίζει τον μέγιστο αριθμό συνδέσμων που μπορεί να έχει μια κορυφή και M_max0, που ορίζει τον μέγιστο αριθμό συνδέσεων για μια κορυφή στο επίπεδο 0.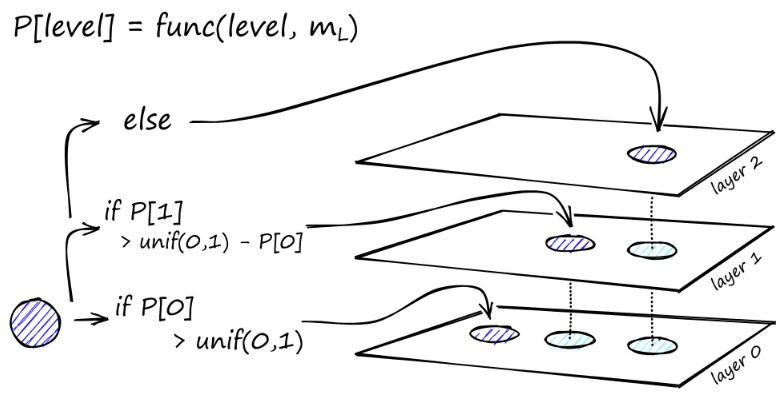
Το HNSW σημαίνει Hierarchical Navigable Small World, ένα γράφημα πολλαπλών επιπέδων. Κάθε αντικείμενο στη βάση δεδομένων καταγράφεται στο χαμηλότερο επίπεδο (επίπεδο 0 στην εικόνα). Αυτά τα αντικείμενα δεδομένων συνδέονται πολύ καλά. Σε κάθε επίπεδο πάνω από το χαμηλότερο επίπεδο, αντιπροσωπεύονται λιγότερα σημεία δεδομένων. Αυτά τα σημεία δεδομένων ταιριάζουν με τα χαμηλότερα επίπεδα, αλλά υπάρχουν εκθετικά λιγότερα σημεία σε κάθε υψηλότερο επίπεδο. Εάν υπάρχει ένα ερώτημα αναζήτησης, τα πλησιέστερα σημεία δεδομένων θα βρεθούν στο ανώτερο επίπεδο. Στο παρακάτω παράδειγμα, αυτό είναι μόνο ένα ακόμη σημείο δεδομένων. Στη συνέχεια πηγαίνει ένα επίπεδο βαθύτερα και βρίσκει το πλησιέστερο σημείο δεδομένων από το πρώτο που βρέθηκε στο υψηλότερο επίπεδο και αναζητά τους πλησιέστερους γείτονες από εκεί. Στο βαθύτερο επίπεδο, θα βρεθεί το πραγματικό αντικείμενο δεδομένων που βρίσκεται πιο κοντά στο ερώτημα αναζήτησης.
Το HNSW είναι μια πολύ γρήγορη και αποδοτική μέθοδος αναζήτησης ομοιότητας στη μνήμη, επειδή μόνο το υψηλότερο επίπεδο (επάνω επίπεδο) αποθηκεύεται στην κρυφή μνήμη και όχι όλα τα σημεία δεδομένων στο χαμηλότερο επίπεδο. Μόνο τα σημεία δεδομένων που βρίσκονται πιο κοντά στο ερώτημα αναζήτησης φορτώνονται αφού ζητηθούν από υψηλότερα επίπεδα, πράγμα που σημαίνει ότι πρέπει να δεσμευτεί μόνο μια μικρή ποσότητα μνήμης.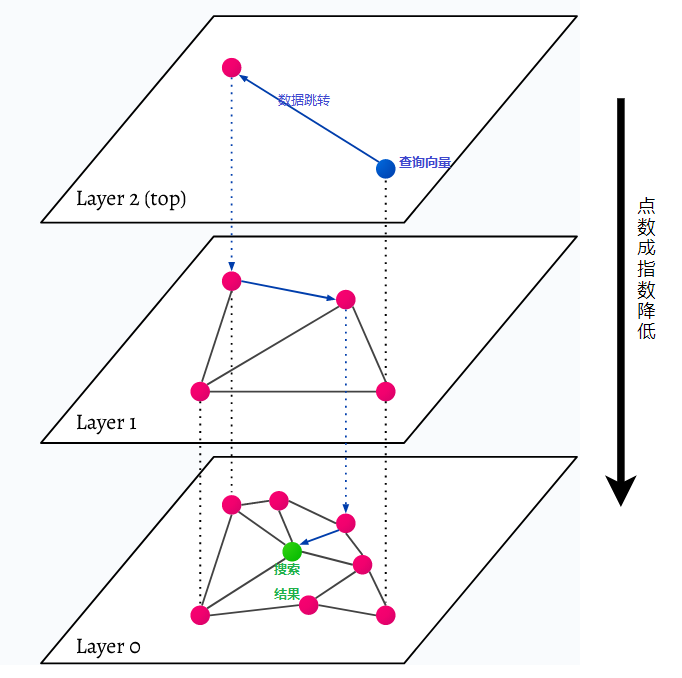

Έχει αφοσιωθεί στην έρευνα της τεχνολογίας για περισσότερα από 30 χρόνια και είναι ικανός σε διάφορες γλώσσες όπως java, linux, javascript, php, css κ.λπ. Έχει κάνει πολλές συνεισφορές στον τομέα του ανοιχτού κώδικα σταθμός τεκμηρίωσης προγραμματιστή για να μοιραστείτε ορισμένα ζητήματα στην ανάπτυξη τεχνολογίας για μελλοντική αναφορά

Ταχυδρομείο[email protected]