Mi informacion de contacto
Correo[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
La base de datos vectorial es el componente central de la práctica actual de recuperación de bases de conocimientos de modelos grandes. La siguiente figura es un diagrama de arquitectura para construir la recuperación de bases de conocimientos: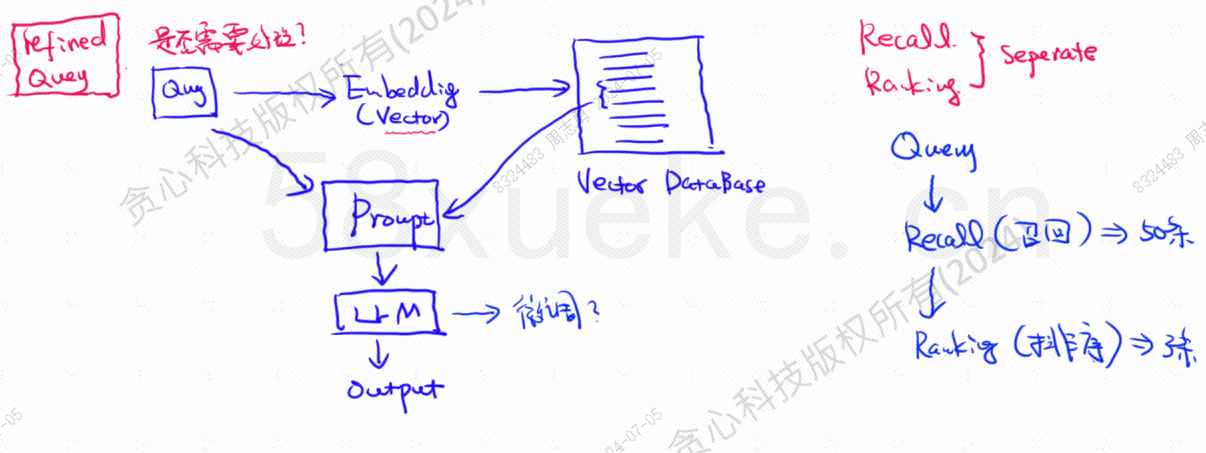
La similitud entre los datos de consulta vectorial y la consulta afecta directamente la calidad de la solicitud. Este artículo presentará brevemente las bases de datos vectoriales existentes en el mercado y luego explicará los métodos de indexación utilizados en ellas, incluido el índice invertido, KNN, KNN aproximado, cuantificación del producto. HSNW, etc., explicarán los conceptos y métodos de diseño de estos algoritmos.
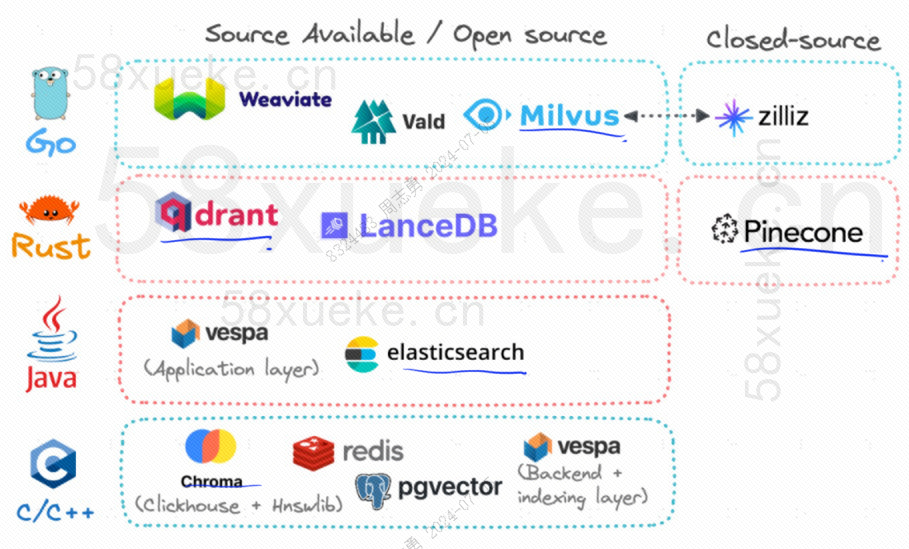
Actualmente, las tres bases de datos vectoriales de código abierto más populares son Chroma, Milvus y Weaviate. Creo que este artículo sobre su introducción y diferencias es bueno. Si está interesado, puede leerlo:Competencia entre tres principales bases de datos vectoriales de código abierto。
La siguiente es la historia del desarrollo de las bases de datos vectoriales de código abierto: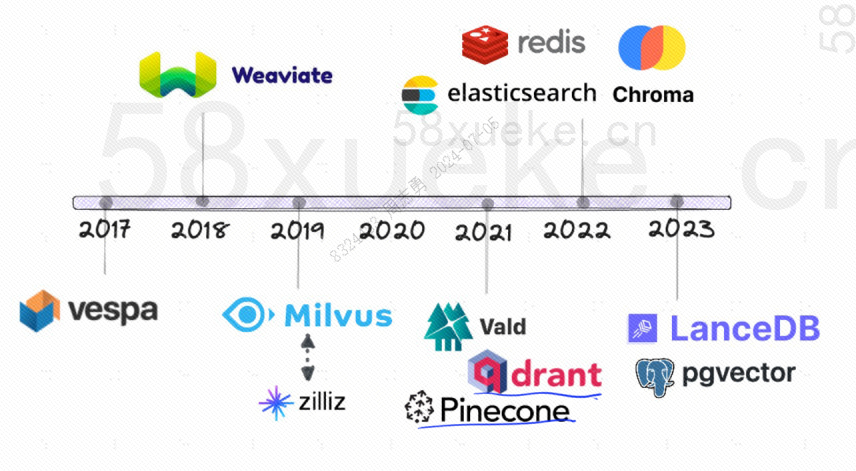
Los métodos de indexación que utilizan son los siguientes:

Si ahora tengo una base de datos que usa un índice invertido, que almacena 10 ^ 12 datos de índice, cuando almacenamos los datos en la base de datos, los dividiremos y luego registraremos las palabras correspondientes a las palabras divididas. posiciones? Debido a que las mismas palabras pueden aparecer en diferentes oraciones, cada palabra corresponde a un conjunto de índices:
Supongamos que ahora tengo una consulta: ¿Qué novedades tendrá la aplicación de modelos grandes en 2024?
La base de datos divide nuestra consulta en tres palabras clave: modelo grande, 2024, desarrollo.Luego consulte la combinación de índice correspondiente a cada palabra y encuentre la intersección. Este proceso de consulta se llama.recordar.
En este momento, hemos obtenido los datos asociados con la consulta, pero la similitud entre estos datos y la declaración de la consulta es diferente. Necesitamos ordenarlos y obtener TOP N.
Sin embargo, este tipo de consulta que corresponde directamente a datos de texto con el índice no es muy eficiente. ¿Hay alguna forma de acelerar la recuperación de similitudes?
En este momento, apareció la recuperación vectorizada, convirtiendo datos en vectores y luego calculando el vector.SemejanzaydistanciaBusque de dos maneras: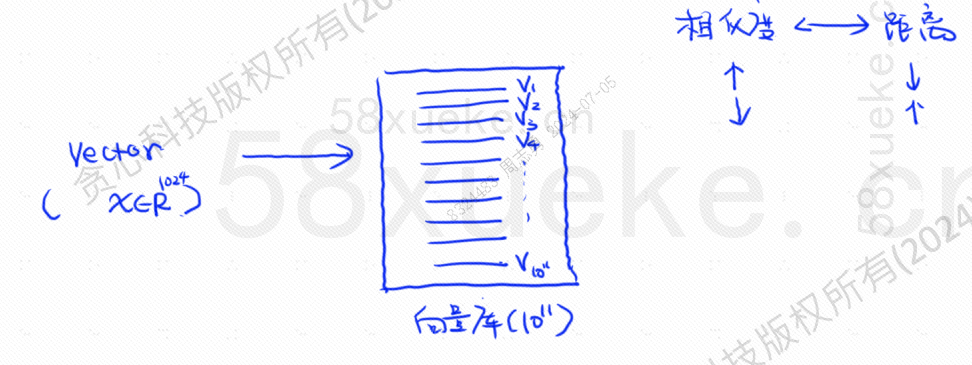
La búsqueda KNN se llama búsqueda del vecino más cercano K. Convierte la declaración de consulta en un vector y luego encuentra el vector y el vector en la base de datos.La mayor similitud y la distancia más cercana.conjunto de vectores.
La complejidad del tiempo es O (N) * O (d), d es la dimensión y los datos dimensionales generalmente son fijos. Suponga que se almacenan 10,000 datos vectoriales en la base de datos y las dimensiones son 1024, luego la consulta. maxSim(q,v)(mayor similitud),minDist(q,v)La complejidad temporal del vector (más cercano) es O(10000)*O(1024).
La ventaja de este método de recuperación es que los datos encontrados son muy precisos, pero la desventaja es que es lento.
La búsqueda KNN aproximada consiste en cambiar el espacio de búsqueda de puntos a bloques. Primero determine el bloque más cercano y luego encuentre el punto más cercano con la mayor similitud en el espacio rápido. El lado izquierdo de la figura siguiente es la búsqueda KNN, y el borde es. Búsqueda KNN aproximada: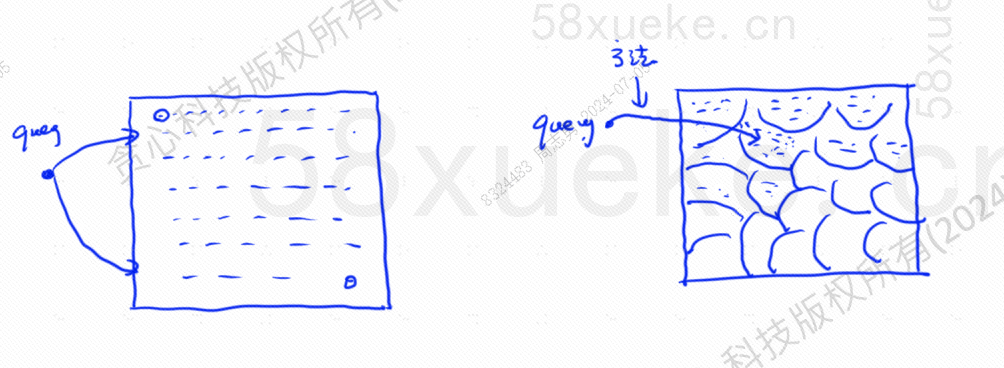
Habrá un punto central en cada bloque. Calcular la distancia entre el punto de consulta y el bloque es calcular la distancia desde el punto de consulta hasta el punto central de cada bloque: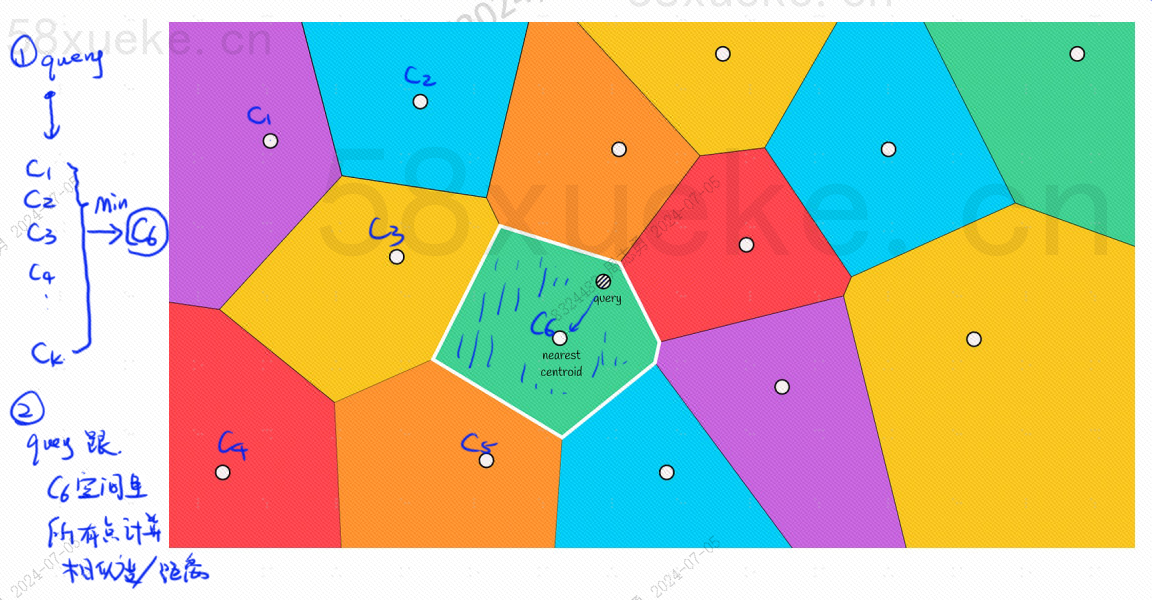
Por ejemplo, los pasos de consulta en la imagen de arriba son los siguientes:
Sin embargo, podemos ver a simple vista que, aunque los puntos centrales de los bloques rojo y naranja están lejos del punto de consulta, los puntos en sus bloques están cerca del punto de consulta. En este momento, necesitamos ampliar el alcance. del bloque de búsqueda: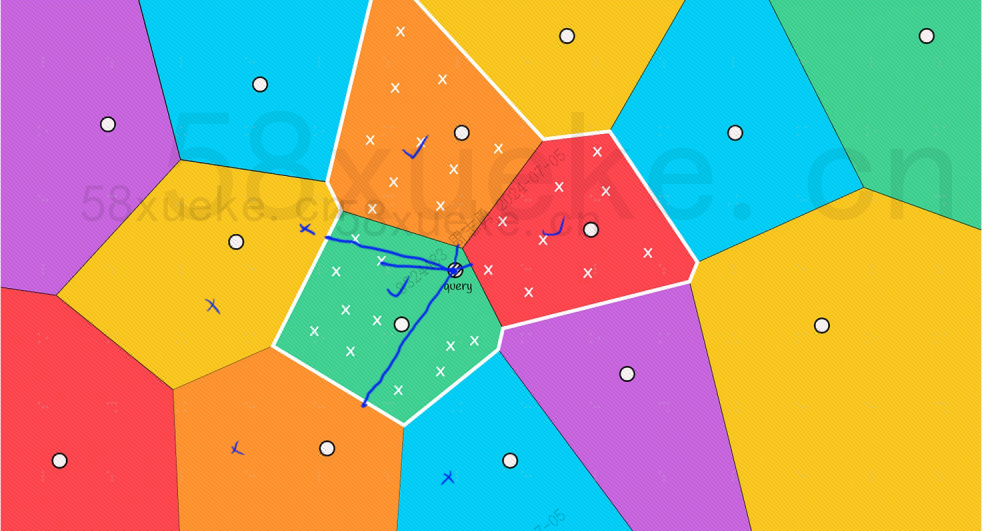
La siguiente es la fórmula del algoritmo para encontrar la similitud más alta y la distancia más cercana. La similitud más alta (COS_SIM) se calcula mediante el coseno. Hay dos algoritmos para la distancia más cercana, el algoritmo europeo y el algoritmo de Manhattan. :
El algoritmo PQ primero divide todos los vectores en múltiples subespacios. Como KNN aproximado, cada subespacio tiene un punto central (centroide).
Luego, el vector de alta dimensión original se dividirá en múltiples subvectores de vector de baja dimensión, y el punto central más cercano al subvector se utilizará como el ID PQ del subvector. Luego, se creará un vector de alta dimensión. estar compuesto por múltiples ID de PQ, que comprime en gran medida el espacio.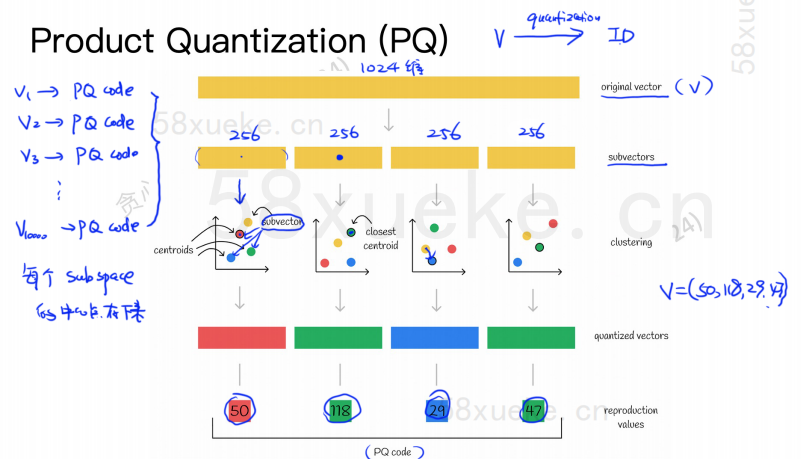
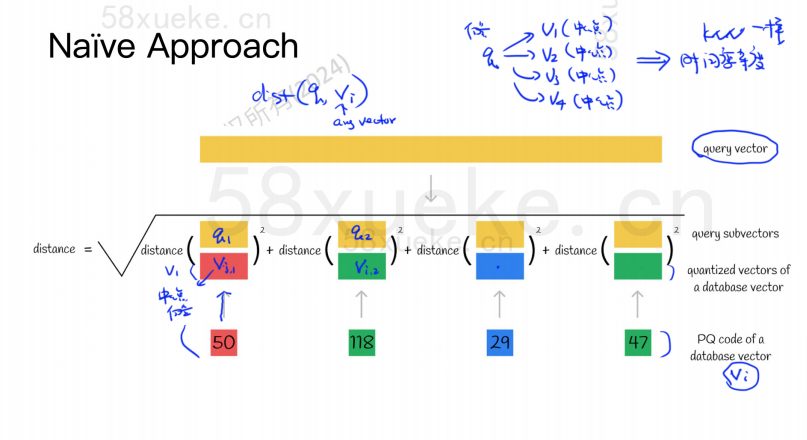
Por ejemplo, el vector de 1024 dimensiones en la figura anterior se divide en cuatro subvectores de 256 dimensiones, y los puntos centrales más cercanos de estos cuatro subvectores son: 50, 118, 29, 47. Por lo tanto, el vector de 1024 dimensiones se puede representar mediante V = (50,118,29,47) y su código PQ también es (50,118,29,47).
Por lo tanto, la base de datos de vectores que utiliza el algoritmo PQ necesita guardar la información de todos los puntos centrales y el código PQ de todos los vectores de alta dimensión.
Supongamos que ahora tenemos una declaración de consulta que necesita consultar el vector con la mayor similitud de la base de datos de vectores. ¿Cómo consultar utilizando el algoritmo PQ?
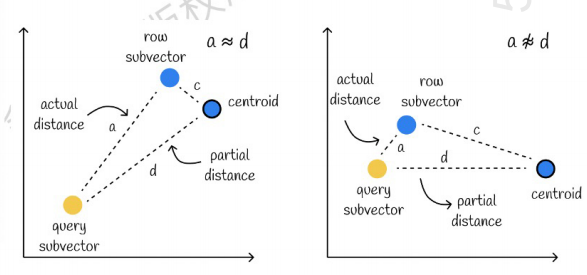
El de la izquierda es un caso donde el error es muy pequeño y el de la derecha es un caso donde el error es relativamente grande. Generalmente habrá algunos errores, pero la mayoría de los errores son relativamente pequeños.
Usar el almacenamiento en caché para acelerar los cálculos
Si el vector de consulta original y el código PQ de cada subvector requieren un cálculo de distancia, entonces no hay mucha diferencia con el algoritmo KNN aproximado. La complejidad espacial es O (n) * O (k), entonces el significado de esto. algoritmo es qué? ¿Es solo para comprimir y reducir el espacio de almacenamiento?
Supongamos que todos los vectores están divididos en K subespacios y que hay n puntos en cada subespacio. Calculamos la distancia desde el punto en cada subespacio hasta su punto central de antemano, lo colocamos en una matriz bidimensional y luego consultamos el vector. correspondencia Podemos consultar la distancia desde cada subvector hasta el punto central directamente desde la matriz, como se muestra en la siguiente figura: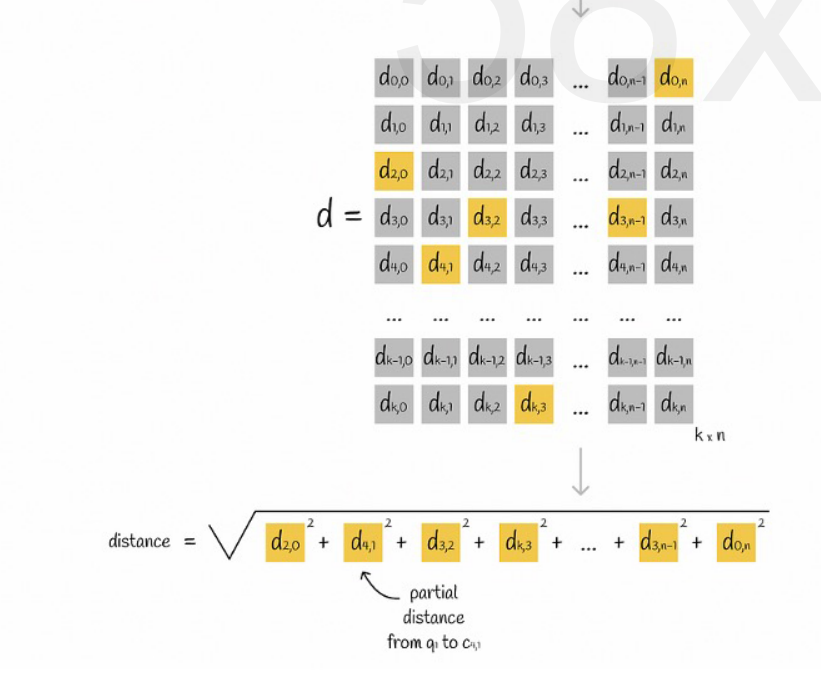
Finalmente solo necesitamos sumar las raíces cuadradas de las distancias de cada subvector.
KNN aproximado combinado con algoritmo PQ
Estos dos algoritmos no entran en conflicto. Primero puede usar KNN aproximado para dividir todos los vectores en múltiples subespacios y luego ubicar el vector de consulta en el subespacio correspondiente.
De esta forma, el algoritmo PQ se utiliza en el subespacio para acelerar el cálculo.
En un conjunto de datos vectoriales dado, K vectores (K-vecino más cercano, KNN) que están cerca del vector de consulta se recuperan de acuerdo con un determinado método de medición. Sin embargo, debido al cálculo excesivo de KNN, generalmente solo nos centramos en los aproximados. Problema de vecinos más cercanos (Vecino más cercano aproximado, ANN).
Al componer una imagen, NSW selecciona puntos aleatoriamente y los agrega a la imagen. Cada vez que se agrega un punto, se encuentra que m puntos son sus vecinos más cercanos para agregar una arista. La estructura final se forma como se muestra en la siguiente figura:
Al buscar mapas de Nueva Gales del Sur, comenzamos desde puntos de entrada predefinidos. Este punto de entrada está conectado a varios vértices cercanos. Determinamos cuál de estos vértices está más cerca de nuestro vector de consulta y nos movemos allí.
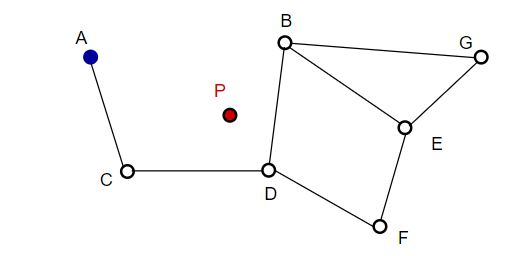
Por ejemplo, a partir de A, el punto vecino C de A se actualiza más cerca de P. Entonces el punto adyacente D de C está más cerca de P, y luego los puntos adyacentes B y F de D no están más cerca, y el programa se detiene, que es el punto D.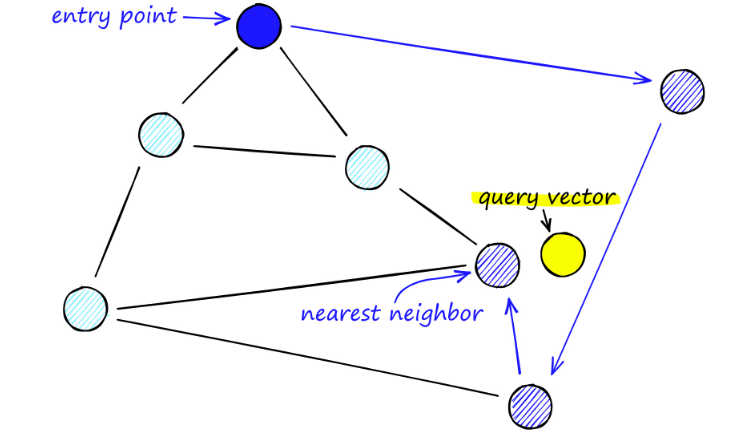
La construcción del gráfico comienza en el nivel superior. Una vez en el gráfico, el algoritmo atraviesa con avidez los bordes para encontrar el vecino ef más cercano al vector q que insertamos; en este momento ef = 1.
Una vez que se encuentra un mínimo local, baja al siguiente nivel (tal como se hizo durante la búsqueda). Repetimos este proceso hasta llegar a la capa de inserción de nuestra elección. Aquí comienza la segunda fase de construcción.
El valor ef aumenta al parámetro efConstruction que configuramos, lo que significa que se devolverán más vecinos más cercanos. En la segunda etapa, estos vecinos más cercanos son candidatos para enlaces al elemento q recién insertado y sirven como puntos de entrada a la siguiente capa.
Después de muchas iteraciones, hay dos parámetros más a considerar al agregar enlaces. M_max, que define el número máximo de enlaces que puede tener un vértice, y M_max0, que define el número máximo de conexiones para un vértice en la capa 0.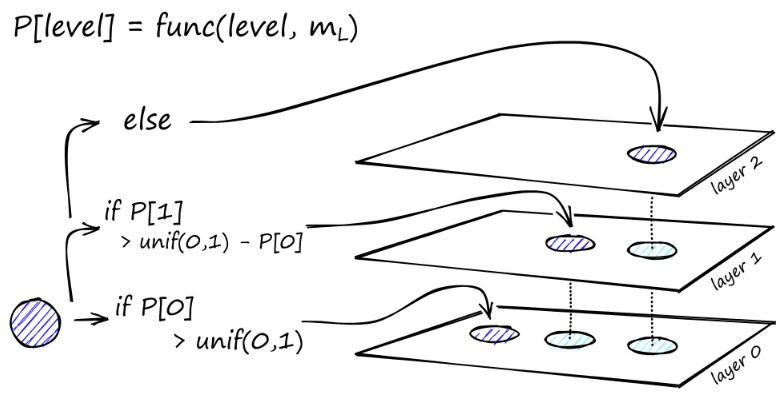
HNSW significa Hierarchical Navigable Small World, un gráfico de varias capas. Cada objeto de la base de datos se captura en el nivel más bajo (nivel 0 en la imagen). Estos objetos de datos están muy bien conectados. En cada capa encima de la capa más baja, se representan menos puntos de datos. Estos puntos de datos coinciden con las capas inferiores, pero hay exponencialmente menos puntos en cada capa superior. Si hay una consulta de búsqueda, los puntos de datos más cercanos se encontrarán en el nivel superior. En el siguiente ejemplo, este es sólo un dato más. Luego va un nivel más profundo y encuentra el punto de datos más cercano al primero encontrado en el nivel más alto y busca los vecinos más cercanos desde allí. En el nivel más profundo, se encontrará el objeto de datos real más cercano a la consulta de búsqueda.
HNSW es un método de búsqueda de similitudes muy rápido y eficiente en memoria porque solo se guarda en la caché la capa más alta (capa superior) en lugar de todos los puntos de datos de la capa más baja. Solo los puntos de datos más cercanos a la consulta de búsqueda se cargan después de ser solicitados por capas superiores, lo que significa que solo es necesario reservar una pequeña cantidad de memoria.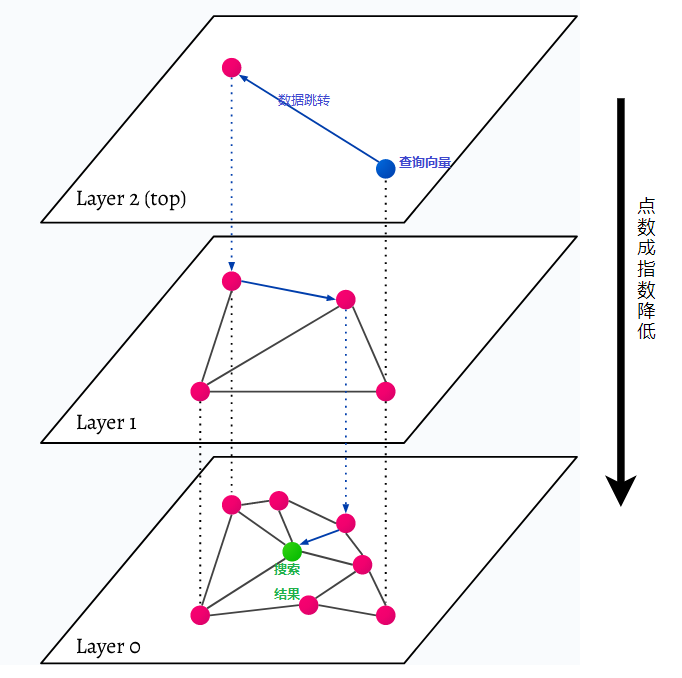

Se ha dedicado a la investigación de tecnología durante más de 30 años y domina varios lenguajes como java, linux, javascript, php, css, etc. Ha realizado muchas contribuciones en el campo del código abierto. Estación de documentación para desarrolladores para compartir algunos problemas en el desarrollo de tecnología para referencia futura.

Correo[email protected]