minhas informações de contato
Correspondência[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
O banco de dados vetorial é o componente principal da prática atual de recuperação da base de conhecimento de grandes modelos. A figura a seguir é um diagrama de arquitetura para construir a recuperação da base de conhecimento: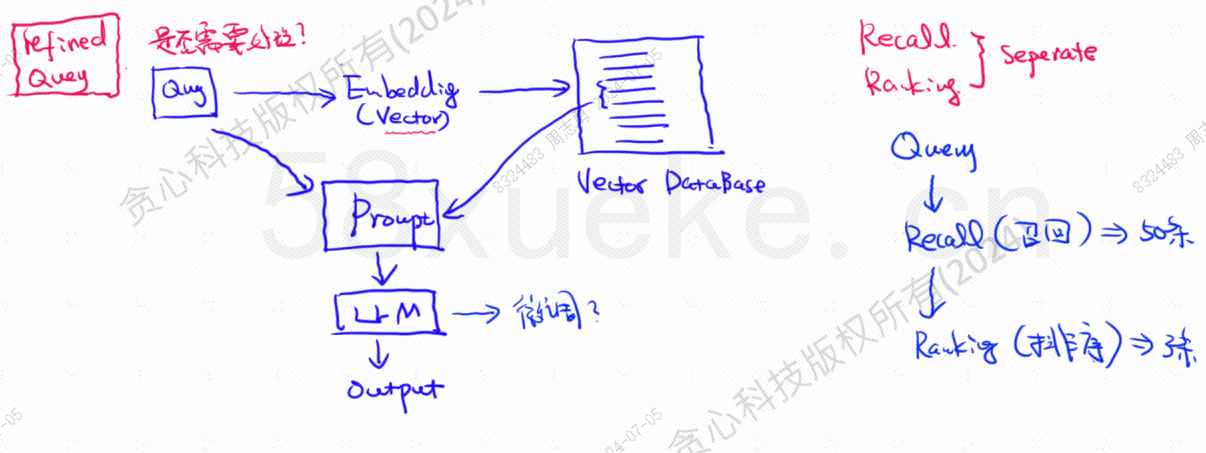
A semelhança entre os dados de consulta vetorial e a consulta afeta diretamente a qualidade do prompt. Este artigo apresentará brevemente os bancos de dados vetoriais existentes no mercado e, em seguida, explicará os métodos de indexação neles usados, incluindo índice invertido, KNN, KNN aproximado, Quantização de produto, HSNW, etc., explicará os conceitos e métodos de design desses algoritmos.
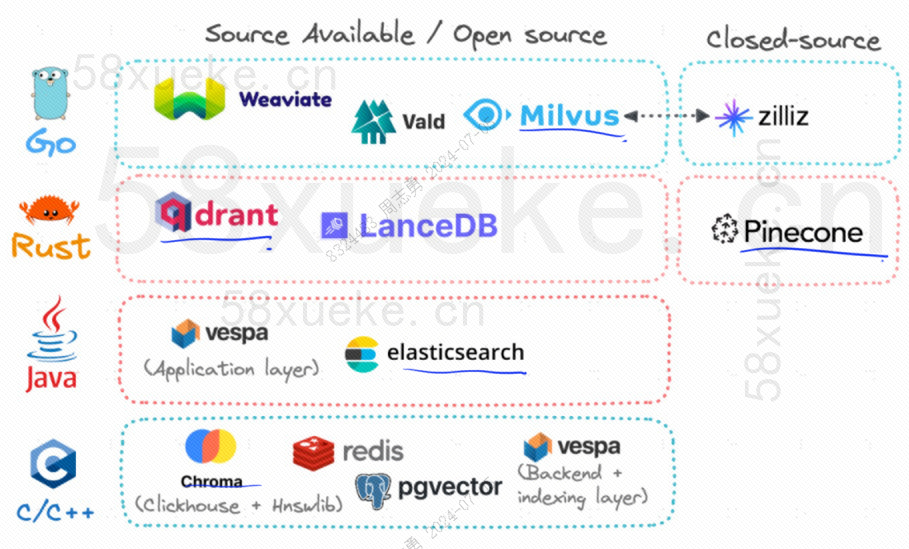
Atualmente, os três bancos de dados vetoriais de código aberto populares são Chroma, Milvus e Weaviate. Acho que este artigo sobre sua introdução e diferenças é bom. Se você estiver interessado, pode lê-lo:Competição entre três grandes bancos de dados vetoriais de código aberto。
A seguir está o histórico de desenvolvimento de bancos de dados vetoriais de código aberto: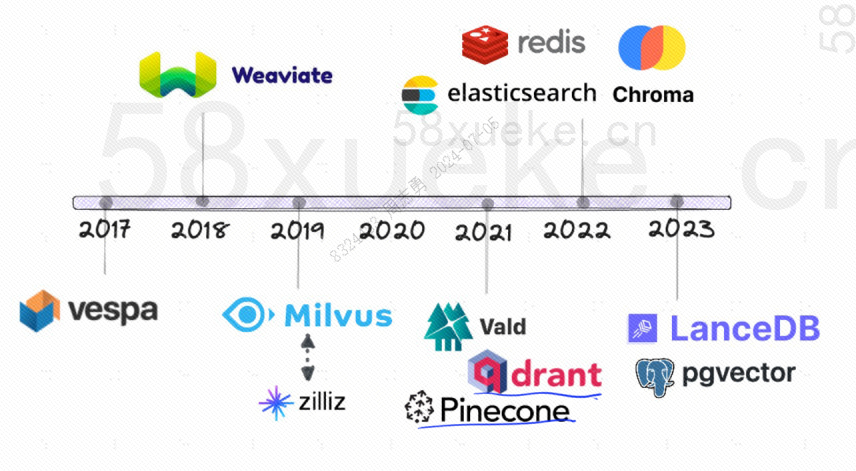
Os métodos de indexação que eles usam são os seguintes:

Se agora eu tiver um banco de dados que usa um índice invertido, que armazena dados de índice 10 ^ 12, quando armazenarmos os dados no banco de dados, dividiremos os dados e, em seguida, registraremos as palavras correspondentes às palavras divididas. posições? Como as mesmas palavras podem aparecer em frases diferentes, cada palavra corresponde a um conjunto de índices:
Suponha que agora eu tenha uma consulta: Que desenvolvimentos terá a aplicação de grandes modelos em 2024?
O banco de dados divide nossa consulta em três palavras-chave: modelo grande, 2024, desenvolvimento.Em seguida, consulte a combinação de índice correspondente a cada palavra e encontre a interseção. Esse processo de consulta é chamado.lembrar.
Neste momento, obtivemos os dados associados à consulta, mas a semelhança entre esses dados e a instrução da consulta é diferente. Precisamos classificá-los e obter o TOP N.
No entanto, esse tipo de consulta que corresponde diretamente aos dados de texto ao índice não é muito eficiente. Existe alguma maneira de acelerar a recuperação de similaridade?
Nessa época, surgiu a recuperação vetorizada, convertendo os dados em vetores e depois calculando o vetorSemelhançaedistânciaPesquise de duas maneiras: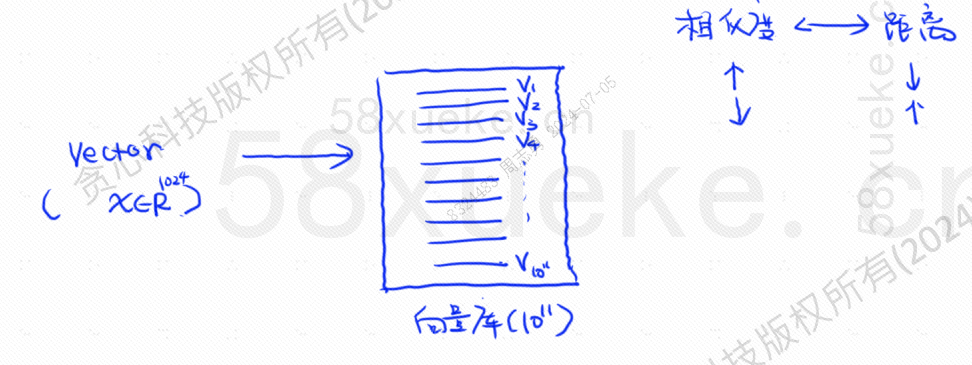
A pesquisa KNN é chamada de pesquisa do vizinho mais próximo K. Ela converte a instrução de consulta em um vetor e, em seguida, encontra o vetor e o vetor no banco de dados.A maior semelhança e a distância mais próximaconjunto de vetores.
A complexidade de tempo é O(N)*O(d), d é a dimensão e os dados dimensionais são geralmente fixos. Suponha que 10.000 dados vetoriais sejam armazenados no banco de dados e que as dimensões sejam todas 1024, então a consulta. maxSim(q,v)(maior similaridade),minDist(q,v)A complexidade de tempo do vetor (mais próximo) é O(10000)*O(1024).
A vantagem deste método de recuperação é que os dados encontrados são altamente precisos, mas a desvantagem é que é lento.
A pesquisa KNN aproximada consiste em alterar o espaço de pesquisa de pontos para blocos. Primeiro, determine o bloco mais próximo e, em seguida, encontre o ponto mais próximo com a maior similaridade no espaço rápido. O lado esquerdo da figura abaixo é a pesquisa KNN e a borda é. pesquisa KNN aproximada: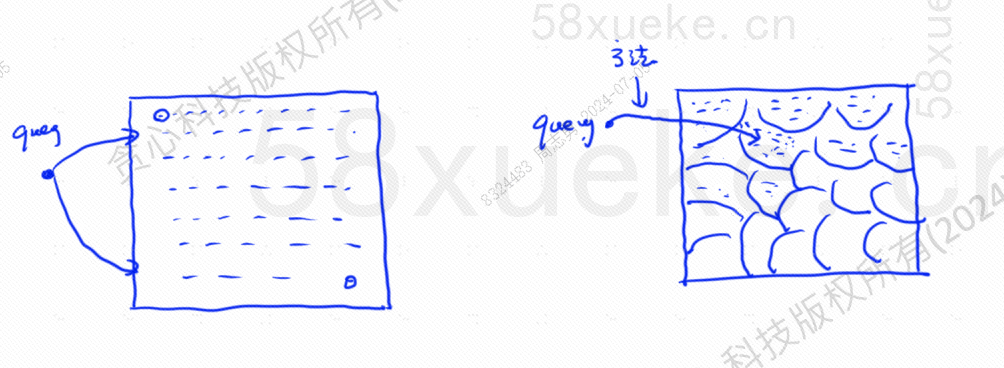
Haverá um ponto central em cada bloco. Calcular a distância entre o ponto de consulta e o bloco é calcular a distância do ponto de consulta ao ponto central de cada bloco: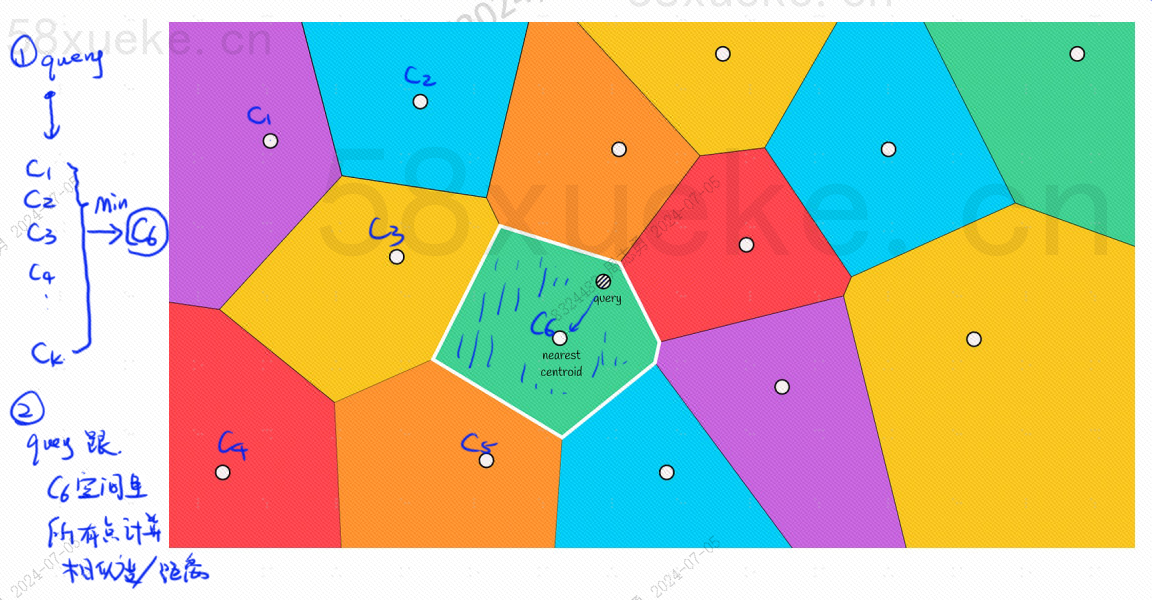
Por exemplo, as etapas de consulta na imagem acima são as seguintes:
No entanto, podemos ver a olho nu que embora os pontos centrais dos blocos vermelho e laranja estejam longe do ponto de consulta, os pontos em seus blocos estão próximos do ponto de consulta. Neste momento, precisamos expandir o escopo. do bloco de pesquisa: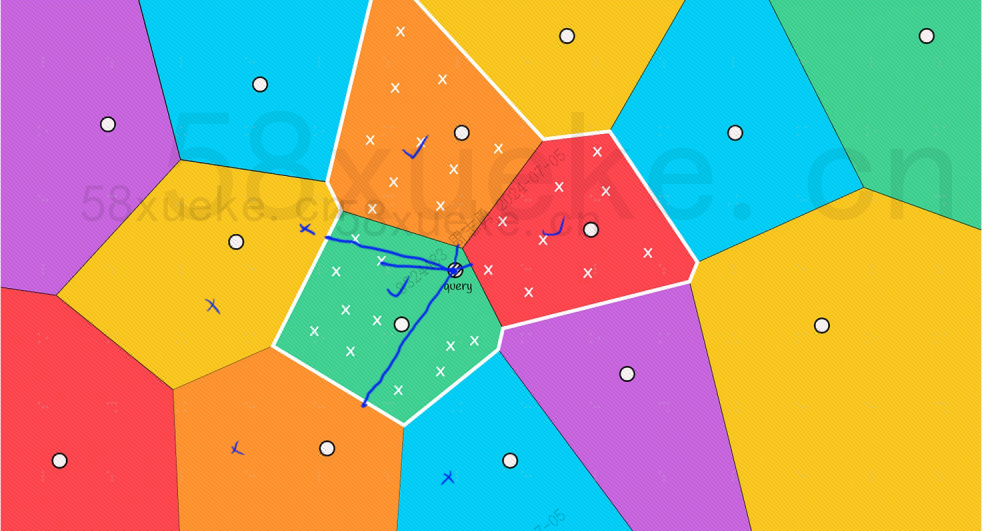
A seguir está a fórmula do algoritmo para encontrar a maior similaridade e a distância mais próxima. A maior similaridade (COS_SIM) é calculada através do cosseno. Existem dois algoritmos para a distância mais próxima, o algoritmo europeu e o algoritmo de Manhattan. :
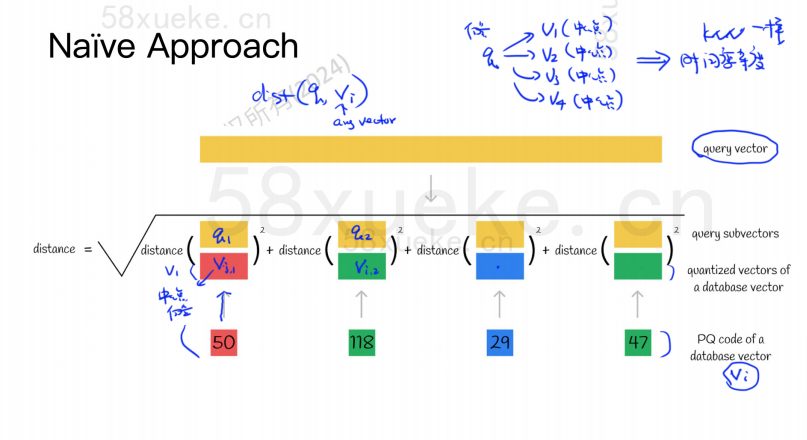
O algoritmo PQ primeiro divide todos os vetores em vários subespaços. Como o KNN aproximado, cada subespaço possui um ponto central (centróide).
Em seguida, o vetor original de alta dimensão será dividido em vários subvetores vetoriais de baixa dimensão e o ponto central mais próximo do subvetor será usado como o PQ ID do subvetor. ser composto por vários IDs PQ, que comprimem bastante o espaço.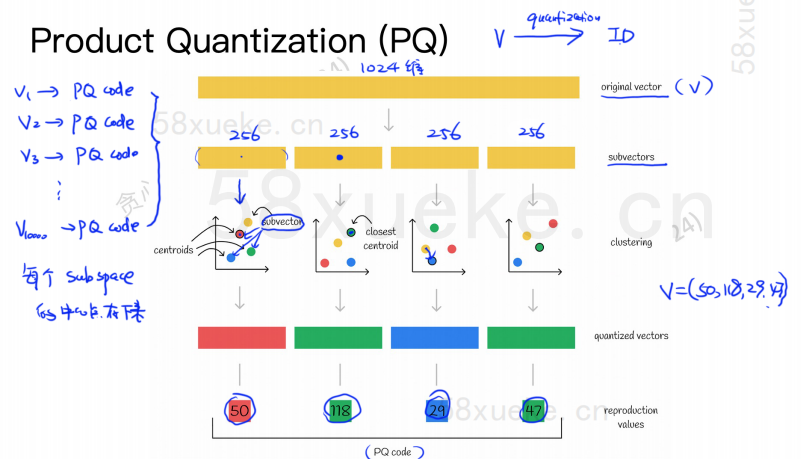
Por exemplo, o vetor de 1.024 dimensões na figura acima é dividido em quatro subvetores de 256 dimensões, e os pontos centrais mais próximos desses quatro subvetores são: 50, 118, 29, 47. Portanto, o vetor de 1024 dimensões pode ser representado por V=(50,118,29,47), e seu código PQ também é (50,118,29,47).
Portanto, o banco de dados vetorial usando o algoritmo PQ precisa salvar as informações de todos os pontos centrais e o código PQ de todos os vetores de alta dimensão.
Suponha que agora temos uma instrução de consulta que precisa consultar o vetor com maior similaridade no banco de dados vetorial. Como consultar usando o algoritmo PQ?
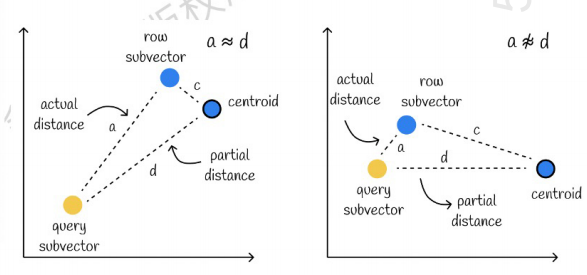
O da esquerda é um caso em que o erro é muito pequeno e o da direita é um caso em que o erro é relativamente grande. Geralmente, haverá alguns erros, mas a maioria dos erros é relativamente pequena.
Usando cache para acelerar cálculos
Se o vetor de consulta original e o código PQ de cada subvetor exigirem um cálculo de distância, então não há muita diferença em relação ao algoritmo KNN aproximado. A complexidade do espaço é O(n)*O(k), então o significado disso. algoritmo é o quê? É apenas para compactação e redução de espaço de armazenamento?
Suponha que todos os vetores sejam divididos em K subespaços e que haja n pontos em cada subespaço. Calculamos antecipadamente a distância do ponto em cada subespaço ao seu ponto central, colocamos em uma matriz bidimensional e depois consultamos o vetor. correspondência Podemos consultar a distância de cada subvetor ao ponto central diretamente da matriz, conforme mostrado na figura a seguir: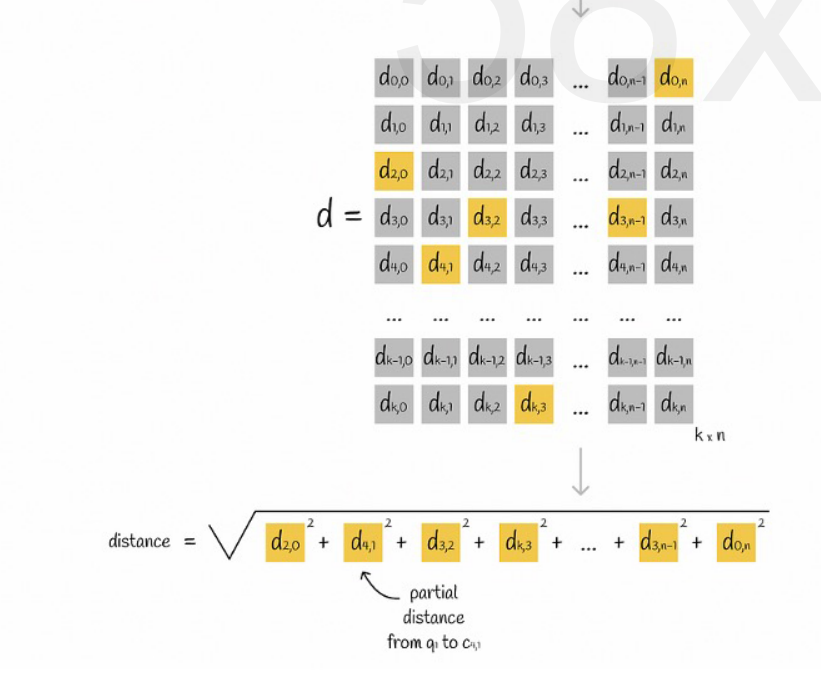
Finalmente, só precisamos somar as raízes quadradas das distâncias de cada subvetor.
KNN aproximado combinado com algoritmo PQ
Esses dois algoritmos não entram em conflito. Você pode primeiro usar o KNN aproximado para dividir todos os vetores em vários subespaços e, em seguida, localizar o vetor de consulta no subespaço correspondente.
Desta forma, o algoritmo PQ é utilizado no subespaço para agilizar o cálculo.
Em um determinado conjunto de dados vetoriais, K vetores (K-Nearest Neighbor, KNN) próximos ao vetor de consulta são recuperados de acordo com um determinado método de medição. No entanto, devido ao cálculo excessivo de KNN, geralmente nos concentramos apenas no aproximado. problema dos vizinhos mais próximos (vizinho mais próximo aproximado, RNA).
Ao compor uma imagem, o NSW seleciona pontos aleatoriamente e os adiciona à imagem. Cada vez que um ponto é adicionado, m pontos são considerados o vizinho mais próximo para adicionar uma aresta. A estrutura final é formada conforme mostrado na figura abaixo:
Ao pesquisar mapas de NSW, partimos de pontos de entrada predefinidos. Este ponto de entrada está conectado a vários vértices próximos. Determinamos qual desses vértices está mais próximo do nosso vetor de consulta e movemos para lá.
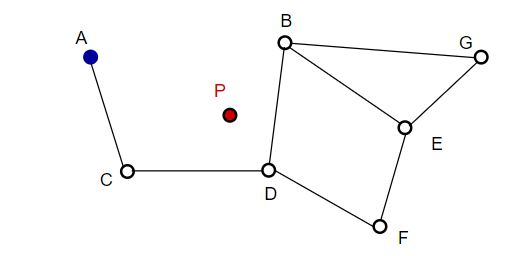
Por exemplo, partindo de A, o ponto vizinho C de A é atualizado mais próximo de P. Então o ponto adjacente D de C está mais próximo de P, e então os pontos adjacentes B e F de D não estão mais próximos, e o programa para, que é o ponto D.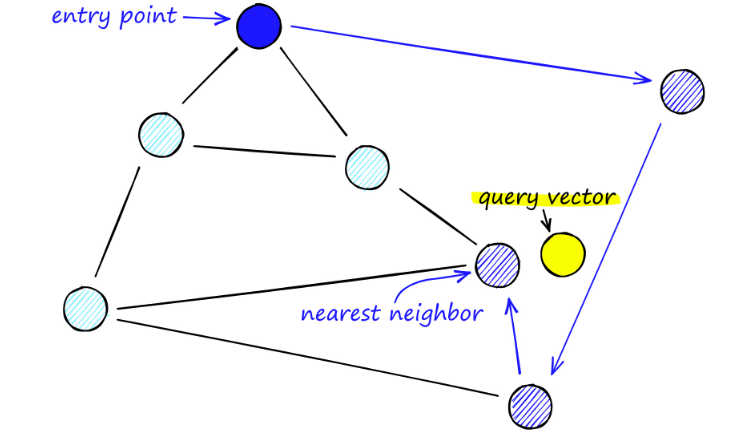
A construção do gráfico começa no nível superior. Uma vez no gráfico, o algoritmo percorre avidamente as arestas para encontrar o vizinho ef mais próximo do vetor q que inserimos - neste momento ef = 1.
Uma vez encontrado um mínimo local, ele desce para o próximo nível (exatamente como foi feito durante a pesquisa). Repita este processo até chegarmos à camada de inserção de nossa escolha. Aqui começa a segunda fase de construção.
O valor ef é aumentado para o parâmetro efConstruction que definimos, o que significa que mais vizinhos mais próximos serão retornados. No segundo estágio, esses vizinhos mais próximos são candidatos a links para o elemento q recém-inserido e servem como pontos de entrada para a próxima camada.
Depois de muitas iterações, há mais dois parâmetros a serem considerados ao adicionar links. M_max, que define o número máximo de links que um vértice pode ter, e M_max0, que define o número máximo de conexões para um vértice na camada 0.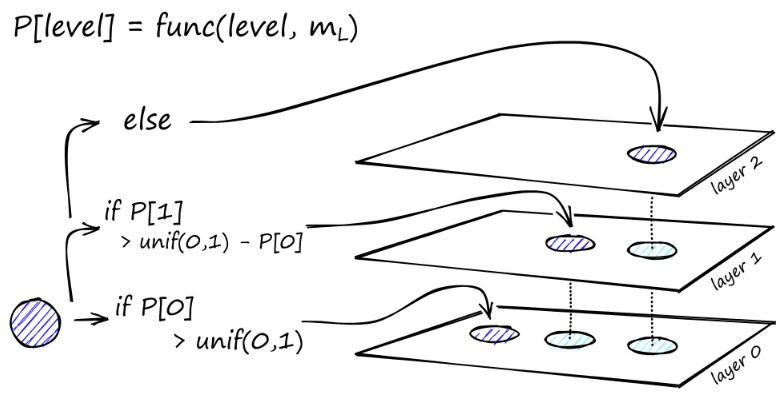
HNSW significa Hierarchical Navigable Small World, um gráfico multicamadas. Cada objeto no banco de dados é capturado no nível mais baixo (nível 0 na imagem). Esses objetos de dados estão muito bem conectados. Em cada camada acima da camada mais baixa, menos pontos de dados são representados. Esses pontos de dados correspondem às camadas inferiores, mas há exponencialmente menos pontos em cada camada superior. Se houver uma consulta de pesquisa, os pontos de dados mais próximos serão encontrados no nível superior. No exemplo abaixo, este é apenas mais um ponto de dados. Em seguida, ele vai um nível mais fundo e encontra o ponto de dados mais próximo do primeiro encontrado no nível mais alto e procura os vizinhos mais próximos a partir daí. No nível mais profundo, o objeto de dados real mais próximo da consulta de pesquisa será encontrado.
HNSW é um método de pesquisa de similaridade muito rápido e eficiente em termos de memória porque apenas a camada mais alta (camada superior) é salva no cache, em vez de todos os pontos de dados na camada mais baixa. Somente os pontos de dados mais próximos da consulta de pesquisa são carregados após serem solicitados pelas camadas superiores, o que significa que apenas uma pequena quantidade de memória precisa ser reservada.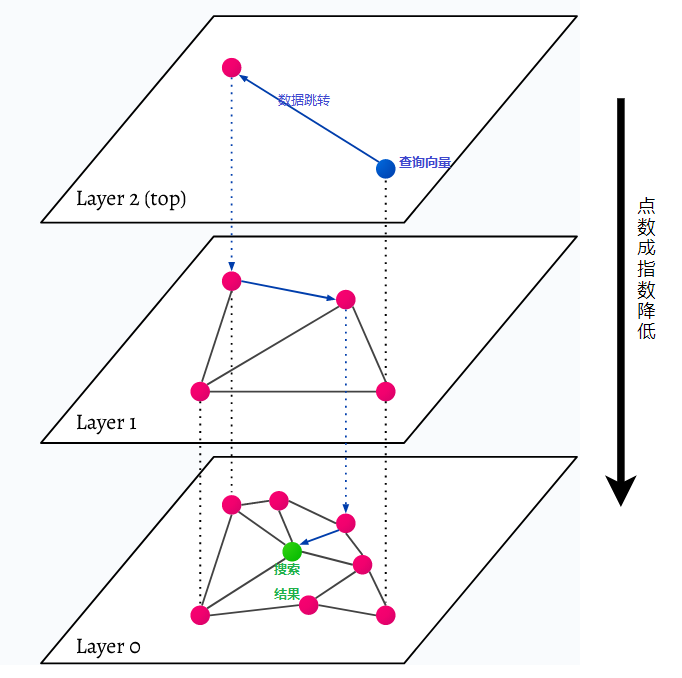

Ele se dedica à pesquisa de tecnologia há mais de 30 anos e é proficiente em diversas linguagens como java, linux, javascript, php, css, etc. estação de documentação do desenvolvedor para compartilhar alguns problemas no desenvolvimento de tecnologia para referência futura.

Correspondência[email protected]