
τα στοιχεία επικοινωνίας μου
Ταχυδρομείο[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Αυτό το άρθρο χρησιμοποιεί την υπηρεσία ανάκτησης διανυσμάτων του Alibaba Cloud (DashVector), σε συνδυασμό με Πολυτροπικό μοντέλο ONE-PEACE , για τη δημιουργία πολυτροπικών δυνατοτήτων ανάκτησης σε πραγματικό χρόνο της «αναζήτησης κειμένου για εικόνες». Η συνολική διαδικασία έχει ως εξής: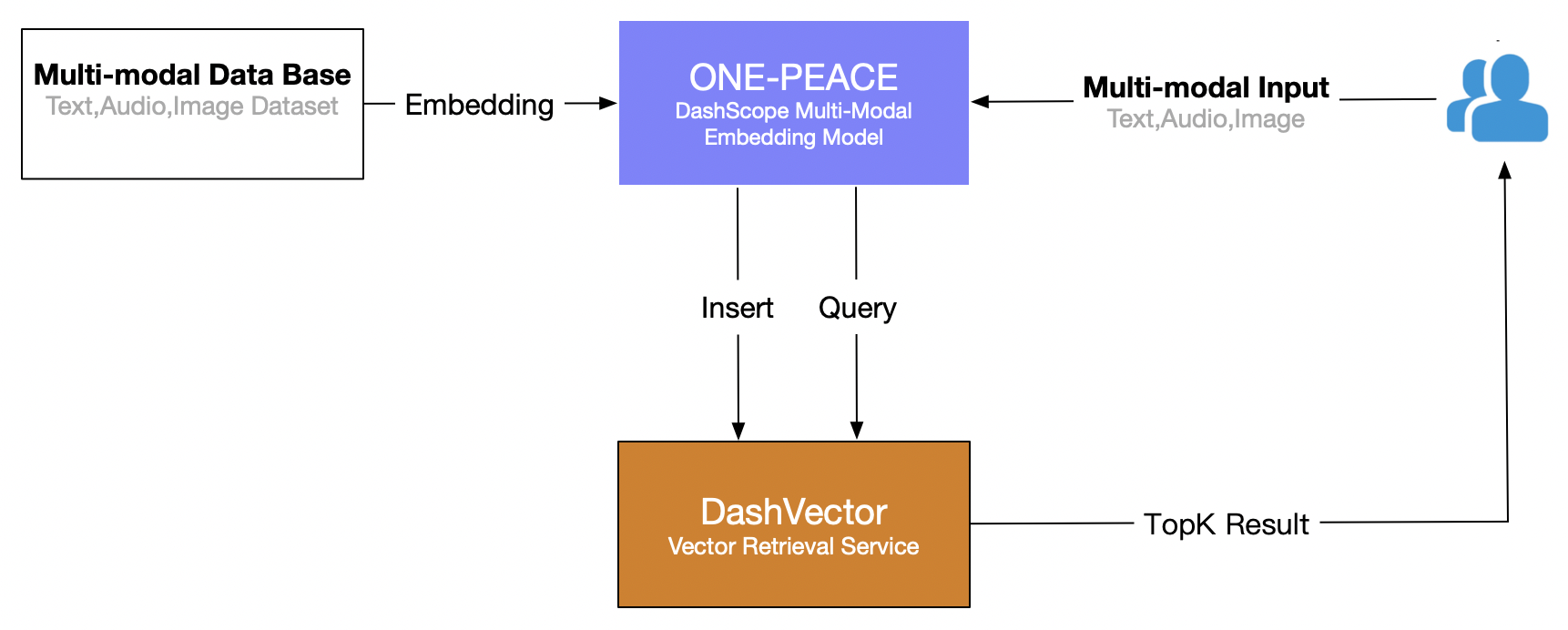
Προαπαιτούμενα
- Ανοίξτε την υπηρεσία μοντέλου Lingji και αποκτήστε το API-KEY:Ενεργοποιήστε το DashScope και δημιουργήστε το API-KEY
- Ανοιχτή υπηρεσία ανάκτησης διανυσμάτων: βλΕγγραφείτε σε μια υπηρεσία。
- Δημιουργία υπηρεσίας ανάκτησης διανυσμάτων API-KEY: βλΔιαχείριση API-KEY。
Περιβαλλοντική προετοιμασία
# 安装 dashscope 和 dashvector sdk
pip3 install dashscope dashvector
# 显示图片
pip3 install Pillow
προετοιμασία δεδομένων
εικονογραφώ
Δεδομένου ότι η υπηρεσία μοντέλου ONE-PEACE του DashScope προς το παρόν υποστηρίζει μόνο είσοδο εικόνας και ήχου με τη μορφή URL, είναι απαραίτητο να ανεβάσετε το σύνολο δεδομένων σε δημόσιο χώρο αποθήκευσης δικτύου (όπως oss/s3) εκ των προτέρων και να αποκτήσετε τη λίστα διευθύνσεων URL της αντίστοιχης εικόνες και ήχους.
Χρησιμοποίησα το OSS του Alibaba Cloud για να αποθηκεύσω την εικόνα και έλαβα την εξωτερικά προσβάσιμη διεύθυνση URL της εικόνας μέσω της διεπαφής του προγράμματος περιήγησης OSS: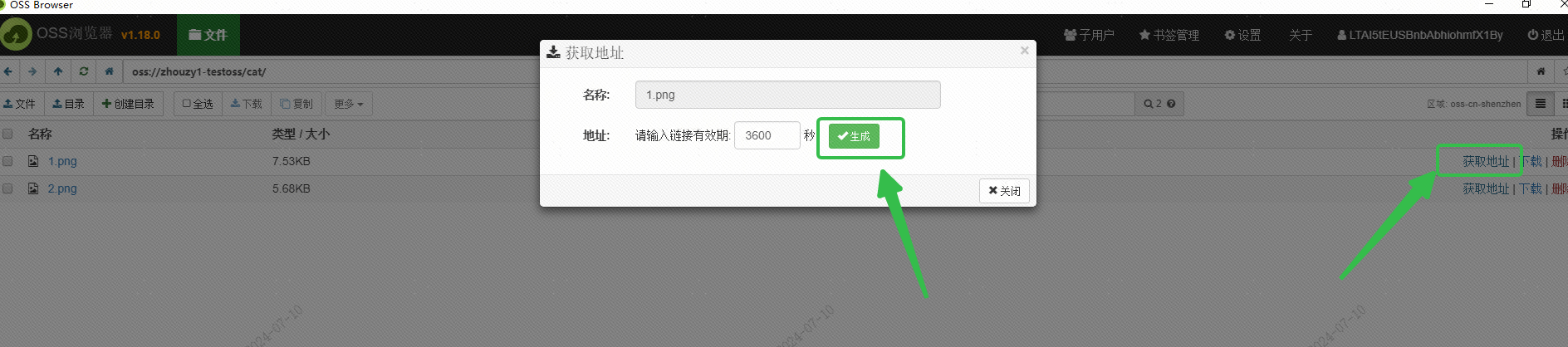
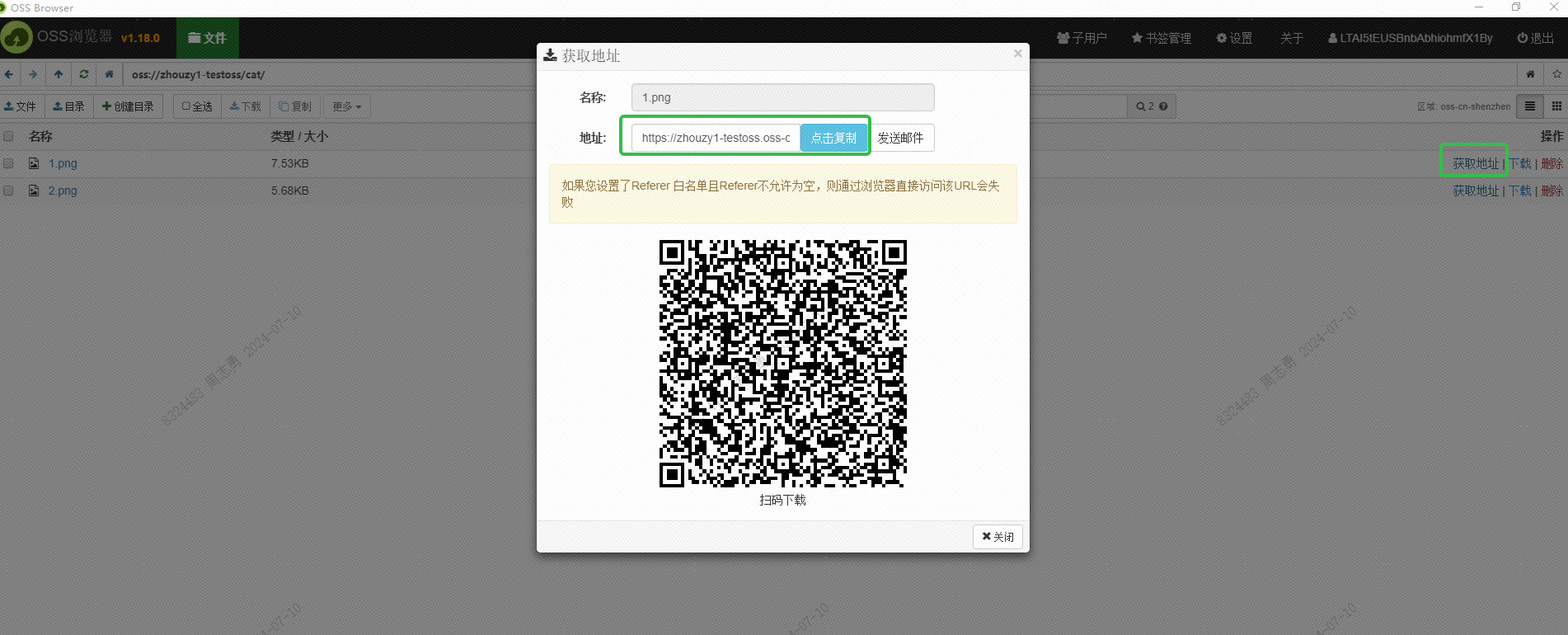
Αυτή η διεύθυνση URL θα πρέπει επίσης να ληφθεί μέσω της διεπαφής. Αυτό δεν έχει μελετηθεί ακόμη. Αποθήκευση στη διανυσματική βάση δεδομένων DashVector.
Αφού λάβετε τη διεύθυνση URL, γράψτε τη διεύθυνση URL στο δικό μας imagenet1k-urls.txt αρχείο, ο κώδικάς μας θα διαβάσει το αρχείο για ενσωμάτωση αργότερα: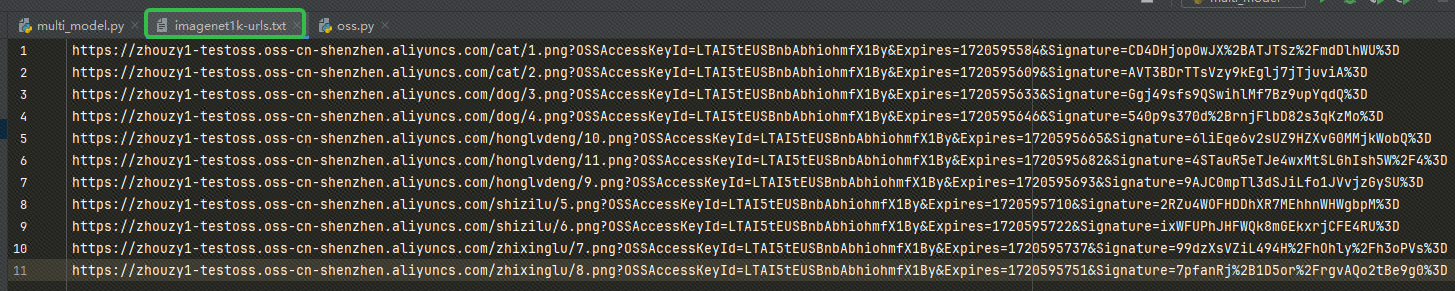
Ο κώδικας για την εκτέλεση της ενσωμάτωσης είναι ο εξής (θα δημοσιεύσω τον πλήρη κώδικα και τη δομή καταλόγου αργότερα, μόνο ο ενσωματωμένος κώδικας δημοσιεύεται εδώ):
def index_image(self):
# 创建集合:指定集合名称和向量维度, ONE-PEACE 模型产生的向量统一为 1536 维
collection = self.vector_client.get(self.vector_collection_name)
if not collection:
rsp = self.vector_client.create(self.vector_collection_name, 1536)
collection = self.vector_client.get(self.vector_collection_name)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# 调用 dashscope ONE-PEACE 模型生成图片 Embedding,并插入 dashvector
with open(self.IMAGENET1K_URLS_FILE_PATH, 'r') as file:
for i, line in enumerate(file):
url = line.strip('n')
input = [{'image': url}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}")
continue
embedding = result.output["embedding"]
collection.insert(
Doc(
id=str(i),
vector=embedding,
fields={'image_url': url}
)
)
if (i + 1) % 100 == 0:
print(f"---- Succeeded to insert {i + 1} image embeddings")
IMAGENET1K_URLS_FILE_PATHΤο URL της εικόνας στη διεύθυνση URL και, στη συνέχεια, εκτελέστε ένα αίτημα DashScope για διανυσματική και αποθήκευση της εικόνας μας.Μετά την εκτέλεση, μπορείτε να περάσετεΔιανυσματική κονσόλα υπηρεσίας ανάκτησης, ελέγξτε τα διανυσματικά δεδομένα: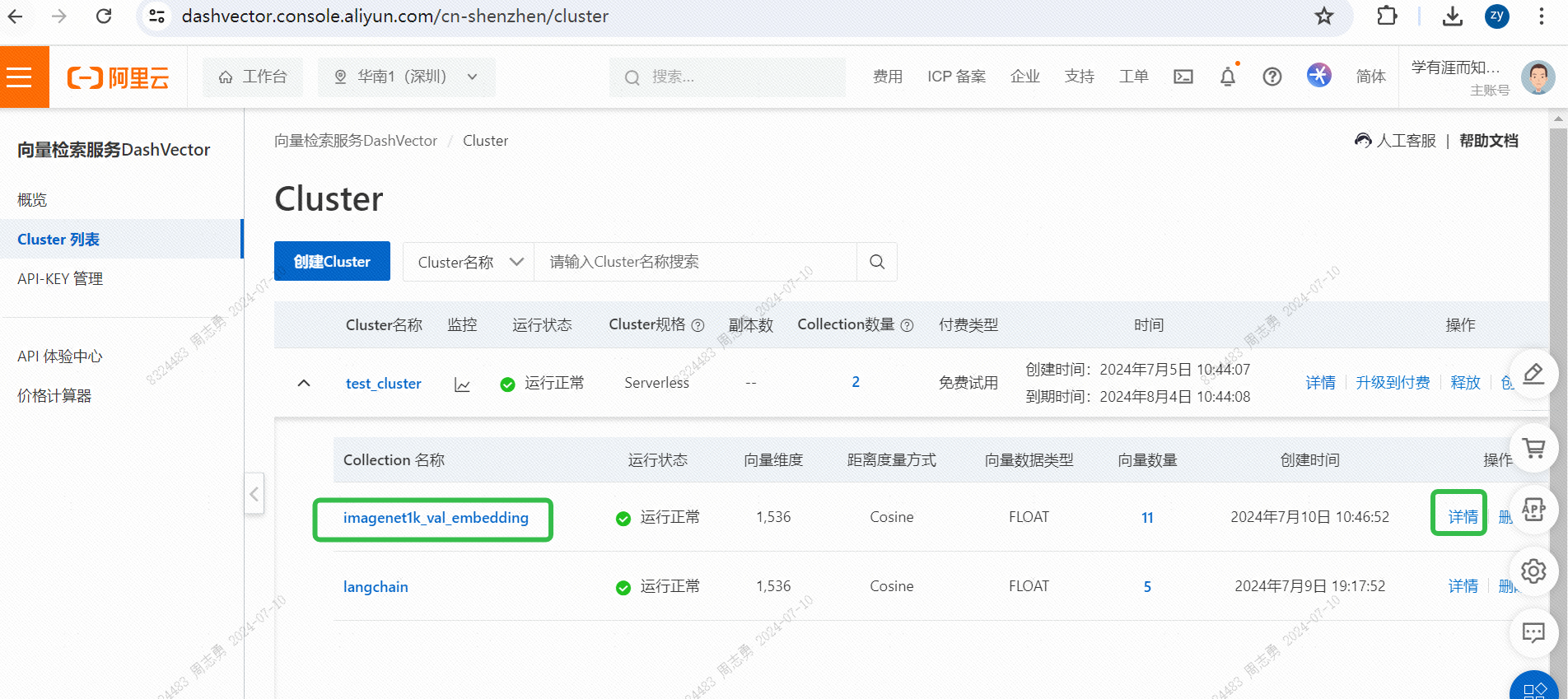
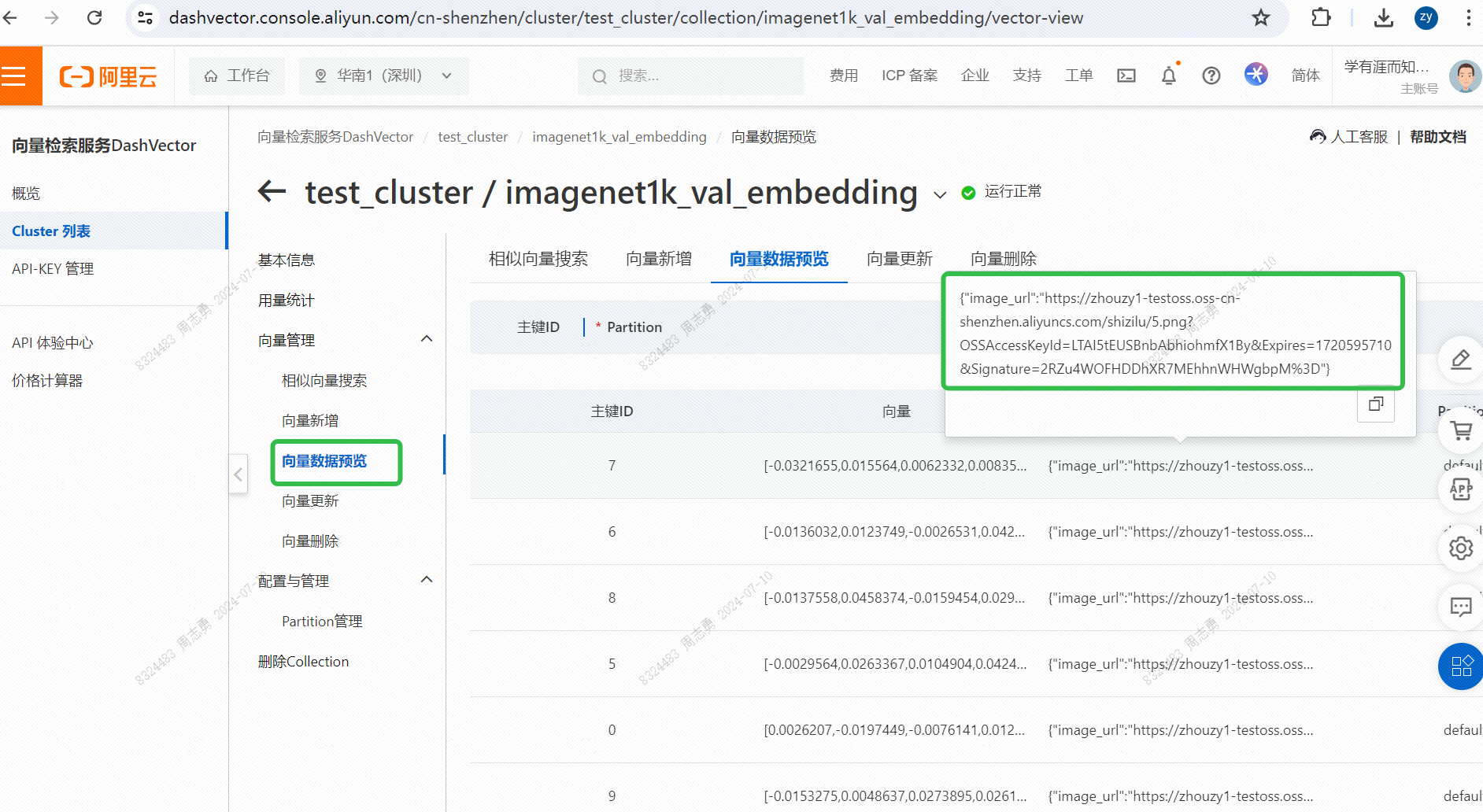
Για να ανακτήσω δεδομένα από μια διανυσματική βάση δεδομένων με κείμενο, εισάγωcatΜετά την ανάκτηση τριών εικόνων (topk=3 σετ στον κώδικά μας), μπορείτε να ελέγξετε το αποτέλεσμα δύο είναι εικόνες γατών, αλλά η μία είναι μια εικόνα ενός σκύλου: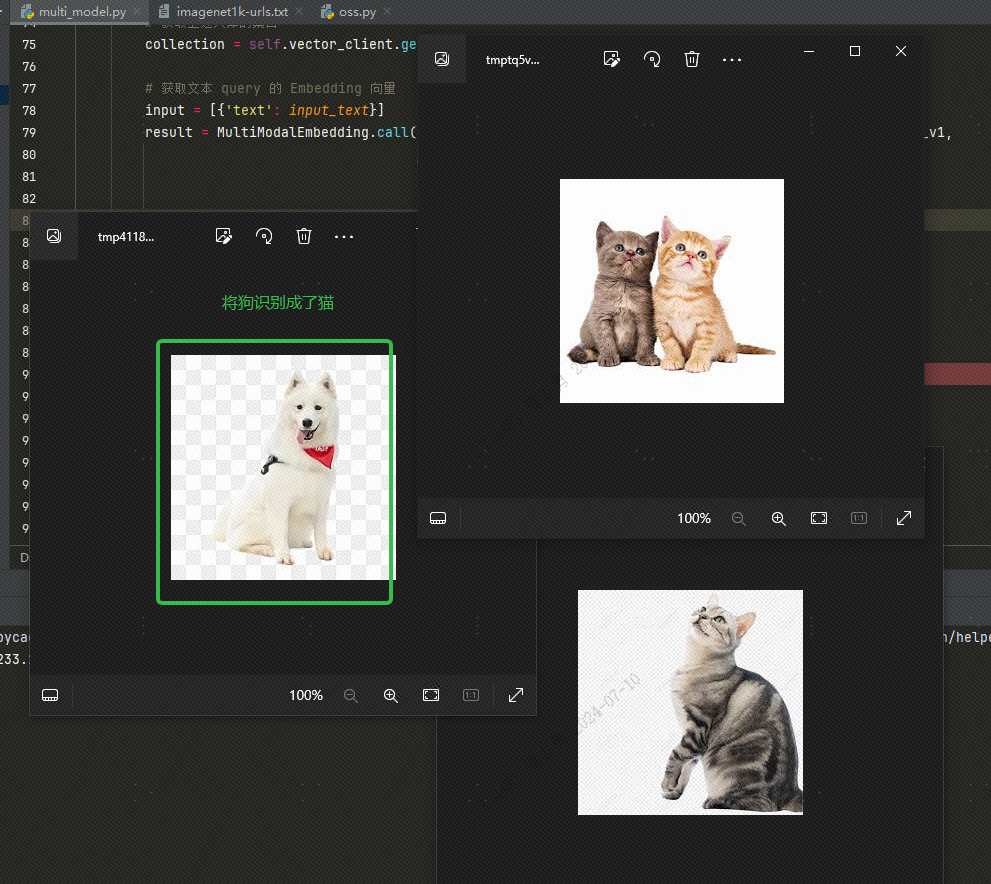
Αυτό συμβαίνει γιατί υπάρχουν ομοιότητες μεταξύ σκύλων και γατώνtopkΟρίστε στο 2, θεωρητικά ο σκύλος δεν μπορεί να ανιχνευθεί, ας δούμε το αποτέλεσμα, και σίγουρα δεν υπάρχει σκύλος.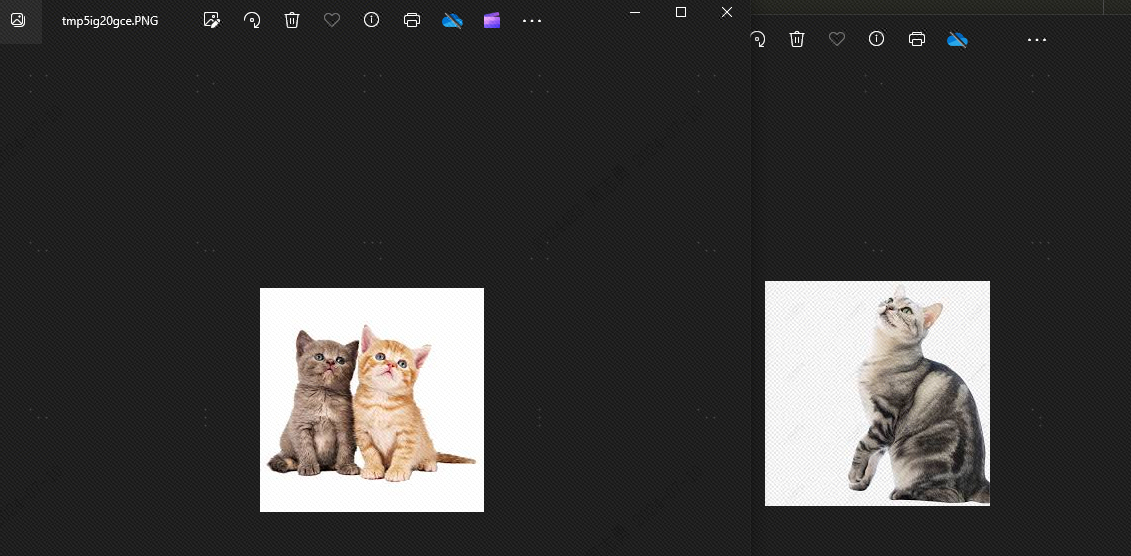
Ο λόγος για τον οποίο εμφανίζονται τα σκυλιά είναι επειδή έχω αποθηκεύσει 4 εικόνες ζώων στη διανυσματική βιβλιοθήκη, 2 εικόνες γάτας και 2 εικόνες σκύλων.
multi_model.pyΤα αρχεία είναι τα εξής:
import os
import dashscope
from dashvector import Client, Doc, DashVectorException
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
class DashVectorMultiModel:
def __init__(self):
# 我们需要同时开通 DASHSCOPE_API_KEY 和 DASHVECTOR_API_KEY
os.environ["DASHSCOPE_API_KEY"] = ""
os.environ["DASHVECTOR_API_KEY"] = ""
os.environ["DASHVECTOR_ENDPOINT"] = ""
dashscope.api_key = os.environ["DASHSCOPE_API_KEY"]
# 由于 ONE-PEACE 模型服务当前只支持 url 形式的图片、音频输入,因此用户需要将数据集提前上传到
# 公共网络存储(例如 oss/s3),并获取对应图片、音频的 url 列表。
# 该文件每行存储数据集单张图片的公共 url,与当前python脚本位于同目录下
self.IMAGENET1K_URLS_FILE_PATH = "imagenet1k-urls.txt"
self.vector_client = self.init_vector_client()
self.vector_collection_name = 'imagenet1k_val_embedding'
def init_vector_client(self):
return Client(
api_key=os.environ["DASHVECTOR_API_KEY"],
endpoint=os.environ["DASHVECTOR_ENDPOINT"]
)
def index_image(self):
# 创建集合:指定集合名称和向量维度, ONE-PEACE 模型产生的向量统一为 1536 维
collection = self.vector_client.get(self.vector_collection_name)
if not collection:
rsp = self.vector_client.create(self.vector_collection_name, 1536)
collection = self.vector_client.get(self.vector_collection_name)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# 调用 dashscope ONE-PEACE 模型生成图片 Embedding,并插入 dashvector
with open(self.IMAGENET1K_URLS_FILE_PATH, 'r') as file:
for i, line in enumerate(file):
url = line.strip('n')
input = [{'image': url}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}")
continue
embedding = result.output["embedding"]
collection.insert(
Doc(
id=str(i),
vector=embedding,
fields={'image_url': url}
)
)
if (i + 1) % 100 == 0:
print(f"---- Succeeded to insert {i + 1} image embeddings")
def show_image(self, image_list):
for img in image_list:
# 注意:show() 函数在 Linux 服务器上可能需要安装必要的图像浏览器组件才生效
# 建议在支持 jupyter notebook 的服务器上运行该代码
img.show()
def text_search(self, input_text):
# 获取上述入库的集合
collection = self.vector_client.get('imagenet1k_val_embedding')
# 获取文本 query 的 Embedding 向量
input = [{'text': input_text}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
text_vector = result.output["embedding"]
# DashVector 向量检索
rsp = collection.query(text_vector, topk=2)
image_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img = Image.open(urlopen(img_url))
image_list.append(img)
return image_list
if __name__ == '__main__':
a = DashVectorMultiModel()
# 执行 embedding 操作
a.index_image()
# 文本检索
text_query = "Traffic light"
a.show_image(a.text_search(text_query))
DASHSCOPE_API_KEY,DASHVECTOR_API_KEY,DASHVECTOR_ENDPOINTΗ δομή του καταλόγου κώδικα έχει ως εξής: Τοποθετήστε το αρχείο txt και το αρχείο py στον ίδιο κατάλογο:
Επιπλέον πληροφορίες
Χρησιμοποιήστε τοπικές εικόνες: Ανέβασα την εικόνα στο OSS Μπορείτε επίσης να χρησιμοποιήσετε ένα τοπικό αρχείο εικόνας και να αντικαταστήσετε τη διαδρομή αρχείου στο txt με την τοπική διαδρομή εικόνας, ως εξής:
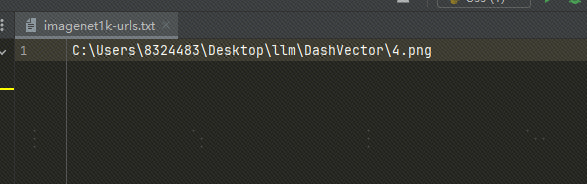
Εάν χρησιμοποιούμε τοπικές εικόνες, πρέπει να τροποποιήσουμε τον παραπάνω κώδικα και τον παρακάτω κώδικα:
# 将 img = Image.open(urlopen(img_url)) 替换为下边的代码
img = Image.open(img_url)

Έχει αφοσιωθεί στην έρευνα της τεχνολογίας για περισσότερα από 30 χρόνια και είναι ικανός σε διάφορες γλώσσες όπως java, linux, javascript, php, css κ.λπ. Έχει κάνει πολλές συνεισφορές στον τομέα του ανοιχτού κώδικα σταθμός τεκμηρίωσης προγραμματιστή για να μοιραστείτε ορισμένα ζητήματα στην ανάπτυξη τεχνολογίας για μελλοντική αναφορά

Ταχυδρομείο[email protected]