2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Dieser Artikel verwendet den Vektorabrufdienst (DashVector) von Alibaba Cloud in Kombination mit Multimodales ONE-PEACE-Modell Erstellen Sie eine multimodale Echtzeit-Abruffunktion für die „Textsuche nach Bildern“. Der Gesamtprozess ist wie folgt: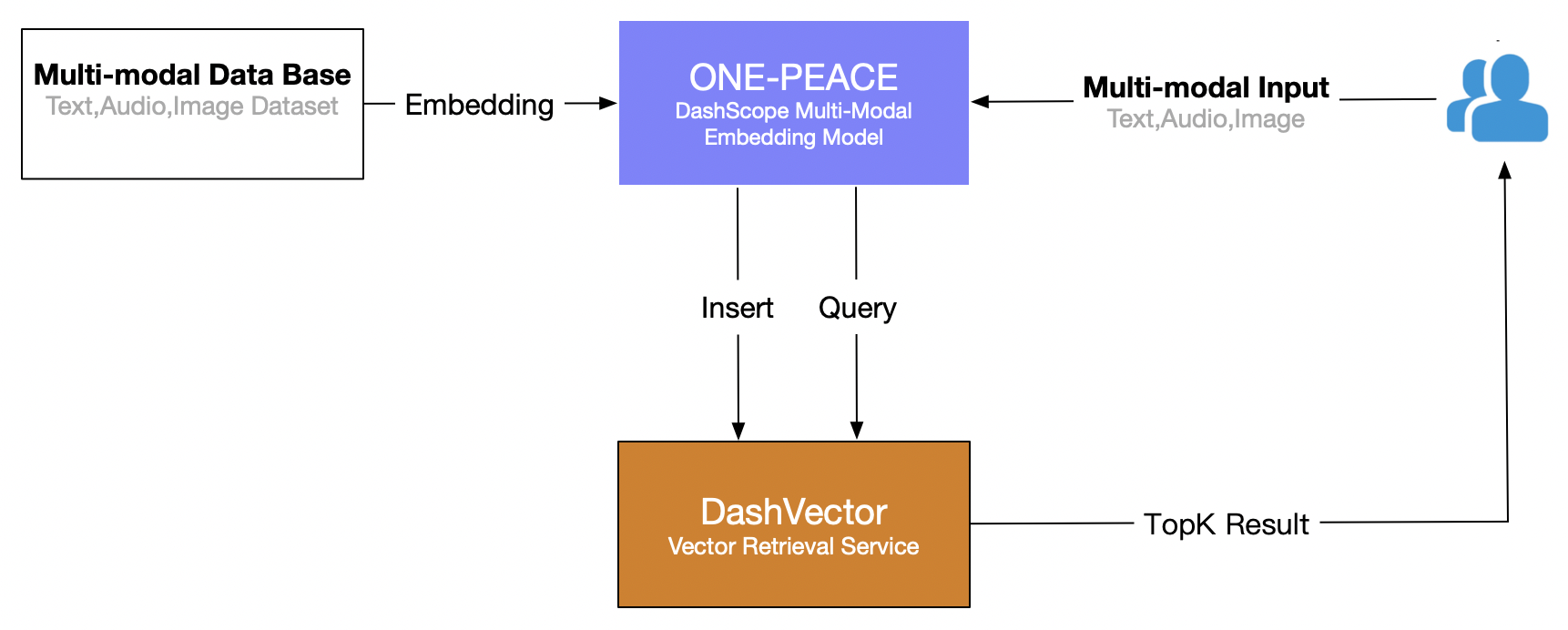
Voraussetzungen
- Öffnen Sie den Lingji-Modelldienst und erhalten Sie den API-KEY:Aktivieren Sie DashScope und erstellen Sie einen API-KEY
- Offener Vektorabrufdienst: sieheAbonnieren Sie einen Dienst。
- API-KEY für den Vektorabrufdienst erstellen: sieheAPI-KEY-Verwaltung。
Umweltvorbereitung
# 安装 dashscope 和 dashvector sdk
pip3 install dashscope dashvector
# 显示图片
pip3 install Pillow
Datenaufbereitung
veranschaulichen
Da der ONE-PEACE-Modelldienst von DashScope derzeit nur Bild- und Audioeingaben in Form von URLs unterstützt, ist es erforderlich, den Datensatz vorab in einen öffentlichen Netzwerkspeicher (z. B. oss/s3) hochzuladen und die entsprechende URL-Adressliste abzurufen Bilder und Audios.
Ich habe das OSS von Alibaba Cloud zum Speichern des Bildes verwendet und die extern zugängliche URL des Bildes über die OSS-Browser-Schnittstelle erhalten: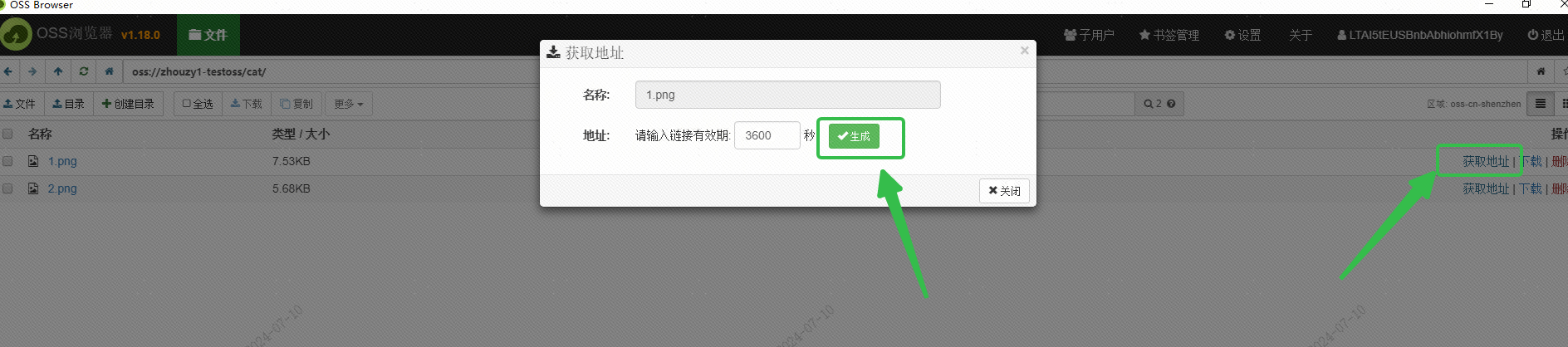
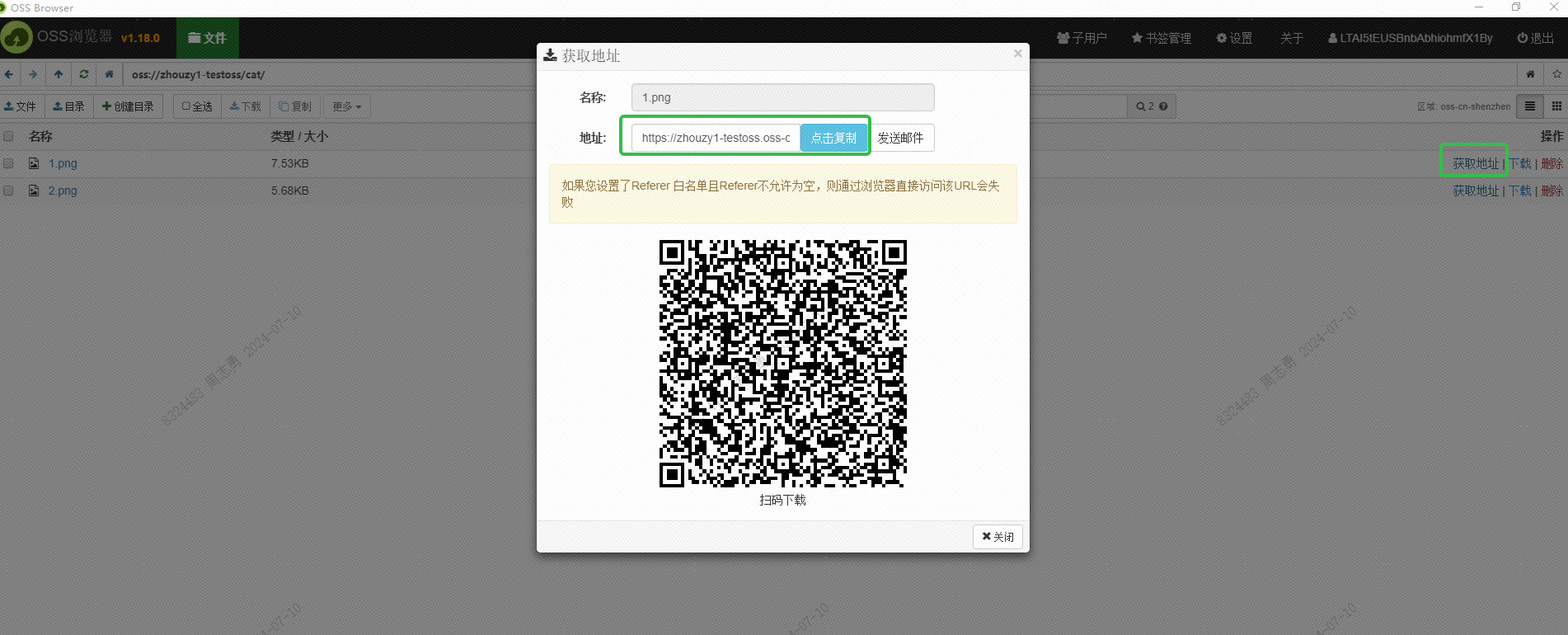
Diese URL sollte auch über die Schnittstelle abgerufen werden. Interessierte Freunde können versuchen, sie stapelweise über die Schnittstelle abzurufen. Der Zweck dieser URL besteht darin, dem DashScope-Dienst das Lesen des Bildes zum Einbetten zu ermöglichen. Speichern Sie in der DashVector-Vektordatenbank.
Nachdem Sie die URL erhalten haben, schreiben Sie die URL in unsere imagenet1k-urls.txt Datei, unser Code liest die Datei zum späteren Einbetten: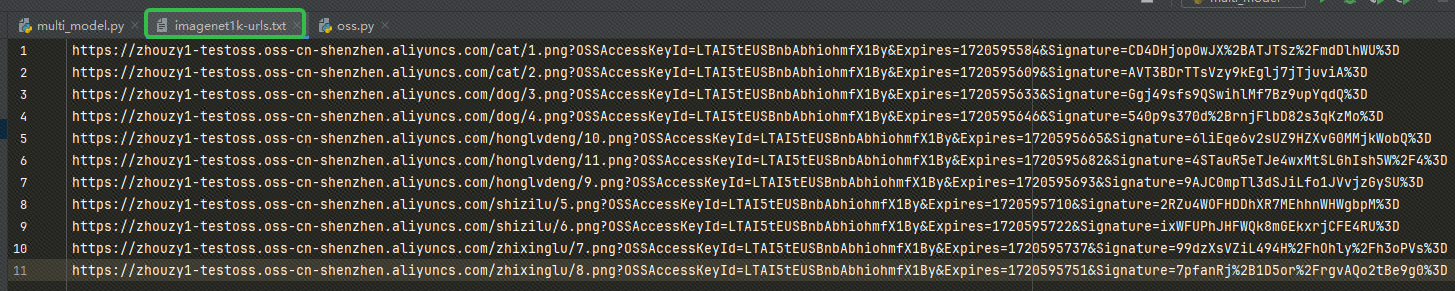
Der Code zum Ausführen der Einbettung lautet wie folgt (den vollständigen Code und die Verzeichnisstruktur werde ich später veröffentlichen, hier wird nur der eingebettete Code veröffentlicht):
def index_image(self):
# 创建集合:指定集合名称和向量维度, ONE-PEACE 模型产生的向量统一为 1536 维
collection = self.vector_client.get(self.vector_collection_name)
if not collection:
rsp = self.vector_client.create(self.vector_collection_name, 1536)
collection = self.vector_client.get(self.vector_collection_name)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# 调用 dashscope ONE-PEACE 模型生成图片 Embedding,并插入 dashvector
with open(self.IMAGENET1K_URLS_FILE_PATH, 'r') as file:
for i, line in enumerate(file):
url = line.strip('n')
input = [{'image': url}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}")
continue
embedding = result.output["embedding"]
collection.insert(
Doc(
id=str(i),
vector=embedding,
fields={'image_url': url}
)
)
if (i + 1) % 100 == 0:
print(f"---- Succeeded to insert {i + 1} image embeddings")
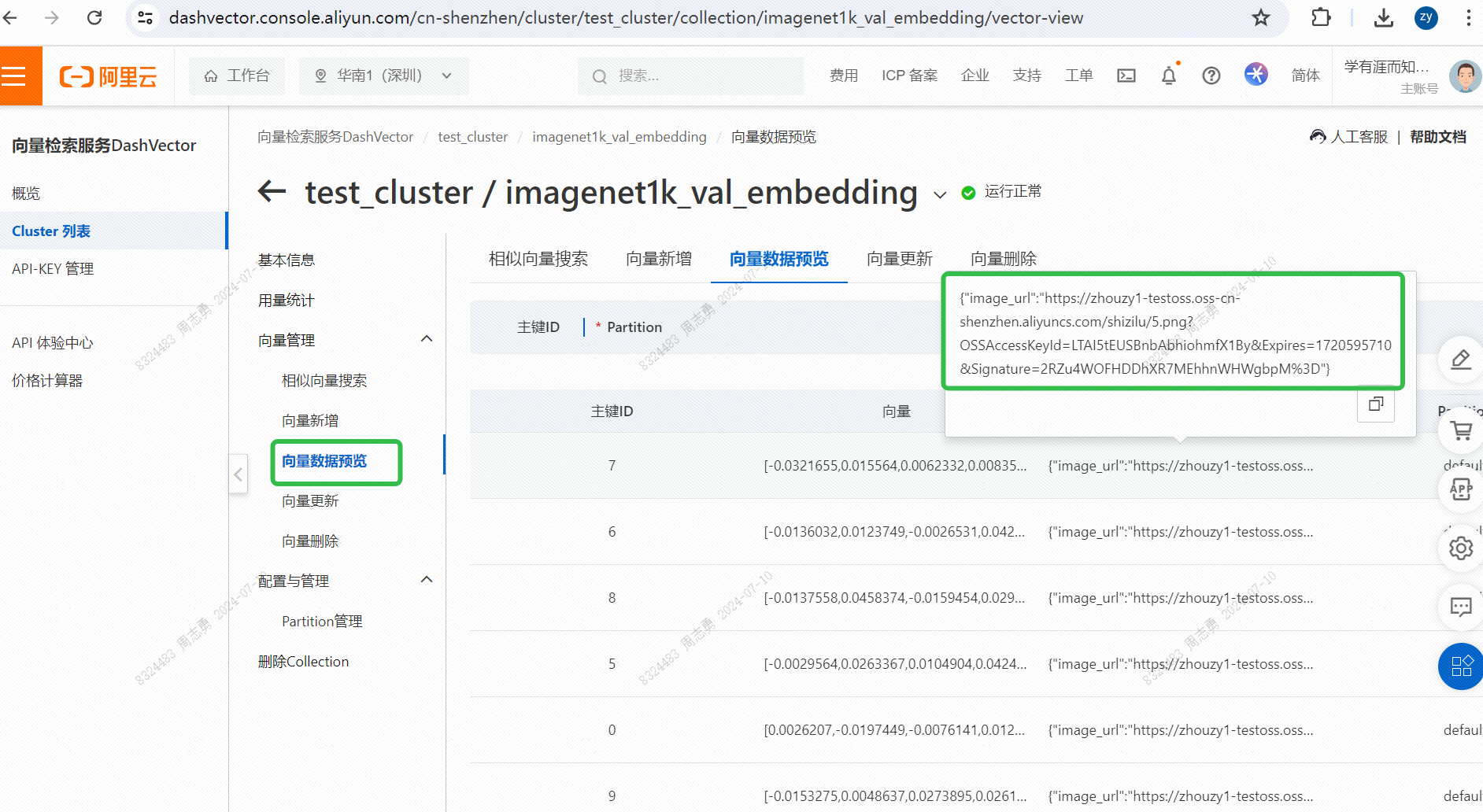
IMAGENET1K_URLS_FILE_PATHGeben Sie die Bild-URL in die URL ein und führen Sie dann eine DashScope-Anfrage aus, um unser Bild zu vektorisieren und zu speichern.Nach der Ausführung können Sie bestehenKonsole für den Vektorabrufdienst, überprüfen Sie die Vektordaten: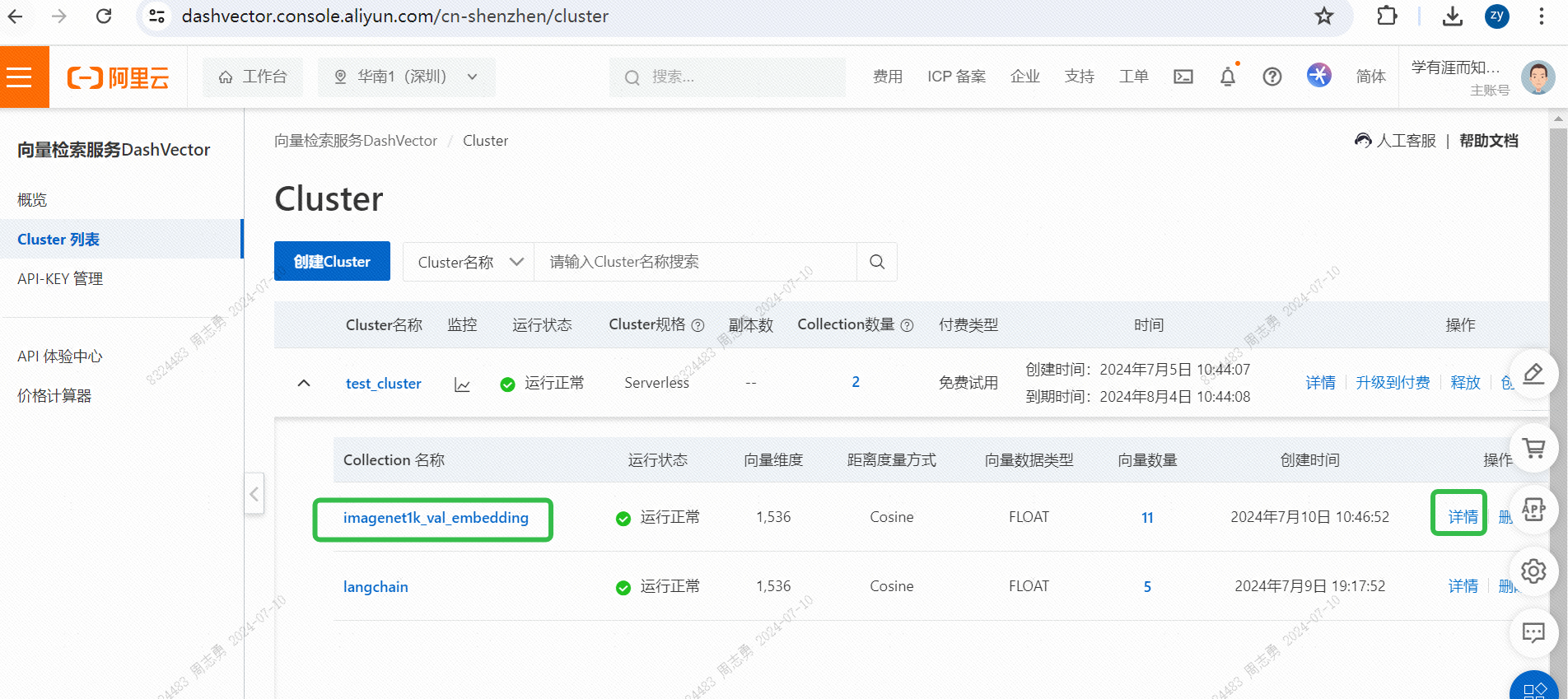
Um Daten aus einer Vektordatenbank per Text abzurufen, gebe ich eincatNachdem Sie drei Bilder abgerufen haben (topk=3 in unserem Code festgelegt), können Sie den Effekt überprüfen. Zwei sind Bilder von Katzen, aber eines ist ein Bild eines Hundes: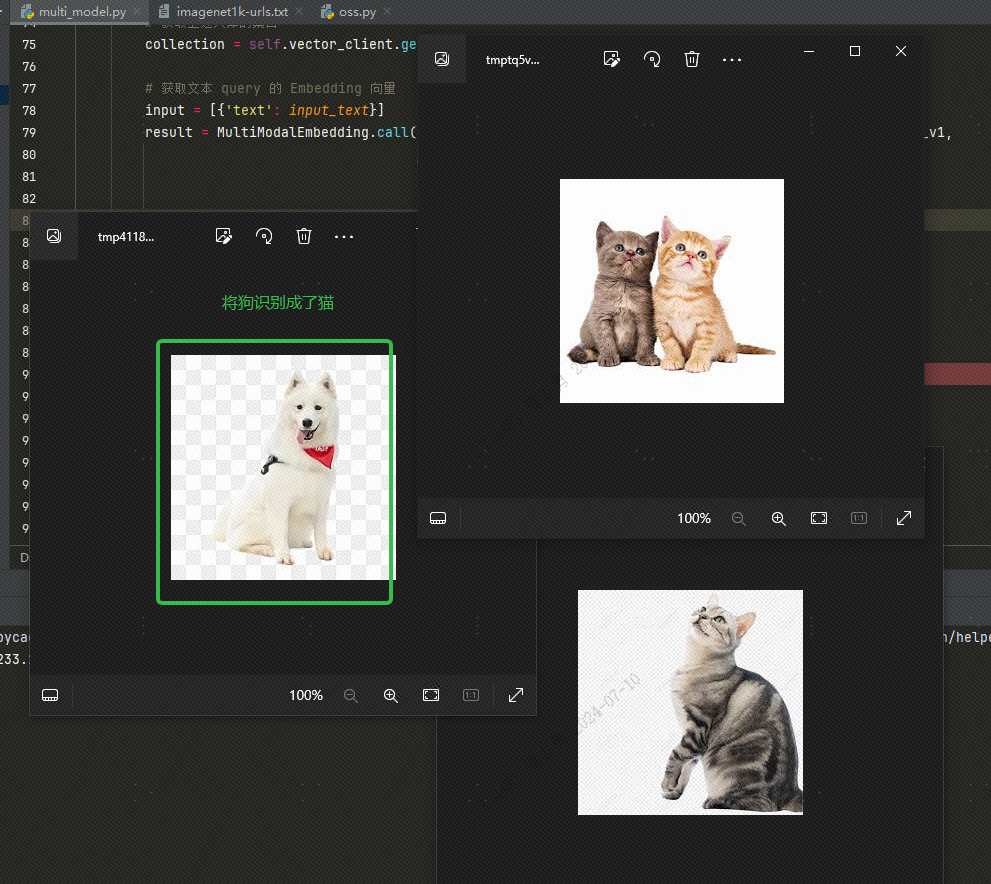
Dies liegt daran, dass es Ähnlichkeiten zwischen Hunden und Katzen gibttopkAuf 2 eingestellt, kann der Hund theoretisch nicht erkannt werden. Schauen wir uns den Effekt an, und tatsächlich gibt es keinen Hund: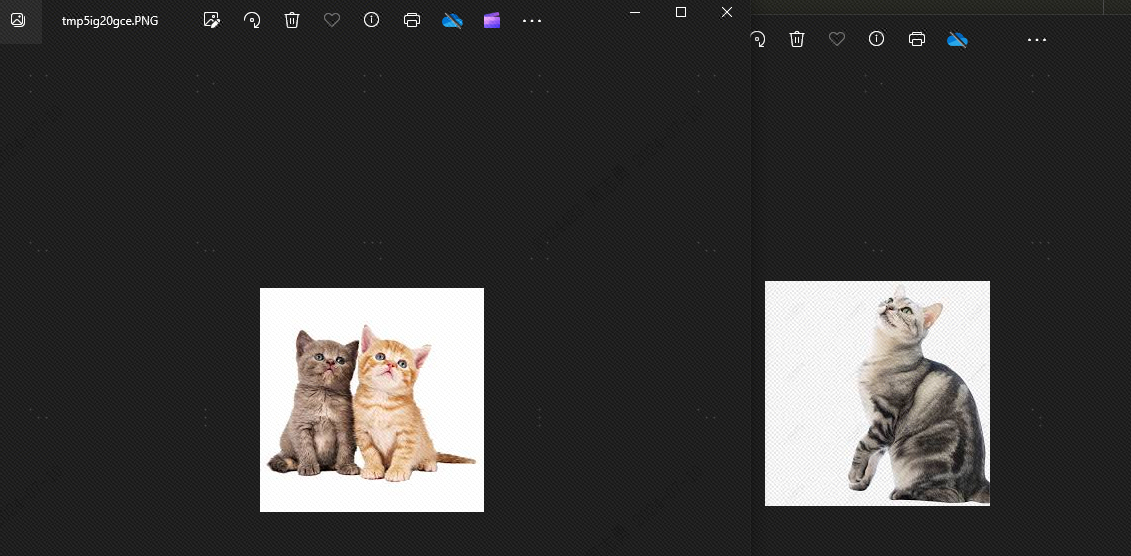
Der Grund, warum Hunde angezeigt werden, ist, dass ich 4 Tierbilder in der Vektorbibliothek gespeichert habe, 2 Katzenbilder und 2 Hundebilder. Wenn unser Topk auf 3 eingestellt ist, wird ein weiteres Hundebild erkannt.
multi_model.pyDie Dateien lauten wie folgt:
import os
import dashscope
from dashvector import Client, Doc, DashVectorException
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
class DashVectorMultiModel:
def __init__(self):
# 我们需要同时开通 DASHSCOPE_API_KEY 和 DASHVECTOR_API_KEY
os.environ["DASHSCOPE_API_KEY"] = ""
os.environ["DASHVECTOR_API_KEY"] = ""
os.environ["DASHVECTOR_ENDPOINT"] = ""
dashscope.api_key = os.environ["DASHSCOPE_API_KEY"]
# 由于 ONE-PEACE 模型服务当前只支持 url 形式的图片、音频输入,因此用户需要将数据集提前上传到
# 公共网络存储(例如 oss/s3),并获取对应图片、音频的 url 列表。
# 该文件每行存储数据集单张图片的公共 url,与当前python脚本位于同目录下
self.IMAGENET1K_URLS_FILE_PATH = "imagenet1k-urls.txt"
self.vector_client = self.init_vector_client()
self.vector_collection_name = 'imagenet1k_val_embedding'
def init_vector_client(self):
return Client(
api_key=os.environ["DASHVECTOR_API_KEY"],
endpoint=os.environ["DASHVECTOR_ENDPOINT"]
)
def index_image(self):
# 创建集合:指定集合名称和向量维度, ONE-PEACE 模型产生的向量统一为 1536 维
collection = self.vector_client.get(self.vector_collection_name)
if not collection:
rsp = self.vector_client.create(self.vector_collection_name, 1536)
collection = self.vector_client.get(self.vector_collection_name)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# 调用 dashscope ONE-PEACE 模型生成图片 Embedding,并插入 dashvector
with open(self.IMAGENET1K_URLS_FILE_PATH, 'r') as file:
for i, line in enumerate(file):
url = line.strip('n')
input = [{'image': url}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}")
continue
embedding = result.output["embedding"]
collection.insert(
Doc(
id=str(i),
vector=embedding,
fields={'image_url': url}
)
)
if (i + 1) % 100 == 0:
print(f"---- Succeeded to insert {i + 1} image embeddings")
def show_image(self, image_list):
for img in image_list:
# 注意:show() 函数在 Linux 服务器上可能需要安装必要的图像浏览器组件才生效
# 建议在支持 jupyter notebook 的服务器上运行该代码
img.show()
def text_search(self, input_text):
# 获取上述入库的集合
collection = self.vector_client.get('imagenet1k_val_embedding')
# 获取文本 query 的 Embedding 向量
input = [{'text': input_text}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
text_vector = result.output["embedding"]
# DashVector 向量检索
rsp = collection.query(text_vector, topk=2)
image_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img = Image.open(urlopen(img_url))
image_list.append(img)
return image_list
if __name__ == '__main__':
a = DashVectorMultiModel()
# 执行 embedding 操作
a.index_image()
# 文本检索
text_query = "Traffic light"
a.show_image(a.text_search(text_query))
DASHSCOPE_API_KEY,DASHVECTOR_API_KEY,DASHVECTOR_ENDPOINTDie Codeverzeichnisstruktur ist wie folgt. Platzieren Sie die TXT-Datei und die Py-Datei im selben Verzeichnis:
Weitere Informationen
Verwenden Sie lokale Bilder: Ich habe das Bild auf OSS hochgeladen. Sie können auch eine lokale Bilddatei verwenden und den Dateipfad in txt wie folgt durch den lokalen Bildpfad ersetzen:
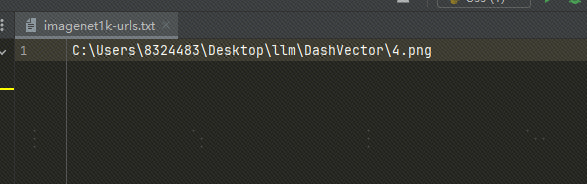
Wenn wir lokale Bilder verwenden, müssen wir den obigen Code ändern und den folgenden Code ändern:
# 将 img = Image.open(urlopen(img_url)) 替换为下边的代码
img = Image.open(img_url)

Er widmet sich seit mehr als 30 Jahren der Technologieforschung und beherrscht verschiedene Sprachen wie Java, Linux, Javascript, PHP, CSS usw. Er hat viele Beiträge im Open-Source-Bereich geleistet Entwicklerdokumentationsstation, um einige Themen in der Technologieentwicklung als zukünftige Referenz zu teilen

