моя контактная информация
Почтамезофия@protonmail.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
База данных векторов является основным компонентом современной практики поиска данных из базы знаний больших моделей. На следующем рисунке показана архитектурная схема построения поиска из базы знаний: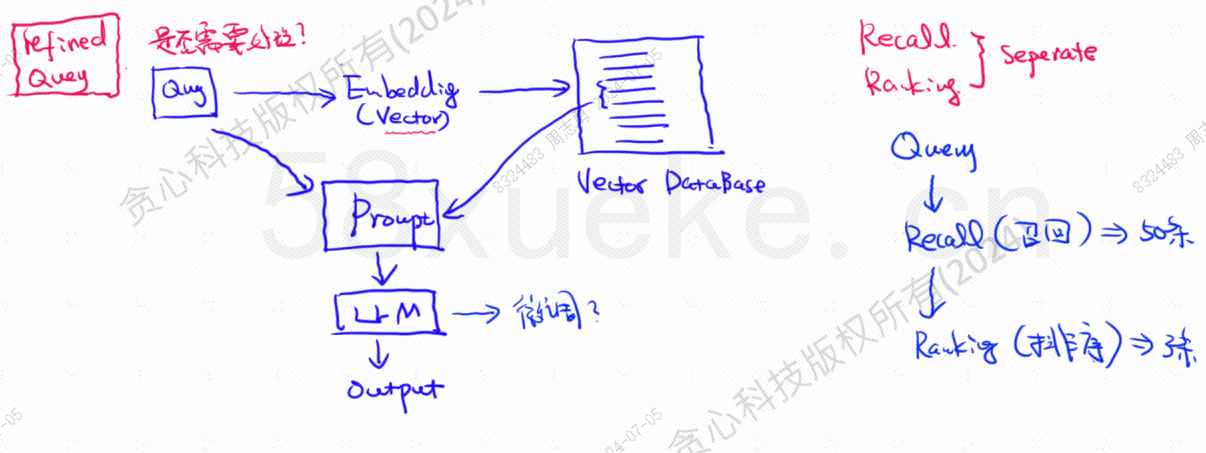
Сходство между данными векторного запроса и запросом напрямую влияет на качество подсказки. В этой статье будут кратко представлены существующие на рынке векторные базы данных, а затем объяснены методы индексации, используемые в них, включая инвертированный индекс, KNN, Приблизительный KNN, Квантование продукта. HSNW и т. д. объяснят концепции проектирования и методы этих алгоритмов.
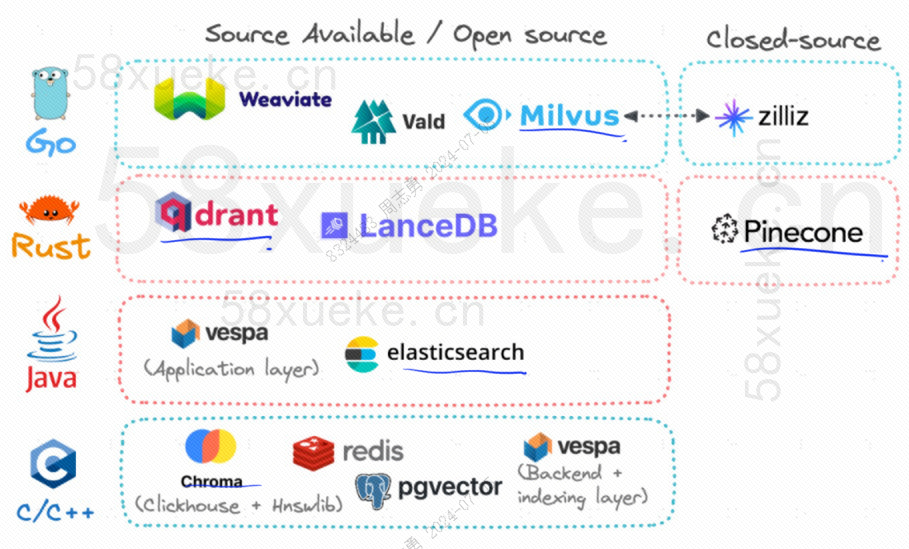
В настоящее время тремя популярными векторными базами данных с открытым исходным кодом являются Chroma, Milvus и Weaviate. Я думаю, что эта статья об их введении и различиях будет полезной. Если вам интересно, вы можете прочитать ее:Конкуренция между тремя основными векторными базами данных с открытым исходным кодом。
Ниже представлена история развития векторных баз данных с открытым исходным кодом: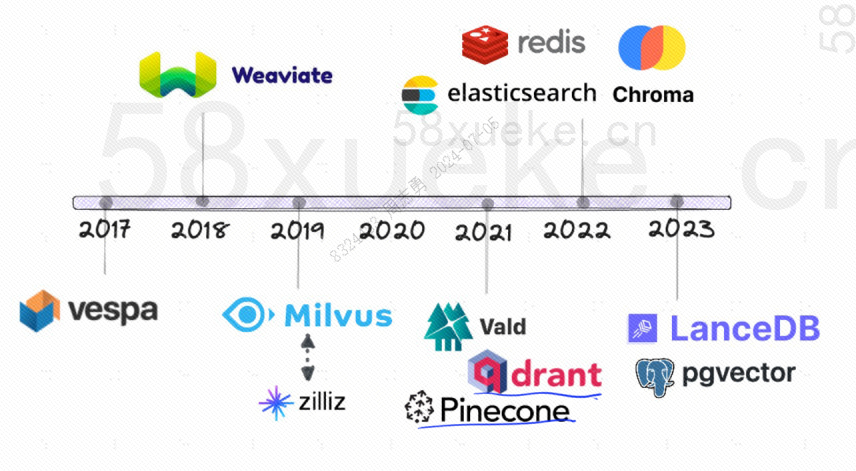
Они используют следующие методы индексации:

Если теперь у меня есть база данных, которая использует инвертированный индекс, в котором хранятся данные индекса 10 ^ 12, когда мы сохраняем данные в базе данных, мы разделим данные, а затем запишем слова, соответствующие разделенным словам. Что такое индекс. позиции? Поскольку одни и те же слова могут встречаться в разных предложениях, каждому слову соответствует набор индексов:
Предположим, теперь у меня есть запрос: Какие изменения будут иметь применение крупных моделей в 2024 году?
База данных разделяет наш запрос на три ключевых слова: большая модель, 2024 год, разработка.Затем запросите комбинацию индексов, соответствующую каждому слову, и найдите пересечение. Этот процесс запроса называется.отзывать.
На данный момент мы получили данные, связанные с запросом, но сходство между этими данными и оператором запроса другое. Нам нужно отсортировать их и получить TOP N.
Однако такой запрос, который напрямую сопоставляет текстовые данные с индексом, не очень эффективен. Можно ли как-нибудь ускорить поиск сходства?
В это время появился векторизованный поиск, преобразующий данные в векторы, а затем вычисляющий вектор.СходствоирасстояниеИскать двумя способами: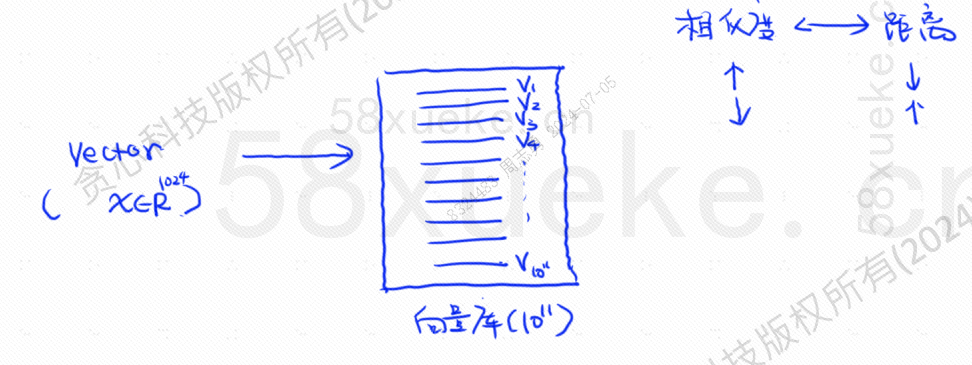
Поиск KNN называется поиском ближайшего соседа K. Он преобразует оператор запроса в вектор, а затем находит вектор и вектор в базе данных.Наивысшее сходство и наименьшее расстояниевекторный набор.
Временная сложность равна O(N)*O(d), d — размерность, а размерные данные обычно фиксированы. Предположим, что в базе данных хранится 10 000 векторных данных, а все измерения равны 1024, тогда запрос. maxSim(q,v)(наивысшее сходство),minDist(q,v)Временная сложность (ближайшего) вектора равна O(10000)*O(1024).
Преимущество этого метода поиска в том, что найденные данные очень точны, а недостаток в том, что он медленный.
Приблизительный поиск KNN заключается в изменении пространства поиска с точек на блоки. Сначала определите ближайший блок, а затем найдите ближайшую точку с наибольшим сходством в быстром пространстве. Левая часть рисунка ниже — это поиск KNN, а край — это. приблизительный поиск по КНН: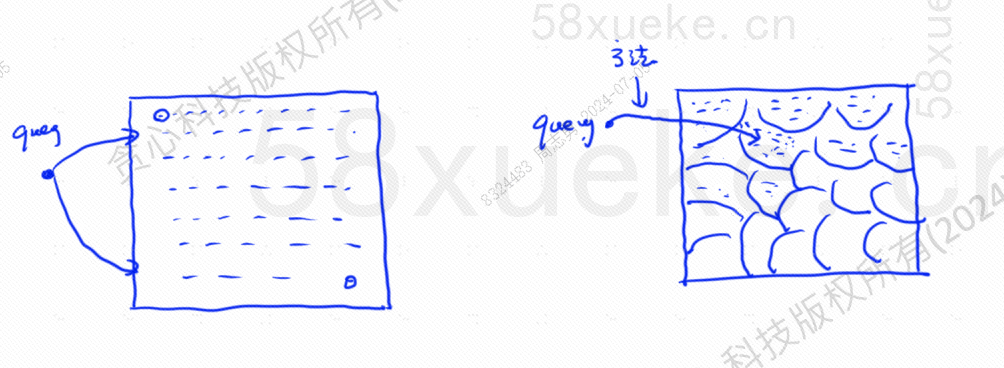
В каждом блоке будет центральная точка. Вычисление расстояния между точкой запроса и блоком заключается в вычислении расстояния от точки запроса до центральной точки каждого блока: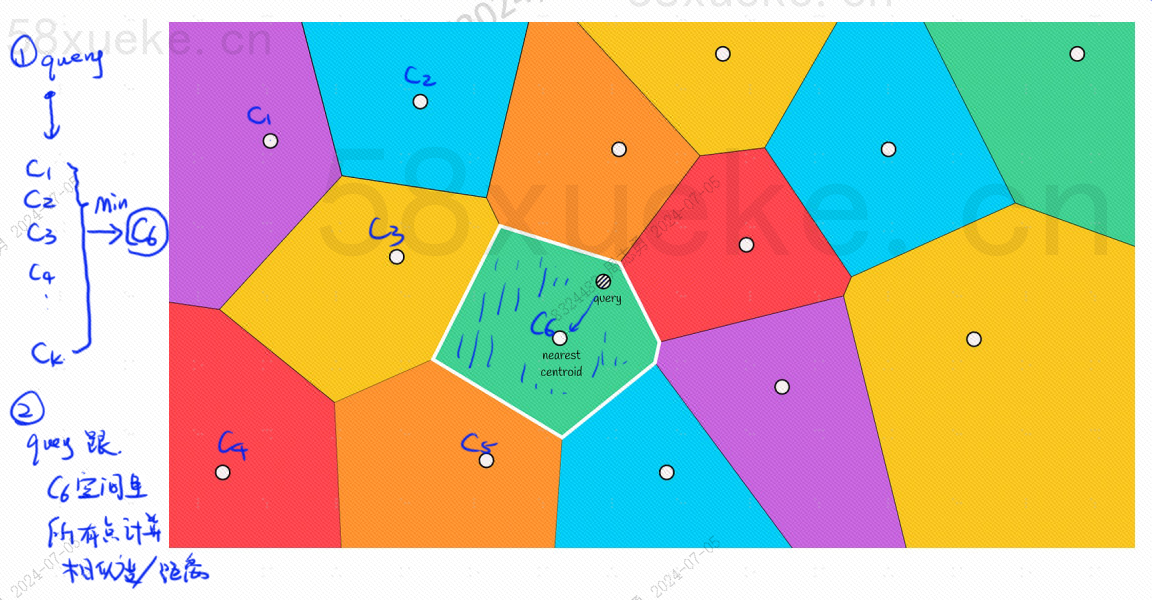
Например, шаги запроса на рисунке выше следующие:
Однако мы можем видеть невооруженным глазом, что хотя центральные точки красного и оранжевого блоков находятся далеко от точки запроса, точки в их блоках расположены близко к точке запроса. На данный момент нам необходимо расширить область действия. блока поиска: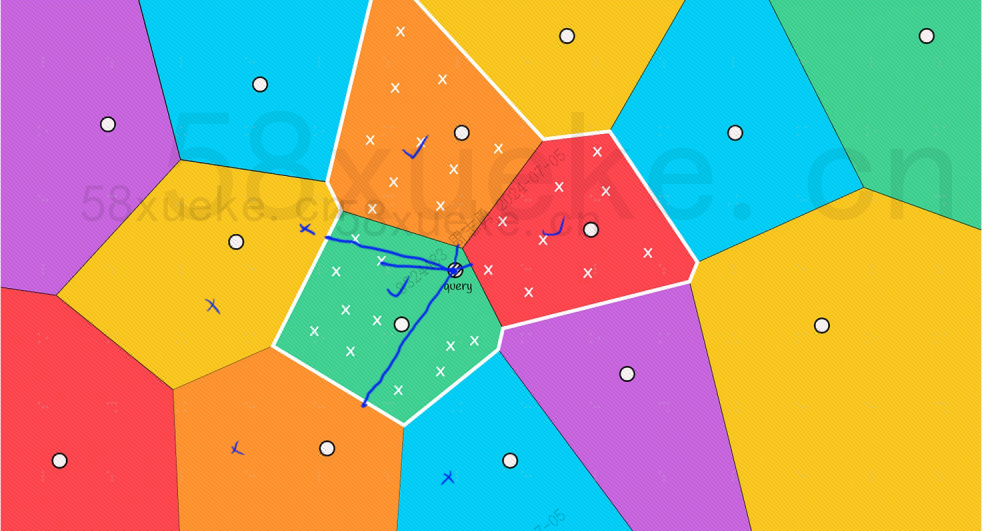
Ниже приведена формула алгоритма для поиска наибольшего сходства и ближайшего расстояния. Наивысшее сходство (COS_SIM) рассчитывается через косинус. Существует два алгоритма для определения наибольшего расстояния: европейский алгоритм и манхэттенский алгоритм. Я не буду их здесь объяснять. :
Алгоритм PQ сначала делит все векторы на несколько подпространств. Как и в приближенном KNN, каждое подпространство имеет центральную точку (центроид).
Затем исходный многомерный вектор будет разделен на несколько векторных субвекторов низкой размерности, а центральная точка, ближайшая к субвектору, будет использоваться в качестве идентификатора PQ субвектора. Затем будет создан многомерный вектор. состоять из нескольких идентификаторов PQ, что сильно сжимает пространство.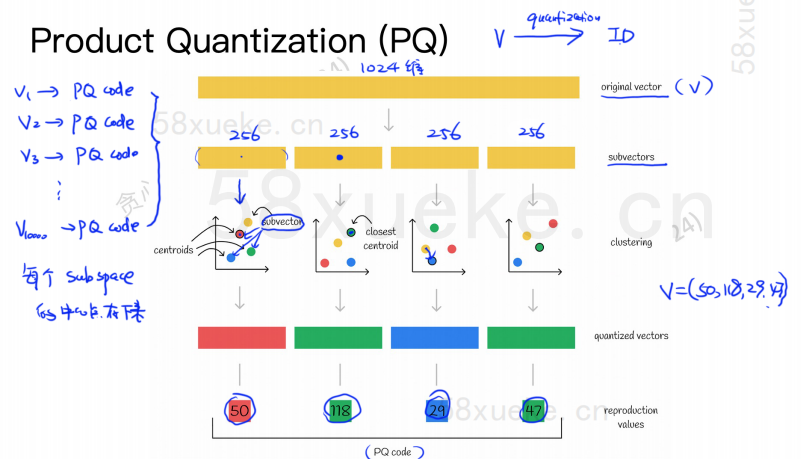
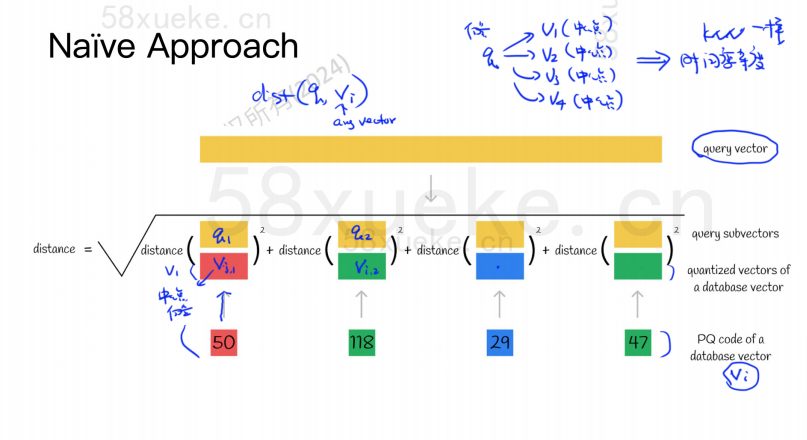
Например, 1024-мерный вектор на рисунке выше разделен на четыре 256-мерных субвекторов, а ближайшие центральные точки этих четырех субвекторов: 50, 118, 29, 47. Следовательно, 1024-мерный вектор может быть представлен как V=(50,118,29,47), и его PQ-код также равен (50,118,29,47).
Следовательно, база данных векторов, использующая алгоритм PQ, должна сохранять информацию обо всех центральных точках и код PQ всех многомерных векторов.
Предположим, что теперь у нас есть оператор запроса, которому необходимо запросить вектор с наибольшим сходством из базы данных векторов. Как выполнить запрос с использованием алгоритма PQ?
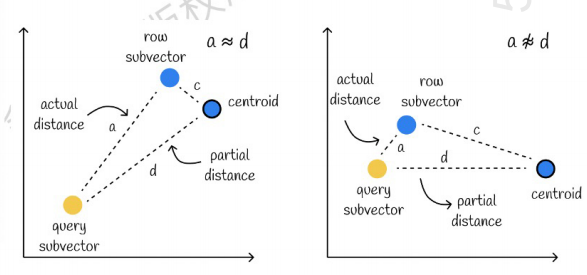
Слева — случай, когда ошибка очень мала, а справа — случай, когда ошибка относительно велика. Как правило, ошибок будет несколько, но большинство из них относительно малы.
Использование кэширования для ускорения вычислений
Если исходный вектор запроса и PQ-код каждого подвектора требуют расчета расстояния, то особой разницы с приближенным алгоритмом KNN нет. Пространственная сложность равна O(n)*O(k), тогда смысл этого. алгоритм какой? Это просто для сжатия и уменьшения места для хранения?
Предположим, что все векторы разделены на K подпространств, и в каждом подпространстве имеется n точек. Мы заранее вычисляем расстояние от точки в каждом подпространстве до его центральной точки, помещаем его в двумерную матрицу, а затем опрашиваем вектор. соответствие Мы можем запросить расстояние от каждого подвектора до центральной точки непосредственно из матрицы, как показано на следующем рисунке: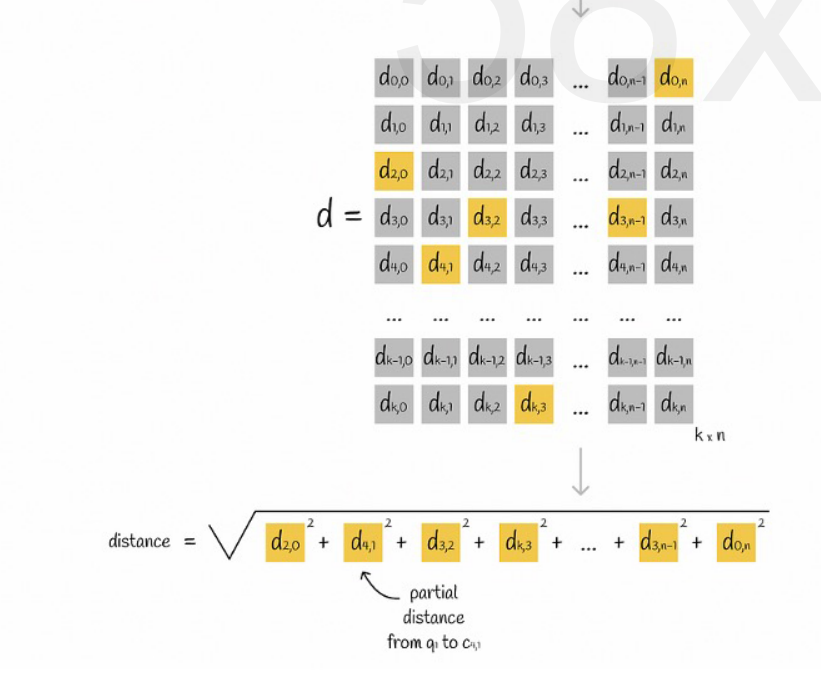
Наконец, нам просто нужно сложить квадратные корни из расстояний каждого подвектора.
Приблизительный KNN в сочетании с алгоритмом PQ
Эти два алгоритма не конфликтуют. Вы можете сначала использовать приблизительный KNN, чтобы разделить все векторы на несколько подпространств, а затем найти вектор запроса в соответствующем подпространстве.
Таким образом, алгоритм PQ используется в подпространстве для ускорения вычислений.
В заданном наборе векторных данных K векторов (K-Nearest Neighbor, KNN), близких к вектору запроса, извлекаются в соответствии с определенным методом измерения. Однако из-за чрезмерного расчета KNN мы обычно сосредотачиваемся только на приближении. проблема ближайших соседей (Approximate Nearest Neighbor, ANN).
При составлении изображения NSW случайным образом выбирает точки и добавляет их на изображение. Каждый раз, когда добавляется точка, m точек оказываются ее ближайшим соседом, к которому можно добавить ребро. Окончательная структура формируется, как показано на рисунке ниже:
При поиске на картах Нового Южного Уэльса мы начинаем с заранее определенных точек входа. Эта точка входа соединена с несколькими близлежащими вершинами. Мы определяем, какая из этих вершин ближе всего к нашему вектору запроса, и перемещаемся туда.
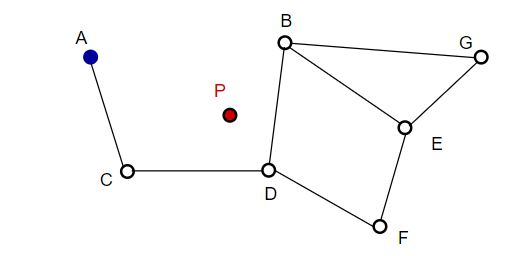
Например, начиная с A, соседняя с A точка C обновляется ближе к P. Тогда соседняя точка D из C окажется ближе к P, а затем соседние точки B и F из D не станут ближе, и программа остановится, что и есть точка D.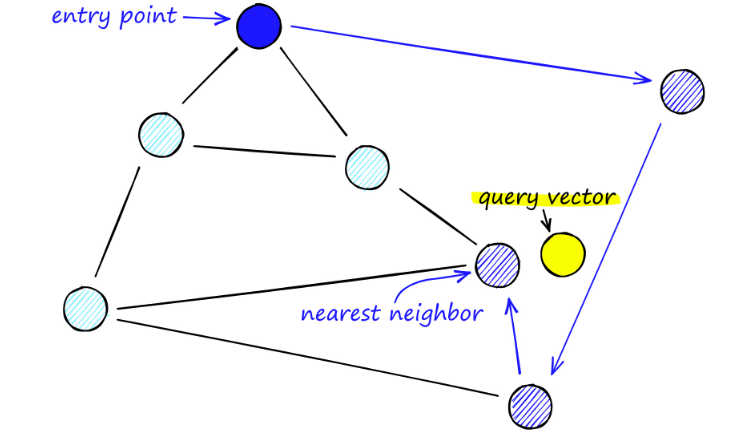
Построение графа начинается на верхнем уровне. Оказавшись в графе, алгоритм жадно обходит ребра, чтобы найти ближайшего соседа ef к вставленному нами вектору q — в этот момент ef = 1.
Как только локальный минимум найден, он перемещается на следующий уровень (так же, как это делалось при поиске). Повторяйте этот процесс, пока не достигнем выбранного нами слоя вставки. Здесь начинается второй этап строительства.
Значение ef увеличивается до установленного нами параметра efConstruction, что означает, что будет возвращено больше ближайших соседей. На втором этапе эти ближайшие соседи являются кандидатами на ссылки на вновь вставленный элемент q и служат точками входа на следующий уровень.
После многих итераций при добавлении ссылок необходимо учитывать еще два параметра. M_max, который определяет максимальное количество связей, которое может иметь вершина, и M_max0, который определяет максимальное количество соединений для вершины в слое 0.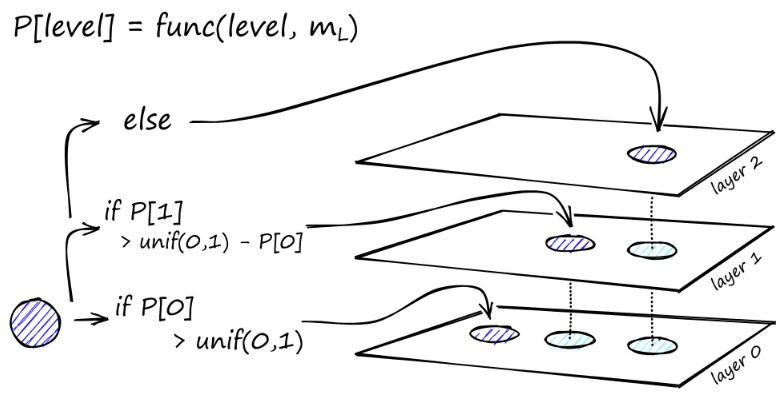
HNSW расшифровывается как Hierarchical Navigable Small World, многослойный граф. Каждый объект в базе данных фиксируется на самом низком уровне (уровень 0 на рисунке). Эти объекты данных очень хорошо связаны. На каждом слое выше самого нижнего уровня представлено меньше точек данных. Эти точки данных соответствуют нижним слоям, но в каждом более высоком слое их экспоненциально меньше. Если есть поисковый запрос, ближайшие точки данных будут найдены на верхнем уровне. В приведенном ниже примере это всего лишь еще одна точка данных. Затем он идет на один уровень глубже и находит ближайшую точку данных из первой, найденной на самом высоком уровне, и оттуда ищет ближайших соседей. На самом глубоком уровне будет найден фактический объект данных, наиболее близкий к поисковому запросу.
HNSW — это очень быстрый и эффективный метод поиска по сходству, поскольку в кэше сохраняется только самый высокий уровень (верхний уровень), а не все точки данных самого нижнего уровня. После запроса на более высоких уровнях загружаются только точки данных, ближайшие к поисковому запросу, а это означает, что необходимо зарезервировать лишь небольшой объем памяти.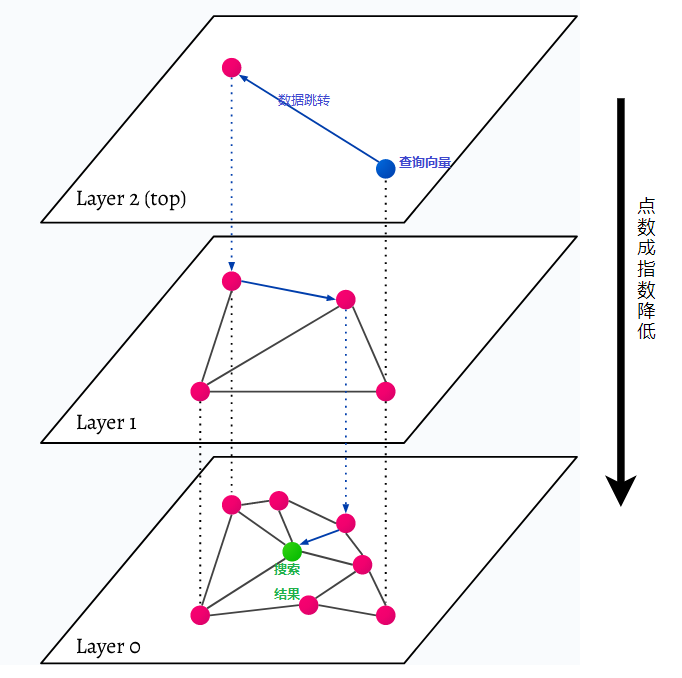

Он посвятил себя исследованию технологий более 30 лет и владеет различными языками, такими как Java, Linux, Javascript, php, css и т. д. Он внес большой вклад в область открытого исходного кода. Станция документации для разработчиков, где можно поделиться некоторыми проблемами в разработке технологий для дальнейшего использования. Все ознакомьтесь.

Почтамезофия@protonmail.com