
minhas informações de contato
Correspondência[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Este artigo usa o serviço de recuperação de vetores do Alibaba Cloud (DashVector), combinado com Modelo multimodal ONE-PEACE , para construir capacidades de recuperação multimodal em tempo real de "pesquisa de texto para imagens". O processo geral é o seguinte: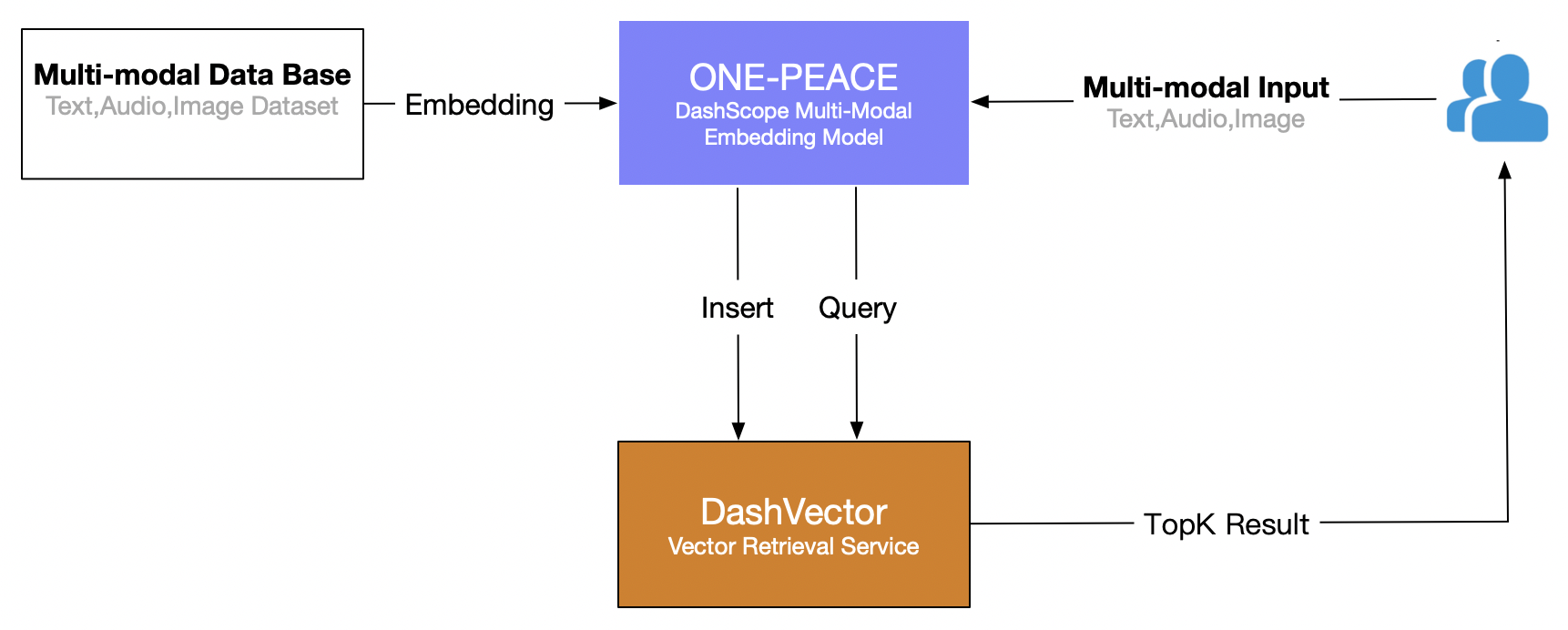
Pré-requisitos
- Abra o serviço do modelo Lingji e obtenha API-KEY:Ative o DashScope e crie API-KEY
- Serviço aberto de recuperação de vetores: consulteAssinar um serviço。
- Criar API-KEY do serviço de recuperação de vetores: consulteGerenciamento de API-KEY。
Preparação ambiental
# 安装 dashscope 和 dashvector sdk
pip3 install dashscope dashvector
# 显示图片
pip3 install Pillow
preparação de dados
ilustrar
Como o serviço do modelo ONE-PEACE do DashScope atualmente suporta apenas entrada de imagem e áudio na forma de URLs, é necessário carregar o conjunto de dados para armazenamento de rede pública (como oss/s3) com antecedência e obter a lista de endereços URL do correspondente imagens e áudios.
Usei o OSS do Alibaba Cloud para salvar a imagem e obtive o URL da imagem acessível externamente por meio da interface do navegador OSS: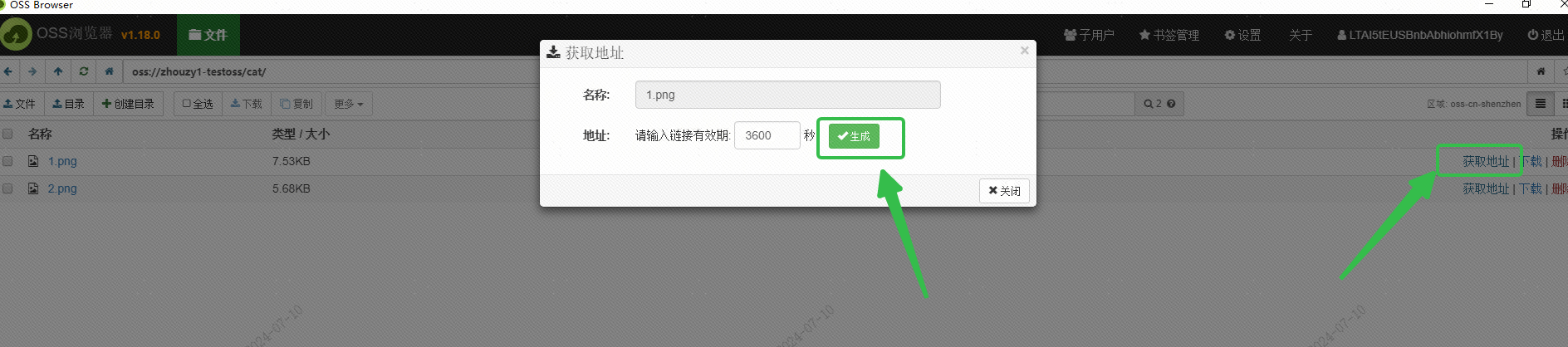
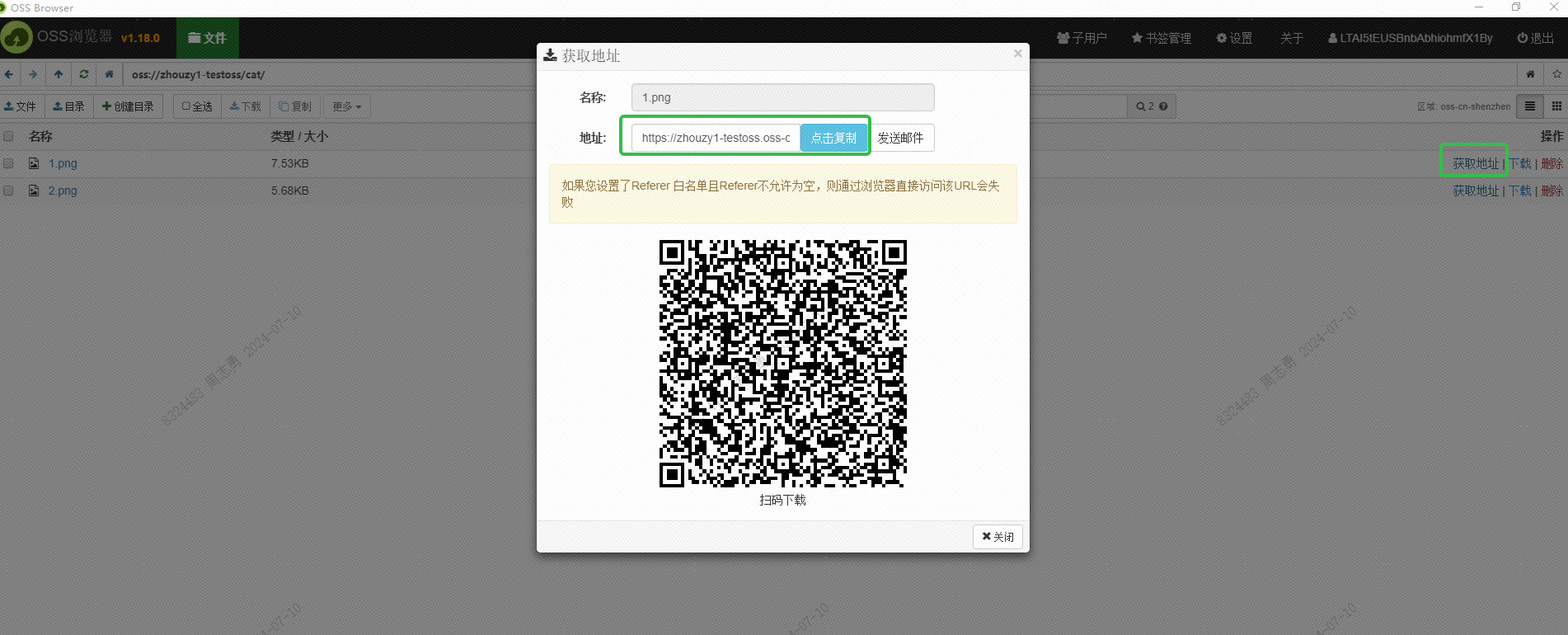
Este URL também deve ser obtido através da interface. Isso ainda não foi estudado. Amigos interessados podem tentar obtê-lo em lotes através da interface. O objetivo de obter este URL é permitir que o serviço DashScope do Alibaba Cloud leia a imagem para incorporação. Salve no banco de dados vetorial DashVector.
Depois de obter o URL, escreva-o em nosso imagenet1k-urls.txt arquivo, nosso código lerá o arquivo para incorporação posteriormente: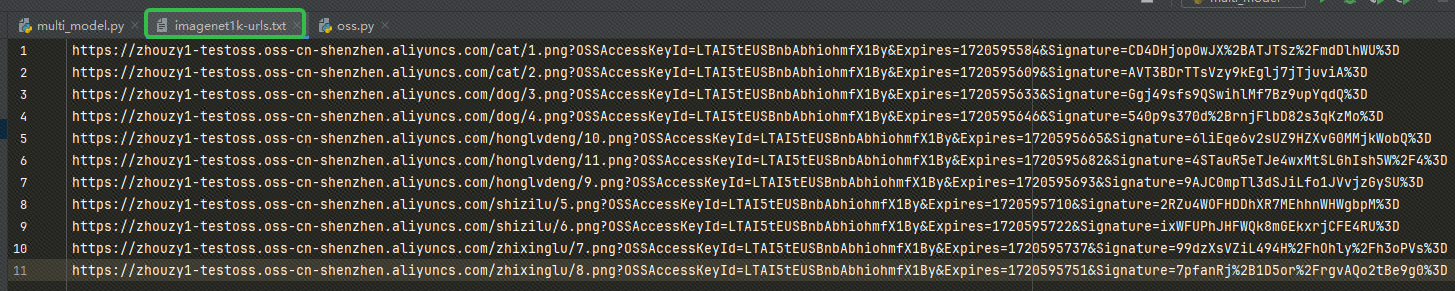
O código para executar a incorporação é o seguinte (postarei o código completo e a estrutura de diretórios mais tarde, apenas o código incorporado é postado aqui):
def index_image(self):
# 创建集合:指定集合名称和向量维度, ONE-PEACE 模型产生的向量统一为 1536 维
collection = self.vector_client.get(self.vector_collection_name)
if not collection:
rsp = self.vector_client.create(self.vector_collection_name, 1536)
collection = self.vector_client.get(self.vector_collection_name)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# 调用 dashscope ONE-PEACE 模型生成图片 Embedding,并插入 dashvector
with open(self.IMAGENET1K_URLS_FILE_PATH, 'r') as file:
for i, line in enumerate(file):
url = line.strip('n')
input = [{'image': url}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}")
continue
embedding = result.output["embedding"]
collection.insert(
Doc(
id=str(i),
vector=embedding,
fields={'image_url': url}
)
)
if (i + 1) % 100 == 0:
print(f"---- Succeeded to insert {i + 1} image embeddings")
IMAGENET1K_URLS_FILE_PATHO URL da imagem no URL e, em seguida, execute uma solicitação DashScope para vetorizar e armazenar nossa imagem.Após a execução, você pode passarConsole de serviço de recuperação de vetores, verifique os dados vetoriais: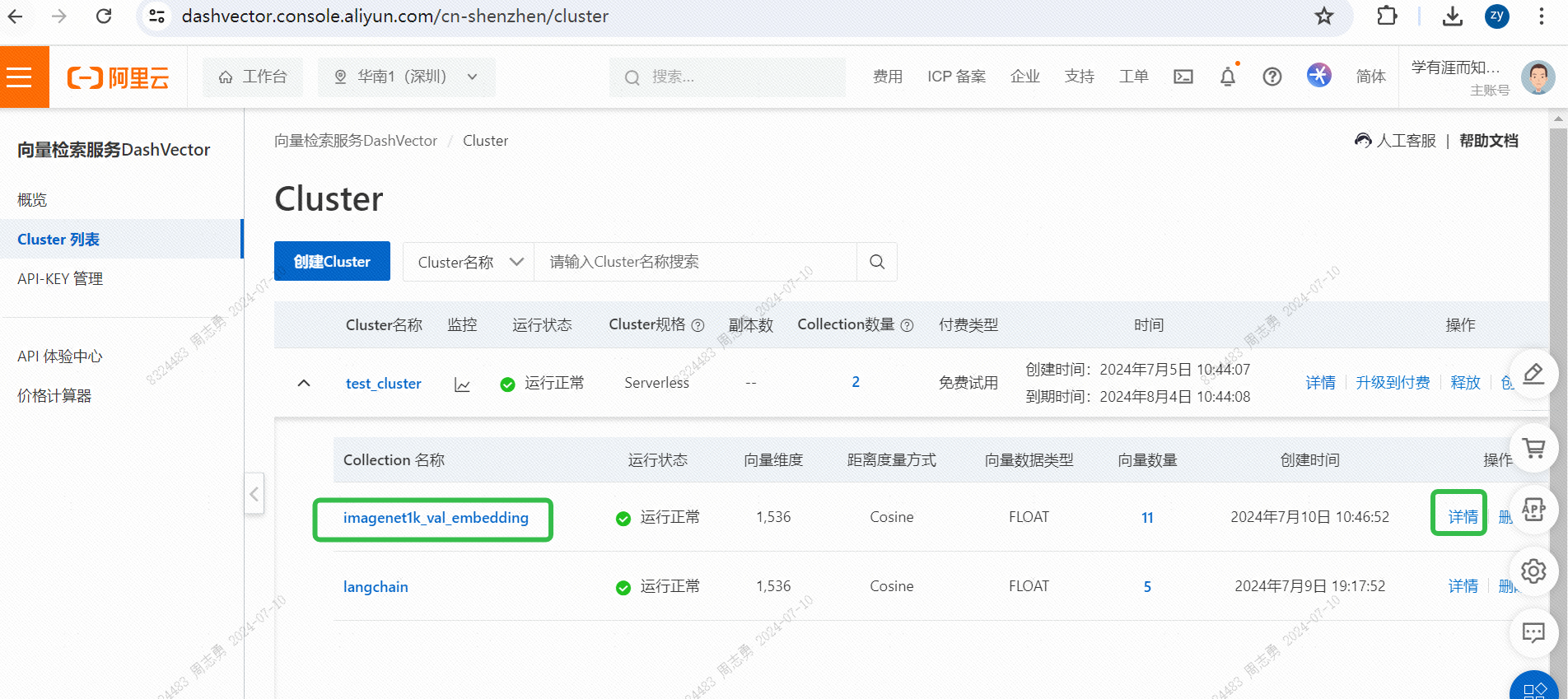
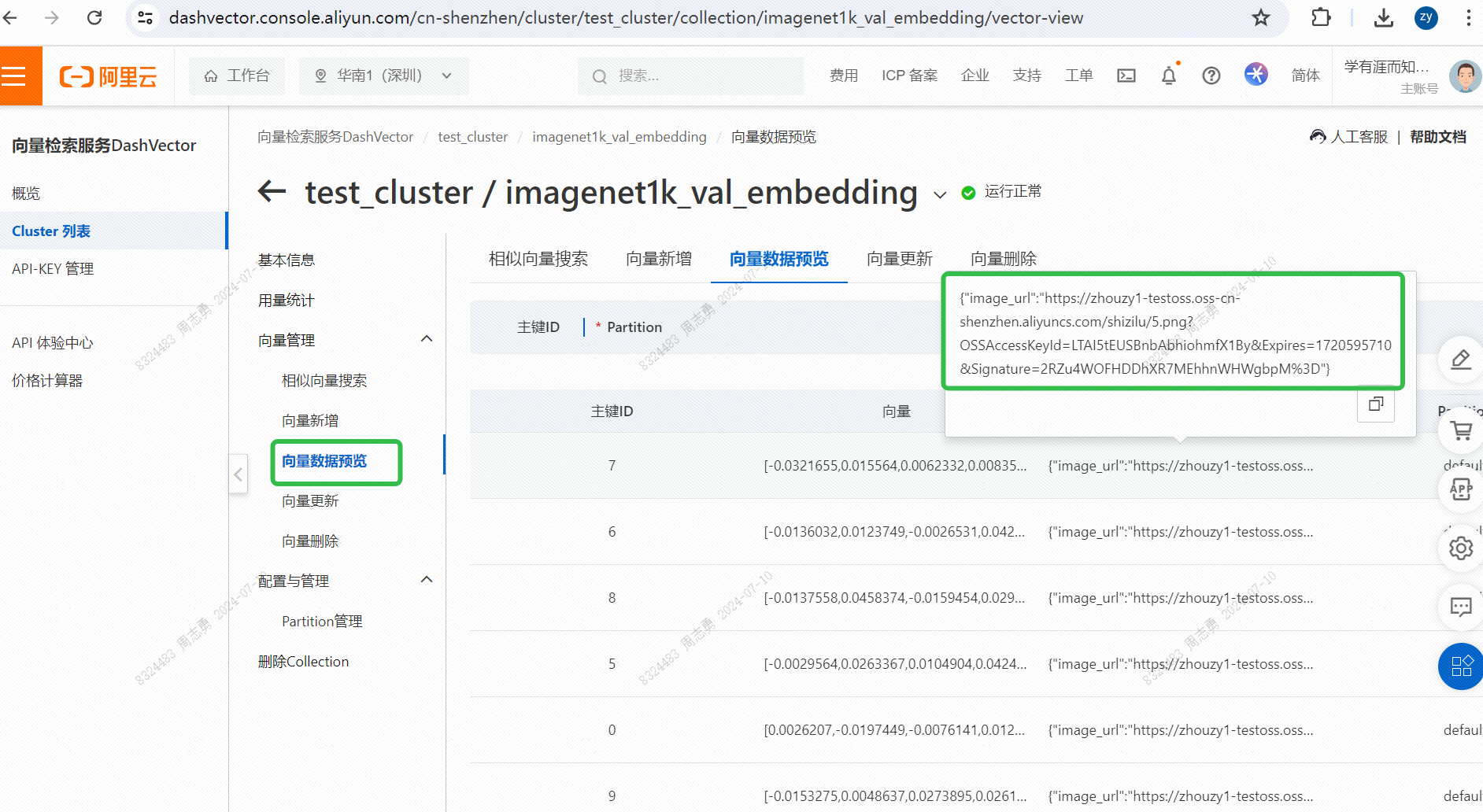
Para recuperar dados de um banco de dados vetorial por texto, eu insirocatDepois de recuperar três fotos (topk = 3 definidas em nosso código), você pode verificar o efeito. Duas são fotos de gatos, mas uma é a foto de um cachorro: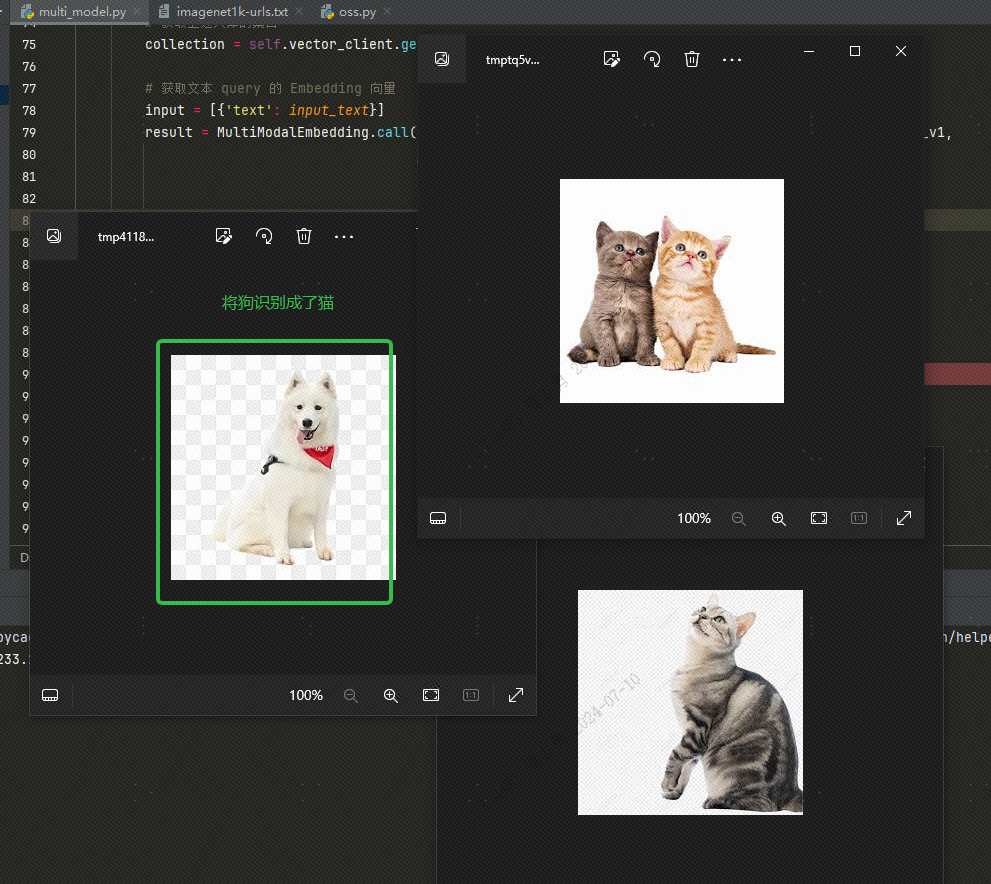
Isso ocorre porque existem semelhanças entre cães e gatos. A seguir, veremos.topkDefinido como 2, teoricamente o cachorro não pode ser detectado. Vamos ver o efeito e, com certeza, não há cachorro: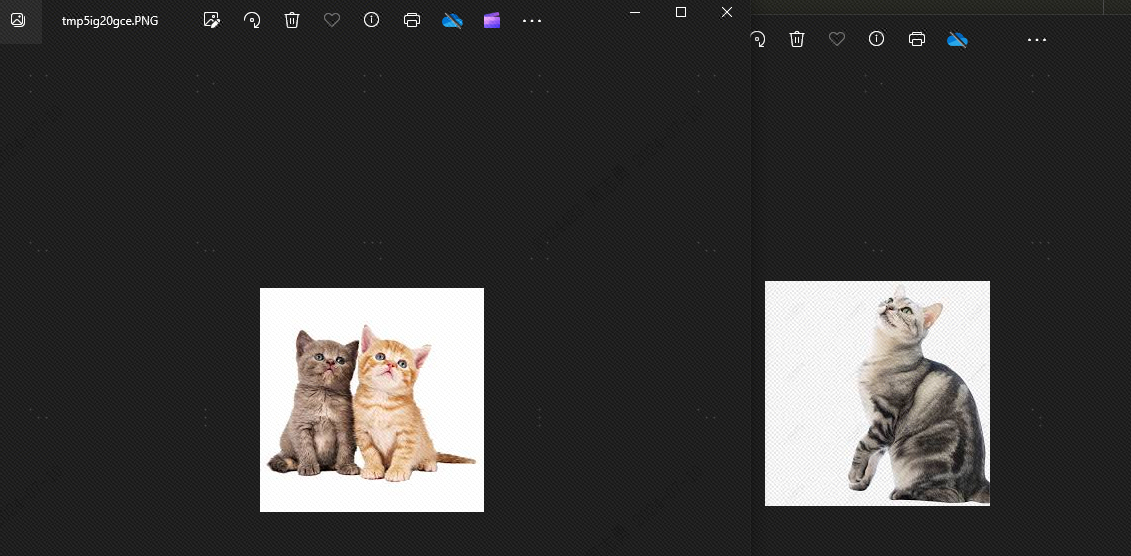
A razão pela qual os cães aparecem é porque armazenei 4 imagens de animais na biblioteca de vetores, 2 imagens de gatos e 2 imagens de cães. Se nosso topk estiver definido como 3, mais uma imagem de cachorro será detectada.
multi_model.pyOs arquivos são os seguintes:
import os
import dashscope
from dashvector import Client, Doc, DashVectorException
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
class DashVectorMultiModel:
def __init__(self):
# 我们需要同时开通 DASHSCOPE_API_KEY 和 DASHVECTOR_API_KEY
os.environ["DASHSCOPE_API_KEY"] = ""
os.environ["DASHVECTOR_API_KEY"] = ""
os.environ["DASHVECTOR_ENDPOINT"] = ""
dashscope.api_key = os.environ["DASHSCOPE_API_KEY"]
# 由于 ONE-PEACE 模型服务当前只支持 url 形式的图片、音频输入,因此用户需要将数据集提前上传到
# 公共网络存储(例如 oss/s3),并获取对应图片、音频的 url 列表。
# 该文件每行存储数据集单张图片的公共 url,与当前python脚本位于同目录下
self.IMAGENET1K_URLS_FILE_PATH = "imagenet1k-urls.txt"
self.vector_client = self.init_vector_client()
self.vector_collection_name = 'imagenet1k_val_embedding'
def init_vector_client(self):
return Client(
api_key=os.environ["DASHVECTOR_API_KEY"],
endpoint=os.environ["DASHVECTOR_ENDPOINT"]
)
def index_image(self):
# 创建集合:指定集合名称和向量维度, ONE-PEACE 模型产生的向量统一为 1536 维
collection = self.vector_client.get(self.vector_collection_name)
if not collection:
rsp = self.vector_client.create(self.vector_collection_name, 1536)
collection = self.vector_client.get(self.vector_collection_name)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# 调用 dashscope ONE-PEACE 模型生成图片 Embedding,并插入 dashvector
with open(self.IMAGENET1K_URLS_FILE_PATH, 'r') as file:
for i, line in enumerate(file):
url = line.strip('n')
input = [{'image': url}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}")
continue
embedding = result.output["embedding"]
collection.insert(
Doc(
id=str(i),
vector=embedding,
fields={'image_url': url}
)
)
if (i + 1) % 100 == 0:
print(f"---- Succeeded to insert {i + 1} image embeddings")
def show_image(self, image_list):
for img in image_list:
# 注意:show() 函数在 Linux 服务器上可能需要安装必要的图像浏览器组件才生效
# 建议在支持 jupyter notebook 的服务器上运行该代码
img.show()
def text_search(self, input_text):
# 获取上述入库的集合
collection = self.vector_client.get('imagenet1k_val_embedding')
# 获取文本 query 的 Embedding 向量
input = [{'text': input_text}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
text_vector = result.output["embedding"]
# DashVector 向量检索
rsp = collection.query(text_vector, topk=2)
image_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img = Image.open(urlopen(img_url))
image_list.append(img)
return image_list
if __name__ == '__main__':
a = DashVectorMultiModel()
# 执行 embedding 操作
a.index_image()
# 文本检索
text_query = "Traffic light"
a.show_image(a.text_search(text_query))
DASHSCOPE_API_KEY,DASHVECTOR_API_KEY,DASHVECTOR_ENDPOINTA estrutura do diretório do código é a seguinte. Coloque o arquivo txt e o arquivo py no mesmo diretório: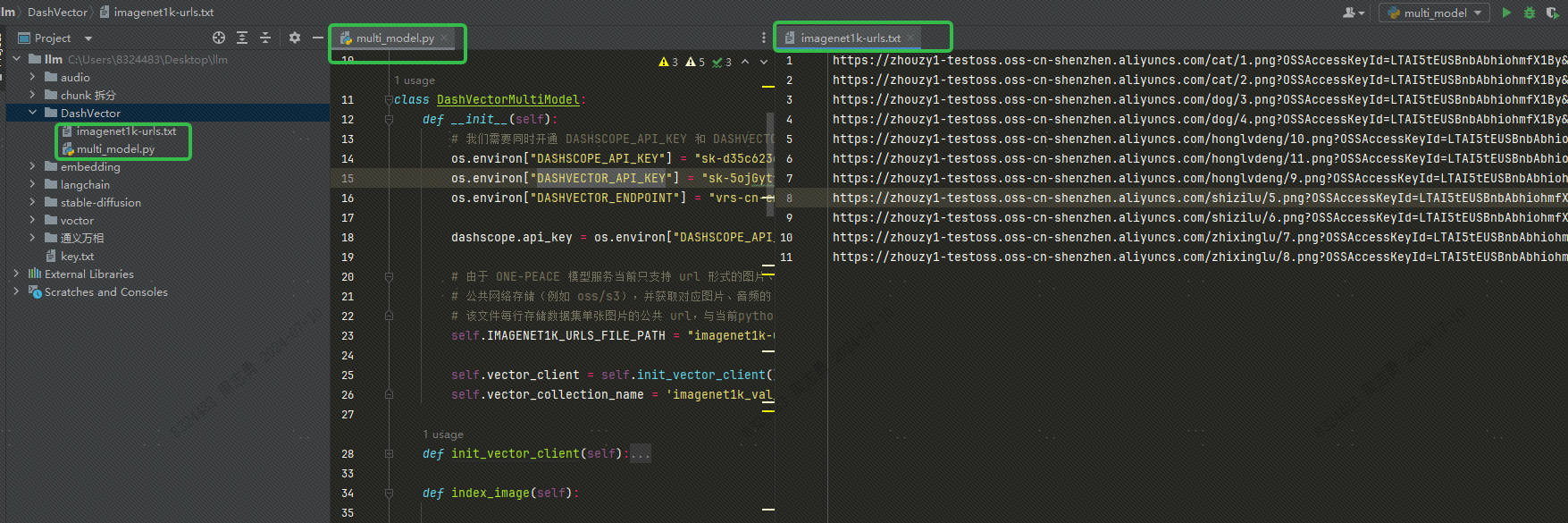
Informações adicionais
Use imagens locais: carreguei a imagem no OSS. Você também pode usar um arquivo de imagem local e substituir o caminho do arquivo em txt pelo caminho da imagem local, da seguinte maneira:
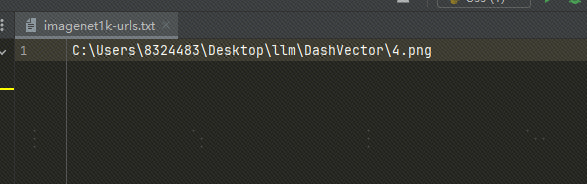
Se usarmos imagens locais, teremos que modificar o código acima e o código abaixo:
# 将 img = Image.open(urlopen(img_url)) 替换为下边的代码
img = Image.open(img_url)

Ele se dedica à pesquisa de tecnologia há mais de 30 anos e é proficiente em diversas linguagens como java, linux, javascript, php, css, etc. estação de documentação do desenvolvedor para compartilhar alguns problemas no desenvolvimento de tecnologia para referência futura.

Correspondência[email protected]