
моя контактная информация
Почтамезофия@protonmail.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
В этой статье используется служба векторного поиска Alibaba Cloud (DashVector) в сочетании с Мультимодальная модель ONE-PEACE , для создания возможностей мультимодального поиска в режиме реального времени «текстового поиска изображений». Общий процесс выглядит следующим образом: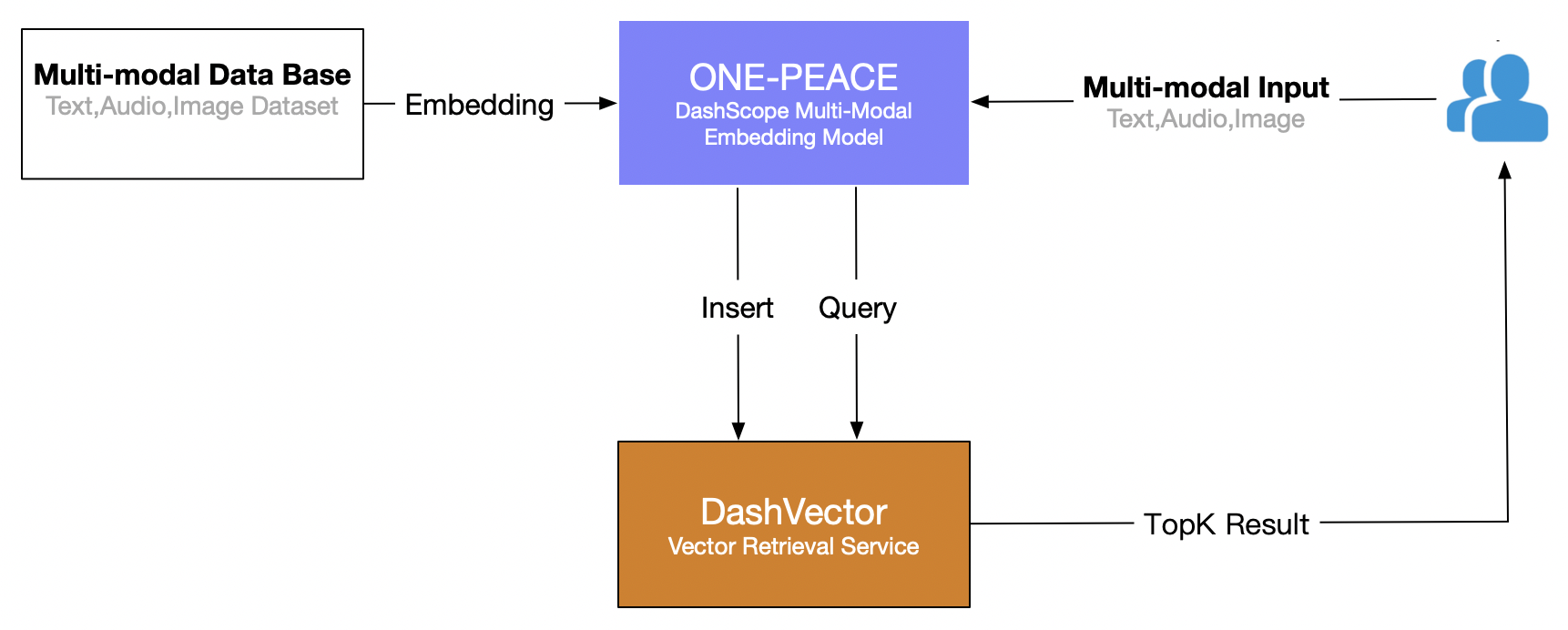
Предварительные условия
- Откройте сервис модели Lingji и получите API-KEY:Активируйте DashScope и создайте API-KEY
- Служба поиска открытых векторов: см.Подписаться на услугу。
- Создайте службу векторного поиска API-KEY: см.Управление API-КЛЮЧАМИ。
Экологическая подготовка
# 安装 dashscope 和 dashvector sdk
pip3 install dashscope dashvector
# 显示图片
pip3 install Pillow
подготовка данных
иллюстрировать
Поскольку сервис модели ONE-PEACE DashScope в настоящее время поддерживает только ввод изображений и аудио в виде URL-адресов, необходимо заранее загрузить набор данных в общедоступное сетевое хранилище (например, oss/s3) и получить список URL-адресов соответствующих изображения и аудио.
Я использовал OSS Alibaba Cloud для сохранения изображения и получил доступный извне URL-адрес изображения через интерфейс браузера OSS: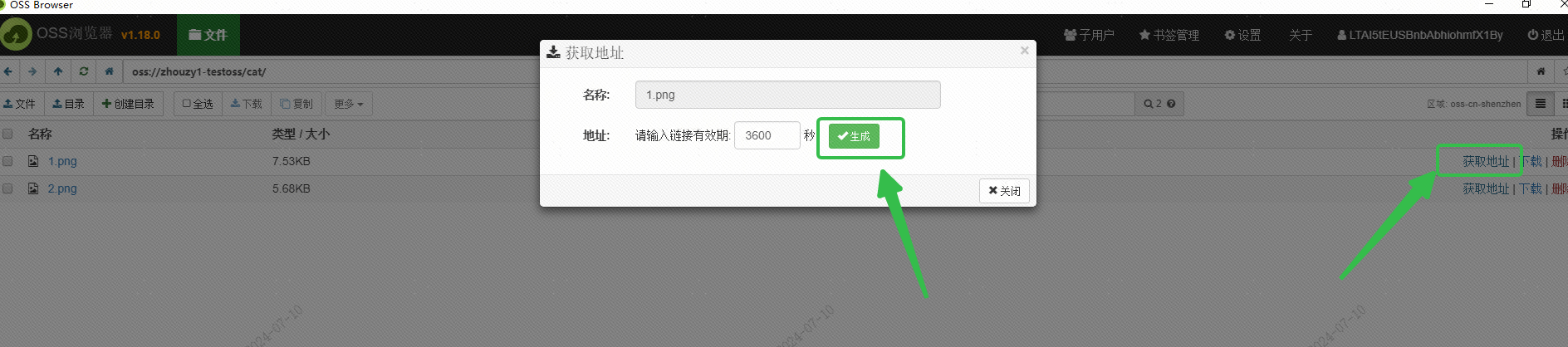
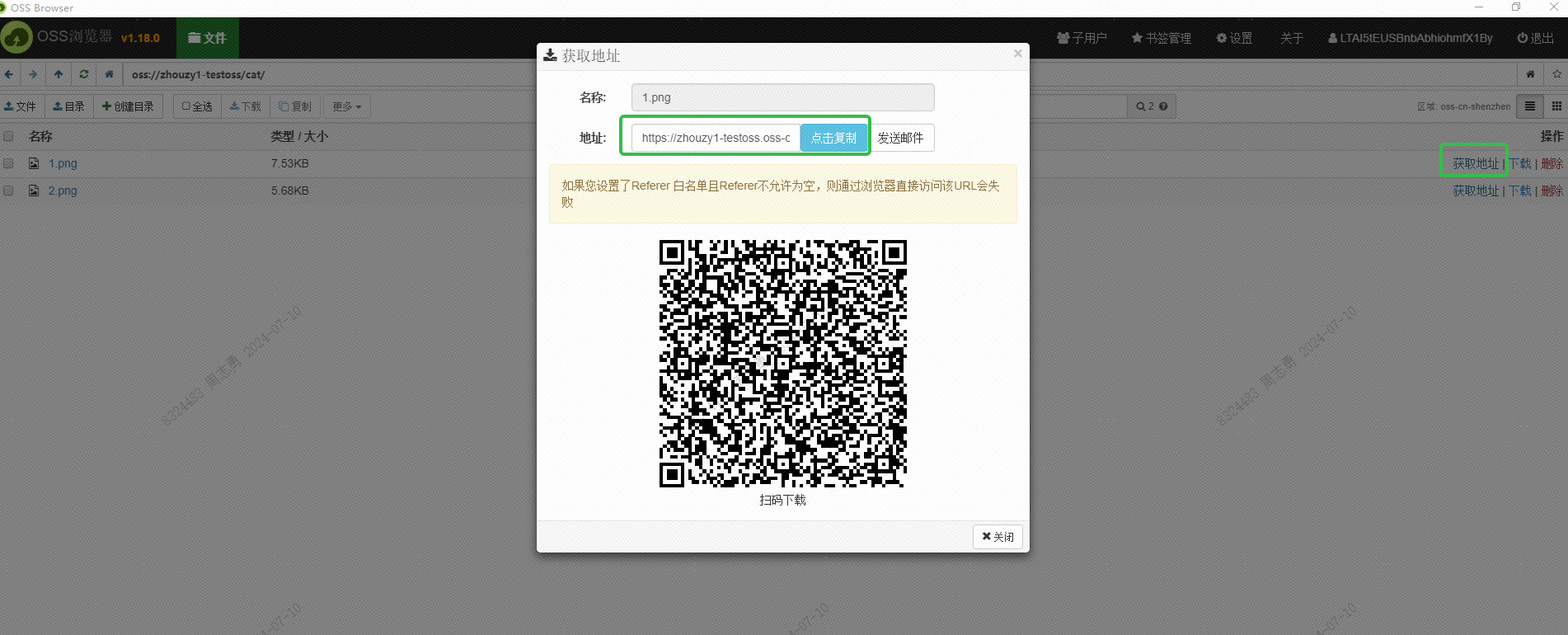
Этот URL-адрес также следует получить через интерфейс. Это еще не изучено. Заинтересованные друзья могут попытаться получить его пакетно через интерфейс. Цель получения этого URL-адреса — дать возможность сервису DashScope Alibaba Cloud прочитать изображение для встраивания. Сохранить в векторную базу данных DashVector.
После получения URL-адреса запишите URL-адрес в наш imagenet1k-urls.txt файл, наш код прочитает файл для последующего встраивания: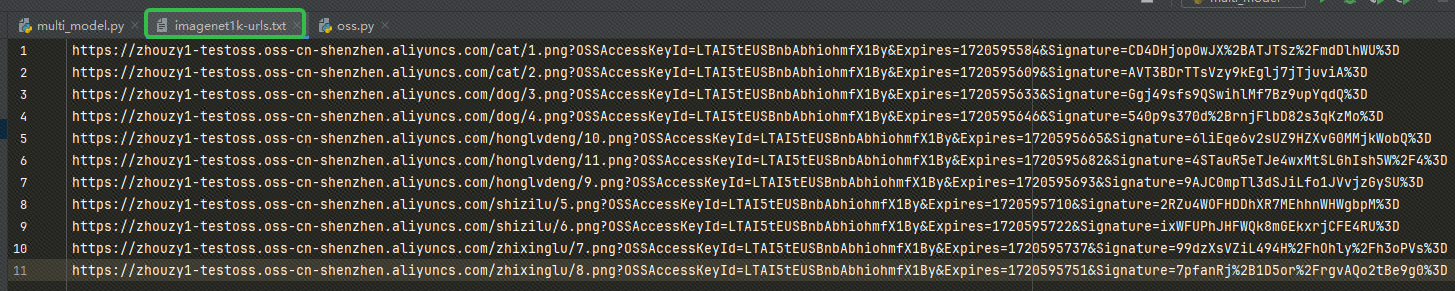
Код для внедрения выглядит следующим образом (полный код и структуру каталогов я опубликую позже, здесь размещен только встроенный код):
def index_image(self):
# 创建集合:指定集合名称和向量维度, ONE-PEACE 模型产生的向量统一为 1536 维
collection = self.vector_client.get(self.vector_collection_name)
if not collection:
rsp = self.vector_client.create(self.vector_collection_name, 1536)
collection = self.vector_client.get(self.vector_collection_name)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# 调用 dashscope ONE-PEACE 模型生成图片 Embedding,并插入 dashvector
with open(self.IMAGENET1K_URLS_FILE_PATH, 'r') as file:
for i, line in enumerate(file):
url = line.strip('n')
input = [{'image': url}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}")
continue
embedding = result.output["embedding"]
collection.insert(
Doc(
id=str(i),
vector=embedding,
fields={'image_url': url}
)
)
if (i + 1) % 100 == 0:
print(f"---- Succeeded to insert {i + 1} image embeddings")
IMAGENET1K_URLS_FILE_PATHURL-адрес изображения в URL-адресе, а затем выполните запрос DashScope для векторизации и сохранения нашего изображения.После выполнения можно пройтиКонсоль службы векторного поиска, проверьте векторные данные: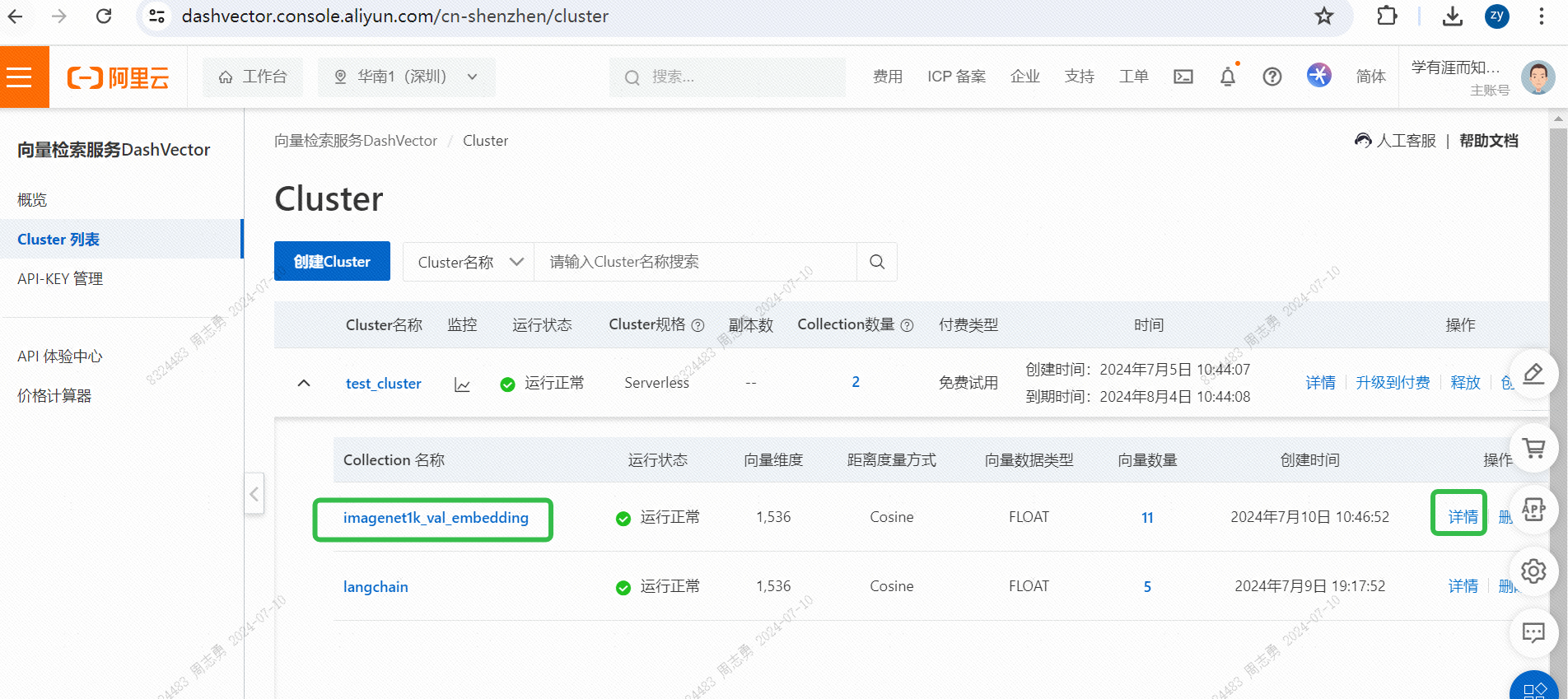
Чтобы получить данные из векторной базы данных по тексту, я ввожуcatПосле получения трех изображений (в нашем коде установлено значение topk=3) вы можете проверить эффект. Два из них — изображения кошек, а одно — изображение собаки: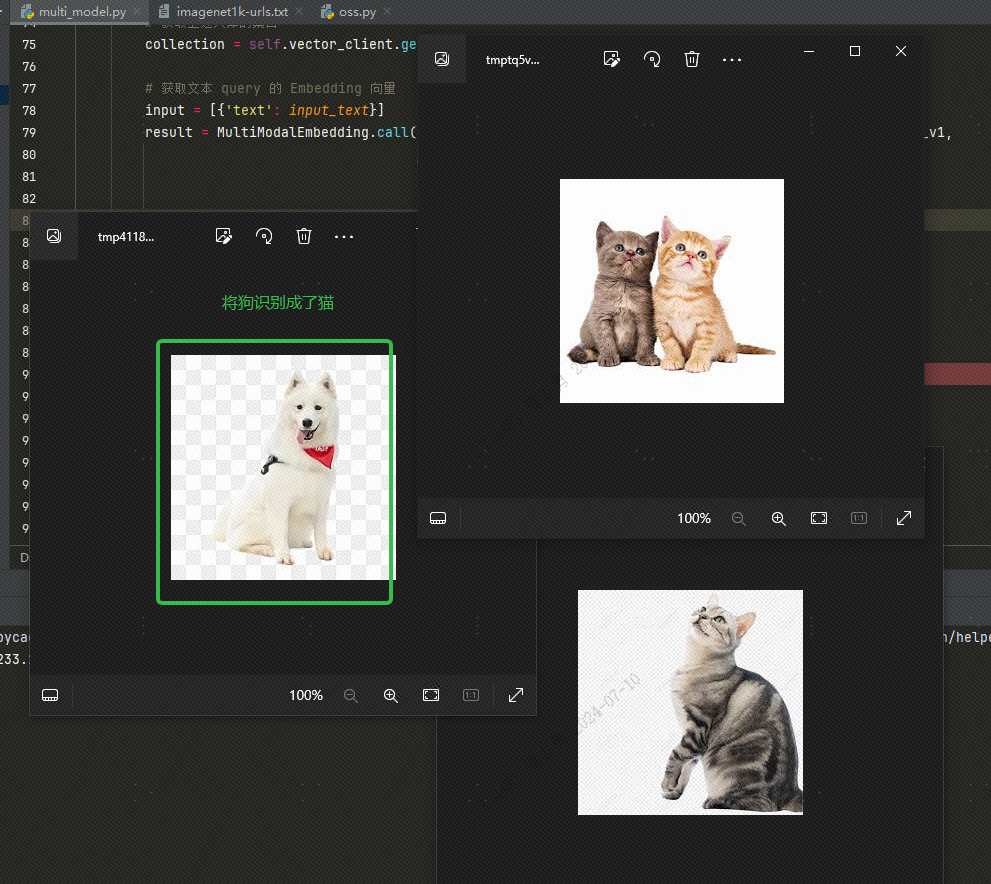
Это потому, что между собаками и кошками есть сходство. Далее мы поговорим.topkЕсли установлено значение 2, теоретически собака не может быть обнаружена. Давайте посмотрим на эффект, и действительно, собаки нет: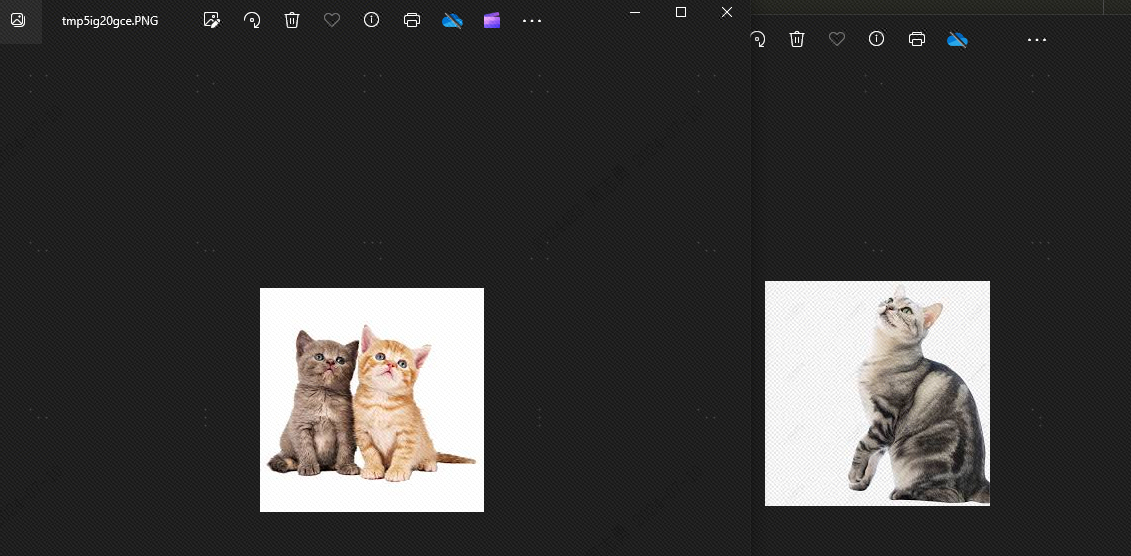
Причина появления собак заключается в том, что я сохранил в векторной библиотеке 4 изображения животных, 2 изображения кошек и 2 изображения собак. Если для нашего топка установлено значение 3, будет обнаружено еще одно изображение собаки.
multi_model.pyФайлы следующие:
import os
import dashscope
from dashvector import Client, Doc, DashVectorException
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
class DashVectorMultiModel:
def __init__(self):
# 我们需要同时开通 DASHSCOPE_API_KEY 和 DASHVECTOR_API_KEY
os.environ["DASHSCOPE_API_KEY"] = ""
os.environ["DASHVECTOR_API_KEY"] = ""
os.environ["DASHVECTOR_ENDPOINT"] = ""
dashscope.api_key = os.environ["DASHSCOPE_API_KEY"]
# 由于 ONE-PEACE 模型服务当前只支持 url 形式的图片、音频输入,因此用户需要将数据集提前上传到
# 公共网络存储(例如 oss/s3),并获取对应图片、音频的 url 列表。
# 该文件每行存储数据集单张图片的公共 url,与当前python脚本位于同目录下
self.IMAGENET1K_URLS_FILE_PATH = "imagenet1k-urls.txt"
self.vector_client = self.init_vector_client()
self.vector_collection_name = 'imagenet1k_val_embedding'
def init_vector_client(self):
return Client(
api_key=os.environ["DASHVECTOR_API_KEY"],
endpoint=os.environ["DASHVECTOR_ENDPOINT"]
)
def index_image(self):
# 创建集合:指定集合名称和向量维度, ONE-PEACE 模型产生的向量统一为 1536 维
collection = self.vector_client.get(self.vector_collection_name)
if not collection:
rsp = self.vector_client.create(self.vector_collection_name, 1536)
collection = self.vector_client.get(self.vector_collection_name)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# 调用 dashscope ONE-PEACE 模型生成图片 Embedding,并插入 dashvector
with open(self.IMAGENET1K_URLS_FILE_PATH, 'r') as file:
for i, line in enumerate(file):
url = line.strip('n')
input = [{'image': url}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}")
continue
embedding = result.output["embedding"]
collection.insert(
Doc(
id=str(i),
vector=embedding,
fields={'image_url': url}
)
)
if (i + 1) % 100 == 0:
print(f"---- Succeeded to insert {i + 1} image embeddings")
def show_image(self, image_list):
for img in image_list:
# 注意:show() 函数在 Linux 服务器上可能需要安装必要的图像浏览器组件才生效
# 建议在支持 jupyter notebook 的服务器上运行该代码
img.show()
def text_search(self, input_text):
# 获取上述入库的集合
collection = self.vector_client.get('imagenet1k_val_embedding')
# 获取文本 query 的 Embedding 向量
input = [{'text': input_text}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
text_vector = result.output["embedding"]
# DashVector 向量检索
rsp = collection.query(text_vector, topk=2)
image_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img = Image.open(urlopen(img_url))
image_list.append(img)
return image_list
if __name__ == '__main__':
a = DashVectorMultiModel()
# 执行 embedding 操作
a.index_image()
# 文本检索
text_query = "Traffic light"
a.show_image(a.text_search(text_query))
DASHSCOPE_API_KEY,DASHVECTOR_API_KEY,DASHVECTOR_ENDPOINTСтруктура каталога кода следующая. Поместите файл txt и файл py в один каталог: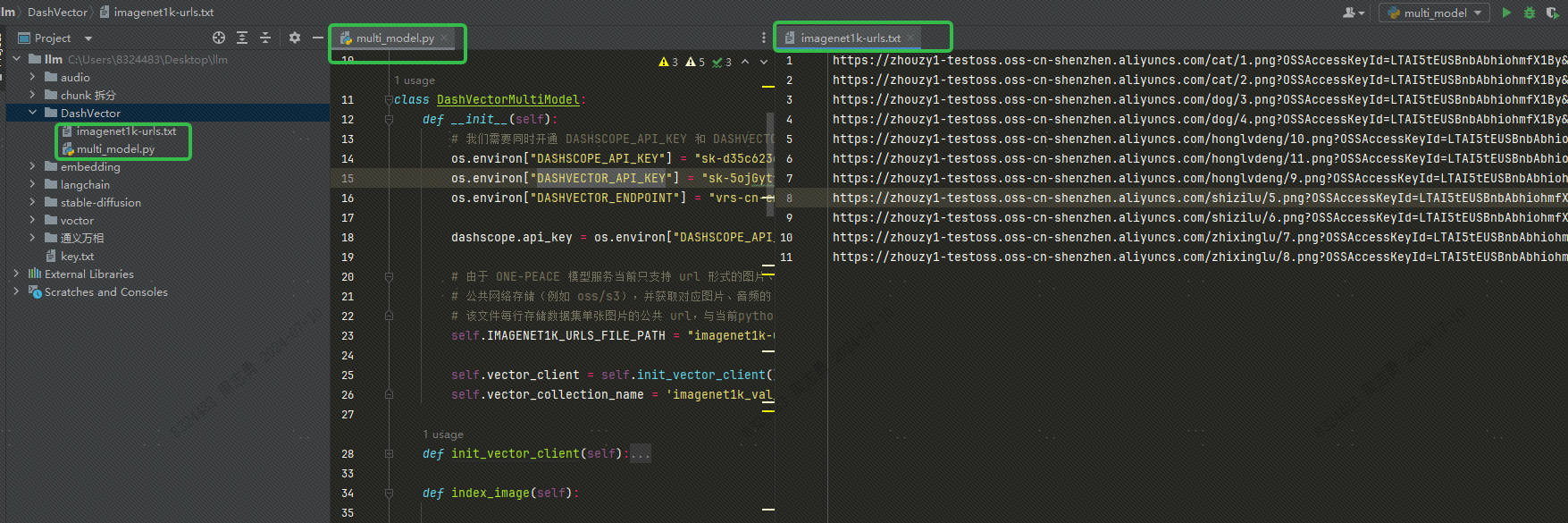
Дополнительная информация
Используйте локальные изображения: Я загрузил изображение в OSS. Вы также можете использовать локальный файл изображения и заменить путь к файлу в формате txt на локальный путь к изображению, как показано ниже:
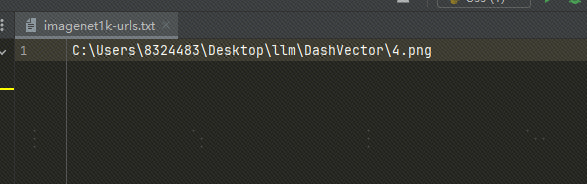
Если мы используем локальные изображения, нам придется изменить код выше и код ниже:
# 将 img = Image.open(urlopen(img_url)) 替换为下边的代码
img = Image.open(img_url)

Он посвятил себя исследованию технологий более 30 лет и владеет различными языками, такими как Java, Linux, Javascript, php, css и т. д. Он внес большой вклад в область открытого исходного кода. Станция документации для разработчиков, где можно поделиться некоторыми проблемами в разработке технологий для дальнейшего использования. Все ознакомьтесь.

Почтамезофия@protonmail.com