
내 연락처 정보
우편메소피아@프로톤메일.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
이 기사에서는 다음과 결합된 Alibaba Cloud의 벡터 검색 서비스(DashVector)를 사용합니다. ONE-PEACE 다중 모드 모델 , "그림 텍스트 검색"의 실시간 다중 모드 검색 기능을 구축합니다. 전반적인 과정은 다음과 같습니다.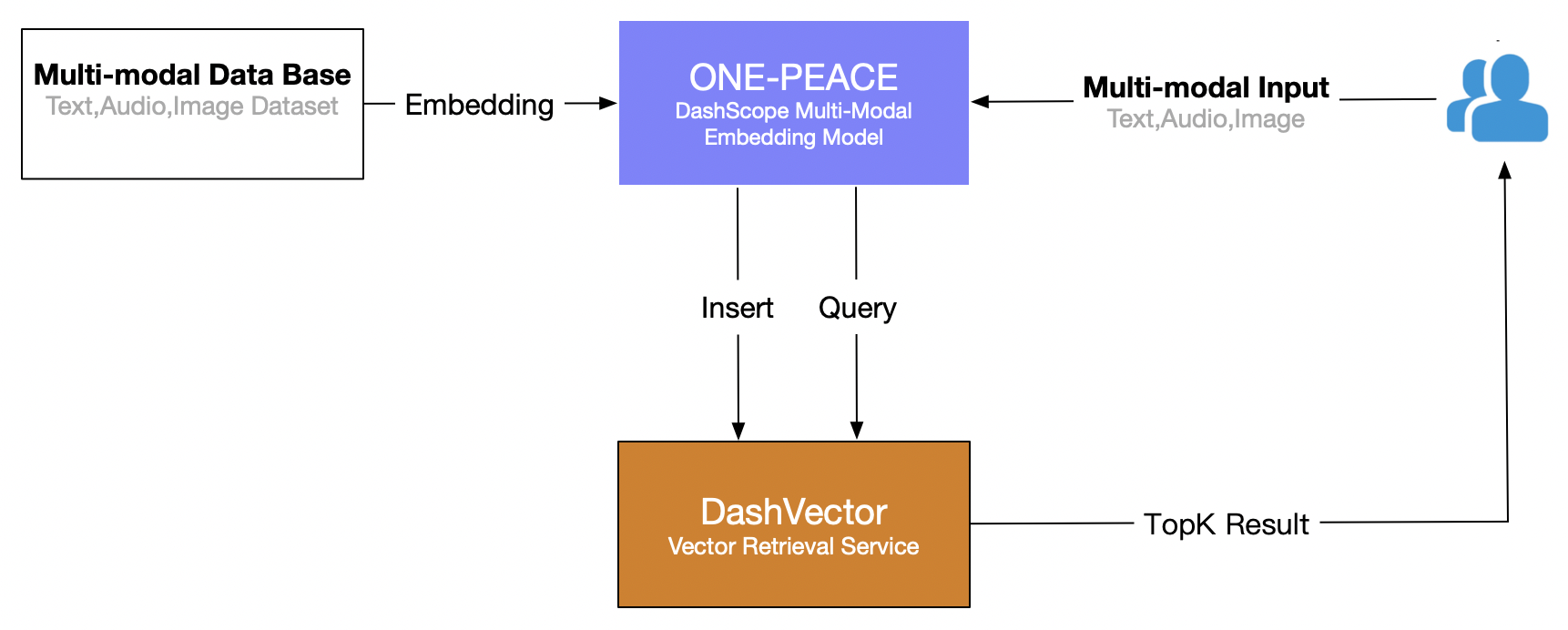
전제조건
- Lingji 모델 서비스를 열고 API-KEY를 얻으세요:DashScope를 활성화하고 API-KEY를 생성하세요
- 공개 벡터 검색 서비스: 참조서비스 구독。
- 벡터 검색 서비스 API-KEY 생성: 참조API-KEY 관리。
환경 준비
# 安装 dashscope 和 dashvector sdk
pip3 install dashscope dashvector
# 显示图片
pip3 install Pillow
데이터 준비
설명하다
DashScope의 ONE-PEACE 모델 서비스는 현재 URL 형식의 이미지 및 오디오 입력만 지원하므로, 미리 공용 네트워크 저장소(oss/s3 등)에 데이터 세트를 업로드하고 해당 모델의 URL 주소 목록을 얻어야 합니다. 이미지와 오디오.
Alibaba Cloud의 OSS를 사용하여 이미지를 저장하고 OSS 브라우저 인터페이스를 통해 외부에서 액세스할 수 있는 이미지 URL을 얻었습니다.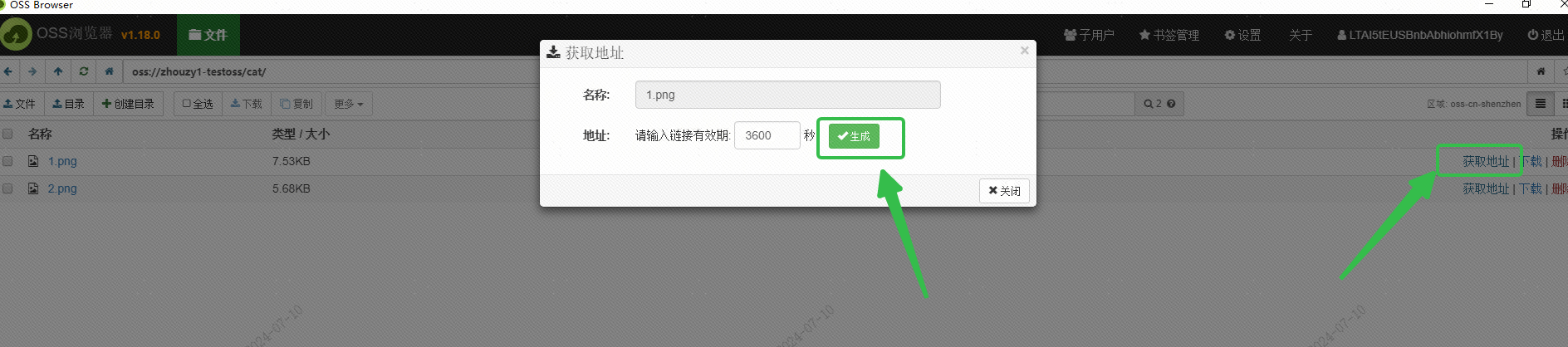
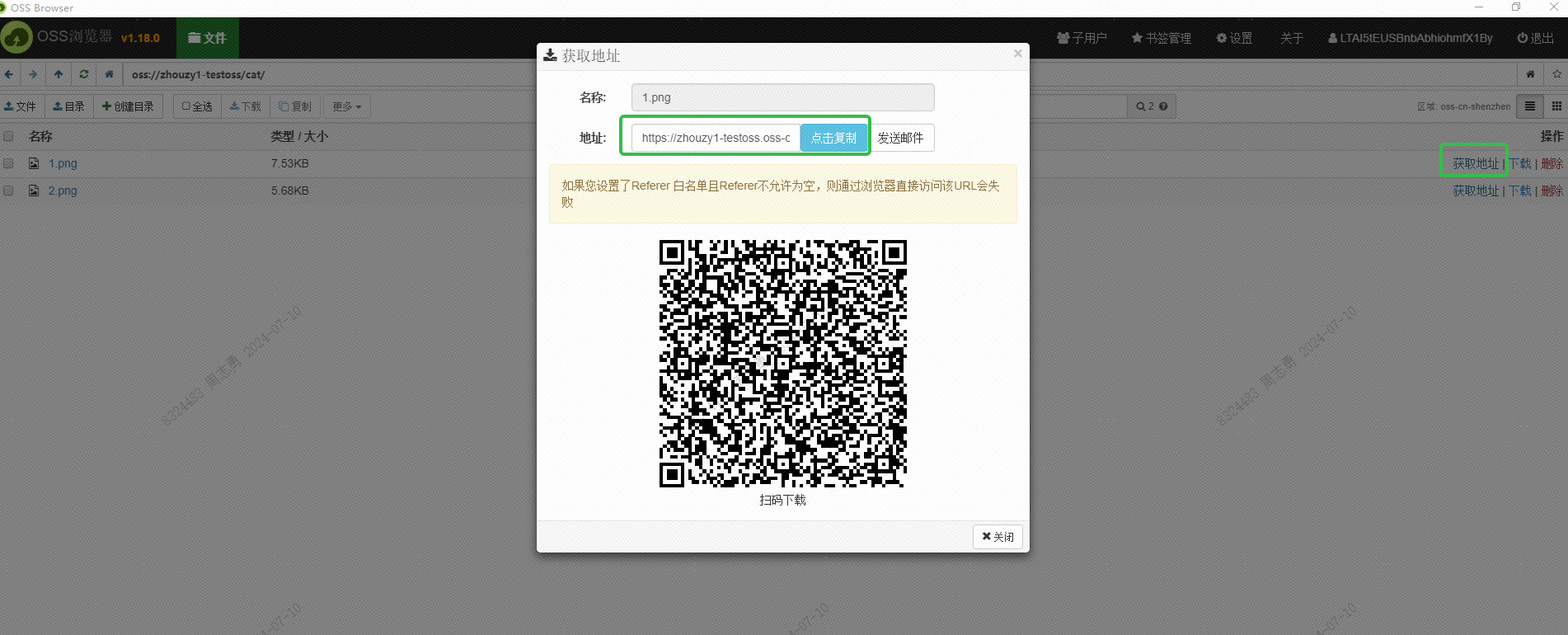
이 URL은 인터페이스를 통해서도 얻어야 합니다. 아직 연구되지 않았습니다. 관심 있는 친구들은 인터페이스를 통해 일괄적으로 얻으려고 시도할 수 있습니다. 이 URL을 얻는 목적은 Alibaba Cloud의 DashScope 서비스가 삽입할 이미지를 읽을 수 있도록 하는 것입니다. DashVector 벡터 데이터베이스에 저장합니다.
URL을 얻은 후 URL을 우리의 imagenet1k-urls.txt 파일이 있으면 코드는 나중에 삽입하기 위해 파일을 읽습니다.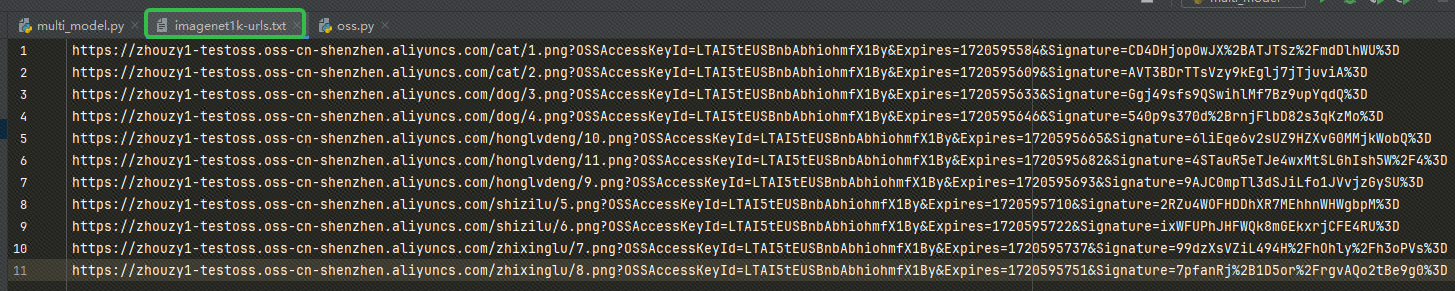
임베딩을 실행하는 코드는 다음과 같습니다(전체 코드와 디렉터리 구조는 나중에 게시할 예정이며 여기에는 임베디드 코드만 게시됩니다).
def index_image(self):
# 创建集合:指定集合名称和向量维度, ONE-PEACE 模型产生的向量统一为 1536 维
collection = self.vector_client.get(self.vector_collection_name)
if not collection:
rsp = self.vector_client.create(self.vector_collection_name, 1536)
collection = self.vector_client.get(self.vector_collection_name)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# 调用 dashscope ONE-PEACE 模型生成图片 Embedding,并插入 dashvector
with open(self.IMAGENET1K_URLS_FILE_PATH, 'r') as file:
for i, line in enumerate(file):
url = line.strip('n')
input = [{'image': url}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}")
continue
embedding = result.output["embedding"]
collection.insert(
Doc(
id=str(i),
vector=embedding,
fields={'image_url': url}
)
)
if (i + 1) % 100 == 0:
print(f"---- Succeeded to insert {i + 1} image embeddings")
IMAGENET1K_URLS_FILE_PATHURL에 이미지 URL을 입력한 다음 DashScope 요청을 수행하여 이미지를 벡터화하고 저장합니다.실행 후 통과 가능벡터 검색 서비스 콘솔, 벡터 데이터를 확인하십시오.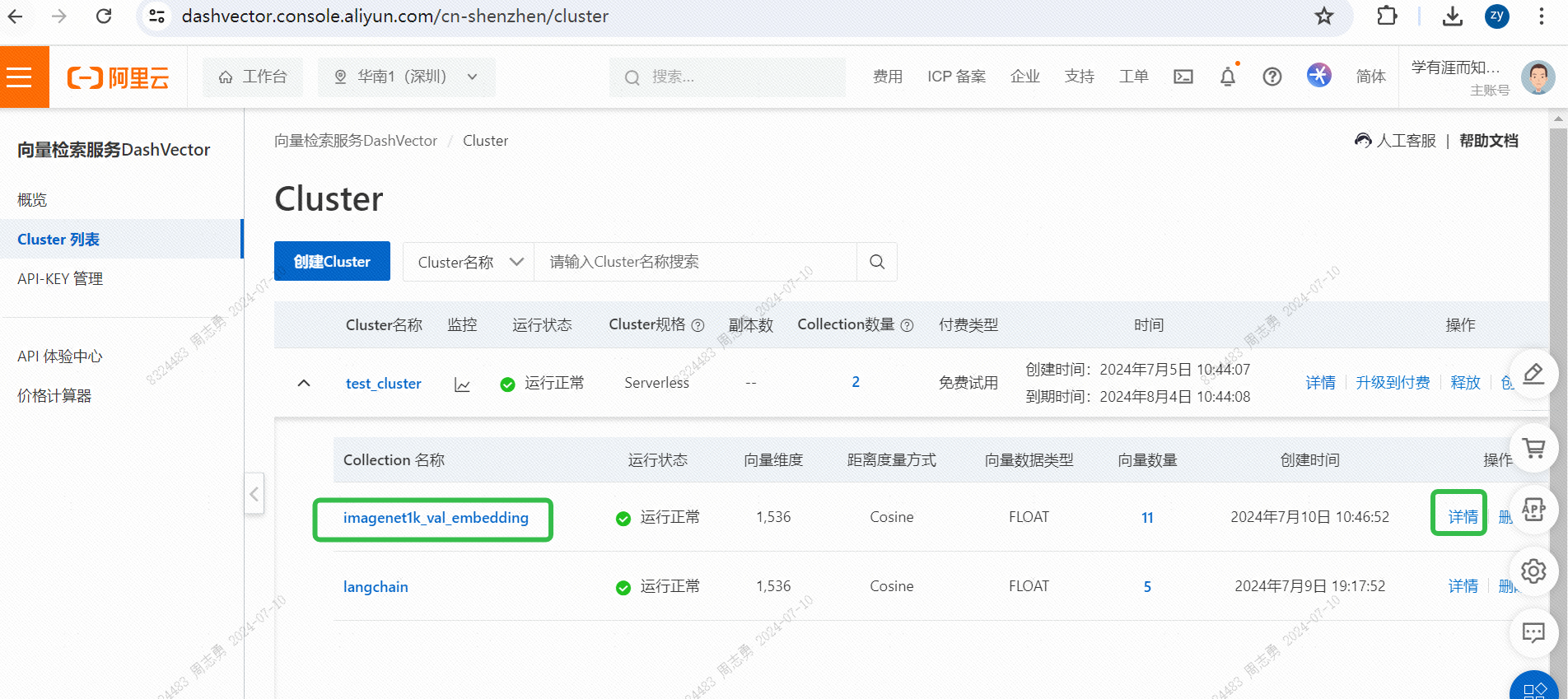
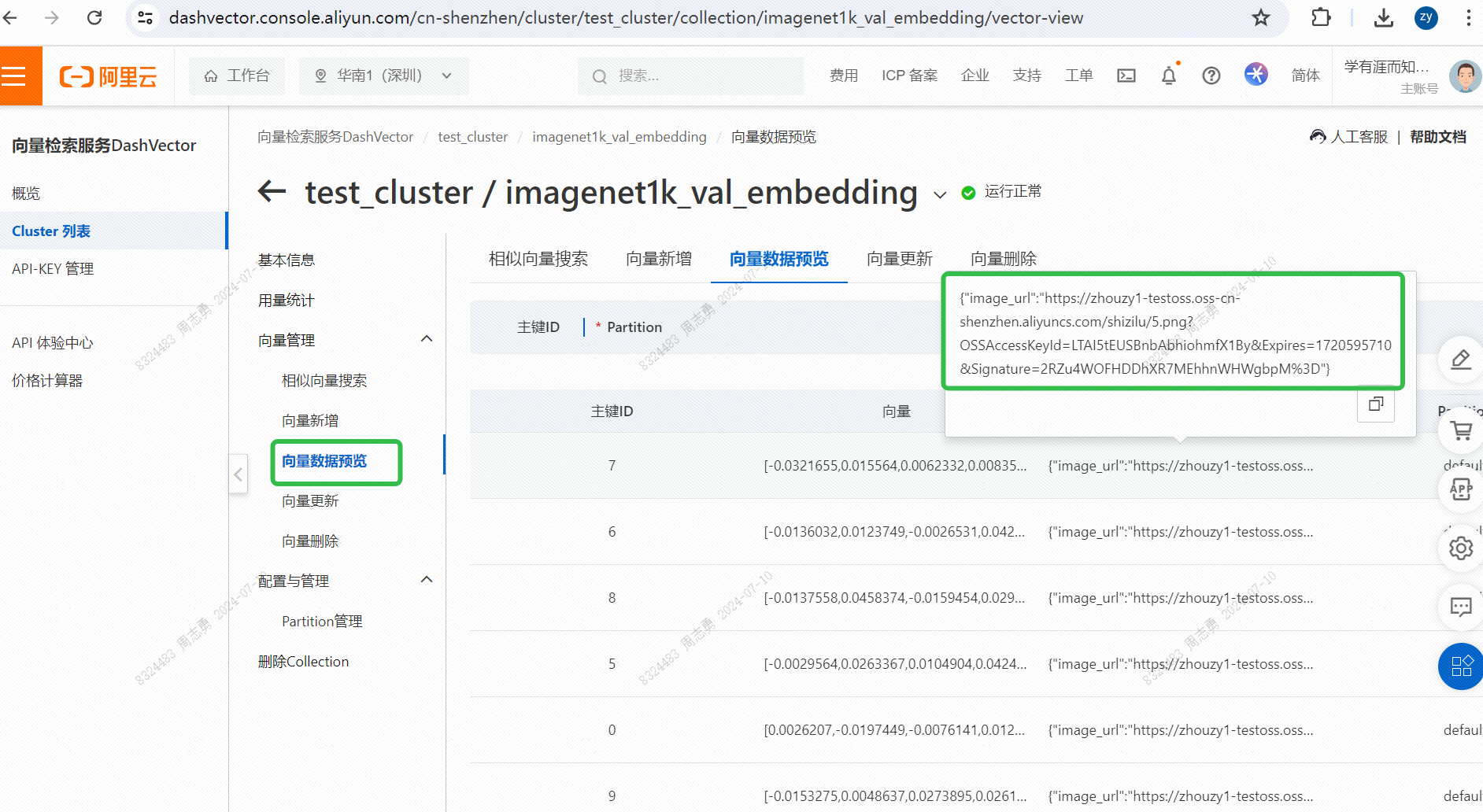
벡터 데이터베이스에서 텍스트로 데이터를 검색하려면 다음을 입력합니다.cat세 장의 사진(코드에서 topk=3으로 설정)을 검색한 후 두 개는 고양이 사진이고 한 개는 강아지 사진인 것을 확인할 수 있습니다.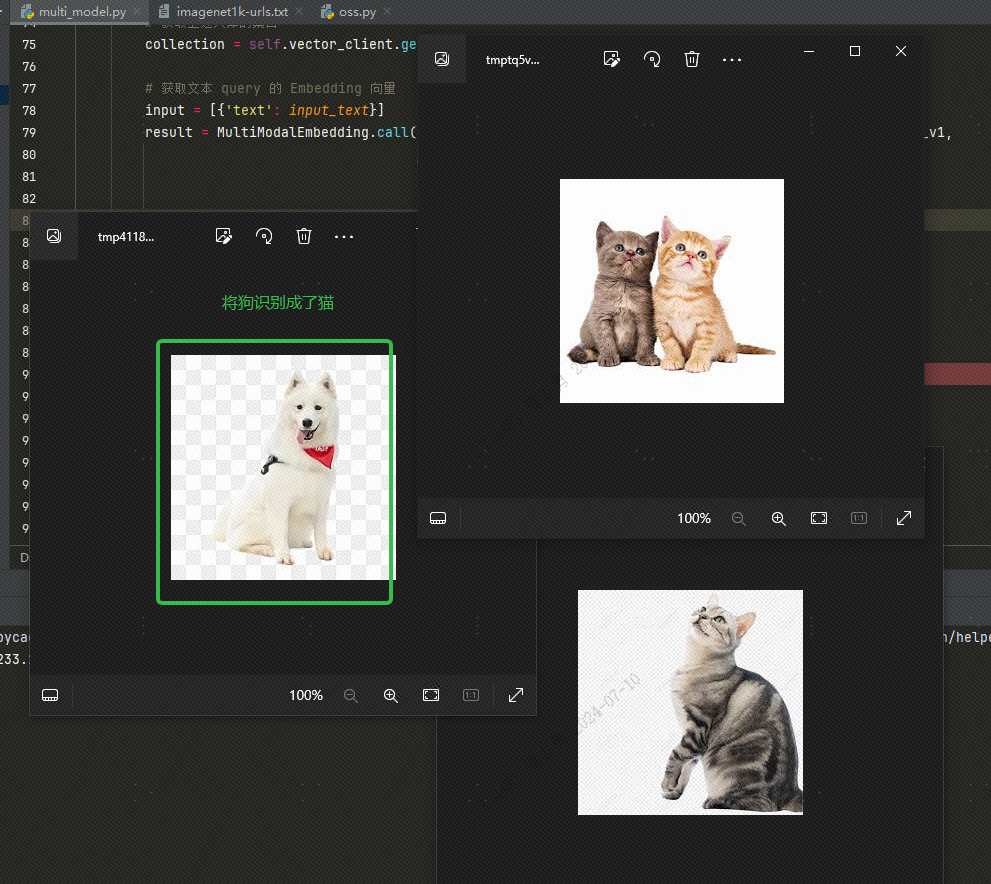
다음으로 개와 고양이 사이에는 유사점이 있기 때문입니다.topk2로 설정하면 이론적으로 개를 감지할 수 없습니다. 효과를 살펴보겠습니다. 확실히 개가 없습니다.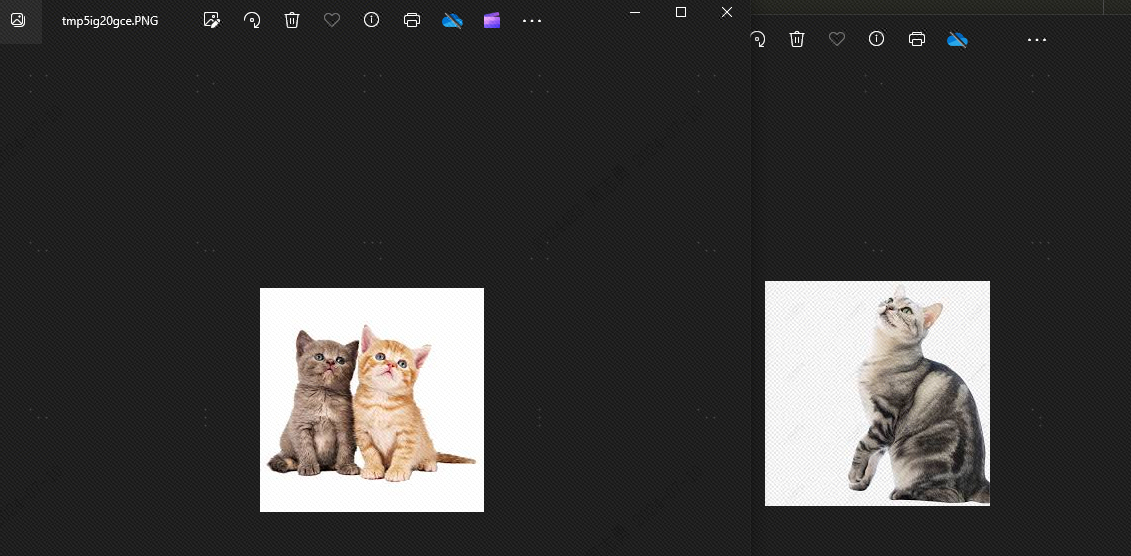
개가 나타나는 이유는 벡터 라이브러리에 동물 사진 4장, 고양이 사진 2장, 개 사진 2장을 저장했기 때문입니다. topk를 3으로 설정하면 개 사진이 한 장 더 검색됩니다.
multi_model.py파일은 다음과 같습니다:
import os
import dashscope
from dashvector import Client, Doc, DashVectorException
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
class DashVectorMultiModel:
def __init__(self):
# 我们需要同时开通 DASHSCOPE_API_KEY 和 DASHVECTOR_API_KEY
os.environ["DASHSCOPE_API_KEY"] = ""
os.environ["DASHVECTOR_API_KEY"] = ""
os.environ["DASHVECTOR_ENDPOINT"] = ""
dashscope.api_key = os.environ["DASHSCOPE_API_KEY"]
# 由于 ONE-PEACE 模型服务当前只支持 url 形式的图片、音频输入,因此用户需要将数据集提前上传到
# 公共网络存储(例如 oss/s3),并获取对应图片、音频的 url 列表。
# 该文件每行存储数据集单张图片的公共 url,与当前python脚本位于同目录下
self.IMAGENET1K_URLS_FILE_PATH = "imagenet1k-urls.txt"
self.vector_client = self.init_vector_client()
self.vector_collection_name = 'imagenet1k_val_embedding'
def init_vector_client(self):
return Client(
api_key=os.environ["DASHVECTOR_API_KEY"],
endpoint=os.environ["DASHVECTOR_ENDPOINT"]
)
def index_image(self):
# 创建集合:指定集合名称和向量维度, ONE-PEACE 模型产生的向量统一为 1536 维
collection = self.vector_client.get(self.vector_collection_name)
if not collection:
rsp = self.vector_client.create(self.vector_collection_name, 1536)
collection = self.vector_client.get(self.vector_collection_name)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# 调用 dashscope ONE-PEACE 模型生成图片 Embedding,并插入 dashvector
with open(self.IMAGENET1K_URLS_FILE_PATH, 'r') as file:
for i, line in enumerate(file):
url = line.strip('n')
input = [{'image': url}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}")
continue
embedding = result.output["embedding"]
collection.insert(
Doc(
id=str(i),
vector=embedding,
fields={'image_url': url}
)
)
if (i + 1) % 100 == 0:
print(f"---- Succeeded to insert {i + 1} image embeddings")
def show_image(self, image_list):
for img in image_list:
# 注意:show() 函数在 Linux 服务器上可能需要安装必要的图像浏览器组件才生效
# 建议在支持 jupyter notebook 的服务器上运行该代码
img.show()
def text_search(self, input_text):
# 获取上述入库的集合
collection = self.vector_client.get('imagenet1k_val_embedding')
# 获取文本 query 的 Embedding 向量
input = [{'text': input_text}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
text_vector = result.output["embedding"]
# DashVector 向量检索
rsp = collection.query(text_vector, topk=2)
image_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img = Image.open(urlopen(img_url))
image_list.append(img)
return image_list
if __name__ == '__main__':
a = DashVectorMultiModel()
# 执行 embedding 操作
a.index_image()
# 文本检索
text_query = "Traffic light"
a.show_image(a.text_search(text_query))
DASHSCOPE_API_KEY,DASHVECTOR_API_KEY,DASHVECTOR_ENDPOINT코드 디렉터리 구조는 다음과 같습니다. txt 파일과 py 파일을 동일한 디렉터리에 배치합니다.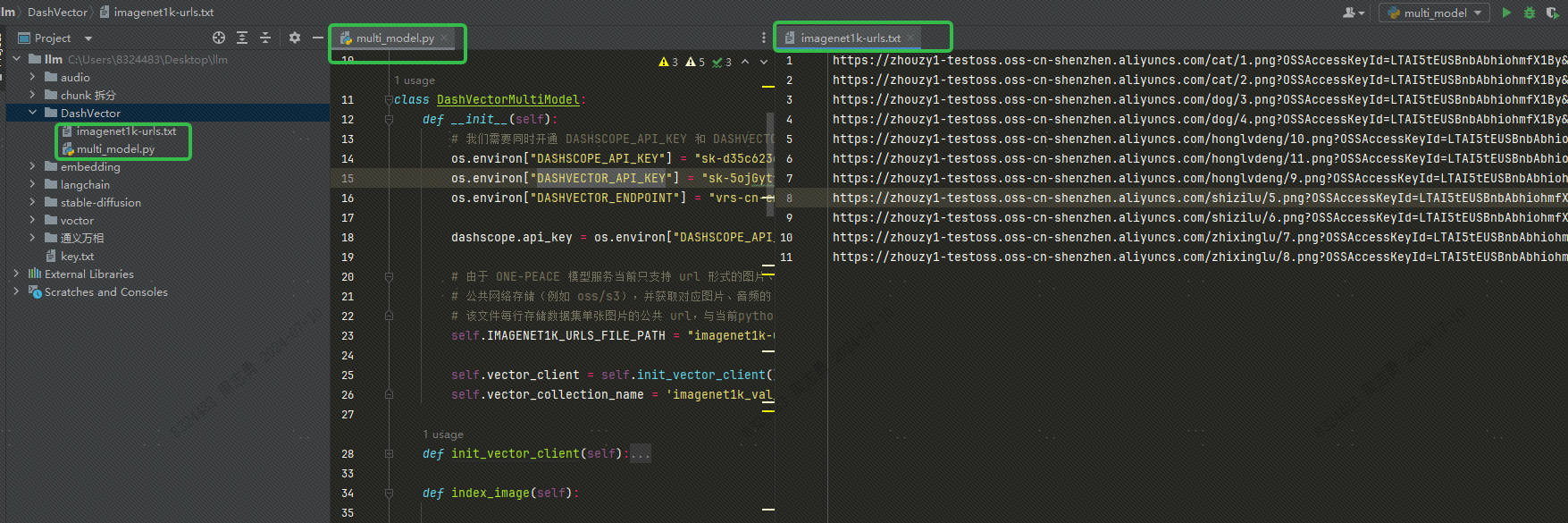
추가 정보
로컬 이미지 사용: 이미지를 OSS에 업로드했습니다. 다음과 같이 로컬 이미지 파일을 사용하고 txt의 파일 경로를 로컬 이미지 경로로 바꿀 수도 있습니다.
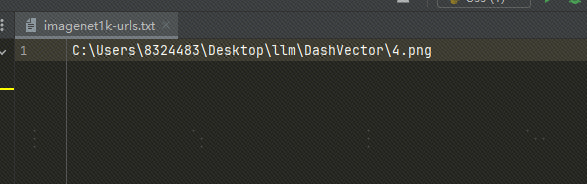
로컬 이미지를 사용하는 경우 위 코드와 아래 코드를 수정해야 합니다.
# 将 img = Image.open(urlopen(img_url)) 替换为下边的代码
img = Image.open(img_url)

그는 30년 이상 기술 연구에 전념해 왔으며, java, linux, javascript, php, css 등 다양한 언어에 능숙하며, 오픈 소스 분야에 많은 공헌을 했습니다. 나중에 참조할 수 있도록 기술 개발의 일부 문제를 공유하는 개발자 문서 스테이션입니다.

우편메소피아@프로톤메일.com