le mie informazioni di contatto
Posta[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Il database vettoriale è il componente principale dell'odierna pratica di recupero della knowledge base su grandi modelli. La figura seguente è un diagramma dell'architettura per la creazione del recupero della knowledge base: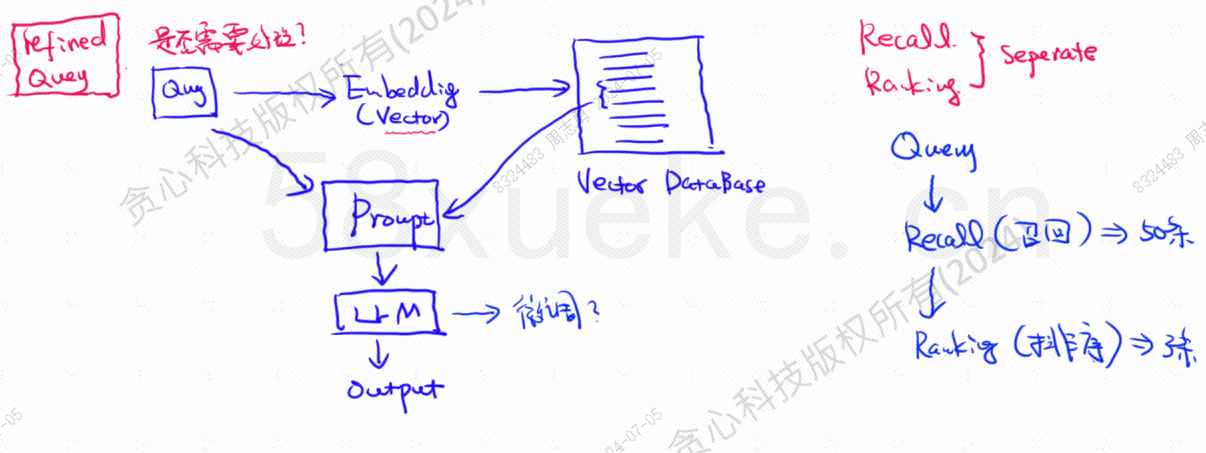
La somiglianza tra i dati della query vettoriale e la query influisce direttamente sulla qualità del prompt. Questo articolo introdurrà brevemente i database vettoriali esistenti sul mercato e quindi spiegherà i metodi di indicizzazione utilizzati in essi, inclusi indice invertito, KNN, KNN approssimativo, quantizzazione del prodotto. HSNW, ecc., spiegheranno i concetti di progettazione e i metodi di questi algoritmi.
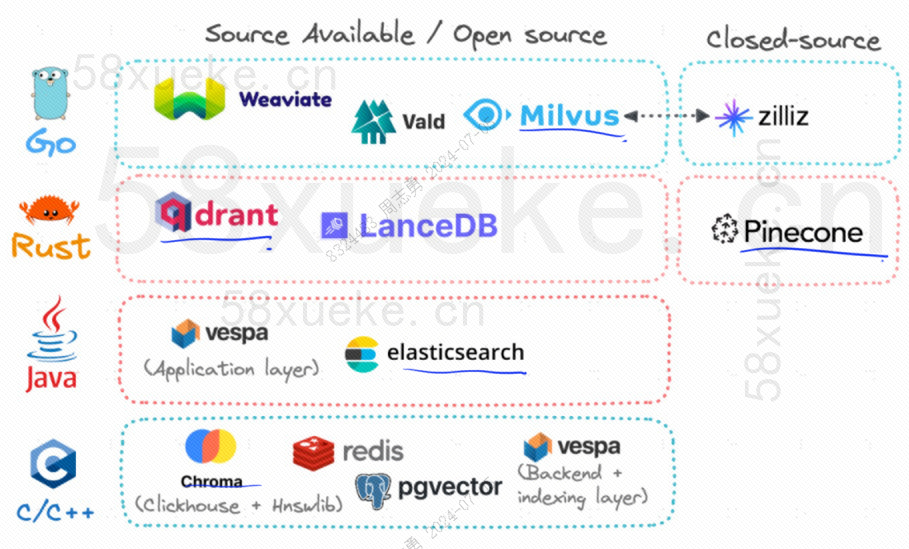
Attualmente, i tre popolari database vettoriali open source sono Chroma, Milvus e Weaviate. Penso che questo articolo sulla loro introduzione e sulle differenze sia utile. Se sei interessato, puoi leggerlo:Competizione tra tre principali database vettoriali open source。
Quella che segue è la storia dello sviluppo dei database vettoriali open source: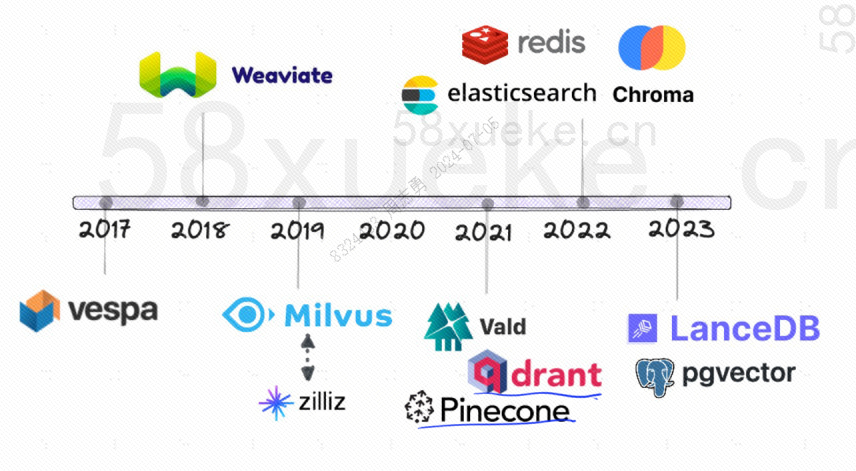
I metodi di indicizzazione utilizzati sono i seguenti:

Se ora dispongo di un database che utilizza un indice invertito, che memorizza 10 ^ 12 dati di indice, quando memorizziamo i dati nel database, divideremo i dati e quindi registreremo le parole corrispondenti alle parole divise posizioni? Poiché le stesse parole possono apparire in frasi diverse, ogni parola corrisponde a un insieme di indici:
Supponiamo ora di avere una domanda: Quali sviluppi avrà l’applicazione dei grandi modelli nel 2024?
Il database divide la nostra dichiarazione di query in tre parole chiave: modello di grandi dimensioni, 2024, sviluppo.Quindi interroga la combinazione di indici corrispondente a ciascuna parola e trova l'intersezione. Viene chiamato questo processo di queryrichiamare.
A questo punto, abbiamo ottenuto i dati associati alla query, ma la somiglianza tra questi dati e l'istruzione della query è diversa. Dobbiamo ordinarli e ottenere TOP N.
Tuttavia, questo tipo di query che fa corrispondere direttamente i dati di testo all'indice non è molto efficiente. Esiste un modo per accelerare il recupero delle somiglianze?
A quel tempo apparve il recupero vettorizzato, che converteva i dati in vettori e quindi calcolava il vettoreSomiglianzaEdistanzaCerca in due modi: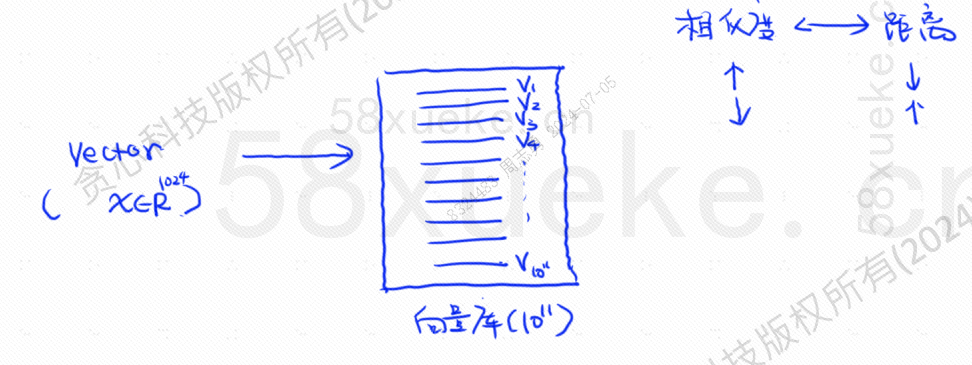
La ricerca KNN è chiamata ricerca del vicino più vicino K. Converte l'istruzione di query in un vettore, quindi trova il vettore e il vettore nel database.La somiglianza più alta e la distanza più vicinainsieme di vettore.
La complessità temporale è O(N)*O(d), d è la dimensione e i dati dimensionali sono generalmente fissi. Supponiamo che nel database siano archiviati 10.000 dati vettoriali e che le dimensioni siano tutte 1024, quindi la query. maxSim(q,v)(massima somiglianza),minDist(q,v)La complessità temporale del vettore (più vicino) è O(10000)*O(1024).
Il vantaggio di questo metodo di recupero è che i dati trovati sono estremamente accurati, ma lo svantaggio è che è lento.
La ricerca KNN approssimativa consiste nel modificare lo spazio di ricerca da punti a blocchi Determinare innanzitutto il blocco più vicino, quindi trovare il punto più vicino con la somiglianza più elevata nello spazio veloce. Il lato sinistro della figura seguente è la ricerca KNN e il bordo lo è approssimativo. Ricerca KNN: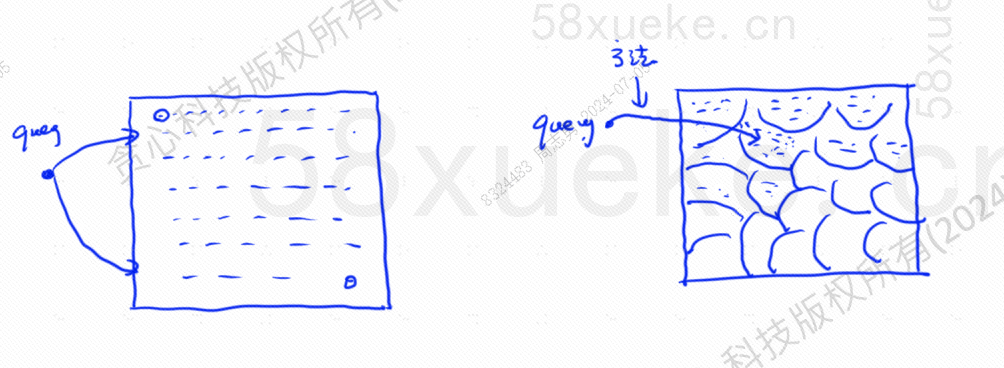
Ci sarà un punto centrale in ciascun blocco. Calcolare la distanza tra il punto di query e il blocco significa calcolare la distanza dal punto di query al punto centrale di ciascun blocco: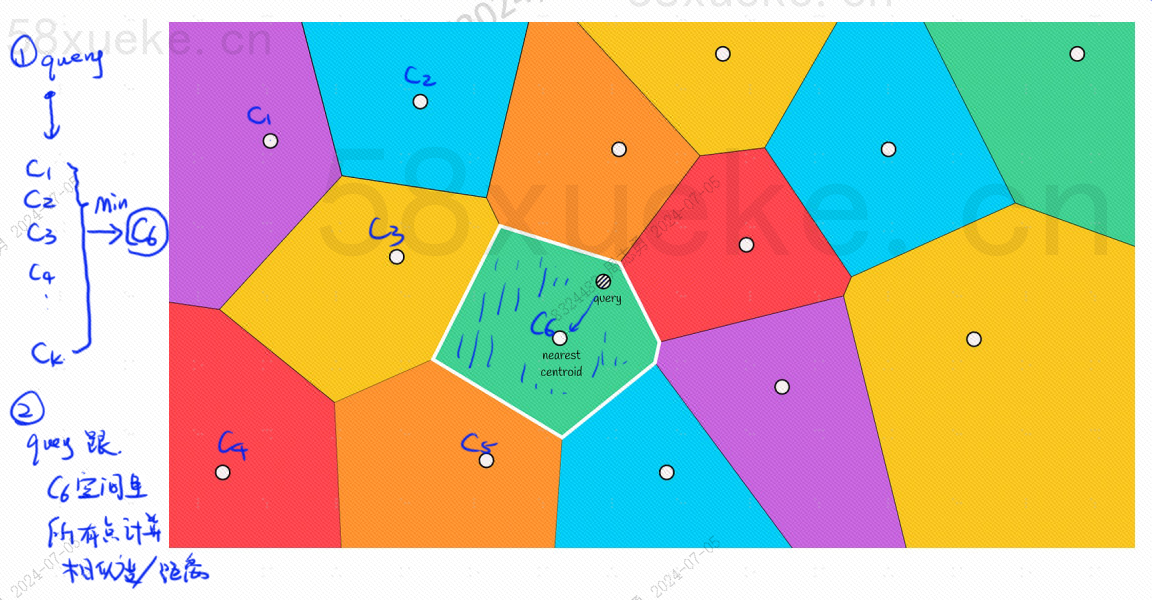
Ad esempio, i passaggi della query nell'immagine sopra sono i seguenti:
Tuttavia, possiamo vedere ad occhio nudo che sebbene i punti centrali dei blocchi rossi e arancioni siano lontani dal punto di query, i punti nei relativi blocchi sono vicini al punto di query. A questo punto, dobbiamo espandere l'ambito del blocco di ricerca: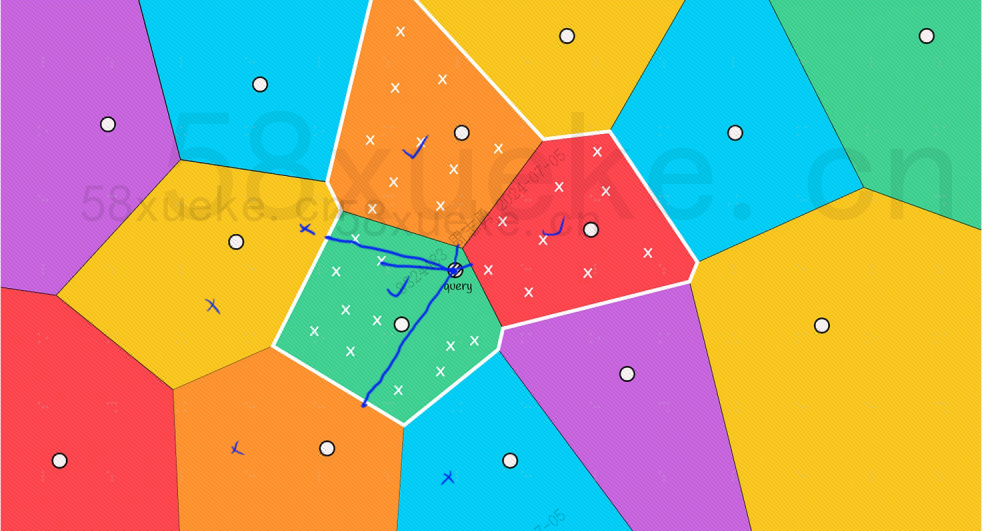
Quella che segue è la formula dell'algoritmo per trovare la somiglianza più alta e la distanza più vicina. La somiglianza più alta (COS_SIM) viene calcolata tramite il coseno. Esistono due algoritmi per la distanza più vicina, l'algoritmo europeo e l'algoritmo di Manhattan che non li spiegherò qui :
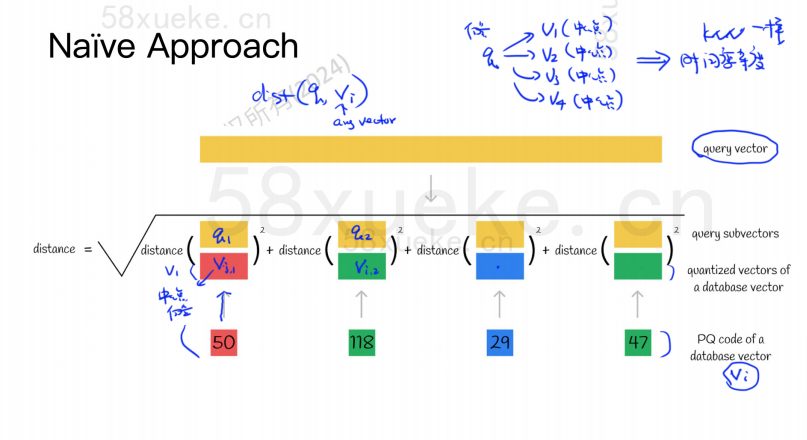
L'algoritmo PQ divide innanzitutto tutti i vettori in più sottospazi. Come il KNN approssimato, ogni sottospazio ha un punto centrale (centroide).
Quindi il vettore originale ad alta dimensionalità verrà suddiviso in più sottovettori vettoriali a bassa dimensionalità e il punto centrale più vicino al sottovettore verrà utilizzato come ID PQ del sottovettore. Quindi verrà utilizzato un vettore ad alta dimensionalità essere composto da più ID PQ, che riducono notevolmente lo spazio.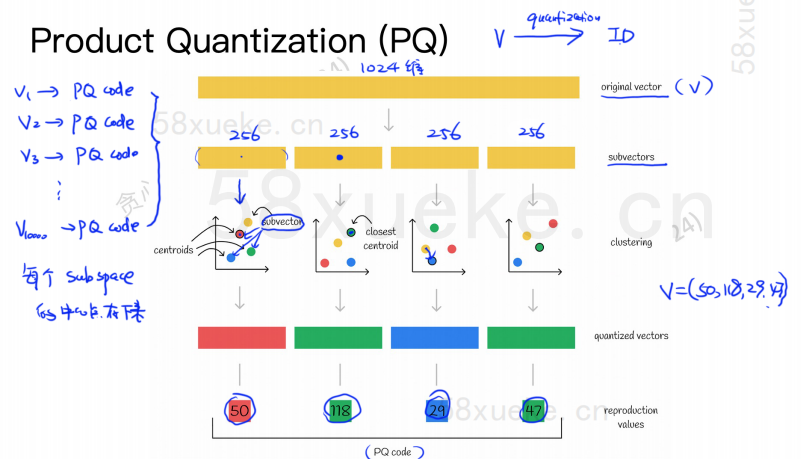
Ad esempio, il vettore a 1024 dimensioni nella figura sopra è suddiviso in quattro sottovettori a 256 dimensioni e i punti centrali più vicini di questi quattro sottovettori sono: 50, 118, 29, 47. Pertanto, il vettore a 1024 dimensioni può essere rappresentato da V=(50,118,29,47) e anche il suo codice PQ è (50,118,29,47).
Pertanto, il database vettoriale che utilizza l'algoritmo PQ deve salvare le informazioni di tutti i punti centrali e il codice PQ di tutti i vettori ad alta dimensione.
Supponiamo ora di avere un'istruzione di query che deve interrogare il vettore con la massima somiglianza dal database dei vettori. Come eseguire una query utilizzando l'algoritmo PQ?
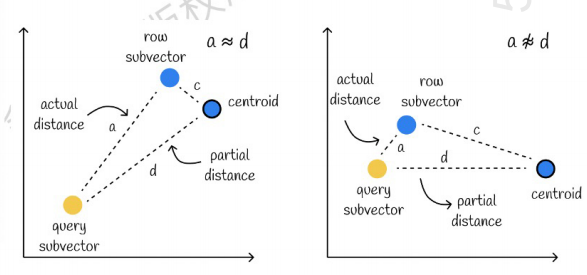
Quello a sinistra è un caso in cui l'errore è molto piccolo, mentre quello a destra è un caso in cui l'errore è relativamente grande. In genere, si verificheranno alcuni errori, ma la maggior parte degli errori saranno relativamente piccoli.
Utilizzo della memorizzazione nella cache per accelerare i calcoli
Se il vettore di query originale e il codice PQ di ciascun sottovettore richiedono un calcolo della distanza, allora non c'è molta differenza dall'algoritmo KNN approssimativo. La complessità dello spazio è O(n)*O(k), quindi il significato di questo l'algoritmo è cosa? Serve solo per comprimere e ridurre lo spazio di archiviazione?
Supponiamo che tutti i vettori siano divisi in K sottospazi e che ci siano n punti in ciascun sottospazio. Calcoliamo in anticipo la distanza dal punto in ciascun sottospazio al suo punto centrale, la inseriamo in una matrice bidimensionale e quindi interroghiamo il vettore. corrispondenza Possiamo interrogare la distanza di ciascun sottovettore dal punto centrale direttamente dalla matrice, come mostrato nella figura seguente: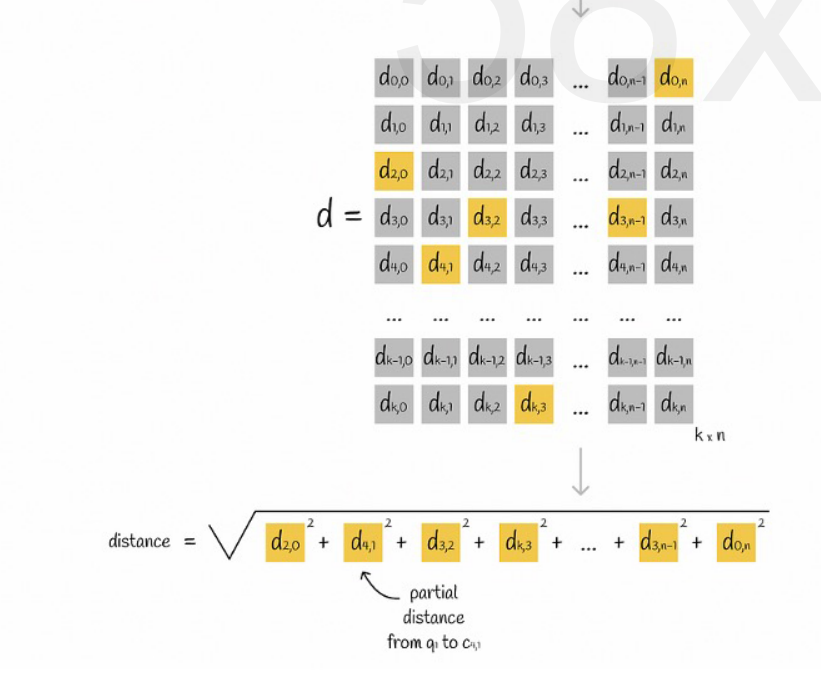
Infine non ci resta che sommare le radici quadrate delle distanze di ciascun sottovettore.
KNN approssimativo combinato con l'algoritmo PQ
Questi due algoritmi non sono in conflitto. È possibile innanzitutto utilizzare KNN approssimativo per dividere tutti i vettori in più sottospazi e quindi individuare il vettore di query nel sottospazio corrispondente.
In questo modo l'algoritmo PQ viene utilizzato nel sottospazio per velocizzare il calcolo.
In un dato set di dati vettoriali, i vettori K (K-Nearest Neighbor, KNN) che sono vicini al vettore di query vengono recuperati secondo un determinato metodo di misurazione. Tuttavia, a causa del calcolo eccessivo di KNN, di solito ci concentriamo solo su quelli approssimativi problema dei vicini più prossimi (Approximate Neighbor, ANN).
Quando si compone un'immagine, NSW seleziona casualmente i punti e li aggiunge all'immagine. Ogni volta che viene aggiunto un punto, si scopre che m punti sono i vicini più vicini a cui aggiungere un bordo. La struttura finale è formata come mostrato nella figura seguente:
Durante la ricerca sulle mappe del NSW, iniziamo da punti di ingresso predefiniti. Questo punto di ingresso è collegato a diversi vertici vicini. Determiniamo quale di questi vertici è più vicino al nostro vettore di query e ci spostiamo lì.
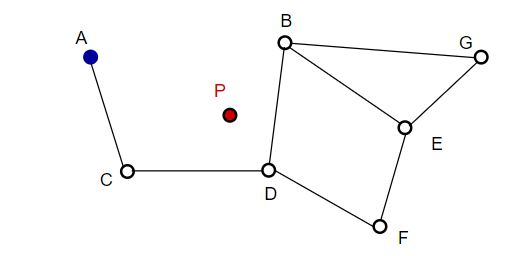
Ad esempio, partendo da A, il punto C vicino ad A viene aggiornato più vicino a P. Quindi il punto adiacente D di C è più vicino a P, quindi i punti adiacenti B e F di D non sono più vicini e il programma si ferma, ovvero il punto D.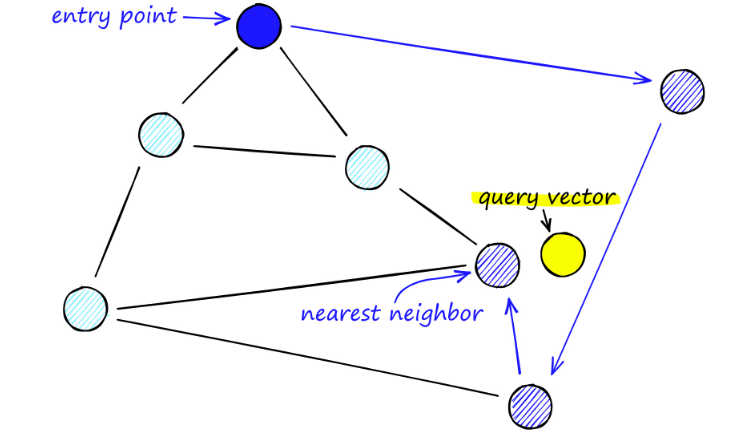
La costruzione del grafico inizia al livello più alto. Una volta nel grafico, l'algoritmo attraversa avidamente gli archi per trovare il vicino ef più vicino al vettore q che abbiamo inserito - in questo momento ef = 1.
Una volta trovato il minimo locale, si passa al livello successivo (proprio come è stato fatto durante la ricerca). Ripeti questo processo finché non raggiungiamo il livello di inserimento di nostra scelta. Qui inizia la seconda fase di costruzione.
Il valore ef viene aumentato al parametro efConstruction impostato, il che significa che verranno restituiti più vicini più vicini. Nella seconda fase, questi vicini più prossimi sono candidati per i collegamenti all'elemento q appena inserito e servono come punti di ingresso allo strato successivo.
Dopo molte iterazioni, ci sono altri due parametri da considerare quando si aggiungono collegamenti. M_max, che definisce il numero massimo di collegamenti che un vertice può avere, e M_max0, che definisce il numero massimo di connessioni per un vertice nel livello 0.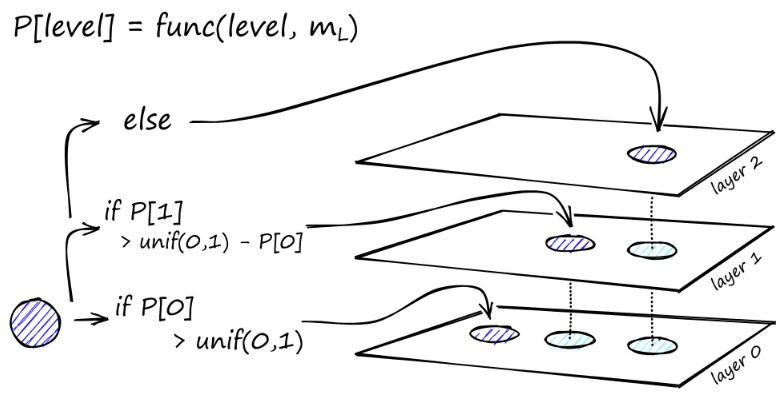
HNSW sta per Hierarchical Navigable Small World, un grafico multistrato. Ogni oggetto nel database viene catturato al livello più basso (livello 0 nell'immagine). Questi oggetti dati sono collegati molto bene. Su ogni livello sopra quello più basso sono rappresentati meno punti dati. Questi punti dati corrispondono agli strati inferiori, ma ci sono esponenzialmente meno punti in ogni strato superiore. Se è presente una query di ricerca, i punti dati più vicini verranno trovati al livello superiore. Nell'esempio seguente, questo è solo un ulteriore punto dati. Poi va più in profondità di un livello e trova il punto dati più vicino dal primo trovato nel livello più alto e da lì cerca i vicini più vicini. Al livello più profondo, verrà trovato l'oggetto dati effettivo più vicino alla query di ricerca.
HNSW è un metodo di ricerca per similarità molto veloce ed efficiente in termini di memoria perché nella cache viene salvato solo il livello più alto (livello superiore) anziché tutti i punti dati nel livello più basso. Solo i punti dati più vicini alla query di ricerca vengono caricati dopo essere stati richiesti dai livelli superiori, il che significa che è necessario riservare solo una piccola quantità di memoria.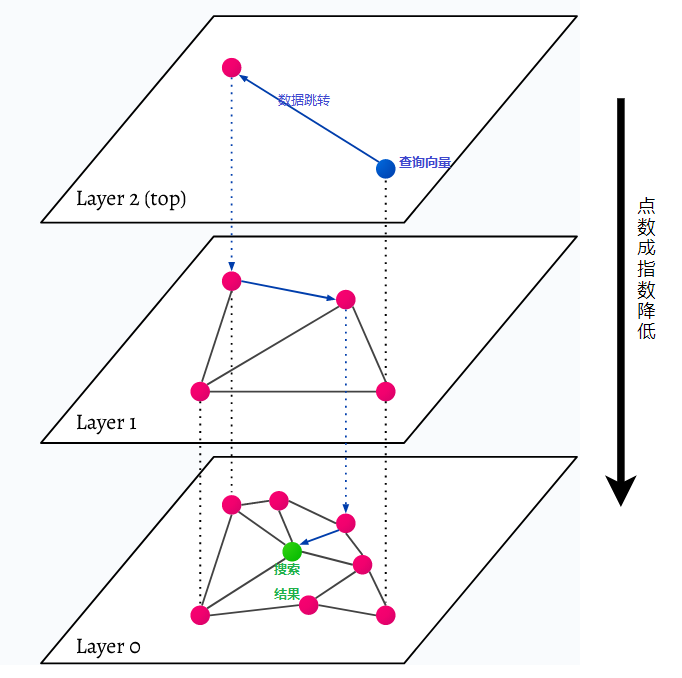

Si dedica alla ricerca tecnologica da più di 30 anni ed è esperto in vari linguaggi come Java, Linux, Javascript, php, css, ecc. Ha dato numerosi contributi nel campo dell'open source stazione di documentazione per gli sviluppatori per condividere alcuni problemi nello sviluppo della tecnologia per riferimento futuro

Posta[email protected]