
プライベートな連絡先の最初の情報
送料メール:
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
この記事では、Alibaba Cloud のベクトル検索サービス (DashVector) を使用し、 ONE-PEACEマルチモーダルモデル 、「画像のテキスト検索」のリアルタイムのマルチモーダル検索機能を構築します。全体的なプロセスは次のとおりです。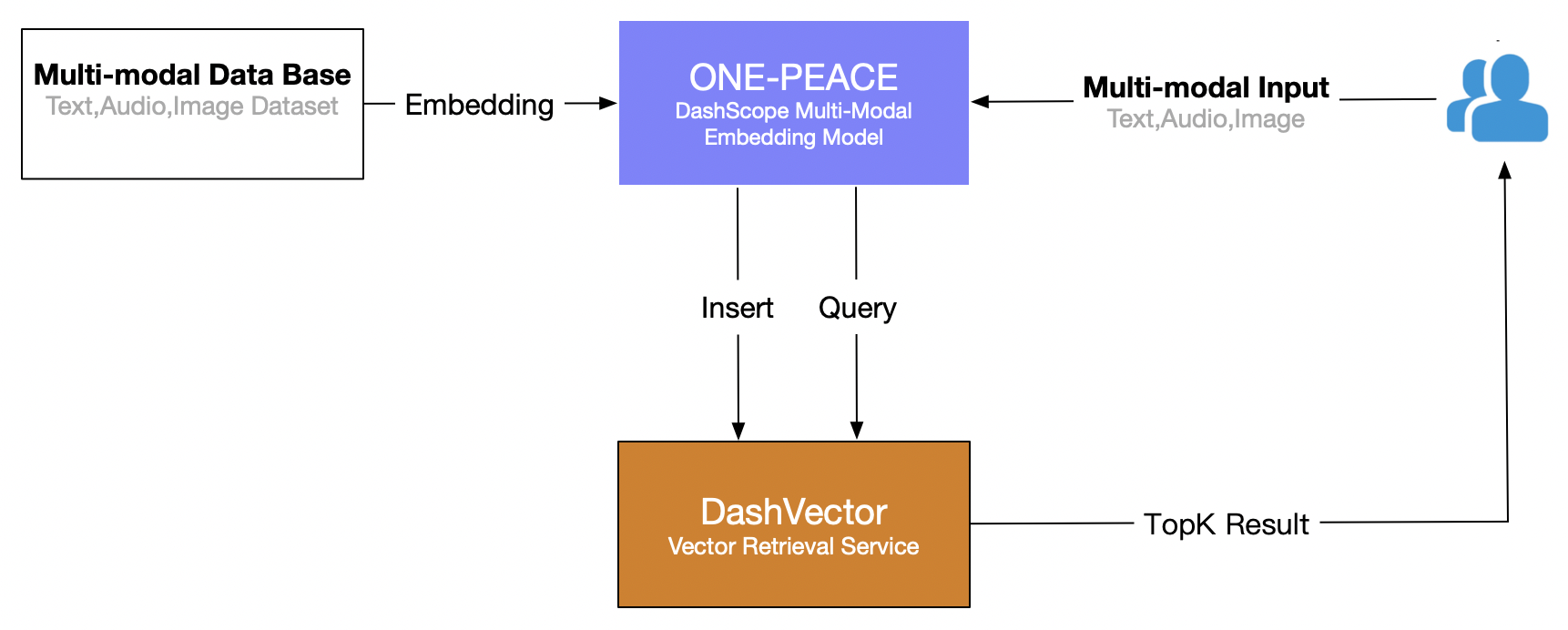
前提条件
- Lingji モデル サービスを開き、API-KEY を取得します。DashScopeを有効にしてAPI-KEYを作成する
- オープンベクター検索サービス: を参照してください。サービスに登録する。
- ベクトル検索サービス API-KEY の作成: を参照してください。API-KEY管理。
環境整備
# 安装 dashscope 和 dashvector sdk
pip3 install dashscope dashvector
# 显示图片
pip3 install Pillow
データの準備
説明する
DashScope の ONE-PEACE モデル サービスは現在、URL 形式での画像と音声の入力のみをサポートしているため、事前にデータセットをパブリック ネットワーク ストレージ (oss/s3 など) にアップロードし、対応する URL アドレス リストを取得する必要があります。画像と音声。
Alibaba Cloud の OSS を使用して画像を保存し、OSS ブラウザ インターフェイスを通じて外部からアクセス可能な画像の URL を取得しました。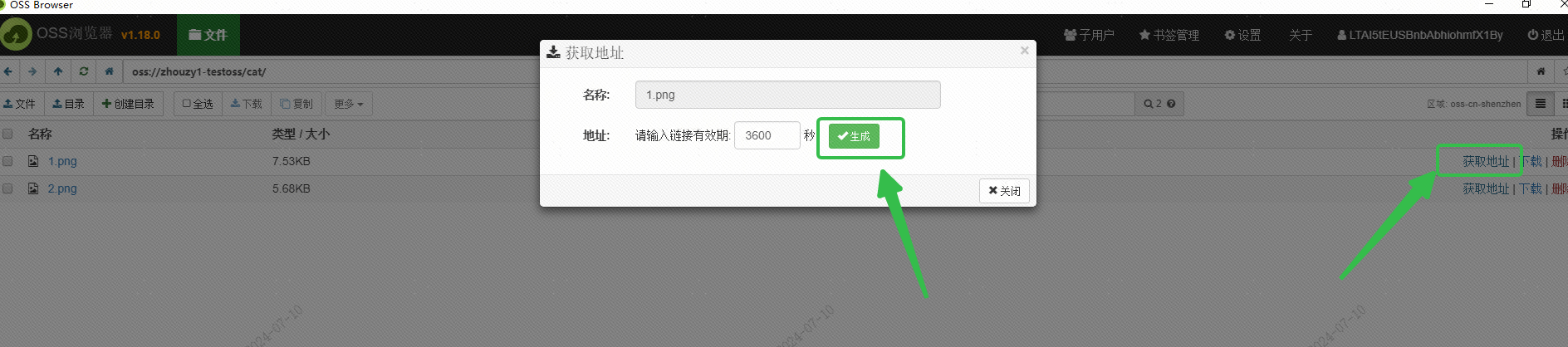
この URL もインターフェイスを通じて取得する必要があります。これについてはまだ検討されていません。興味のある友人は、Alibaba Cloud の DashScope サービスが埋め込み用の画像を読み取れるようにするために、インターフェイスを通じてバッチで取得することを試みることができます。 DashVector ベクトル データベースに保存します。
URLを取得したら、そのURLを imagenet1k-urls.txt ファイルを作成すると、コードは後で埋め込むためにファイルを読み取ります。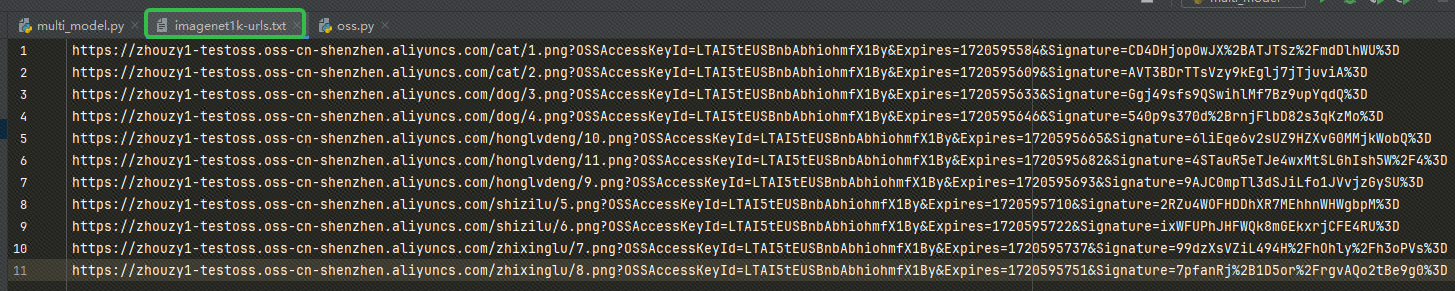
埋め込みを実行するコードは次のとおりです (完全なコードとディレクトリ構造は後で投稿します。ここでは埋め込みコードのみを投稿します)。
def index_image(self):
# 创建集合:指定集合名称和向量维度, ONE-PEACE 模型产生的向量统一为 1536 维
collection = self.vector_client.get(self.vector_collection_name)
if not collection:
rsp = self.vector_client.create(self.vector_collection_name, 1536)
collection = self.vector_client.get(self.vector_collection_name)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# 调用 dashscope ONE-PEACE 模型生成图片 Embedding,并插入 dashvector
with open(self.IMAGENET1K_URLS_FILE_PATH, 'r') as file:
for i, line in enumerate(file):
url = line.strip('n')
input = [{'image': url}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}")
continue
embedding = result.output["embedding"]
collection.insert(
Doc(
id=str(i),
vector=embedding,
fields={'image_url': url}
)
)
if (i + 1) % 100 == 0:
print(f"---- Succeeded to insert {i + 1} image embeddings")
IMAGENET1K_URLS_FILE_PATHURL 内の画像 URL を指定し、DashScope リクエストを実行して画像をベクトル化して保存します。実行後は渡すことができますベクトル検索サービスコンソール、ベクトル データを確認します。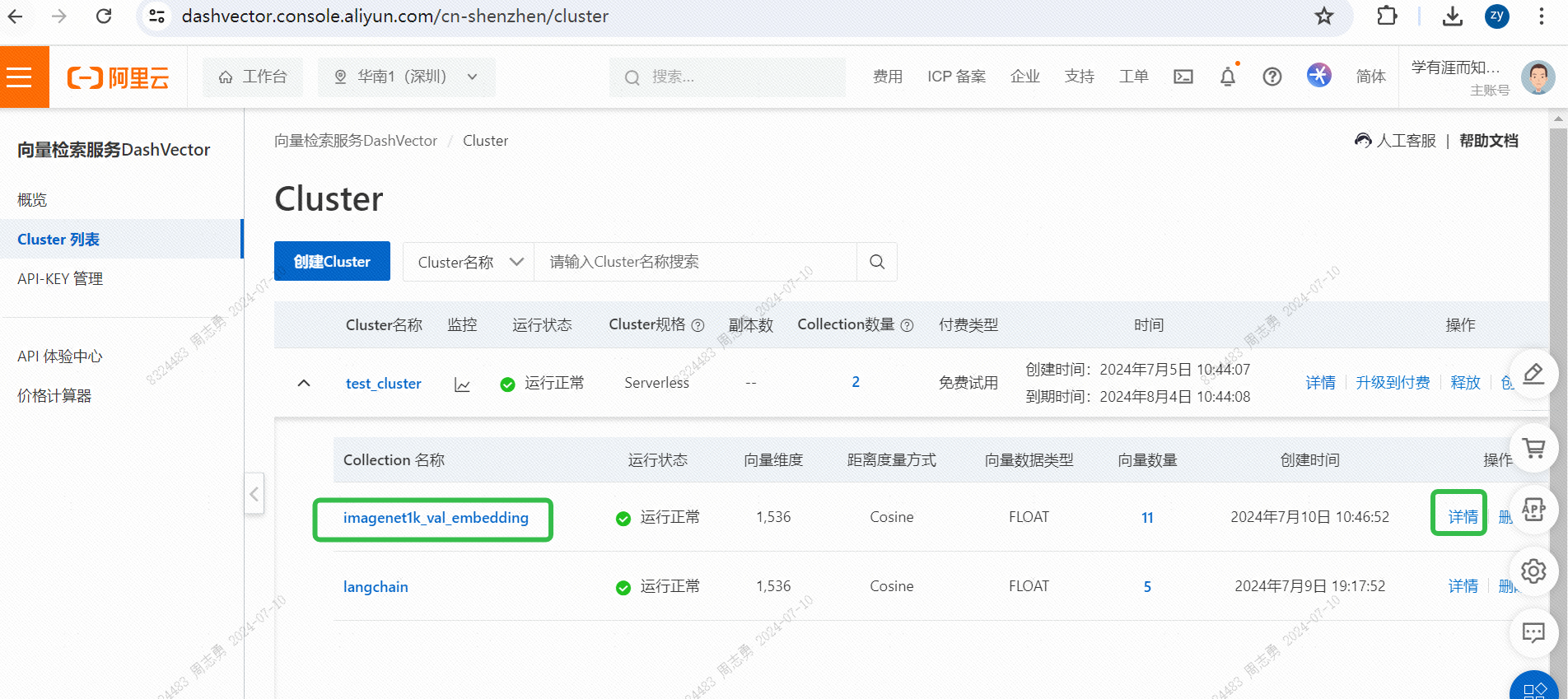
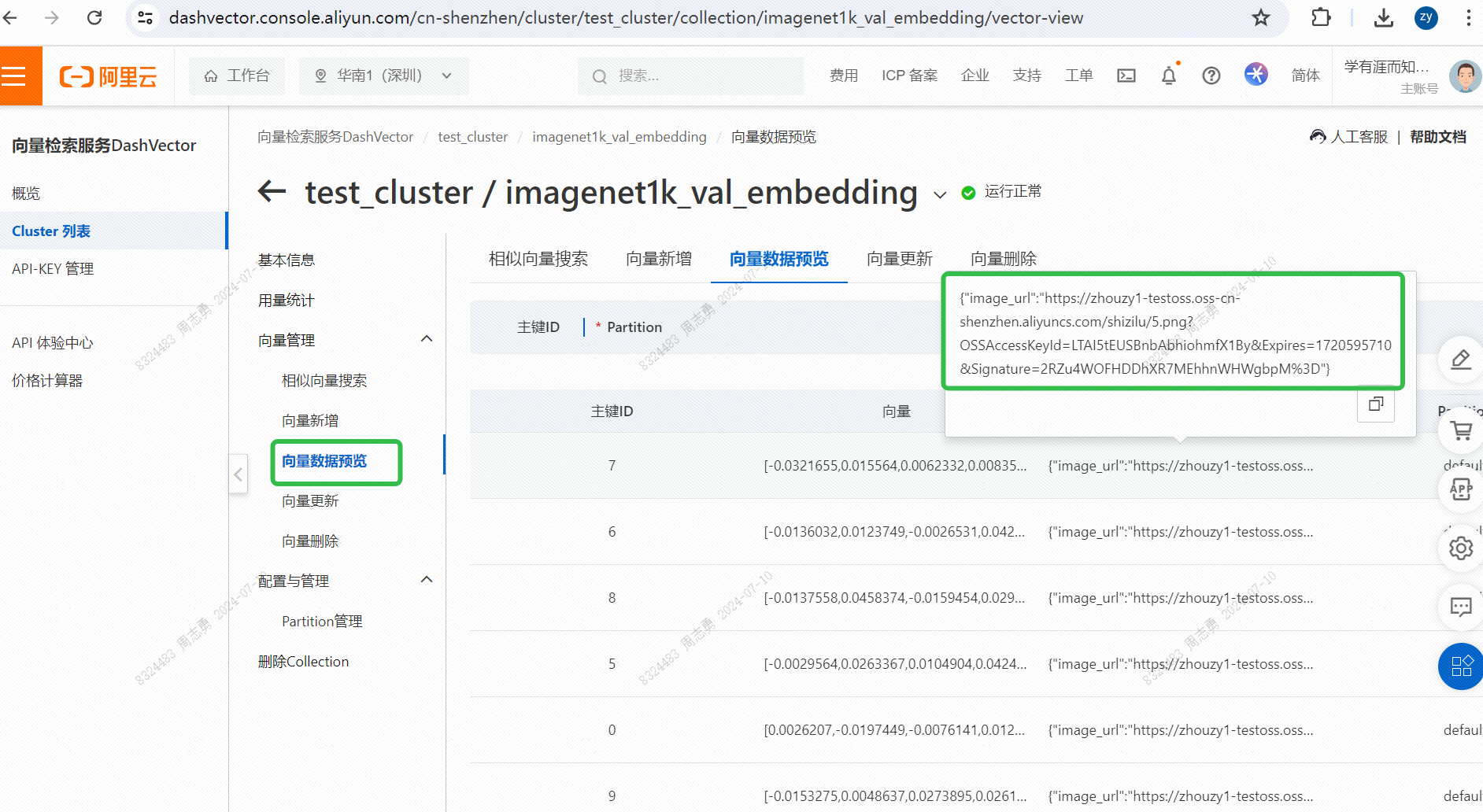
ベクトル データベースからデータをテキストで取得するには、次のように入力します。cat3 枚の写真 (コードで topk=3 に設定) を取得した後、2 枚は猫の写真ですが、1 枚は犬の写真であることを確認できます。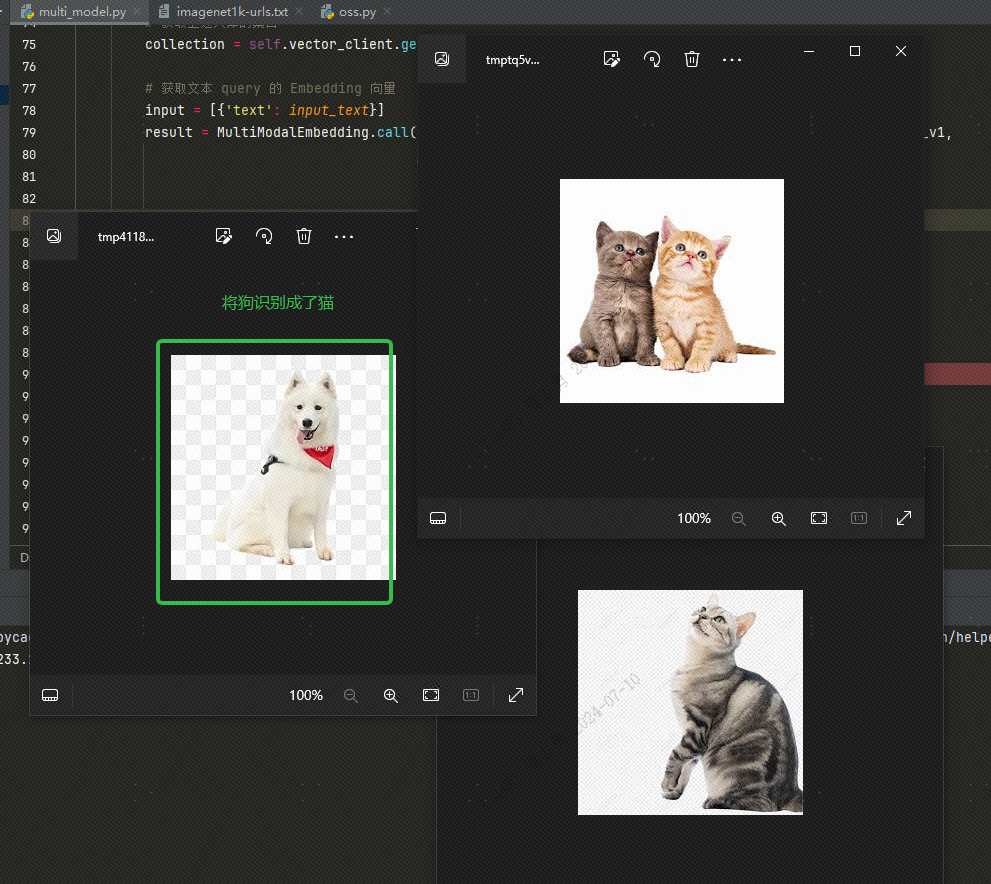
犬と猫には類似点があるからです。topk2 に設定すると、理論的には犬は検出されません。効果を見てみましょう。確かに、犬は存在しません。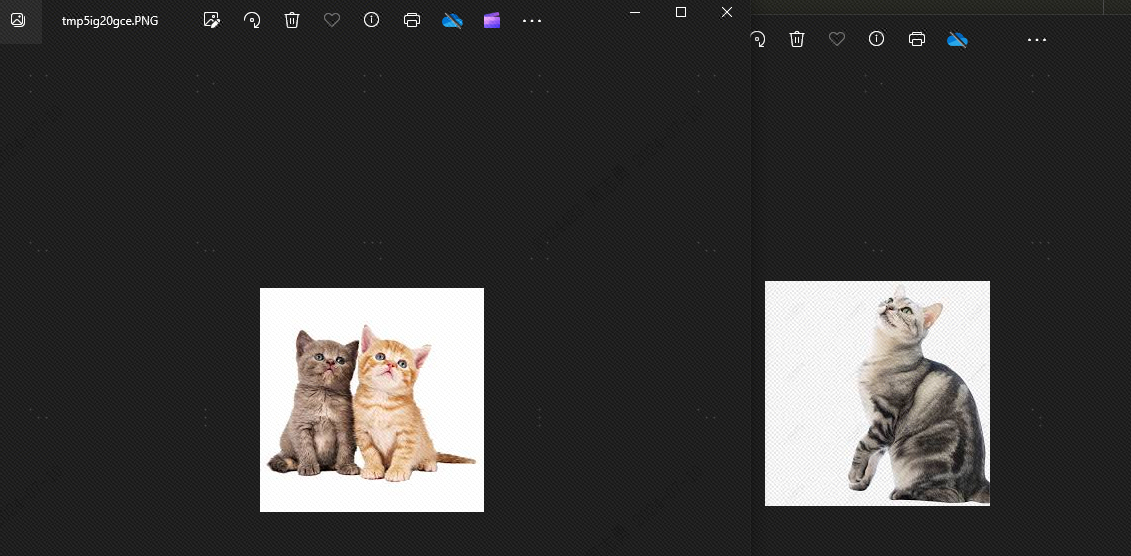
犬が表示される理由は、ベクトル ライブラリに 4 つの動物の写真、2 つの猫の写真、2 つの犬の写真を保存しているためです。topk を 3 に設定すると、さらに 1 枚の犬の写真が検出されます。
multi_model.pyファイルは次のとおりです。
import os
import dashscope
from dashvector import Client, Doc, DashVectorException
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
class DashVectorMultiModel:
def __init__(self):
# 我们需要同时开通 DASHSCOPE_API_KEY 和 DASHVECTOR_API_KEY
os.environ["DASHSCOPE_API_KEY"] = ""
os.environ["DASHVECTOR_API_KEY"] = ""
os.environ["DASHVECTOR_ENDPOINT"] = ""
dashscope.api_key = os.environ["DASHSCOPE_API_KEY"]
# 由于 ONE-PEACE 模型服务当前只支持 url 形式的图片、音频输入,因此用户需要将数据集提前上传到
# 公共网络存储(例如 oss/s3),并获取对应图片、音频的 url 列表。
# 该文件每行存储数据集单张图片的公共 url,与当前python脚本位于同目录下
self.IMAGENET1K_URLS_FILE_PATH = "imagenet1k-urls.txt"
self.vector_client = self.init_vector_client()
self.vector_collection_name = 'imagenet1k_val_embedding'
def init_vector_client(self):
return Client(
api_key=os.environ["DASHVECTOR_API_KEY"],
endpoint=os.environ["DASHVECTOR_ENDPOINT"]
)
def index_image(self):
# 创建集合:指定集合名称和向量维度, ONE-PEACE 模型产生的向量统一为 1536 维
collection = self.vector_client.get(self.vector_collection_name)
if not collection:
rsp = self.vector_client.create(self.vector_collection_name, 1536)
collection = self.vector_client.get(self.vector_collection_name)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# 调用 dashscope ONE-PEACE 模型生成图片 Embedding,并插入 dashvector
with open(self.IMAGENET1K_URLS_FILE_PATH, 'r') as file:
for i, line in enumerate(file):
url = line.strip('n')
input = [{'image': url}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}")
continue
embedding = result.output["embedding"]
collection.insert(
Doc(
id=str(i),
vector=embedding,
fields={'image_url': url}
)
)
if (i + 1) % 100 == 0:
print(f"---- Succeeded to insert {i + 1} image embeddings")
def show_image(self, image_list):
for img in image_list:
# 注意:show() 函数在 Linux 服务器上可能需要安装必要的图像浏览器组件才生效
# 建议在支持 jupyter notebook 的服务器上运行该代码
img.show()
def text_search(self, input_text):
# 获取上述入库的集合
collection = self.vector_client.get('imagenet1k_val_embedding')
# 获取文本 query 的 Embedding 向量
input = [{'text': input_text}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
text_vector = result.output["embedding"]
# DashVector 向量检索
rsp = collection.query(text_vector, topk=2)
image_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img = Image.open(urlopen(img_url))
image_list.append(img)
return image_list
if __name__ == '__main__':
a = DashVectorMultiModel()
# 执行 embedding 操作
a.index_image()
# 文本检索
text_query = "Traffic light"
a.show_image(a.text_search(text_query))
DASHSCOPE_API_KEY,DASHVECTOR_API_KEY,DASHVECTOR_ENDPOINTコードのディレクトリ構造は次のとおりです。txt ファイルと py ファイルを同じディレクトリに配置します。
追加情報
ローカルイメージを使用する: イメージを OSS にアップロードしました。次のように、ローカル イメージ ファイルを使用して、txt 内のファイル パスをローカル イメージ パスに置き換えることもできます。
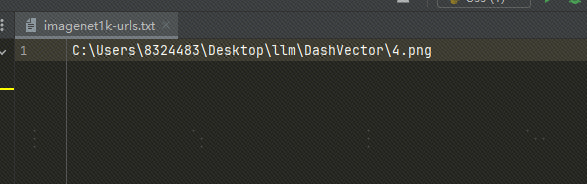
ローカル イメージを使用する場合は、上記のコードと以下のコードを変更する必要があります。
# 将 img = Image.open(urlopen(img_url)) 替换为下边的代码
img = Image.open(img_url)

彼は 30 年以上テクノロジーの研究に専念しており、Java、linux、javascript、php、css などのさまざまな言語に堪能であり、オープンソース分野で多くの貢献を行っています。将来の参考のために技術開発におけるいくつかの問題を共有する開発者ドキュメント ステーション。

送料メール: