2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
La base de données vectorielle est le composant central de la pratique actuelle de récupération de base de connaissances sur de grands modèles. La figure suivante est un diagramme d'architecture permettant de créer une récupération de base de connaissances :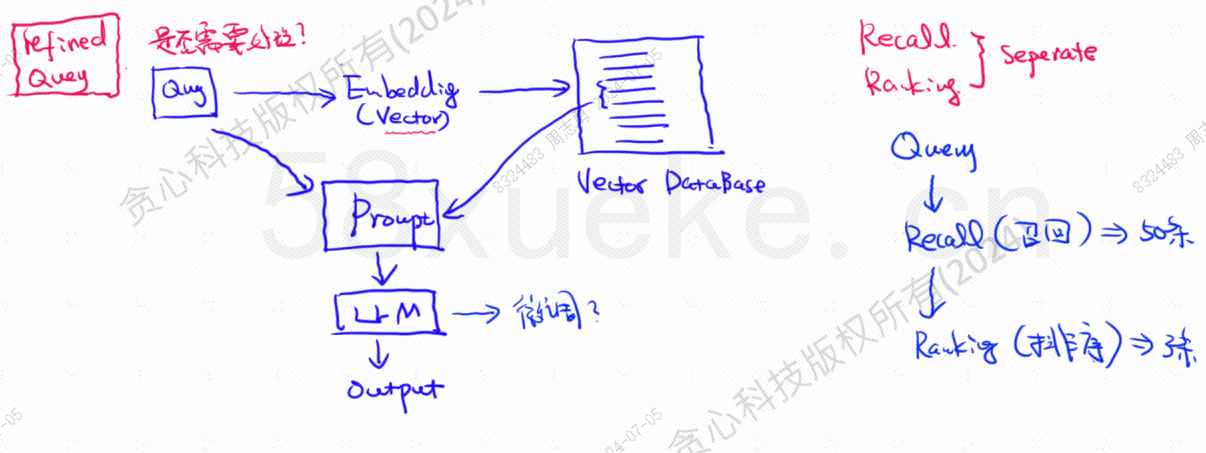
La similitude entre les données de requête vectorielle et la requête affecte directement la qualité de l'invite.Cet article présentera brièvement les bases de données vectorielles existantes sur le marché, puis expliquera les méthodes d'indexation utilisées, notamment l'index inversé, KNN, KNN approximatif, la quantification du produit, HSNW, etc., expliquera les concepts de conception et les méthodes de ces algorithmes.
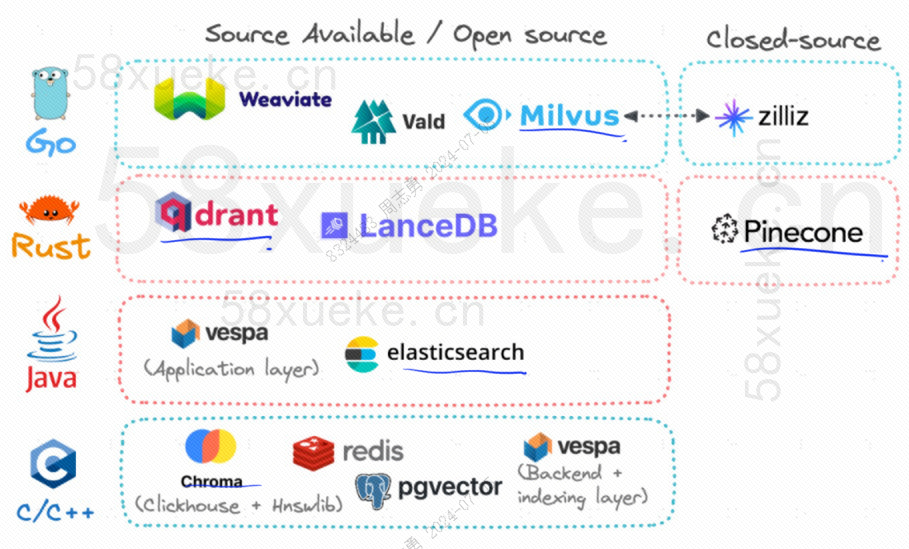
Actuellement, les trois bases de données vectorielles open source populaires sont Chroma, Milvus et Weaviate. Je pense que cet article sur leur introduction et leurs différences est bon. Si vous êtes intéressé, vous pouvez le lire :Concurrence entre trois principales bases de données vectorielles open source。
Voici l’historique du développement des bases de données vectorielles open source :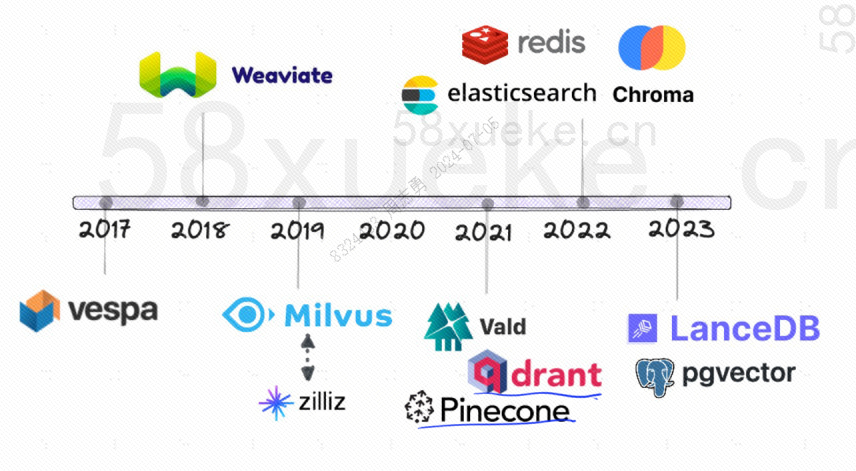
Les méthodes d'indexation qu'ils utilisent sont les suivantes :

Si j'ai maintenant une base de données qui utilise un index inversé, qui stocke 10 ^ 12 données d'index, lorsque nous stockons les données dans la base de données, nous diviserons les données, puis enregistrerons les mots correspondant aux mots divisés. Quels sont les index. positions ? Parce que les mêmes mots peuvent apparaître dans des phrases différentes, chaque mot correspond à un ensemble d'index :
Supposons maintenant que j'ai une requête : Quelles évolutions aura l’application des grands modèles en 2024 ?
La base de données divise notre énoncé de requête en trois mots clés : grand modèle, 2024, développement.Recherchez ensuite la combinaison d'index correspondant à chaque mot et trouvez l'intersection. Ce processus de requête est appelé.rappel.
À l'heure actuelle, nous avons obtenu les données associées à la requête, mais la similitude entre ces données et l'instruction de requête est différente. Nous devons les trier et obtenir TOP N.
Cependant, ce type de requête qui fait directement correspondre les données texte à l'index n'est pas très efficace. Existe-t-il un moyen d'accélérer la récupération des similarités ?
A cette époque, la récupération vectorisée est apparue, convertissant les données en vecteurs, puis calculant le vecteurSimilaritéetdistanceRecherchez de deux manières :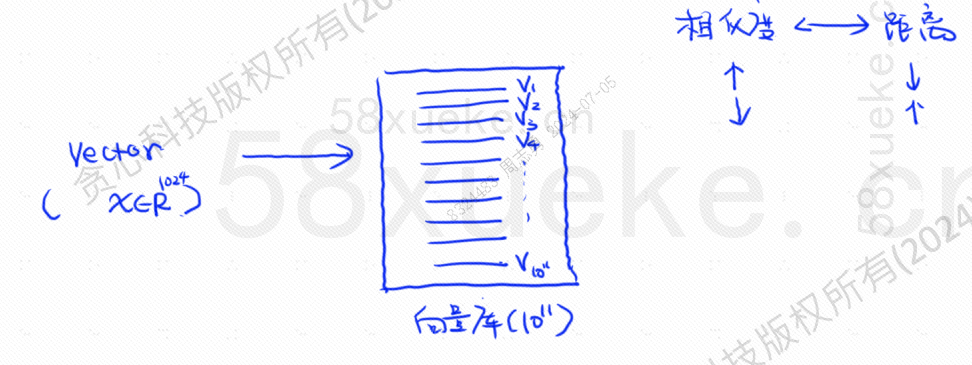
La recherche KNN est appelée recherche du voisin le plus proche. Elle convertit l'instruction de requête en vecteur, puis trouve le vecteur et le vecteur dans la base de données.La plus grande similitude et la distance la plus procheensemble de vecteurs.
La complexité temporelle est O(N)*O(d), d est la dimension et les données dimensionnelles sont généralement fixes. Supposons que 10 000 données vectorielles sont stockées dans la base de données et que les dimensions sont toutes de 1 024, alors la requête. maxSim(q,v)(plus grande similarité),minDist(q,v)La complexité temporelle du vecteur (le plus proche) est O(10000)*O(1024).
L’avantage de cette méthode de récupération est que les données trouvées sont très précises, mais l’inconvénient est qu’elle est lente.
La recherche KNN approximative consiste à modifier l'espace de recherche de points en blocs. Déterminez d'abord le bloc le plus proche, puis trouvez le point le plus proche avec la plus grande similitude dans l'espace rapide. Le côté gauche de la figure ci-dessous est la recherche KNN et le bord est. recherche KNN approximative :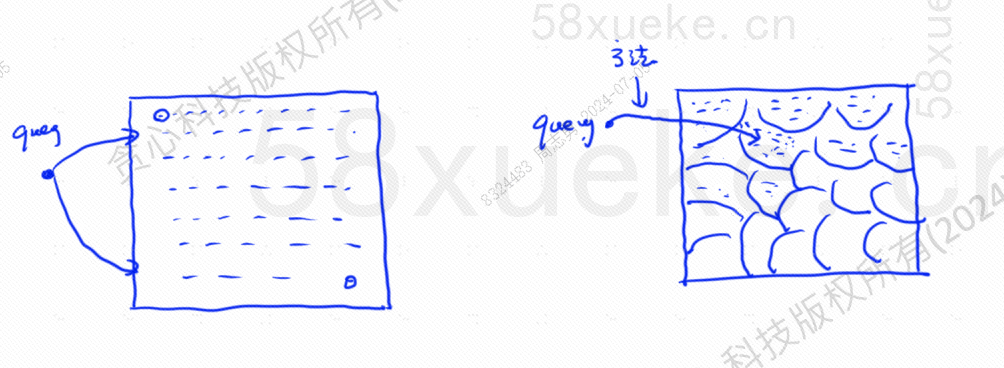
Il y aura un point central dans chaque bloc. Calculer la distance entre le point de requête et le bloc consiste à calculer la distance entre le point de requête et le point central de chaque bloc :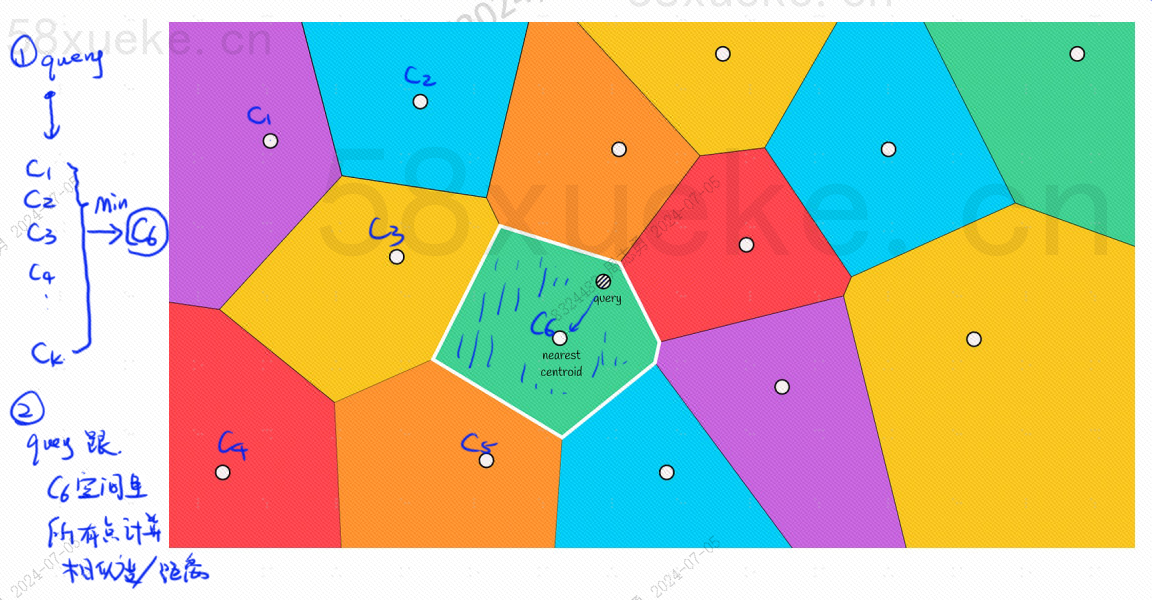
Par exemple, les étapes de requête dans l'image ci-dessus sont les suivantes :
Cependant, nous pouvons voir à l'œil nu que même si les points centraux des blocs rouge et orange sont éloignés du point de requête, les points de leurs blocs sont proches du point de requête. À ce stade, nous devons élargir la portée. du bloc de recherche :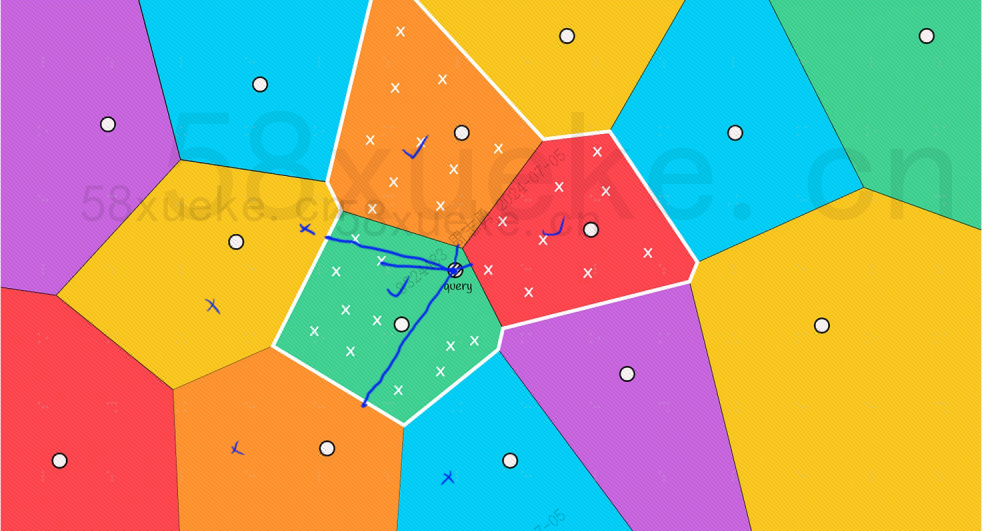
Voici la formule de l'algorithme pour trouver la similarité la plus élevée et la distance la plus proche. La similarité la plus élevée (COS_SIM) est calculée via le cosinus. Il existe deux algorithmes pour la distance la plus proche, l'algorithme européen et l'algorithme de Manhattan. Je ne les expliquerai pas ici. :
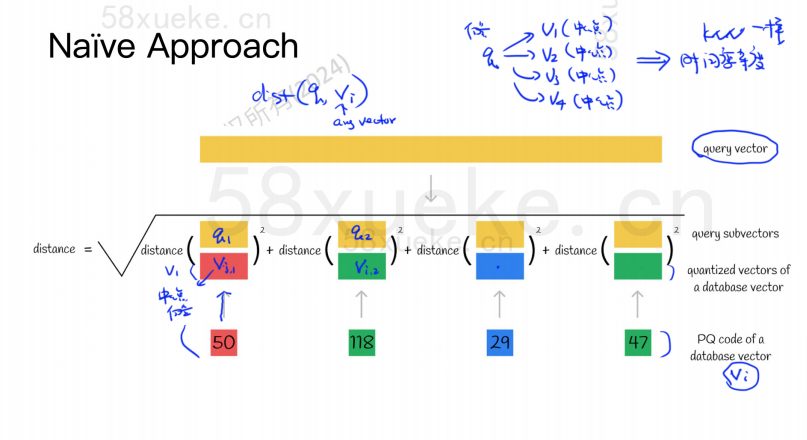
L'algorithme PQ divise d'abord tous les vecteurs en plusieurs sous-espaces, comme le KNN approximatif, chaque sous-espace a un point central (centroïde).
Ensuite, le vecteur de haute dimension d'origine sera divisé en plusieurs sous-vecteurs de vecteur de basse dimension, et le point central le plus proche du sous-vecteur sera utilisé comme ID PQ du sous-vecteur. Ensuite, un vecteur de haute dimension sera utilisé. être composé de plusieurs ID PQ, ce qui compresse considérablement l'espace.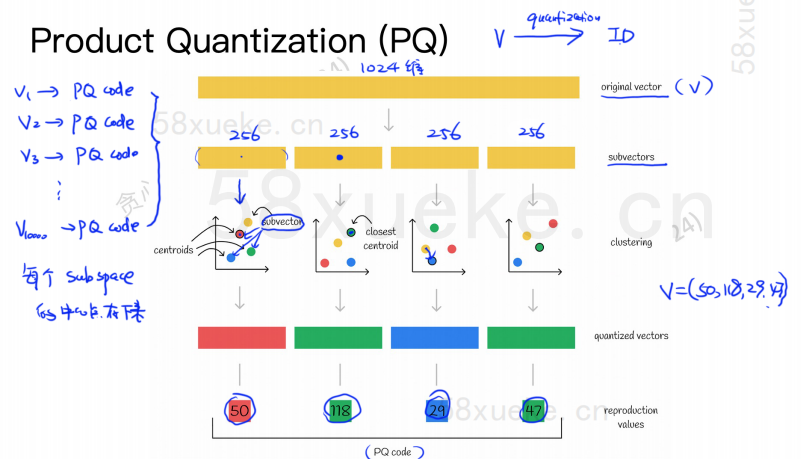
Par exemple, le vecteur à 1 024 dimensions dans la figure ci-dessus est divisé en quatre sous-vecteurs à 256 dimensions, et les points centraux les plus proches de ces quatre sous-vecteurs sont : 50, 118, 29, 47. Par conséquent, le vecteur à 1024 dimensions peut être représenté par V=(50,118,29,47), et son code PQ est également (50,118,29,47).
Par conséquent, la base de données vectorielles utilisant l'algorithme PQ doit enregistrer les informations de tous les points centraux et le code PQ de tous les vecteurs de grande dimension.
Supposons maintenant que nous ayons une instruction de requête qui doit interroger le vecteur présentant la plus grande similarité dans la base de données vectorielles. Comment interroger à l'aide de l'algorithme PQ ?
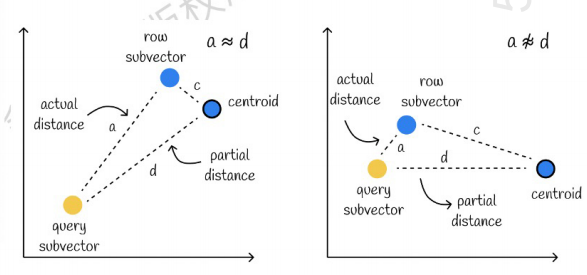
Celui de gauche est un cas où l'erreur est très faible, et celui de droite est un cas où l'erreur est relativement importante. Généralement, il y aura quelques erreurs, mais la plupart des erreurs sont relativement petites.
Utiliser la mise en cache pour accélérer les calculs
Si le vecteur de requête d'origine et le code PQ de chaque sous-vecteur nécessitent un calcul de distance, alors il n'y a pas beaucoup de différence par rapport à l'algorithme KNN approximatif. La complexité spatiale est O(n)*O(k), alors la signification de ceci. l'algorithme c'est quoi ? Est-ce uniquement pour la compression et la réduction de l'espace de stockage ?
Supposons que tous les vecteurs sont divisés en K sous-espaces et qu'il y a n points dans chaque sous-espace. Nous calculons à l'avance la distance entre le point de chaque sous-espace et son point central, la plaçons dans une matrice bidimensionnelle, puis interrogeons le vecteur. correspondance Nous pouvons interroger la distance entre chaque sous-vecteur et le point central directement à partir de la matrice, comme le montre la figure suivante :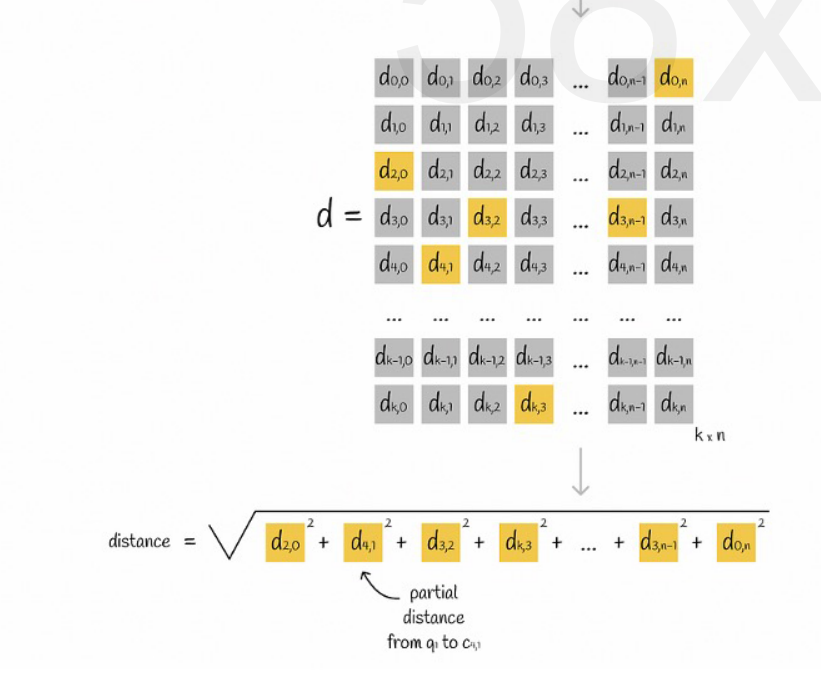
Enfin il suffit d'ajouter les racines carrées des distances de chaque sous-vecteur.
KNN approximatif combiné avec l'algorithme PQ
Ces deux algorithmes n'entrent pas en conflit. Vous pouvez d'abord utiliser un KNN approximatif pour diviser tous les vecteurs en plusieurs sous-espaces, puis localiser le vecteur de requête dans le sous-espace correspondant.
De cette manière, l’algorithme PQ est utilisé dans le sous-espace pour accélérer le calcul.
Dans un ensemble de données vectorielles donné, K vecteurs (K-Nearest Neighbor, KNN) proches du vecteur de requête sont récupérés selon une certaine méthode de mesure. Cependant, en raison du calcul excessif de KNN, nous nous concentrons généralement uniquement sur l'approximation. problème des voisins les plus proches (approximatif le plus proche, ANN).
Lors de la composition d'une image, NSW sélectionne des points au hasard et les ajoute à l'image. Chaque fois qu'un point est ajouté, m points se révèlent être ses voisins les plus proches pour ajouter une arête. La structure finale est formée comme le montre la figure ci-dessous :
Lors de la recherche de cartes NSW, nous partons de points d'entrée prédéfinis. Ce point d'entrée est connecté à plusieurs sommets proches. Nous déterminons lequel de ces sommets est le plus proche de notre vecteur de requête et nous nous y déplaçons.
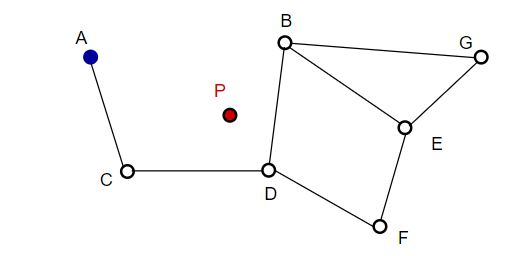
Par exemple, à partir de A, le point C voisin de A est mis à jour plus près de P. Alors le point adjacent D de C est plus proche de P, puis les points adjacents B et F de D ne sont pas plus proches, et le programme s'arrête, ce qui est le point D.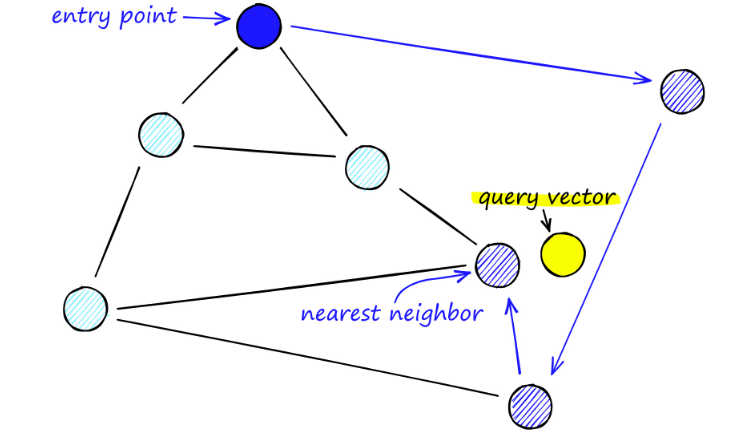
La construction du graphique commence au niveau supérieur. Une fois dans le graphique, l'algorithme parcourt avidement les arêtes pour trouver le voisin ef le plus proche du vecteur q que nous avons inséré - à ce moment ef = 1.
Une fois qu'un minimum local est trouvé, il passe au niveau suivant (comme cela a été fait lors de la recherche). Répétez ce processus jusqu'à ce que nous atteignions la couche d'insertion de notre choix. Ici commence la deuxième phase de construction.
La valeur ef est augmentée jusqu'au paramètre efConstruction que nous avons défini, ce qui signifie que davantage de voisins les plus proches seront renvoyés. Dans un deuxième temps, ces voisins les plus proches sont candidats à des liens vers l’élément q nouvellement inséré et servent de points d’entrée vers la couche suivante.
Après de nombreuses itérations, il reste deux paramètres supplémentaires à prendre en compte lors de l'ajout de liens. M_max, qui définit le nombre maximum de liens qu'un sommet peut avoir, et M_max0, qui définit le nombre maximum de connexions pour un sommet dans la couche 0.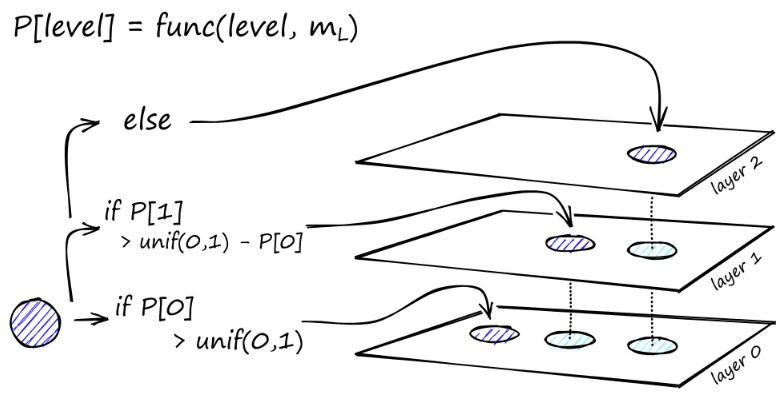
HNSW signifie Hierarchical Navigable Small World, un graphique multicouche. Chaque objet de la base de données est capturé au niveau le plus bas (niveau 0 dans l'image). Ces objets de données sont très bien connectés. Sur chaque couche située au-dessus de la couche la plus basse, moins de points de données sont représentés. Ces points de données correspondent aux couches inférieures, mais il y a exponentiellement moins de points dans chaque couche supérieure. S'il existe une requête de recherche, les points de données les plus proches seront trouvés au niveau supérieur. Dans l’exemple ci-dessous, il ne s’agit que d’un point de données supplémentaire. Ensuite, il va un niveau plus loin et trouve le point de données le plus proche du premier trouvé au niveau le plus élevé et recherche les voisins les plus proches à partir de là. Au niveau le plus profond, l'objet de données réel le plus proche de la requête de recherche sera trouvé.
HNSW est une méthode de recherche de similarité très rapide et efficace en termes de mémoire, car seule la couche la plus élevée (couche supérieure) est enregistrée dans le cache plutôt que tous les points de données de la couche la plus basse. Seuls les points de données les plus proches de la requête de recherche sont chargés après avoir été demandés par les couches supérieures, ce qui signifie que seule une petite quantité de mémoire doit être réservée.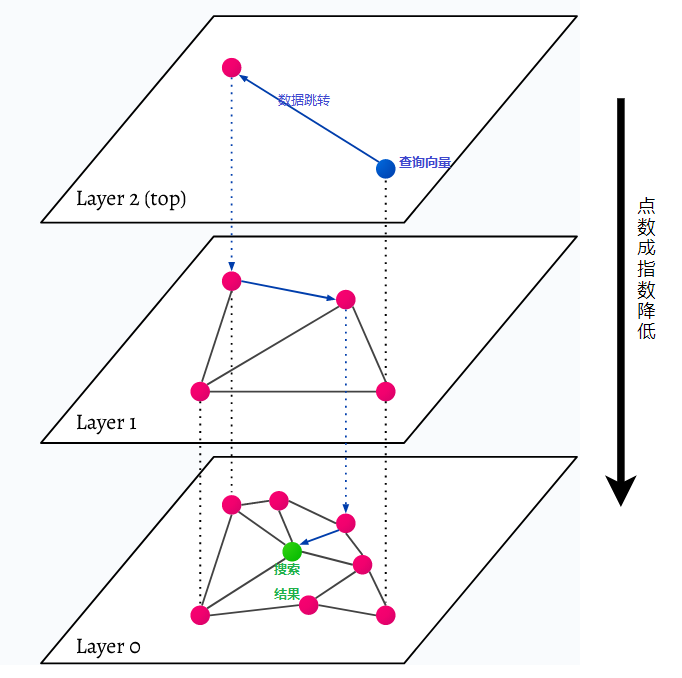

Il se consacre à la recherche technologique depuis plus de 30 ans et maîtrise divers langages tels que java, linux, javascript, php, css, etc. Il a apporté de nombreuses contributions dans le domaine de l'open source. station de documentation pour les développeurs pour partager certains problèmes de développement technologique pour référence future.
