내 연락처 정보
우편메소피아@프로톤메일.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
벡터 데이터베이스는 오늘날의 대규모 모델 지식 기반 검색 실행의 핵심 구성 요소입니다. 다음 그림은 지식 기반 검색 구축을 위한 아키텍처 다이어그램입니다.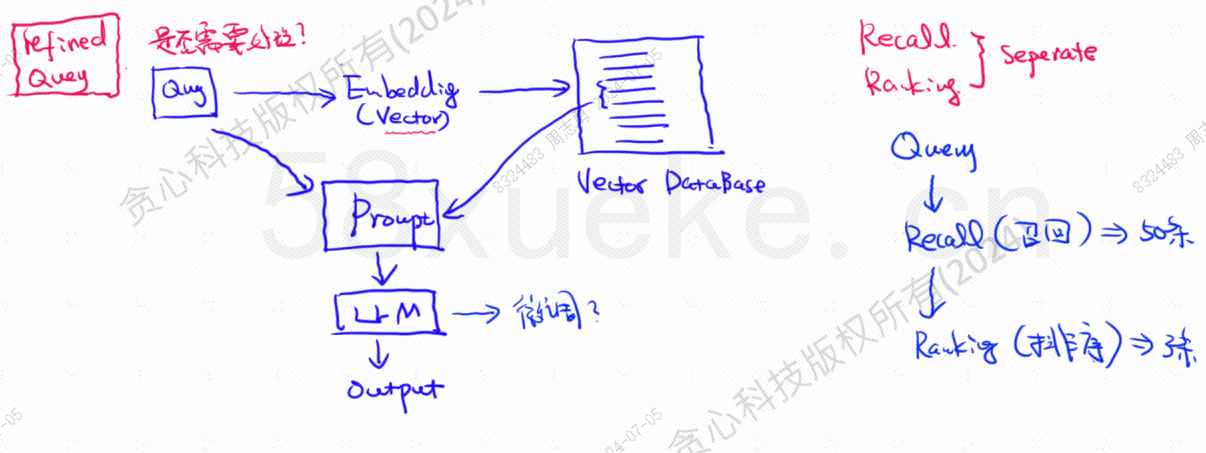
벡터 쿼리 데이터와 쿼리의 유사성은 프롬프트 품질에 직접적인 영향을 미칩니다. 본 글에서는 시중에 나와 있는 기존 벡터 데이터베이스를 간략하게 소개한 후, 역인덱스, KNN, 근사 KNN, 제품 양자화 등 여기에 사용되는 인덱싱 방법을 설명합니다. HSNW 등에서는 이러한 알고리즘의 설계 개념과 방법을 설명합니다.
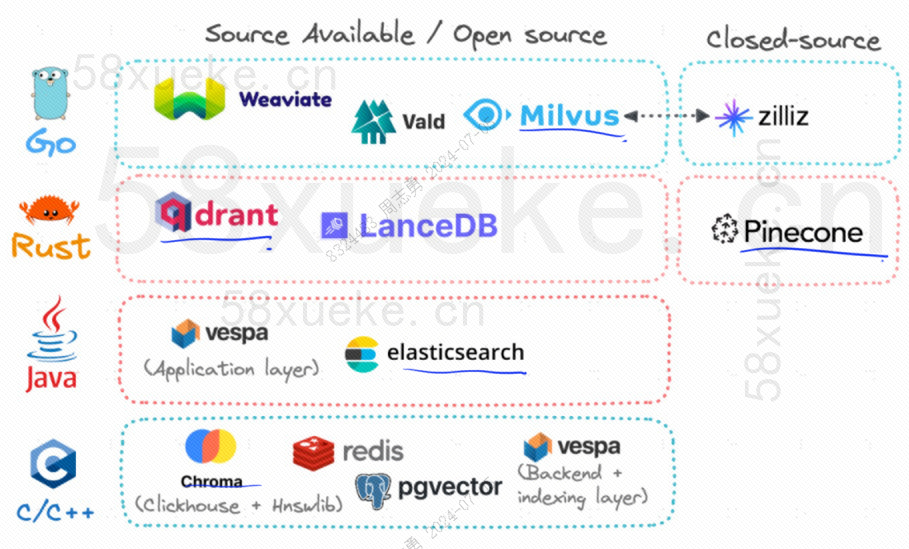
현재 인기 있는 세 가지 오픈 소스 벡터 데이터베이스는 Chroma, Milvus 및 Weaviate입니다. 관심이 있으시면 이 기사를 읽어보시면 좋습니다.세 가지 주요 오픈 소스 벡터 데이터베이스 간의 경쟁。
오픈소스 벡터 데이터베이스의 개발 이력은 다음과 같습니다.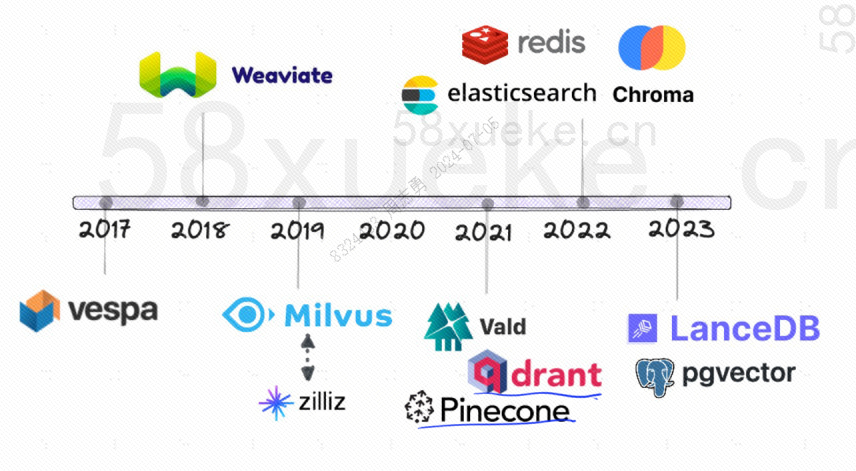
그들이 사용하는 인덱싱 방법은 다음과 같습니다.

이제 10^12 인덱스 데이터를 저장하는 역 인덱스를 사용하는 데이터베이스가 있는 경우 데이터베이스에 데이터를 저장할 때 데이터를 분할한 다음 분할된 단어에 해당하는 단어를 기록합니다. 동일한 단어가 다른 문장에 나타날 수 있으므로 각 단어는 인덱스 세트에 해당합니다.
이제 쿼리가 있다고 가정해 보겠습니다. 2024년에는 대형 모델 적용에 어떤 발전이 있을까요?
데이터베이스는 우리의 쿼리문을 대형 모델, 2024, 개발이라는 세 가지 키워드로 나눕니다.그런 다음 각 단어에 해당하는 색인 조합을 쿼리하고 교차점을 찾는 과정을 호출합니다.상기하다.
이때 쿼리와 관련된 데이터를 얻었으나 이들 데이터와 쿼리문의 유사성이 다르기 때문에 이를 정렬하여 TOP N을 얻어야 합니다.
그러나 텍스트 데이터를 인덱스에 직접 대응시키는 이러한 종류의 쿼리는 그다지 효율적이지 않습니다. 유사성 검색 속도를 높일 수 있는 방법이 있습니까?
이때 데이터를 벡터로 변환한 후 벡터를 계산하는 벡터화 검색이 등장했습니다.유사성그리고거리두 가지 방법으로 검색하세요.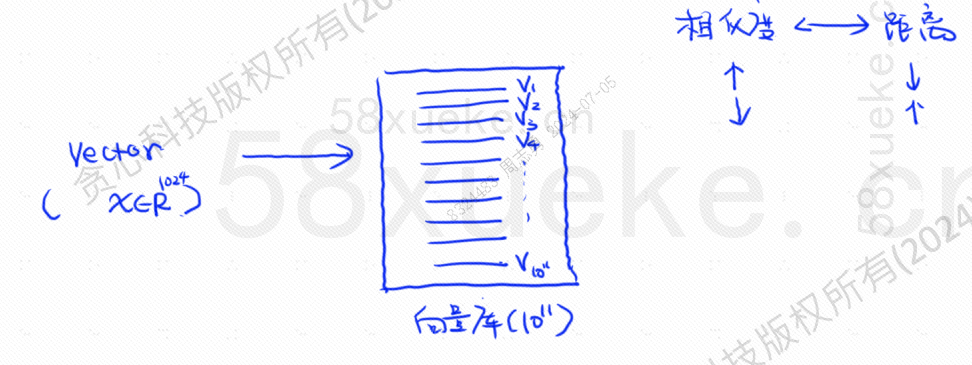
KNN 검색은 K 최근접 이웃 검색(K Nearest Neighbor Search)이라고 합니다. 쿼리 문을 벡터로 변환한 후 데이터베이스에서 벡터와 벡터를 찾습니다.가장 높은 유사성과 가장 가까운 거리벡터 집합입니다.
시간 복잡도는 O(N)*O(d)이고, d는 차원이며 차원 데이터는 일반적으로 데이터베이스에 10,000개의 벡터 데이터가 저장되어 있고 차원이 모두 1024라고 가정하면 쿼리가 수행됩니다. maxSim(q,v)(가장 높은 유사성),minDist(q,v)(가장 가까운) 벡터의 시간 복잡도는 O(10000)*O(1024)입니다.
이 검색 방법의 장점은 찾은 데이터의 정확도가 높다는 점이지만, 속도가 느리다는 단점이 있습니다.
근사 KNN 검색은 검색 공간을 점에서 블록으로 변경하는 것입니다. 먼저 가장 가까운 블록을 결정한 다음 빠른 공간에서 가장 가까운 점을 찾는 것입니다. 아래 그림의 왼쪽은 KNN 검색입니다. 대략적인 KNN 검색: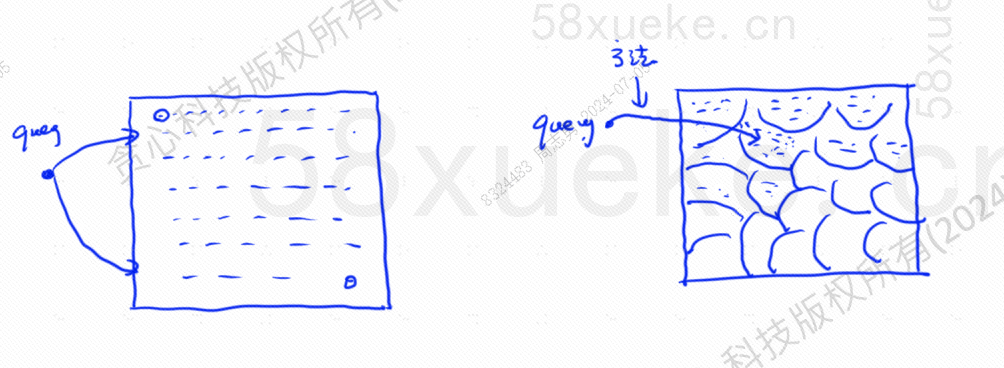
각 블록에는 중심점이 있습니다. 쿼리 점과 블록 사이의 거리를 계산하는 것은 쿼리 점에서 각 블록의 중심점까지의 거리를 계산하는 것입니다.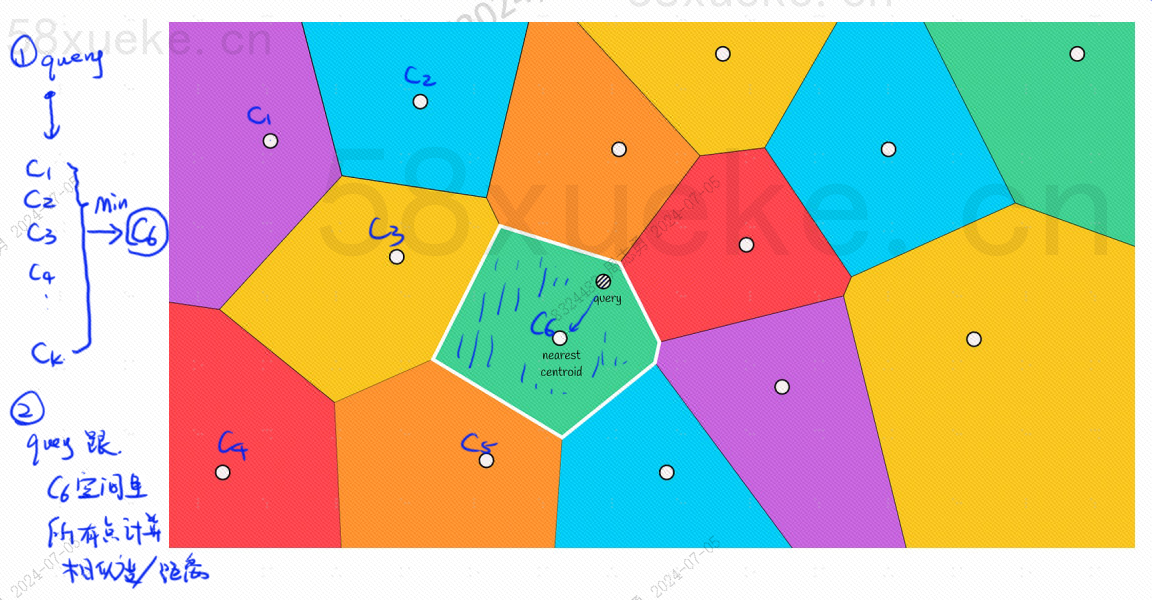
예를 들어 위 그림의 쿼리 단계는 다음과 같습니다.
그러나 빨간색과 주황색 블록의 중심점은 쿼리 지점에서 멀리 떨어져 있지만 해당 블록의 포인트는 쿼리 지점에 가깝다는 것을 육안으로 볼 수 있습니다. 이때 범위를 확장해야 합니다. 검색 블록: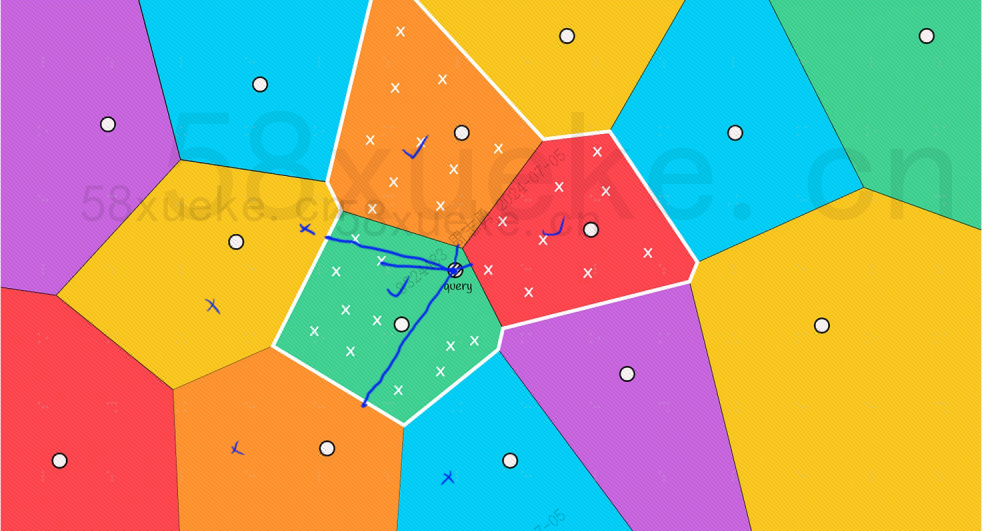
다음은 가장 높은 유사도와 가장 가까운 거리를 찾는 알고리즘 공식입니다. 가장 가까운 거리를 계산하는 알고리즘에는 유럽 알고리즘과 맨하탄 알고리즘이 있습니다. 여기서는 설명하지 않겠습니다. :
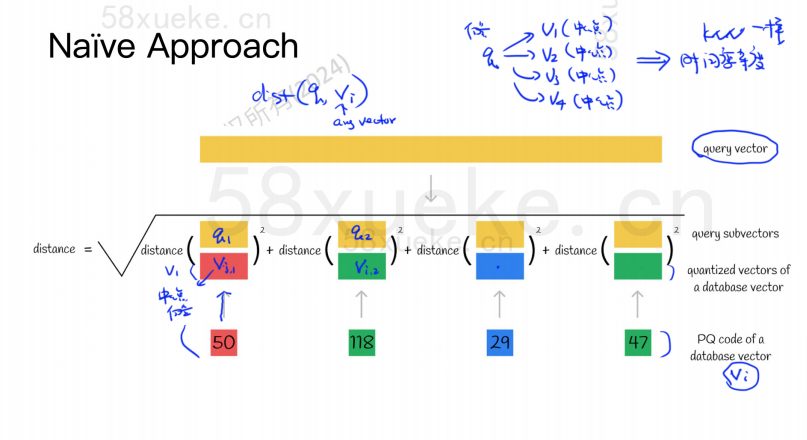
PQ 알고리즘은 먼저 모든 벡터를 대략적인 KNN과 마찬가지로 여러 부분 공간으로 나눕니다. 각 부분 공간에는 중심점(중심)이 있습니다.
그런 다음 원래 고차원 벡터는 여러 개의 저차원 벡터 하위 벡터로 분할되고 하위 벡터에 가장 가까운 중심점이 하위 벡터의 PQ ID로 사용됩니다. 공간을 크게 압축하는 여러 PQ ID로 구성됩니다.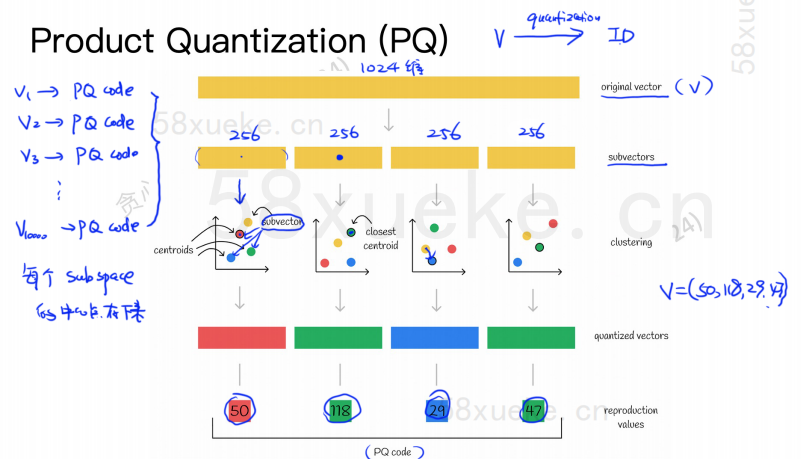
예를 들어, 위 그림의 1024차원 벡터는 4개의 256차원 하위 벡터로 분할되며, 이 4개 하위 벡터의 가장 가까운 중심점은 50, 118, 29, 47입니다. 따라서 1024차원 벡터는 V=(50,118,29,47)로 표현될 수 있으며, 그 PQ 코드도 (50,118,29,47)이다.
따라서 PQ 알고리즘을 사용하는 벡터 데이터베이스는 모든 고차원 벡터의 모든 중심점 정보와 PQ 코드를 저장해야 합니다.
이제 벡터 데이터베이스에서 유사성이 가장 높은 벡터를 쿼리해야 하는 쿼리 문이 있다고 가정합니다. PQ 알고리즘을 사용하여 쿼리하는 방법은 무엇입니까?
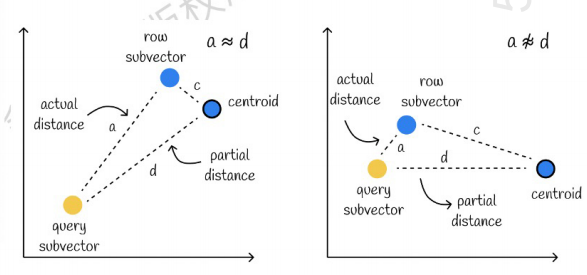
왼쪽은 오차가 매우 작은 경우이고, 오른쪽은 오차가 상대적으로 큰 경우입니다. 일반적으로 오차는 거의 없으나 대부분의 오차가 상대적으로 작습니다.
캐싱을 사용하여 계산 속도 향상
원본 쿼리 벡터와 각 하위 벡터의 PQ 코드에 거리 계산이 필요한 경우 근사 KNN 알고리즘과 큰 차이가 없으며 공간 복잡도는 O(n)*O(k)이므로 이 의미는 다음과 같습니다. 알고리즘이 뭐야? 단지 압축하고 공간 저장 공간을 줄이기 위한 것인가요?
모든 벡터가 K개의 부분공간으로 나누어지고, 각 부분공간에 n개의 점이 있다고 가정하고, 각 부분공간의 점에서 중심점까지의 거리를 미리 계산하여 2차원 행렬에 넣은 후 벡터를 쿼리합니다. 다음 그림과 같이 각 하위 벡터에서 중심점까지의 거리를 행렬에서 직접 쿼리할 수 있습니다.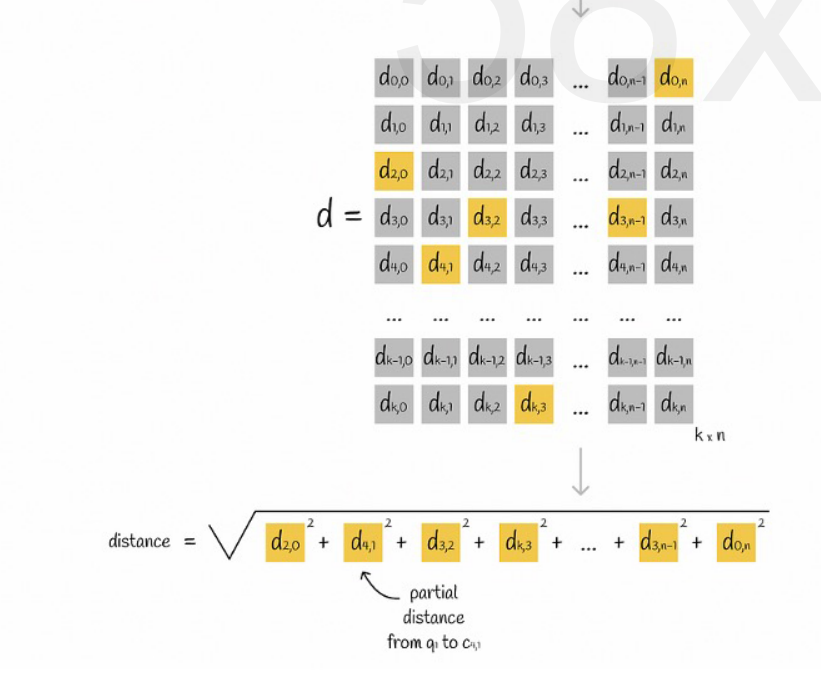
마지막으로 각 하위 벡터 거리의 제곱근을 더하면 됩니다.
PQ 알고리즘과 결합된 근사 KNN
이 두 알고리즘은 충돌하지 않습니다. 먼저 근사 KNN을 사용하여 모든 벡터를 여러 부분 공간으로 나눈 다음 해당 부분 공간에서 쿼리 벡터를 찾을 수 있습니다.
이와 같이 계산 속도를 높이기 위해 부분 공간에서 PQ 알고리즘을 사용합니다.
주어진 벡터 데이터 세트에서 특정 측정 방법에 따라 쿼리 벡터에 가까운 K개의 벡터(K-Nearest Neighbor, KNN)를 검색합니다. 그러나 KNN의 과도한 계산으로 인해 일반적으로 근사치에만 중점을 둡니다. 가장 가까운 이웃(ANN) 문제.
사진을 구성할 때 NSW는 무작위로 점을 선택하여 사진에 추가합니다. 점이 추가될 때마다 m개의 점을 검색하여 가장 가까운 이웃을 찾아 가장자리를 추가합니다. 최종 구조는 아래 그림과 같이 형성됩니다.
NSW 지도를 검색할 때는 미리 정의된 진입점부터 시작합니다. 이 진입점은 인근의 여러 정점에 연결됩니다. 우리는 이러한 정점 중 쿼리 벡터에 가장 가까운 정점을 결정하고 그곳으로 이동합니다.
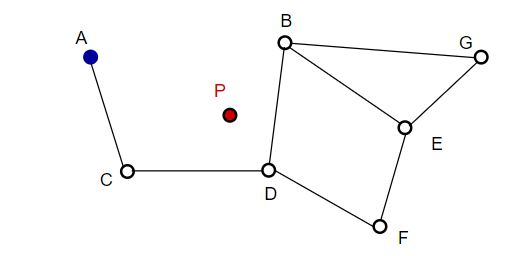
예를 들어 A부터 시작하여 A의 이웃 지점 C가 P에 더 가깝게 업데이트됩니다. 그러면 C의 인접한 점 D는 P에 더 가까워지고 D의 인접한 점 B와 F는 더 가깝지 않게 되며 프로그램이 중지됩니다. 이것이 바로 D입니다.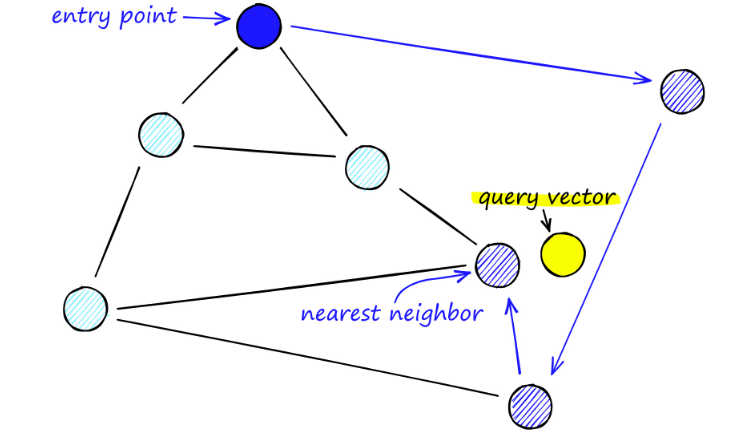
그래프의 구성은 최상위 수준에서 시작됩니다. 그래프에 들어가면 알고리즘은 우리가 삽입한 벡터 q에 가장 가까운 ef 이웃을 찾기 위해 가장자리를 탐욕스럽게 탐색합니다. 이때 ef = 1입니다.
지역 최소값을 찾으면 다음 수준으로 이동합니다(검색 중에 수행된 것과 동일). 선택한 삽입 레이어에 도달할 때까지 이 과정을 반복합니다. 여기서 건설의 두 번째 단계가 시작됩니다.
ef 값은 우리가 설정한 efConstruction 매개변수로 증가합니다. 이는 가장 가까운 이웃이 더 많이 반환된다는 의미입니다. 두 번째 단계에서 이러한 가장 가까운 이웃은 새로 삽입된 요소 q에 대한 링크의 후보이며 다음 레이어에 대한 진입점 역할을 합니다.
여러 번 반복한 후에 링크를 추가할 때 고려해야 할 두 가지 매개변수가 더 있습니다. 정점이 가질 수 있는 최대 링크 수를 정의하는 M_max와 레이어 0의 정점에 대한 최대 연결 수를 정의하는 M_max0입니다.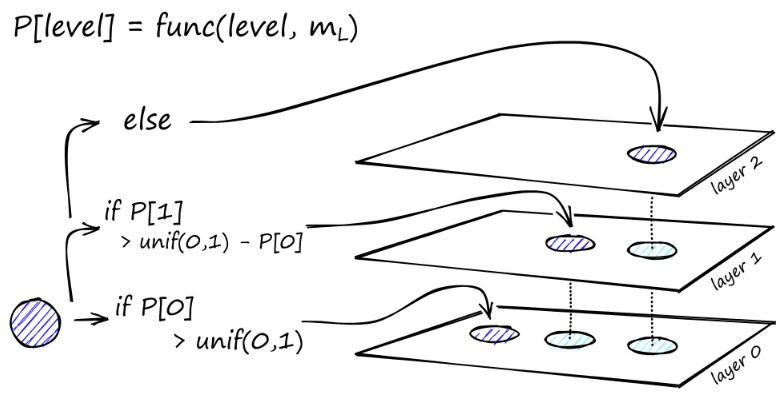
HNSW는 다층 그래프인 Hierarchical Navigable Small World를 나타냅니다. 데이터베이스의 모든 개체는 가장 낮은 수준(그림의 수준 0)에서 캡처됩니다. 이러한 데이터 개체는 매우 잘 연결되어 있습니다. 가장 낮은 레이어 위의 각 레이어에는 더 적은 수의 데이터 포인트가 표시됩니다. 이러한 데이터 포인트는 하위 레이어와 일치하지만 각 상위 레이어에는 기하급수적으로 적은 포인트가 있습니다. 검색어가 있는 경우 가장 가까운 데이터 포인트가 최상위 수준에서 검색됩니다. 아래 예에서 이것은 단지 하나의 데이터 포인트일 뿐입니다. 그런 다음 한 수준 더 깊이 들어가 가장 높은 수준에서 찾은 첫 번째 데이터 지점에서 가장 가까운 데이터 지점을 찾고 거기에서 가장 가까운 이웃을 검색합니다. 가장 깊은 수준에서는 검색 쿼리에 가장 가까운 실제 데이터 개체가 검색됩니다.
HNSW는 가장 낮은 레이어의 모든 데이터 포인트가 아닌 가장 높은 레이어(최상위 레이어)만 캐시에 저장되므로 매우 빠르고 메모리 효율적인 유사성 검색 방법입니다. 상위 계층에서 요청한 후에는 검색 쿼리에 가장 가까운 데이터 포인트만 로드됩니다. 즉, 적은 양의 메모리만 예약하면 됩니다.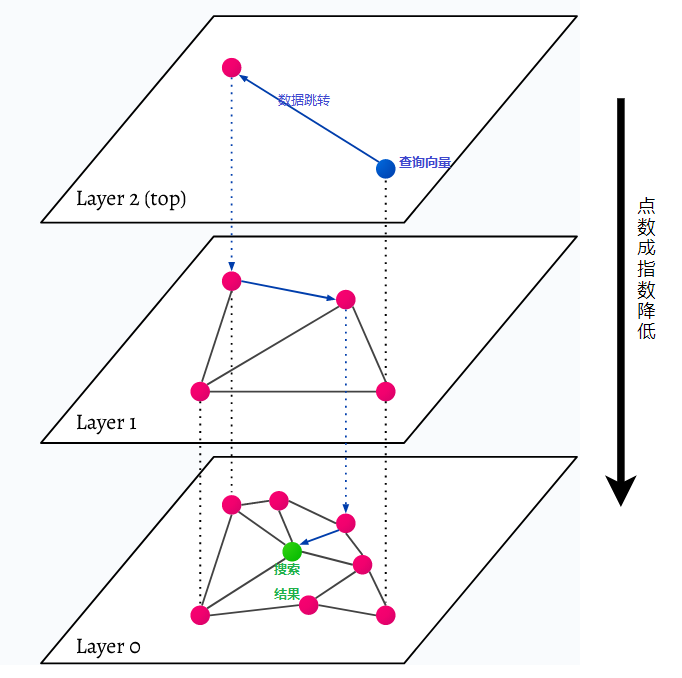

그는 30년 이상 기술 연구에 전념해 왔으며, java, linux, javascript, php, css 등 다양한 언어에 능숙하며, 오픈 소스 분야에서 많은 공헌을 했습니다. 나중에 참조할 수 있도록 기술 개발의 일부 문제를 공유하는 개발자 문서 스테이션입니다.

우편메소피아@프로톤메일.com