informasi kontak saya
Surat[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Basis data vektor adalah komponen inti dari praktik pengambilan basis pengetahuan model besar saat ini. Gambar berikut adalah diagram arsitektur untuk membangun pengambilan basis pengetahuan: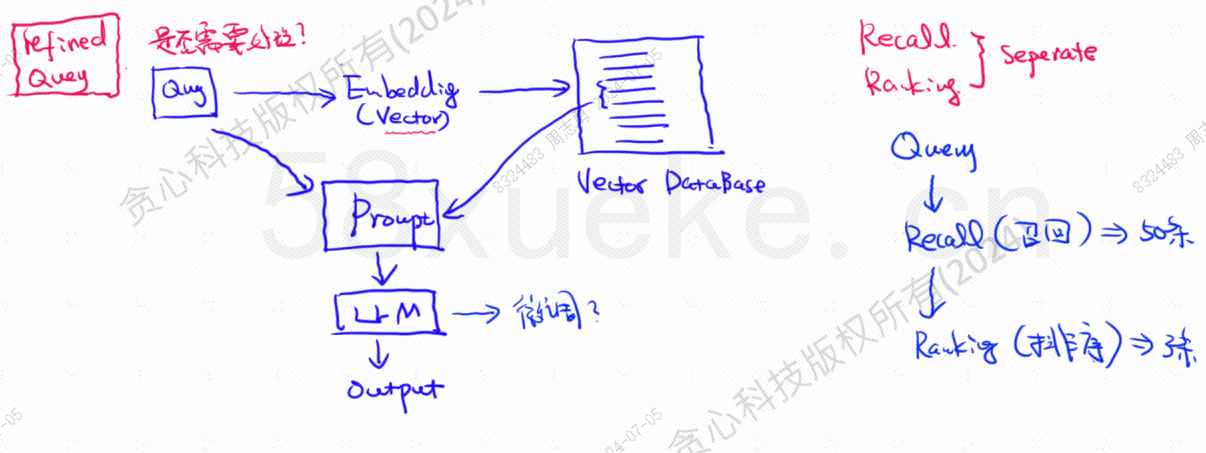
Kesamaan antara data kueri vektor dan kueri secara langsung mempengaruhi kualitas prompt. Artikel ini akan memperkenalkan secara singkat database vektor yang ada di pasar, dan kemudian menjelaskan metode pengindeksan yang digunakan di dalamnya, termasuk indeks terbalik, KNN, Perkiraan KNN, Kuantisasi Produk, HSNW, dll., akan menjelaskan konsep desain dan metode algoritma ini.
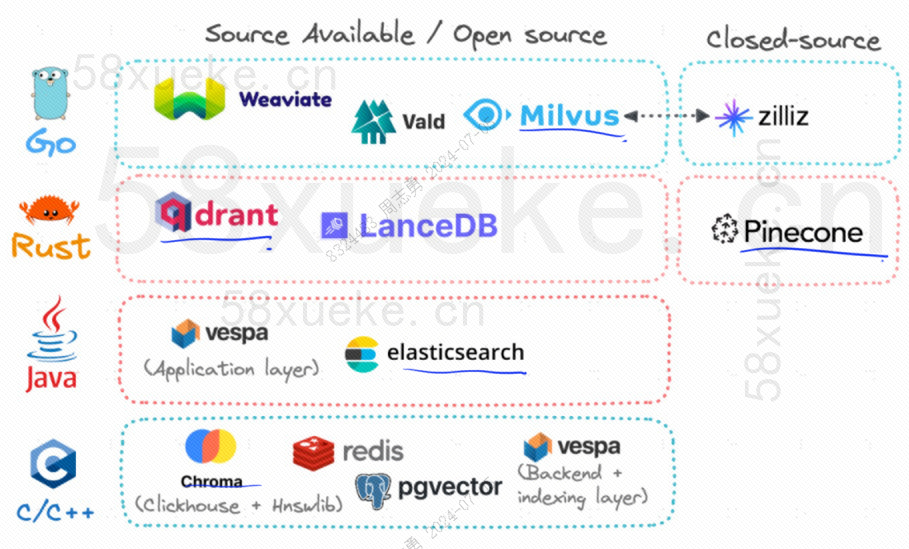
Saat ini, tiga database vektor open source yang populer adalah Chroma, Milvus, dan Weaviate menurut saya artikel tentang pengenalan dan perbedaannya bagus.Persaingan antara tiga database vektor sumber terbuka utama。
Berikut sejarah perkembangan database vektor open source: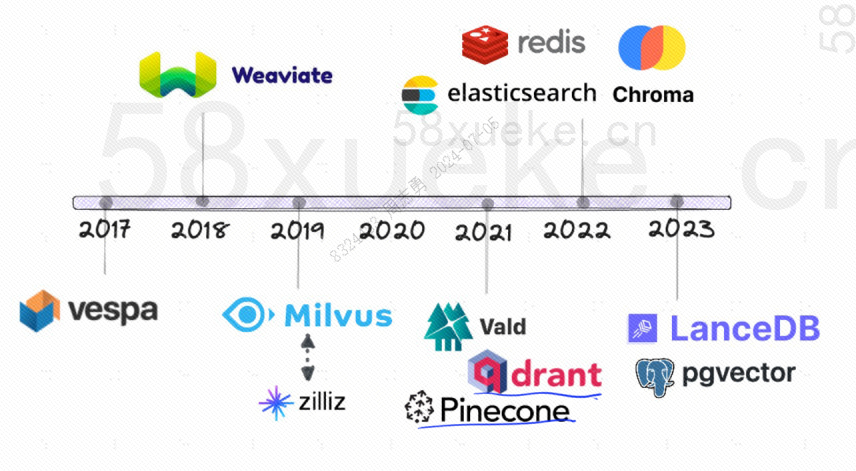
Metode pengindeksan yang mereka gunakan adalah sebagai berikut:

Jika sekarang saya memiliki database yang menggunakan indeks terbalik, yang menyimpan 10^12 data indeks, ketika kita menyimpan data dalam database, kita akan membagi datanya, dan kemudian mencatat kata-kata yang sesuai dengan kata-kata yang dipisahkan tersebut posisi? Karena kata-kata yang sama mungkin muncul dalam kalimat yang berbeda, setiap kata berhubungan dengan kumpulan indeks:
Misalkan sekarang saya punya pertanyaan: Perkembangan apa yang akan terjadi pada penerapan model besar pada tahun 2024?
Basis data membagi pernyataan kueri kami menjadi tiga kata kunci: model besar, 2024, pengembangan.Kemudian kueri kombinasi indeks yang sesuai dengan setiap kata dan temukan titik temunyamengingat.
Saat ini, kita telah memperoleh data yang terkait dengan kueri, tetapi kemiripan antara data tersebut dan pernyataan kueri berbeda. Kita perlu mengurutkannya dan mendapatkan TOP N.
Namun, kueri semacam ini yang secara langsung menghubungkan data teks ke indeks tidak terlalu efisien. Apakah ada cara untuk mempercepat pengambilan kesamaan?
Pada saat ini muncul pengambilan vektor, mengubah data menjadi vektor, dan kemudian menghitung vektornyaKesamaanDanjarakCari dengan dua cara: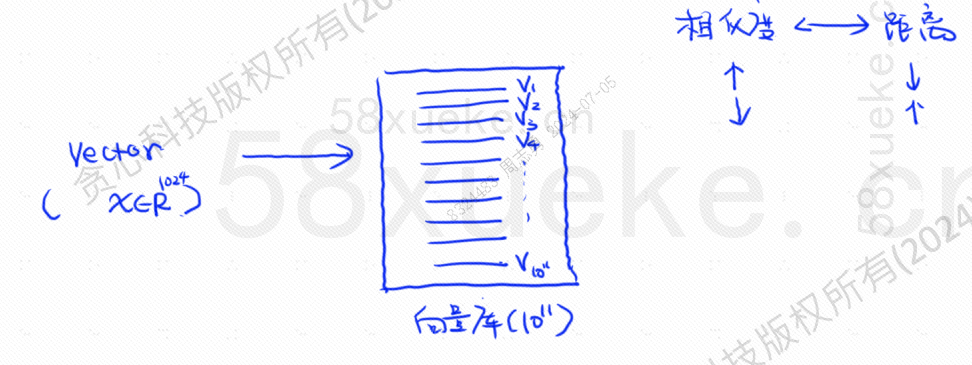
Pencarian KNN disebut pencarian K tetangga terdekat. Ini mengubah pernyataan kueri menjadi vektor, dan kemudian menemukan vektor dan vektor tersebut dalam database.Kemiripan tertinggi dan jarak terdekatkumpulan vektor.
Kompleksitas waktu adalah O(N)*O(d), d adalah dimensi, dan data dimensi umumnya tetap. Asumsikan bahwa 10.000 data vektor disimpan dalam database, dan dimensinya semuanya 1024, maka kuerinya adalah. maxSim(q,v)(kesamaan tertinggi),minDist(q,v)Kompleksitas waktu dari vektor (terdekat) adalah O(10000)*O(1024).
Kelebihan metode retrieval ini adalah data yang ditemukan sangat akurat, namun kelemahannya adalah lambat.
Perkiraan pencarian KNN adalah dengan mengubah ruang pencarian dari titik ke blok. Pertama tentukan blok terdekat, lalu cari titik terdekat dengan kemiripan tertinggi di ruang cepat. Sisi kiri gambar di bawah adalah pencarian KNN, dan tepinya adalah perkiraan pencarian KNN: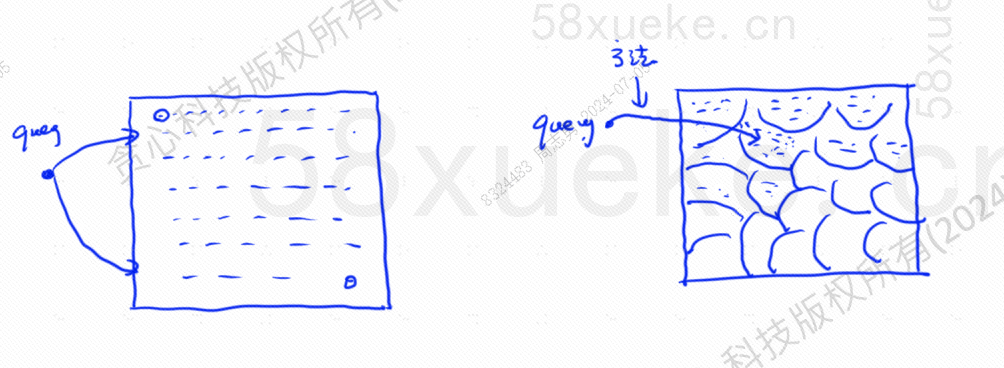
Akan ada titik pusat di setiap blok. Menghitung jarak antara titik query dan blok adalah dengan menghitung jarak dari titik query ke titik pusat setiap blok: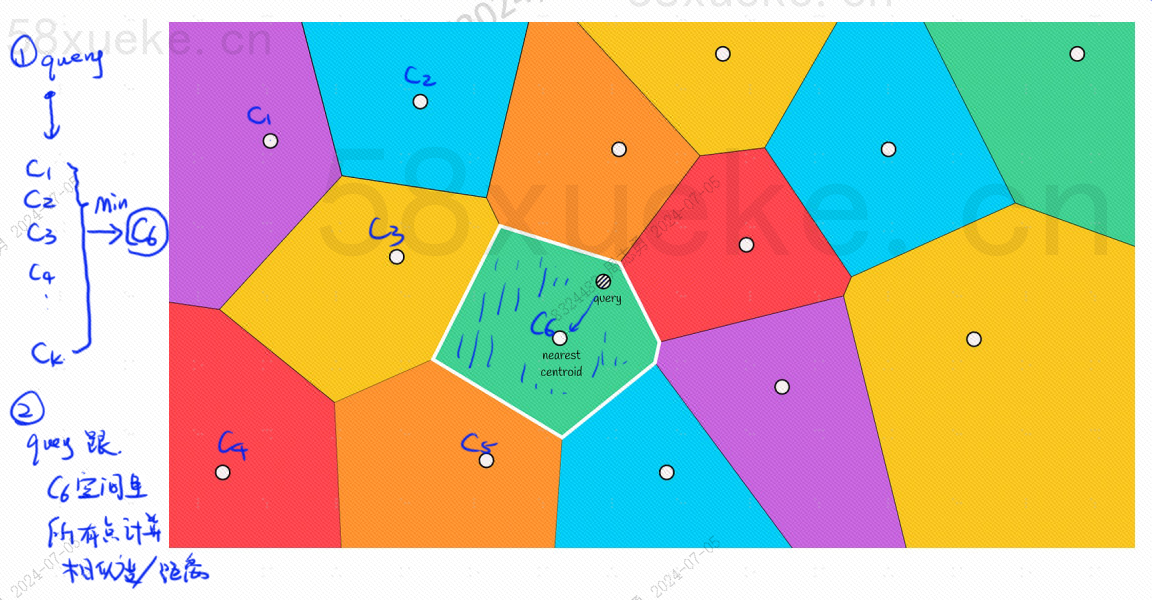
Misalnya langkah query pada gambar di atas adalah sebagai berikut:
Namun, kita dapat melihat dengan mata telanjang bahwa meskipun titik pusat balok merah dan oranye jauh dari titik kueri, namun titik-titik di bloknya dekat dengan titik kueri dari blok pencarian: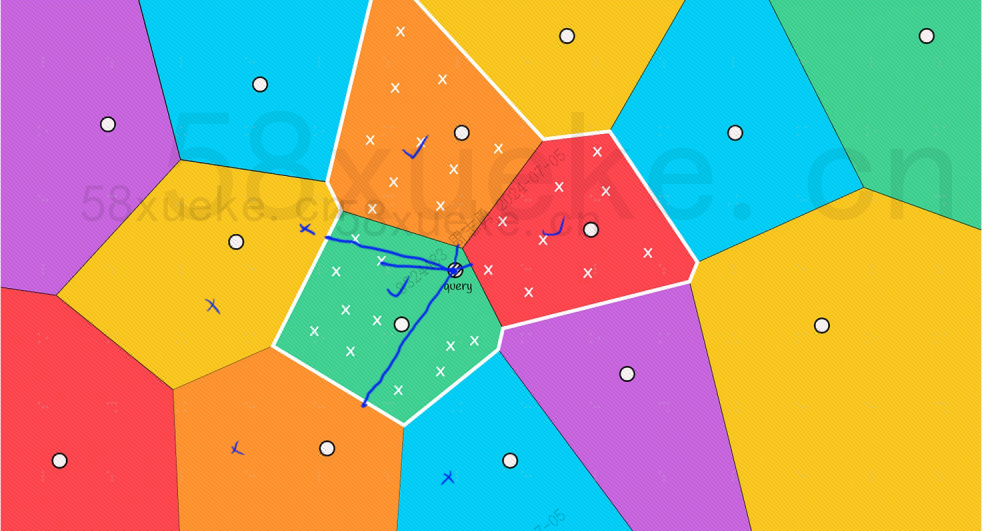
Berikut rumus algoritma untuk mencari kemiripan tertinggi dan jarak terdekat, kesamaan tertinggi (COS_SIM) dihitung melalui kosinus.Ada dua algoritma untuk jarak terdekat yaitu algoritma Eropa dan algoritma Manhattan :
Algoritma PQ pertama-tama membagi semua vektor menjadi beberapa subruang. Seperti perkiraan KNN, setiap subruang memiliki titik pusat (pusat massa).
Kemudian vektor asli berdimensi tinggi akan dipecah menjadi beberapa subvektor vektor berdimensi rendah, dan titik pusat yang paling dekat dengan subvektor tersebut akan digunakan sebagai ID PQ dari subvektor tersebut terdiri dari beberapa ID PQ, yang ruangnya sangat terkompresi.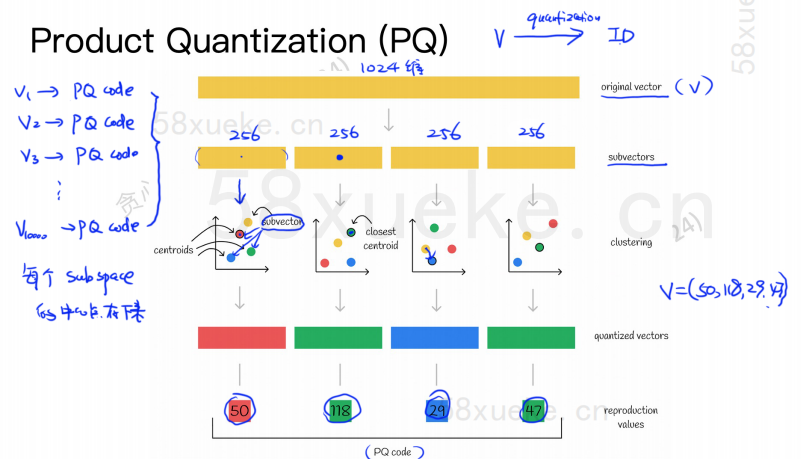
Misalnya vektor berdimensi 1024 pada gambar di atas dipecah menjadi empat subvektor berdimensi 256, dan titik pusat terdekat dari keempat subvektor tersebut adalah: 50, 118, 29, 47. Oleh karena itu, vektor berdimensi 1024 dapat diwakili oleh V=(50,118,29,47), dan kode PQ-nya juga (50,118,29,47).
Oleh karena itu, database vektor yang menggunakan algoritma PQ perlu menyimpan informasi semua titik pusat dan kode PQ semua vektor berdimensi tinggi.
Misalkan sekarang kita memiliki pernyataan kueri yang perlu mengkueri vektor dengan kemiripan tertinggi dari database vektor. Bagaimana cara melakukan kueri menggunakan algoritma PQ?
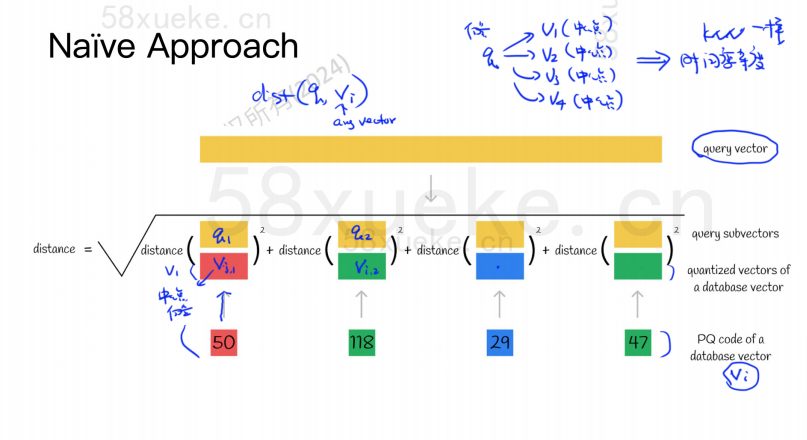
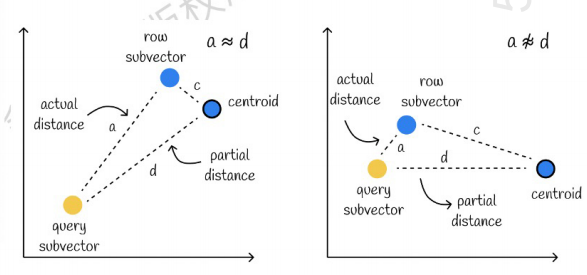
Yang di sebelah kiri adalah kasus yang kesalahannya sangat kecil, dan yang di sebelah kanan adalah kasus yang kesalahannya relatif besar. Umumnya akan ada sedikit kesalahan, tetapi sebagian besar kesalahannya relatif kecil.
Menggunakan caching untuk mempercepat perhitungan
Jika vektor query asli dan kode PQ masing-masing subvektor memerlukan perhitungan jarak, maka tidak banyak perbedaan dari perkiraan algoritma KNN. Kompleksitas ruangnya adalah O(n)*O(k), maka maksudnya begini algoritmanya apa? Apakah hanya untuk kompresi dan mengurangi ruang penyimpanan?
Asumsikan bahwa semua vektor dibagi menjadi K subruang, dan terdapat n titik di setiap subruang. Kita menghitung terlebih dahulu jarak dari titik di setiap subruang ke titik pusatnya, memasukkannya ke dalam matriks dua dimensi, lalu menanyakan vektornya. korespondensi Kita dapat menanyakan jarak setiap subvektor ke titik pusat langsung dari matriks, seperti yang ditunjukkan pada gambar berikut: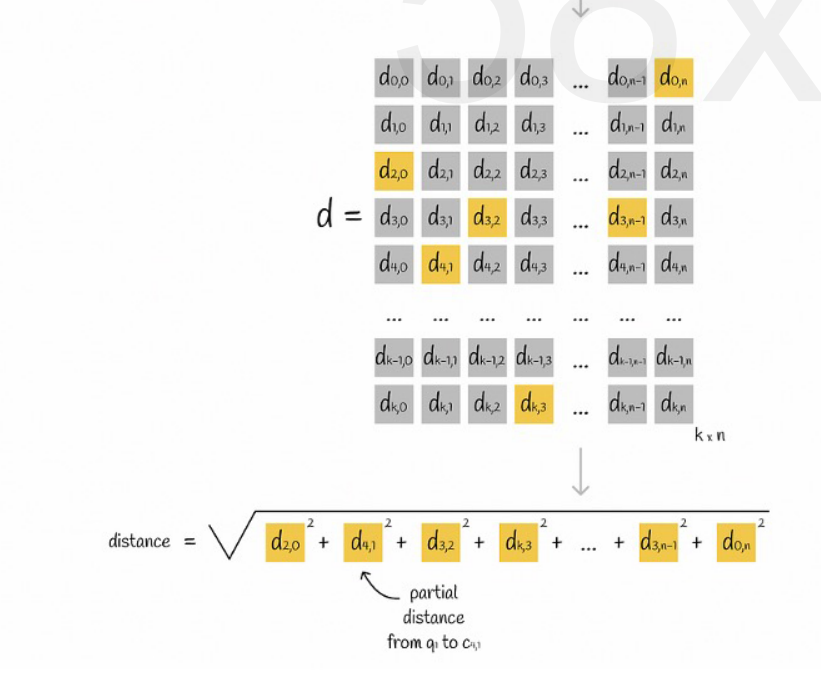
Terakhir kita tinggal menjumlahkan akar kuadrat jarak masing-masing subvektor.
Perkiraan KNN dikombinasikan dengan algoritma PQ
Kedua algoritme ini tidak bertentangan. Pertama-tama Anda dapat menggunakan perkiraan KNN untuk membagi semua vektor menjadi beberapa subruang, lalu menemukan vektor kueri di subruang yang sesuai.
Dengan cara ini, algoritma PQ digunakan di subruang untuk mempercepat perhitungan.
Dalam kumpulan data vektor tertentu, K vektor (K-Nearest Neighbor, KNN) yang dekat dengan vektor kueri diambil berdasarkan metode pengukuran tertentu. Namun, karena penghitungan KNN yang berlebihan, kami biasanya hanya fokus pada perkiraan masalah tetangga terdekat (Perkiraan Terdekat).
Saat membuat gambar, NSW secara acak memilih titik-titik dan menambahkannya ke dalam gambar. Setiap kali sebuah titik ditambahkan, m titik ditemukan sebagai tetangga terdekatnya untuk menambahkan sisi. Struktur akhir terbentuk seperti terlihat pada gambar di bawah ini:
Saat mencari peta NSW, kami memulai dari titik masuk yang telah ditentukan. Titik masuk ini terhubung ke beberapa simpul terdekat. Kami menentukan simpul mana yang paling dekat dengan vektor kueri kami dan pindah ke sana.
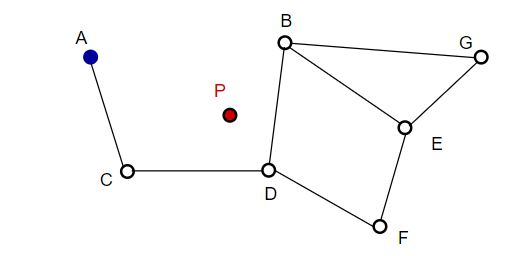
Misalnya, mulai dari A, titik tetangga A, C, diperbarui mendekati P. Kemudian titik D yang berdekatan dari C lebih dekat ke P, kemudian titik B dan F yang berdekatan dari D tidak lebih dekat, dan program berhenti, yaitu titik D.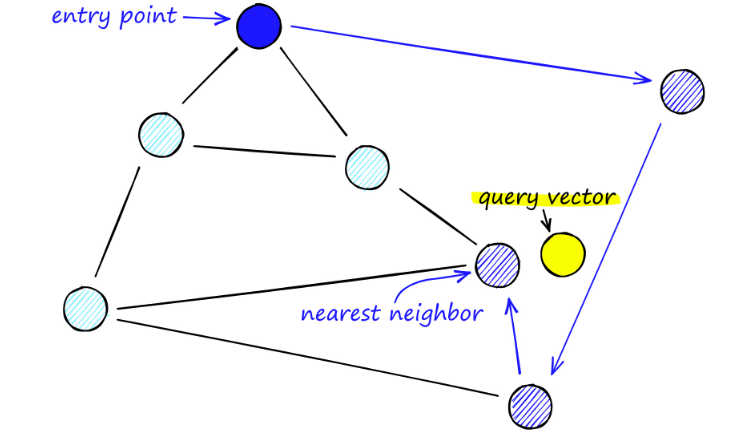
Konstruksi grafik dimulai dari tingkat atas. Setelah berada di dalam grafik, algoritme dengan rakus menelusuri tepinya untuk menemukan tetangga ef terdekat dengan vektor q yang kita sisipkan - saat ini ef = 1.
Setelah nilai minimum lokal ditemukan, nilai tersebut akan turun ke tingkat berikutnya (seperti yang dilakukan selama pencarian). Ulangi proses ini sampai kita mencapai lapisan penyisipan pilihan kita. Di sini dimulailah tahap kedua konstruksi.
Nilai ef ditingkatkan ke parameter efConstruction yang kita tetapkan, yang berarti lebih banyak tetangga terdekat yang akan dikembalikan. Pada tahap kedua, tetangga terdekat ini merupakan kandidat untuk link ke elemen q yang baru disisipkan dan berfungsi sebagai titik masuk ke lapisan berikutnya.
Setelah banyak iterasi, ada dua parameter lagi yang perlu dipertimbangkan saat menambahkan tautan. M_max, yang mendefinisikan jumlah maksimum tautan yang dapat dimiliki sebuah simpul, dan M_max0, yang mendefinisikan jumlah maksimum koneksi untuk sebuah simpul di lapisan 0.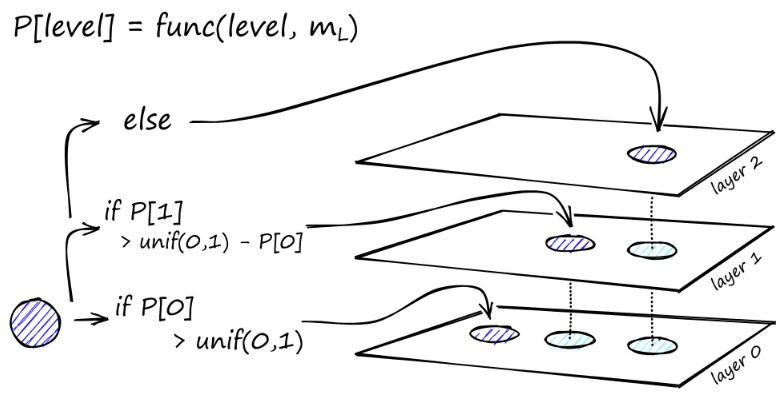
HNSW adalah singkatan dari Hierarchical Navigable Small World, grafik berlapis-lapis. Setiap objek dalam database ditangkap pada level paling bawah (level 0 pada gambar). Objek data ini terhubung dengan sangat baik. Pada setiap lapisan di atas lapisan terbawah, lebih sedikit titik data yang direpresentasikan. Titik data ini cocok dengan lapisan bawah, namun jumlah titik di setiap lapisan atas jauh lebih sedikit secara eksponensial. Jika ada permintaan pencarian, titik data terdekat akan ditemukan di tingkat atas. Pada contoh di bawah, ini hanyalah satu titik data lagi. Kemudian ia melangkah lebih dalam satu tingkat dan menemukan titik data terdekat dari titik data pertama yang ditemukan di tingkat tertinggi dan mencari tetangga terdekat dari sana. Pada tingkat terdalam akan ditemukan objek data aktual yang paling dekat dengan permintaan pencarian.
HNSW adalah metode pencarian kesamaan yang sangat cepat dan hemat memori karena hanya lapisan tertinggi (lapisan atas) yang disimpan dalam cache daripada semua titik data di lapisan terendah. Hanya titik data yang paling dekat dengan permintaan pencarian yang dimuat setelah diminta oleh lapisan yang lebih tinggi, artinya hanya sejumlah kecil memori yang perlu dicadangkan.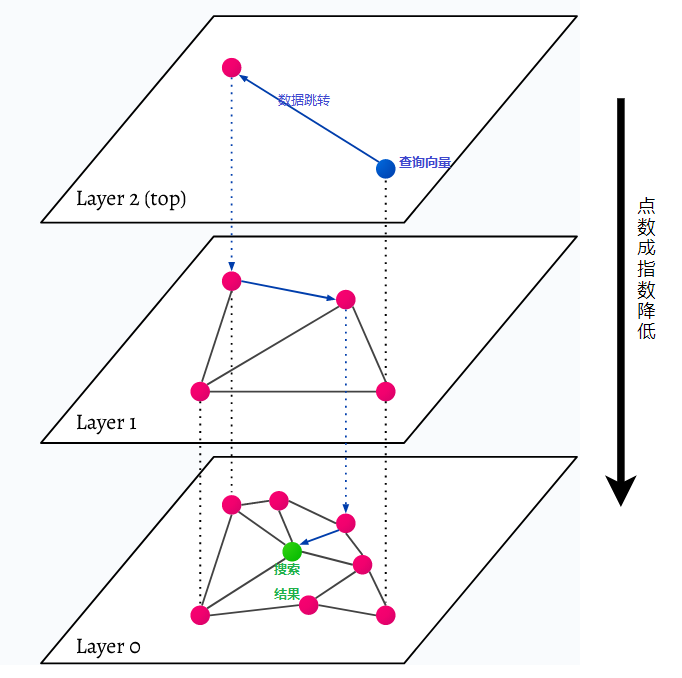

Ia telah mengabdikan dirinya untuk meneliti teknologi selama lebih dari 30 tahun, dan mahir dalam berbagai bahasa seperti java, linux, javascript, php, css, dll. Ia telah memberikan banyak kontribusi di bidang open source stasiun dokumentasi pengembang untuk berbagi beberapa masalah dalam pengembangan teknologi untuk referensi di masa mendatang. Semua orang memeriksanya

Surat[email protected]