2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Vektoritietokanta on nykypäivän laajan mallin tietokannan hakukäytännön ydin. Seuraava kuva on arkkitehtuurikaavio tietokannan haun rakentamiseen.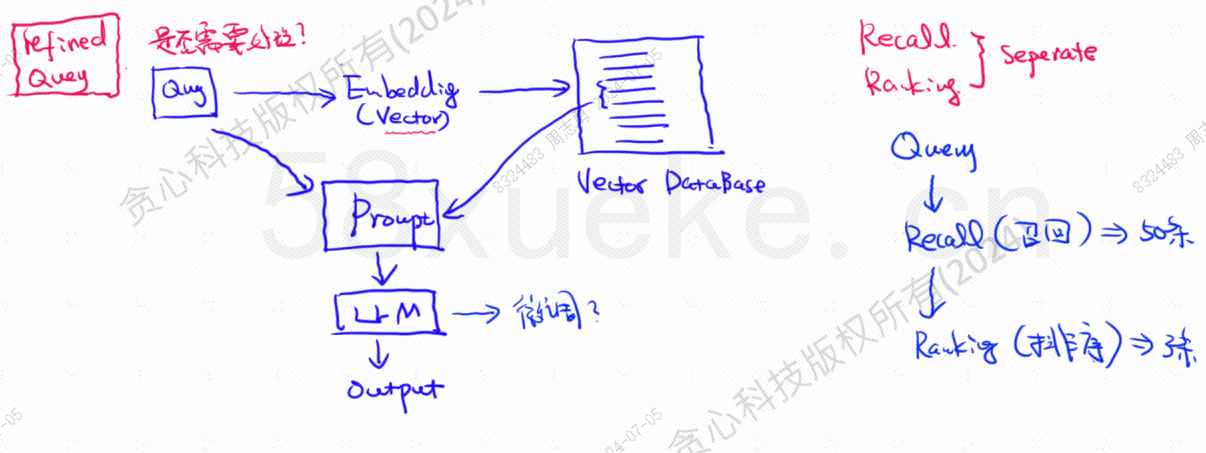
Vektorikyselytietojen ja kyselyn samankaltaisuus vaikuttaa suoraan kehotteen laatuun. Tässä artikkelissa esitellään lyhyesti markkinoilla olevat vektoritietokannat ja selitetään sitten niissä käytetyt indeksointimenetelmät, mukaan lukien käänteinen indeksi, KNN, likimääräinen KNN, tuotteen kvantisointi, HSNW jne. selittää näiden algoritmien suunnittelukonseptit ja menetelmät.
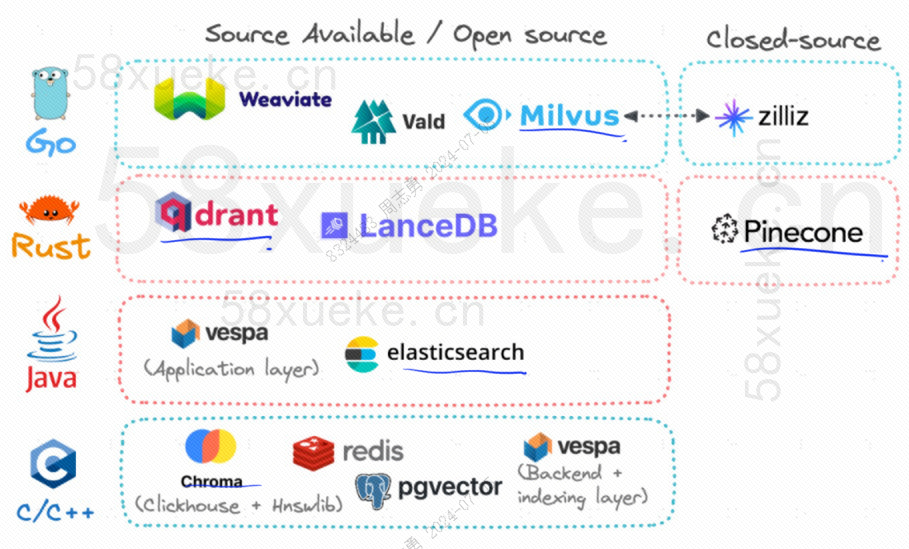
Tällä hetkellä kolme suosittua avoimen lähdekoodin vektoritietokantaa ovat Chroma, Milvus ja Weaviate. Tämä artikkeli niiden esittelystä ja eroista on mielestäni hyvä.Kilpailu kolmen suuren avoimen lähdekoodin vektoritietokannan välillä。
Seuraavassa on avoimen lähdekoodin vektoritietokantojen kehityshistoria: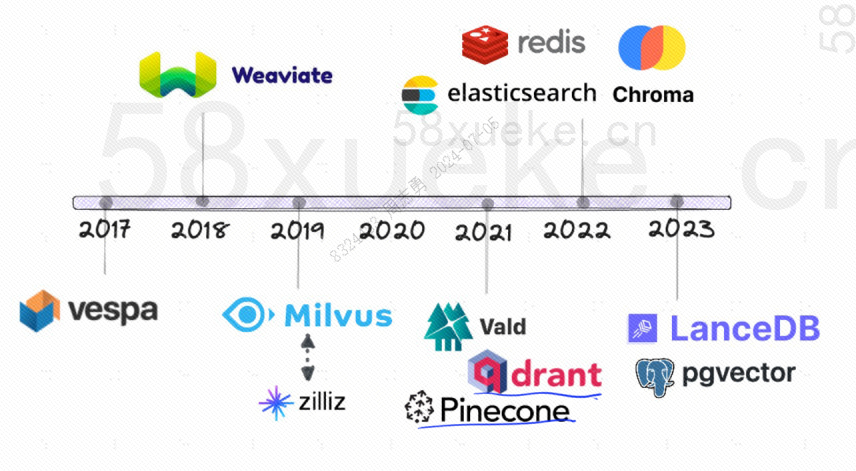
Niiden käyttämät indeksointimenetelmät ovat seuraavat:

Jos minulla on nyt tietokanta, joka käyttää käänteistä indeksiä, joka tallentaa 10^12 indeksitietoa, kun tallennamme tiedot tietokantaan, jaamme tiedot ja tallennamme jaettuja sanoja vastaavat sanat Koska samat sanat voivat esiintyä eri lauseissa, jokainen sana vastaa indeksijoukkoa:
Oletetaan, että minulla on nyt kysely: Mitä kehitystä suurten mallien soveltamisessa on vuonna 2024?
Tietokanta jakaa kyselylauseemme kolmeen avainsanaan: suuri malli, 2024, kehitys.Kysy sitten kutakin sanaa vastaava indeksiyhdistelmä ja etsi leikkauspiste. Tätä kyselyprosessia kutsutaanpalauttaa mieleen.
Tällä hetkellä olemme saaneet kyselyyn liittyvät tiedot, mutta näiden tietojen ja kyselylauseen välinen samankaltaisuus on erilainen. Meidän on lajiteltava ne ja saatava TOP N.
Tällainen kysely, joka vastaa suoraan tekstidataa hakemistoon, ei kuitenkaan ole kovin tehokasta. Voiko samankaltaisuuden hakua mitenkään nopeuttaa?
Tällä hetkellä ilmestyi vektoroitu haku, joka muuntaa tiedot vektoreiksi ja sitten laskee vektorinSamankaltaisuusjaetäisyysHae kahdella tavalla: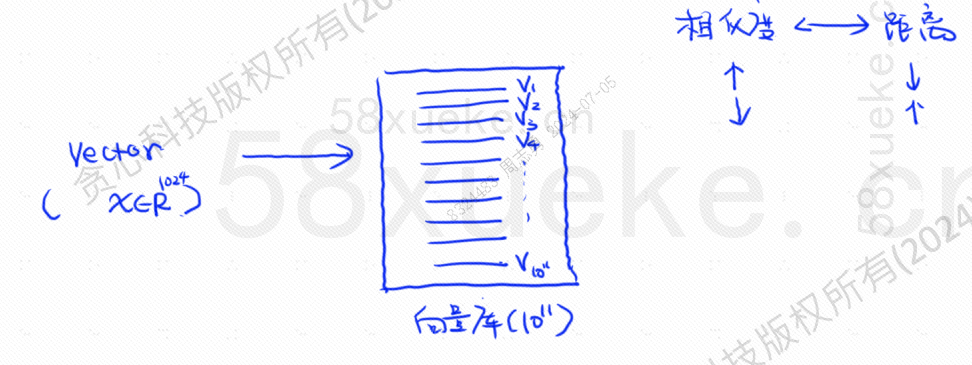
KNN-hakua kutsutaan K lähimmän naapurin hauksi. Se muuntaa kyselylauseen vektoriksi ja löytää sitten vektorin ja vektorin tietokannasta.Suurin samankaltaisuus ja lähin etäisyysvektorijoukko.
Aikamonimutkaisuus on O(N)*O(d), d on ulottuvuus ja mittatiedot ovat yleensä kiinteät. Oletetaan, että tietokantaan on tallennettu 10 000 vektoritietoa ja kaikki mitat ovat 1024, niin kysely. maxSim(q,v)(suurin samankaltaisuus),minDist(q,v)(Lähimmän) vektorin aikakompleksisuus on O(10000)*O(1024).
Tämän hakumenetelmän etuna on, että löydetyt tiedot ovat erittäin tarkkoja, mutta haittana on sen hitaus.
Likimääräinen KNN-haku on muuttaa hakuavaruus pisteistä lohkoiksi ja löytää sitten lähin piste, jolla on suurin samankaltaisuus pika-avaruudessa. Alla olevan kuvan vasen puoli on KNN-haku likimääräinen KNN-haku: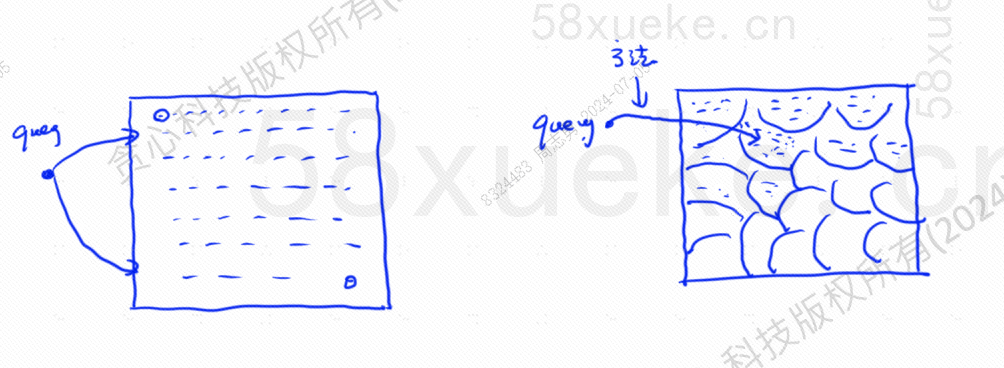
Jokaisessa lohkossa on keskipiste. Kyselypisteen ja lohkon välisen etäisyyden laskeminen on etäisyys kyselypisteestä kunkin lohkon keskipisteeseen.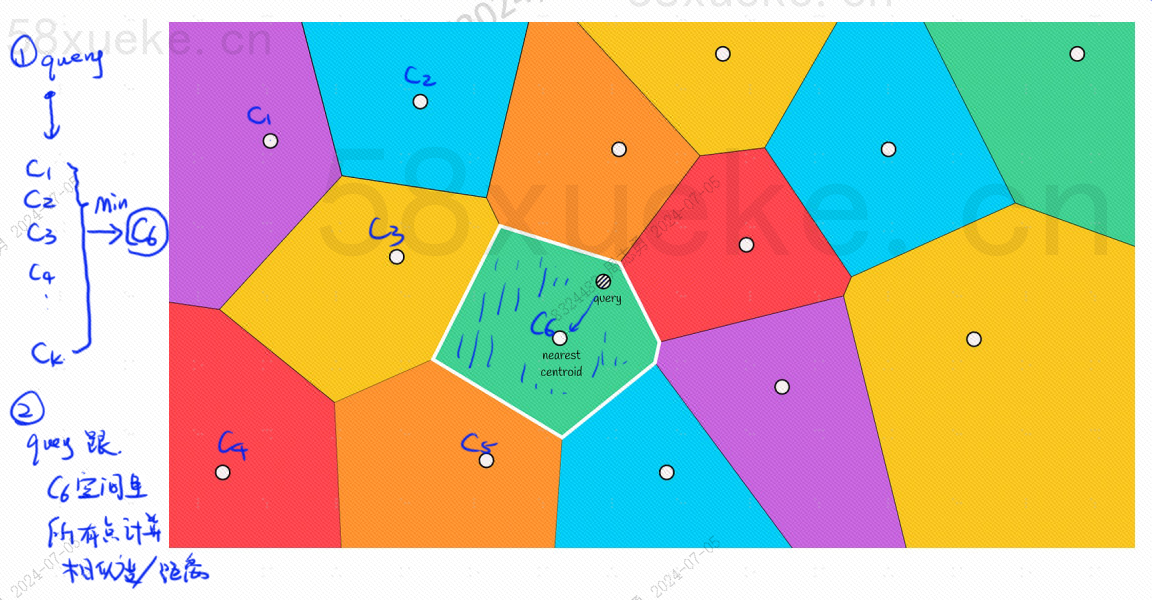
Esimerkiksi yllä olevan kuvan kyselyvaiheet ovat seuraavat:
Voimme kuitenkin nähdä paljaalla silmällä, että vaikka punaisten ja oranssien lohkojen keskipisteet ovat kaukana kyselypisteestä, niiden lohkojen pisteet ovat lähellä kyselypistettä. Tällä hetkellä meidän on laajennettava laajuutta hakulohkosta: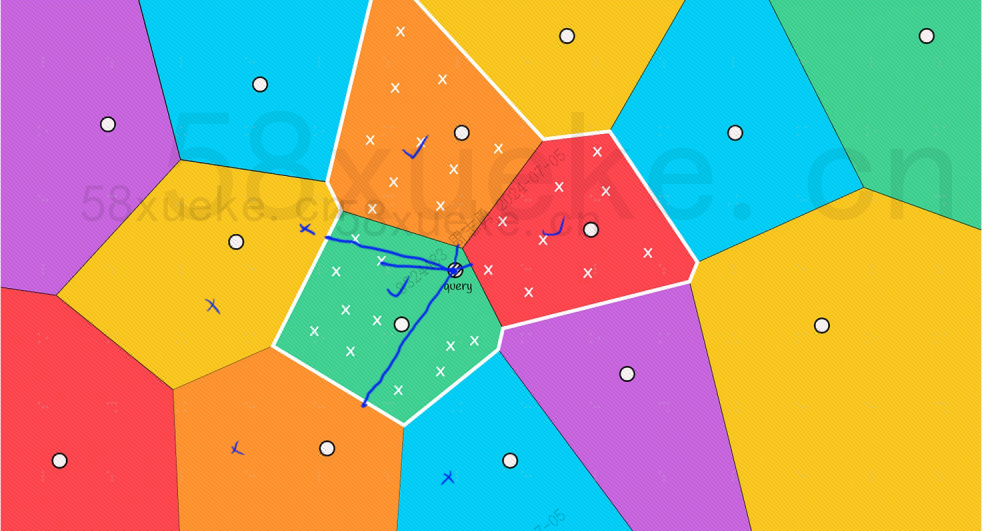
Seuraavassa on algoritmi kaavan suurimman samankaltaisuuden ja lähimmän etäisyyden löytämiseksi. Suurin samankaltaisuus (COS_SIM) lasketaan lähimmän etäisyyden avulla, Euroopan algoritmi ja Manhattan-algoritmi :
PQ-algoritmi jakaa ensin kaikki vektorit useisiin aliavaruuksiin, kuten likimääräisellä KNN:llä, jokaisella aliavaruudella on keskipiste (keskipiste).
Sitten alkuperäinen korkeaulotteinen vektori jaetaan useisiin pieniulotteisiin vektoreihin, ja alivektoria lähimpänä olevaa keskipistettä käytetään alivektorin PQ ID:nä koostua useista PQ ID:istä, jotka pakatut tilaa.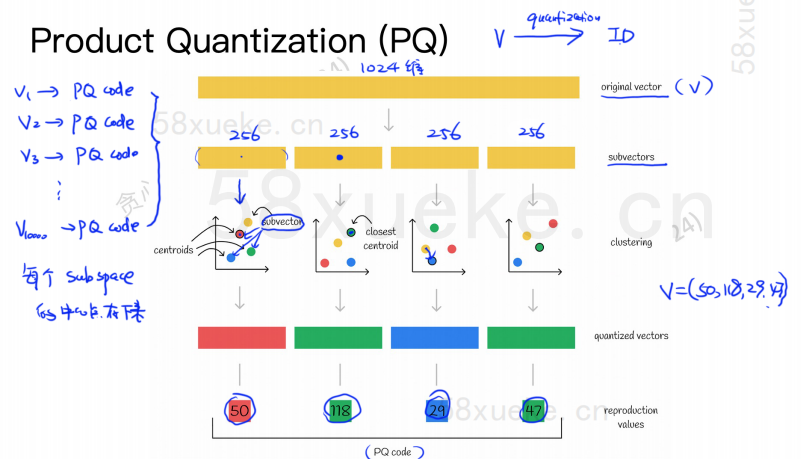
Esimerkiksi 1024-ulotteinen vektori yllä olevassa kuvassa on jaettu neljään 256-ulotteiseen alivektoriin, ja näiden neljän alivektorin lähimmät keskipisteet ovat: 50, 118, 29, 47. Siksi 1024-ulotteinen vektori voidaan esittää V=(50,118,29,47), ja sen PQ-koodi on myös (50,118,29,47).
Siksi PQ-algoritmia käyttävän vektoritietokannan on tallennettava kaikkien keskipisteiden tiedot ja kaikkien korkeadimensionaalisten vektoreiden PQ-koodi.
Oletetaan nyt, että meillä on kyselylause, jonka täytyy kysyä vektoritietokannasta suurin samankaltainen vektori. Kuinka tehdä kysely PQ-algoritmilla?
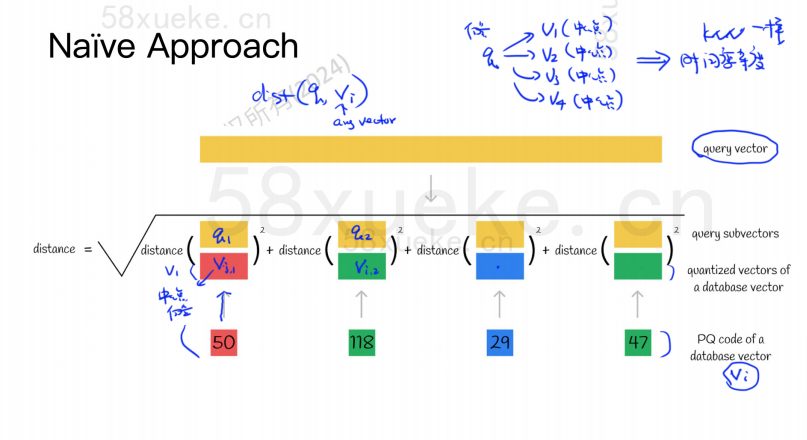
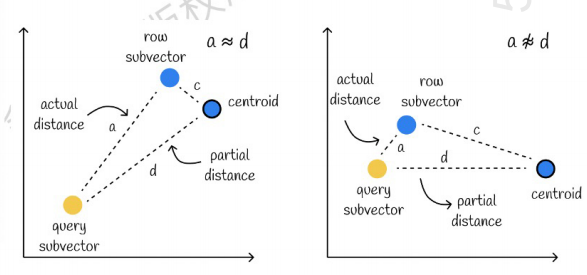
Vasemmanpuoleinen on tapaus, jossa virhe on hyvin pieni, ja oikealla tapaus, jossa virhe on suhteellisen suuri. Yleensä virheitä on muutamia, mutta suurin osa virheistä on suhteellisen pieniä.
Välimuistin käyttäminen laskelmien nopeuttamiseksi
Jos alkuperäinen kyselyvektori ja kunkin alivektorin PQ-koodi vaativat etäisyyslaskennan, ei ole paljon eroa likimääräisestä KNN-algoritmista Tilan monimutkaisuus on O(n)*O(k), niin tämän merkitys algoritmi on mikä? Onko se vain pakkaamista ja tallennustilan vähentämistä varten?
Oletetaan, että kaikki vektorit on jaettu K aliavaruuteen ja jokaisessa aliavaruudessa on n pistettä. Laskemme etukäteen etäisyyden kunkin aliavaruuden pisteestä sen keskipisteeseen, laitamme sen kaksiulotteiseen matriisiin ja kysymme sitten vektorin. vastaavuus Voimme kysyä etäisyyttä kustakin alivektorista keskipisteeseen suoraan matriisista, kuten seuraavassa kuvassa: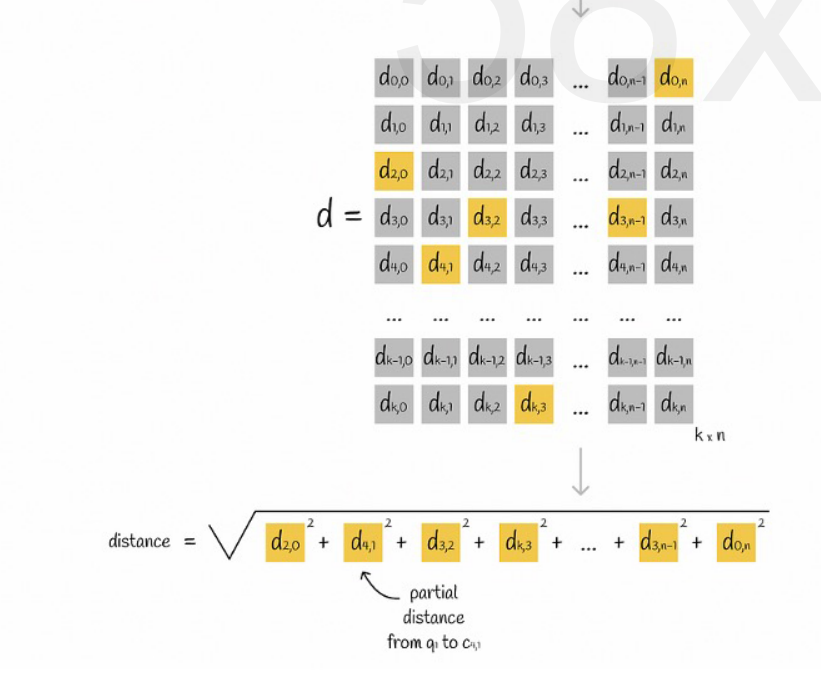
Lopuksi meidän tarvitsee vain lisätä jokaisen alivektorin etäisyyksien neliöjuuret.
Likimääräinen KNN yhdistettynä PQ-algoritmiin
Nämä kaksi algoritmia eivät ole ristiriidassa. Voit ensin käyttää likimääräistä KNN:ää jakaaksesi kaikki vektorit useisiin aliavaruuksiin ja paikantaa sitten kyselyvektorin vastaavasta aliavaruudesta.
Tällä tavalla PQ-algoritmia käytetään aliavaruudessa laskennan nopeuttamiseksi.
Tietyssä vektoritietojoukossa haetaan K vektoria (K-lähin naapuri, KNN), jotka ovat lähellä kyselyvektoria tietyllä mittausmenetelmällä. KNN:n liiallisen laskennan vuoksi keskitymme kuitenkin yleensä vain likimääräiseen lähimpien naapureiden (Approximate Nearest, ANN) ongelma.
Kun sommittelee kuvaa, NSW valitsee satunnaisesti pisteitä ja lisää ne kuvaan. Joka kerta kun piste lisätään, m pistettä havaitaan sen lähimmiksi naapuriksi reunan lisäämiseksi. Lopullinen rakenne muodostetaan alla olevan kuvan mukaisesti:
Kun etsimme NSW-karttoja, aloitamme ennalta määritetyistä lähtöpisteistä. Tämä sisääntulopiste on yhdistetty useisiin lähellä oleviin kärkipisteisiin. Määritämme mikä näistä pisteistä on lähinnä kyselyvektoriamme ja siirrymme sinne.
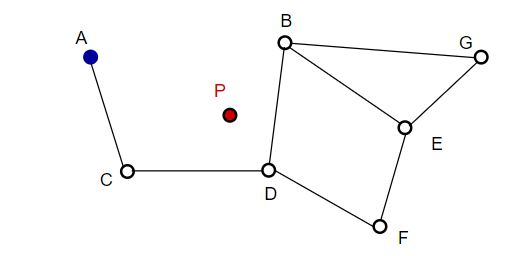
Esimerkiksi A:sta alkaen A:n naapuripiste C päivitetään lähemmäksi P:tä. Silloin C:n viereinen piste D on lähempänä P:tä, ja sitten D:n viereiset pisteet B ja F eivät ole lähempänä, ja ohjelma pysähtyy, joka on piste D.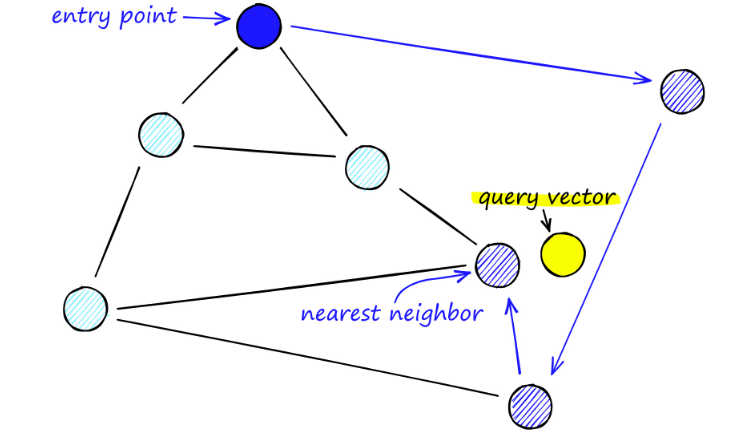
Kaavion rakentaminen alkaa ylätasolta. Kun algoritmi on kaaviossa, se kulkee ahneesti reunojen poikki löytääkseen lähimmän ef-naapurin lisätylle vektorille q - tällä hetkellä ef = 1.
Kun paikallinen minimi on löydetty, se siirtyy alas seuraavalle tasolle (kuten se tehtiin haun aikana). Toista tämä prosessi, kunnes saavutamme valitsemamme lisäyskerroksen. Tästä alkaa rakentamisen toinen vaihe.
ef-arvoa nostetaan asettamamme efConstruction-parametriin, mikä tarkoittaa, että lähimmät naapurit palautetaan enemmän. Toisessa vaiheessa nämä lähimmät naapurit ovat ehdokkaita linkeiksi vasta lisättyyn elementtiin q ja toimivat sisääntulopisteinä seuraavaan kerrokseen.
Useiden iteraatioiden jälkeen on vielä kaksi parametria, jotka on otettava huomioon lisättäessä linkkejä. M_max, joka määrittää linkkien enimmäismäärän, joka kärjessä voi olla, ja M_max0, joka määrittää kerroksen 0 kärkipisteen yhteyksien enimmäismäärän.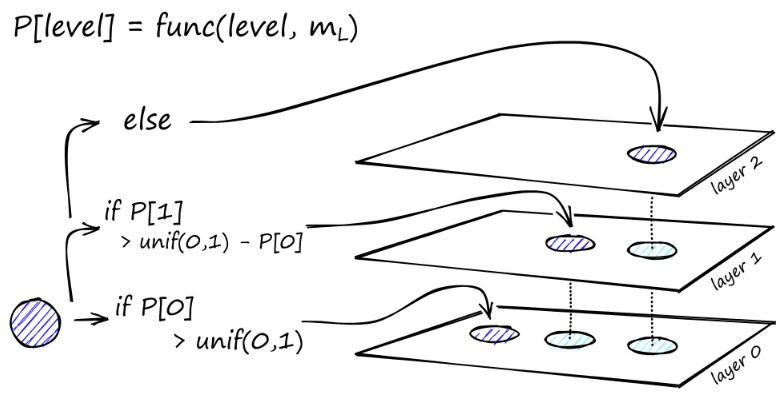
HNSW on lyhenne sanoista Hierarchical Navigable Small World, monikerroksinen graafi. Jokainen tietokannan kohde kaapataan alimmalla tasolla (taso 0 kuvassa). Nämä tietoobjektit ovat yhteydessä erittäin hyvin. Jokaisessa alimman kerroksen yläpuolella olevassa kerroksessa on vähemmän tietopisteitä. Nämä tietopisteet vastaavat alempia kerroksia, mutta jokaisessa ylemmässä kerroksessa on eksponentiaalisesti vähemmän pisteitä. Jos on hakukysely, lähimmät tietopisteet löytyvät ylimmältä tasolta. Alla olevassa esimerkissä tämä on vain yksi lisätietopiste. Sitten se menee yhden tason syvemmälle ja etsii lähimmän datapisteen ensimmäisestä korkeimmalla tasolla löydetystä ja etsii sieltä lähimmät naapurit. Syvimmällä tasolla löydetään varsinainen tietoobjekti, joka on lähinnä hakukyselyä.
HNSW on erittäin nopea ja muistitehokas samankaltaisuuden hakumenetelmä, koska vain ylin kerros (yläkerros) tallennetaan välimuistiin kaikkien alimman kerroksen tietopisteiden sijaan. Vain hakukyselyä lähinnä olevat datapisteet ladataan ylempien kerrosten pyynnön jälkeen, mikä tarkoittaa, että vain pieni määrä muistia tarvitsee varata.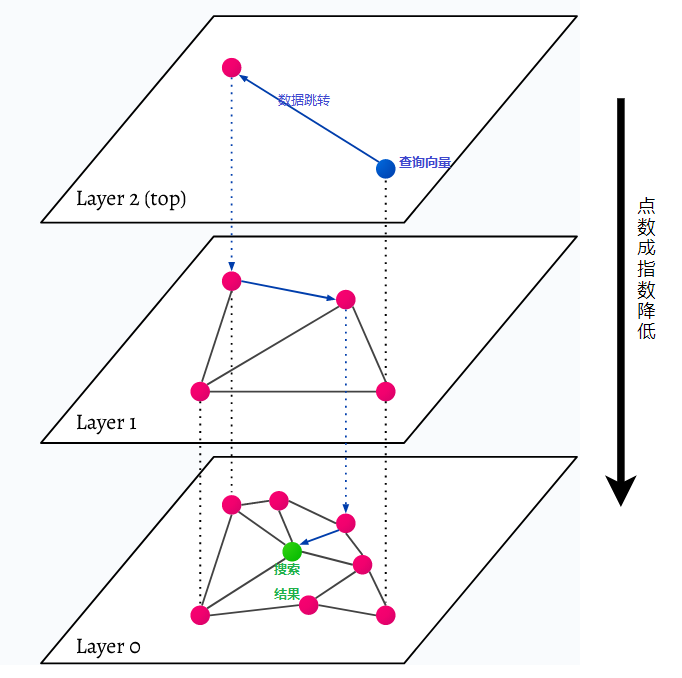

Hän on omistautunut teknologian tutkimukselle yli 30 vuoden ajan ja hallitsee useita kieliä, kuten java, linux, javascript, php, css jne. Hän on tehnyt paljon työtä avoimen lähdekoodin alalla Kehittäjän dokumentaatioasema, jossa voit jakaa joitakin teknologian kehittämisen ongelmia myöhempää käyttöä varten
